

360+ Wisdom AI、「Microsoft + OpenAI」の中国版が登場


大型モデルのコア技術の研究開発において、360は独自の研究開発を採用し、コア「エンジン」の競争力を強化するために「デュアルエンジン」ドライブの開発に協力します。
著者/羅志南明
ビジネスレビューから作成/新たに抜粋
ChatGPT の成功は、決してそれ自体の努力によるものではありません。歴史上最も急速に成長しているこのアプリケーションの背後では、協力者の Microsoft が重要な役割を果たしています。大規模なシステムの破壊に貢献したのは、業界と研究の協力です。言語モデル技術の変化。中国は大規模なモデル戦争を開始したが、数カ月間の喧騒の後、この実証済みの道に乗り出す企業はなく、中国版「Microsoft OpenAI」が登場するかどうかが業界の焦点となっている。
本日、360 CompanyとZhipu AIは戦略的提携を発表し、ついに協力計画を発表しました。両者が共同開発した大規模モデル「360GLM」は、新世代の認知知能一般モデルのレベルに達した。
1. 中国では大型モデルの時代が到来します
ChatGPT のリリースは大きな変化を引き起こしました。Microsoft は、ChatGPT が Office ファミリ バケットに接続されたことを発表しました。これは、アプリケーションに破壊的なイノベーションをもたらし、全世界に衝撃を与えました。
中国を振り返ると、ChatGPT のリリースと適用後、大手メーカーが急速にフォローアップし、Baidu の Wen Xinyiyan、Alibaba の Tongyi Qianwen、iFlytek の Xinghuo などが大型モデルの分野で成功を収め続けました。
同時に、大手メーカーも、大規模モデルのテクノロジーを実用的なアプリケーションに統合することが緊急であることを認識しています。 Alibaba Cloud は、将来的にすべての Alibaba 製品が「Tongyi Qianwen」大型モデルにアクセスすることで完全にアップグレードされると発表しました。iFlytek の Spark 大型モデルには、テキスト生成、知識の質問と回答、数学的機能などのコア機能があります。
現実には、多くの企業が大型モデルを発売していますが、各大型モデルの機能はほぼ同じです。誰もはるかに先を行って世界を支配することはできません。しかし、確かなことは、誰もが「絵に描いた餅」であるとき、ということです。 」、着地が鍵です。
勝敗の決め手は「シナリオ」であるというのが業界のコンセンサスであり、シナリオを持った企業だけが今後の大型モデル業界競争で主導的な地位を占めることができる。
大型モデルのテクノロジー自体はもはや敷居ではなく、産業と研究をより適切に組み合わせる方法と、それをより効果的に実装する方法は、大型モデル業界に参入するすべてのプレーヤーがさらに検討する必要がある問題です。
明らかに、実績のある道に従う方が成功を達成しやすくなります。
360とZhipu AIの連携は、中国版「Microsoft OpenAI」ともいえる。
工業企業だけが存在する場合、オープン AI 科学者の長期的な理想は欠如し、人類のすべての知識を大規模なモデルにエンコードするという道をさらに進めようと考える人は誰もいないかもしれません。
逆も同様で、Open AI だけでは論文を出し続けても意味がありませんし、結局、論文や技術とユーザーのシナリオを組み合わせなければ成功しません。
Microsoft と Open AI は非常に適切な分業体制をとっています。Microsoft は Open AI サービスを製品にバンドルしているため、Open AI サービスを真にエンジニアリング、シナリオベース、製品ベースで実現し、さらには商品化することもできます。
