

データの視覚化は、データ サイエンスまたは機械学習プロジェクトの非常に重要な部分です。通常、データをある程度理解するには、プロジェクトの早い段階で探索的データ分析 (EDA) を実行する必要があります。視覚化を作成すると、特に大規模で高次元のデータの場合、分析タスクがより明確になり、理解しやすくなります。 。 セット。プロジェクトの終わりが近づくと、聴衆 (多くの場合、技術者ではないクライアント) が理解できるように、最終結果を明確かつ簡潔で説得力のある方法で提示することも重要です。
色を使用してデータ マトリックスの各要素の値を表す方法は、ヒート マップと呼ばれます。マトリックス インデックス作成により、比較する必要がある 2 つの項目または特徴が関連付けられ、異なる値を表すために異なる色が使用されます。ヒート マップは、色がその位置の行列要素のサイズを直接反映できるため、複数の特徴変数間の関係を表示するのに適しています。ヒート マップ内の他のポイントを通じて、各関係をデータ セット内の他の関係と比較できます。色の直感的な性質により、データを解釈するためのシンプルでわかりやすい方法が得られます。
次に、実装コードを見てみましょう。 「matplotlib」と比較して、「seaborn」は、通常、複数の色、グラフィック、変数などのより多くのコンポーネントを必要とする、より高度なグラフィックの描画に使用できます。グラフィック表示には「matplotlib」、データ生成には「NumPy」、データ加工には「pandas」が使えます!お絵描きは「seaborn」のシンプルな機能です。
# Importing libs import seaborn as sns import pandas as pd import numpy as np import matplotlib.pyplot as plt # Create a random dataset data = pd.DataFrame(np.random.random((10,6)), columns=["Iron Man","Captain America","Black Widow","Thor","Hulk", "Hawkeye"]) print(data) # Plot the heatmap heatmap_plot = sns.heatmap(data, center=0, cmap='gist_ncar') plt.show()
二次元密度プロット (2D 密度プロット) は、密度プロットの一次元バージョンを直観的に拡張したものです。このバージョンの利点は、変数の 2 つの確率分布間の関係を確認できることです。右側のスケール プロットは、色を使用して、以下の 2D 密度プロットの各点の確率を表します。データの発生確率が最も高い場所 (つまり、データ ポイントが最も集中している場所) は、size=0.5、speed=1.4 付近のようです。ご存知のとおり、2D 密度プロットは、1D 密度プロットのように 1 つの変数だけを使用するのではなく、2 つの変数を使用してデータが最も集中している領域をすばやく見つけるのに非常に役立ちます。 2 次元密度プロットでデータを観察することは、出力にとって重要な 2 つの変数があり、それらがどのように連携して出力の分布に寄与するかを理解したい場合に役立ちます。
#事実は、「seaborn」を使用してコードを記述することが非常に便利であることを再度証明しました。今回は、データの視覚化をより興味深いものにするために、偏った分布を作成します。オプションのパラメーターのほとんどを調整して、視覚化をより鮮明に見せることができます。
# Importing libs import seaborn as sns import matplotlib.pyplot as plt from scipy.stats import skewnorm # Create the data speed = skewnorm.rvs(4, size=50) size = skewnorm.rvs(4, size=50) # Create and shor the 2D Density plot ax = sns.kdeplot(speed, size, cmap="Reds", shade=False, bw=.15, cbar=True) ax.set(xlabel='speed', ylabel='size') plt.show()
スパイダー プロットは、1 対多の関係を表示する最良の方法の 1 つです。つまり、特定の変数またはカテゴリに関連する複数の変数の値をプロットして表示できます。クモの巣図では、カバーされる領域と中心からの長さが特定の方向に大きくなるため、ある変数の他の変数に対する重要性が明確かつ明白になります。これらの変数によって記述されるオブジェクトのさまざまなカテゴリを並べてプロットして、それらの違いを確認できます。下の表では、アベンジャーズのさまざまな属性を比較し、それぞれが優れている点を簡単に確認できます。 (これらのデータはランダムに設定されており、私はアベンジャーズのメンバーに対して偏見を持っていないことに注意してください。)
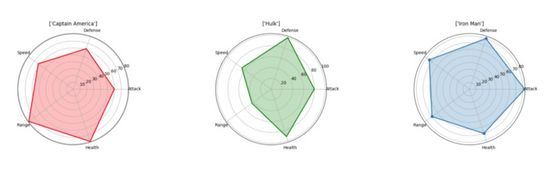