オープン AI は、必ずしも商用化が得意であるわけではなく、製品やシナリオの開発が得意であるとは限りませんが、コア技術の点では常に GPT3.5 から GPT4.0 に移行しており、おそらく GPT5 はすでにその途中にあります。
海外では、産業と研究の成功した組み合わせが先駆者となっており、360 がこの成功した道を模倣することを拒否する理由はありません。
2. 技術シナリオの「中国 GPT 組み合わせ」
Zhipu AIは清華大学コンピューターサイエンス学部の技術成果を転換した企業で、中国で「最もOpenAIの気質とレベルが高い」企業と評価され、昨年11月にはスタンフォード大学のモデルセンターが世界の主流大企業30社を対象に調査を実施し、モデルを全方位的に評価し開発したバイリンガル1000億レベルの超大規模事前学習モデル「GLM-130B」 Zhipu AIは、アジアで唯一選ばれた大型モデルでした。
専門家による評価結果によると、GLM-130B の精度などの重要な指標は、OpenAI、Google Brain、Microsoft、Nvidia などの企業の大規模モデルと同等または同等であることが示されています。世界が使用を申請しました。
Zhipu AI は、大手大型モデル テクノロジー企業として、OpenAI に追いつくリーダー的な立場にあります。ただし、単に技術的に優れているだけでは十分ではありません。より重要な成果は、実際のシナリオでの応用にあります。

360 と Zhipu AI 間のこの連携は、大規模なモデルとシーンを組み合わせる際の重要な実践です。 360 の創設者である周宏儀氏は、大規模モデルの開発におけるシナリオの重要性を常に強調しており、テクノロジーをユーザーのシナリオと組み合わせることができなければ成功しないと述べたこともあります。
ChatGPT の人類への影響が深まり続けるにつれ、ますます多くの国内企業が大型モデルの分野に参入しています。この点に関して、Zhou Honyi 氏は次のように述べています。「最も重要なことは、大型モデル技術を持っているかどうかではなく、どのようにそれを行うかだ」 「Microsoft と OpenAI の連携モデルから学ぶ」では、トレーニング用に優れたデータを取得する方法、より優れたエンジニアリング トレーニング方法を実装する方法、大規模なモデルを使用するためのより優れたユーザー シナリオを見つける方法について説明します。
360 Browser の平均 MAU は 4 億 1,600 万で、360 Search の 1 日あたりの平均リクエスト量は 10 億を超えていることがわかります。これは、その後のトラフィック操作、ユーザー フィードバック、大規模モデルのモデル最適化の基礎となります。 。
Microsoft の「Family Bucket」に匹敵する 360 のフルエンド アプリケーションは、Zhipu AI にテクノロジーの機会を提供します。 同時に、フルエンド アプリケーションのデータを通じて、大規模なアプリケーションの開発にも役立ちます。データ サポートを提供するモデル テクノロジー。大規模モデルの場合、より多くのデータ サポートとシーン情報のフィードバックも、モデルの改善を支援する重要なステップです。テクノロジーとデータが連携してフライホイール効果を生み出します。
大型モデルの「ボリューム」は、ある程度、テクノロジーだけではなく、テクノロジーとアプリケーションの組み合わせでもあります。
Microsoft と OpenAI 間の協力モデルは実現可能であることが証明され、この点が証明されました。国内の大規模モデル技術の導入には、その応用をより包括的に検討する必要があり、特定の分野やシナリオに限定されるべきではありません。
Microsoft に匹敵するユーザー シナリオを備えた 360 と Zhipu AI の連携は、中国版「Microsoft OpenAI」モデルの最良の例となり、大型モデル業界の競争において一定の優位性を占めることになります。 両当事者 技術における強力な提携と技術とシナリオの補完性により、国内大型モデル業界の競争をまったく新しい次元に引き上げることができます。
3. AI 時代、2 行の 360
360 の人工知能戦略は「両面を飛び回る」ことであり、一方ではコア技術を開発し、他方ではユーザーシナリオを掌握します。
コアとなる「エンジン」の競争力を高めるため、360は自主研究開発と共同研究開発という「デュアルエンジン」推進戦略を採用しています。
360 は常にセキュリティのリーダーシップで知られており、国内をリードする人工知能技術の第一段階に位置し、継続的に蓄積してきました。 360はCVやNLPといったAIの最先端技術をIoTやセキュリティビッグデータなどの分野に応用するため、2015年にはすでに人工知能研究所を設立していた。同時に、Safe Brain-国家人工知能オープンプラットフォームプロジェクトにも着手しました。
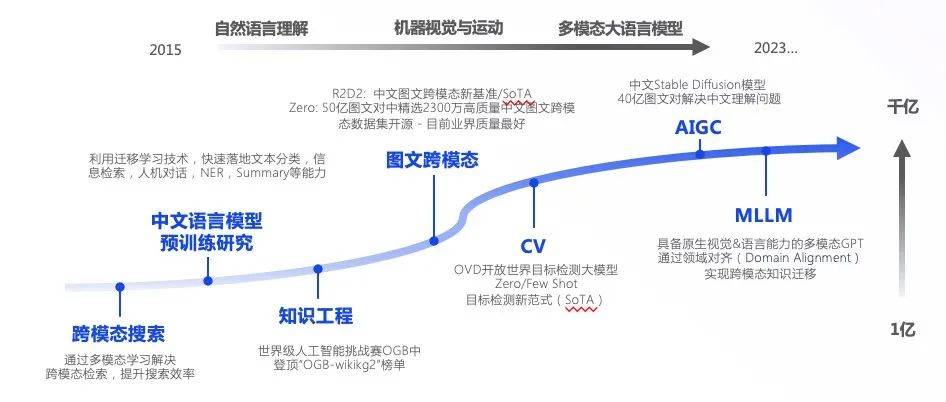
国内先進的なマルチモーダル R&D チームのおかげで、360 は自然言語理解、マシン ビジョンとモーション、および音声セマンティック インタラクションの分野で業界のリーダーシップを獲得しており、そのコア メンバーとチームは複数の AI 関連のコンテストのチャンピオンシップ/ノミネート賞を受賞しています。 . .
大規模モデル関連技術に関しては、360はマルチモーダル学習によりクロスモーダル検索を解決し、検索効率を向上させ、転移学習技術を使用してテキスト分類、情報検索、人間とコンピュータの対話、NERを迅速に実装します。 、概要およびその他の機能. 中国語モデルの事前トレーニング調査を実施しました。
その後、360 は画像とテキストのクロスモダリティの研究を開始し、オープンソースのクロスモーダル データ セット用に 50 億の画像とテキストから 2,300 万枚の高品質の中国語の画像とテキストを選択しました。その後の CV、AIGC、MLLM の研究により、360 は大規模モデルの初期準備のためのより強固な基盤を築きました。
CV では、OVD は世界のターゲット検出の大規模モデル Zero/Few Shot をオープンしました。AIGC では、中国の安定拡散モデルが中国語の理解の問題を解決するために 40 億の画像とテキストのペアを解決しようとしました。MLLM では、ネイティブ視覚と言語 マルチモーダル GPT 機能は、ドメインの調整を通じてクロスモーダルな知識の伝達を実現します。
まとめると、360 の独立した研究開発は、自然言語理解、マシン ビジョンとモーション、マルチモーダル大規模言語モデルなどのプロセスを経て、ますます洗練されました。
AI コア テクノロジーに基づいて、360 は独自の有利なシナリオを活用して「4 方向同時実行」大規模モデルを実装し、大規模モデル関連の製品とサービスを消費者、中小企業、業界、政府企業と都市。
360GPT の製品マトリックスは 360 Intelligent Brain です。360 Intelligent Brain パノラマには、360CV 大型モデル、360GPT 大型モデル、3 60GLM 大型モデル、および 360 マルチモーダル大型モデルが含まれます。