「matplotlib」を使用して視覚化結果を生成できますが、いいえ「シーボーン」を使用する必要があります。各属性を円周上に等間隔に配置する必要があります。各隅にラベルがあり、中心からの距離がその値/サイズに比例する点として値をプロットします。これをより明確に示すために、プロパティ ポイントを接続する線で形成される領域を半透明の色で塗りつぶします。
# Import libs
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# Get the data
df=pd.read_csv("avengers_data.csv")
print(df)
"""
# Name Attack Defense Speed Range Health
0 1 Iron Man 83 80 75 70 70
1 2 Captain America 60 62 63 80 80
2 3 Thor 80 82 83 100 100
3 3 Hulk 80 100 67 44 92
4 4 Black Widow 52 43 60 50 65
5 5 Hawkeye 58 64 58 80 65
"""
# Get the data for Iron Man
labels=np.array(["Attack","Defense","Speed","Range","Health"])
stats=df.loc[0,labels].values
# Make some calculations for the plot
angles=np.linspace(0, 2*np.pi, len(labels), endpoint=False)
stats=np.concatenate((stats,[stats[0]]))
angles=np.concatenate((angles,[angles[0]]))
# Plot stuff
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, stats, 'o-', linewidth=2)
ax.fill(angles, stats, alpha=0.25)
ax.set_thetagrids(angles * 180/np.pi, labels)
ax.set_title([df.loc[0,"Name"]])
ax.grid(True)
plt.show()私たちは小学生の頃からツリーマップの使い方を学んできました。樹形図は本来直観的なものであるため、理解しやすいものです。直接接続されているノードは密接に関連していますが、複数の接続があるノードはそれほど類似していません。以下の視覚化では、Kaggle の統計 (体力、攻撃、防御、特殊攻撃、特殊防御、速度) に基づいて、ポケモン ゲームのデータセットの小さなサブセットの樹形図をプロットしました。
因此,统计意义上最匹配的口袋妖怪将被紧密地连接在一起。例如,在图的顶部,阿柏怪 和尖嘴鸟是直接连接的,如果我们查看数据,阿柏怪的总分为 438,尖嘴鸟则为 442,二者非常接近!但是如果我们看看拉达,我们可以看到其总得分为 413,这和阿柏怪、尖嘴鸟就具有较大差别了,所以它们在树状图中是被分开的!当我们沿着树往上移动时,绿色组的口袋妖怪彼此之间比它们和红色组中的任何口袋妖怪都更相似,即使这里并没有直接的绿色的连接。
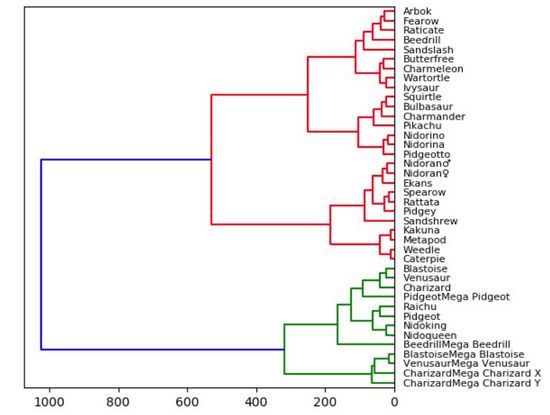
实际上,我们需要使用「Scipy」来绘制树状图。一旦读取了数据集中的数据,我们就会删除字符串列。这么做只是为了使可视化结果更加直观、便于理解,但在实践中,将这些字符串转换为分类变量会得到更好的结果和对比效果。我们还创建了数据帧的索引,以方便在每个节点上正确引用它的列。告诉大家的最后一件事是:在“Scipy”中,计算和绘制树状图只需一行简单代码。
# Import libs import pandas as pd from matplotlib import pyplot as plt from scipy.cluster import hierarchy import numpy as np # Read in the dataset # Drop any fields that are strings # Only get the first 40 because this dataset is big df = pd.read_csv('Pokemon.csv') df = df.set_index('Name') del df.index.name df = df.drop(["Type 1", "Type 2", "Legendary"], axis=1) df = df.head(n=40) # Calculate the distance between each sample Z = hierarchy.linkage(df, 'ward') # Orientation our tree hierarchy.dendrogram(Z, orientation="left", labels=df.index) plt.show()
以上が高速で使いやすい Python データ視覚化方法は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