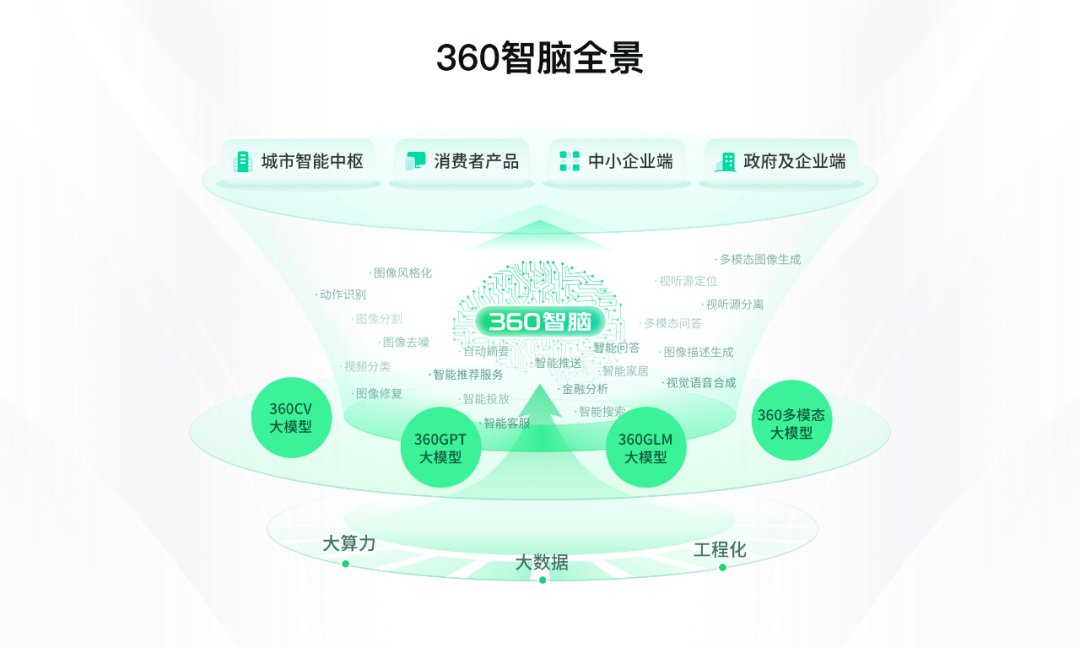
周宏毅氏は、自身の大規模モデルの実装に向けた明確な計画を持っており、「360 Intelligent Brain」が検索シーンで主導権を握った後、GPT 機能と組み合わせたスマート ブラウザ、AI マッピング ツール、エンタープライズ インテリジェント マーケティング クラウドがまもなく登場します。 B エンド ユーザーが利用できるようになるため、テスト用に公開されます。 戦略の観点から見ると、360 は成功を急ぐのではなく、ユーザーの厳格なニーズに焦点を当て、シナリオを成熟させ、シナリオを切り開きます。
周宏毅氏は、中国の大型モデルはGPTに比べて開発が約2年間遅れており、開発を促進するにはユーザーの支持、理解、寛容が必要であると何度も強調してきた。課題や技術面で中国選手が逆転する可能性もある。強力な推論能力、思考の連鎖、創発的な能力など、一部の能力は開発するために特定のプロセスを必要とします。
中国における GPT の開発が十分に成熟していないのは事実ですが、最終的な勝者がどのように現れるかは誰にもわかりません。そして、このプレーヤーは「Microsoft OpenAI」の成功モデルをコピーした 360 になるのでしょうか?見てみましょう。
以上が360+ Wisdom AI、「Microsoft + OpenAI」の中国版が登場の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7524
7524
 15
1378
52
81
11
21
74
15
1378
52
81
11
21
74

 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Systemsでは、Readdir関数はディレクトリコンテンツを読み取るために使用されますが、それが戻る順序は事前に定義されていません。ディレクトリ内のファイルを並べ替えるには、最初にすべてのファイルを読み取り、QSORT関数を使用してソートする必要があります。次のコードは、debianシステムにreaddirとqsortを使用してディレクトリファイルを並べ替える方法を示しています。
 Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverのファイアウォールの構成は、サーバーのセキュリティを確保するための重要なステップです。以下は、iPtablesやFirewalldの使用を含む、一般的に使用されるファイアウォール構成方法です。 iPtablesを使用してファイアウォールを構成してIPTablesをインストールします(まだインストールされていない場合):sudoapt-getupdatesudoapt-getinstalliptablesview現在のiptablesルール:sudoiptables-l configuration
 Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
この記事では、DebianシステムのApachewebサーバーのロギングレベルを調整する方法について説明します。構成ファイルを変更することにより、Apacheによって記録されたログ情報の冗長レベルを制御できます。方法1:メイン構成ファイルを変更して、構成ファイルを見つけます。Apache2.xの構成ファイルは、通常/etc/apache2/ディレクトリにあります。ファイル名は、インストール方法に応じて、apache2.confまたはhttpd.confである場合があります。構成ファイルの編集:テキストエディターを使用してルートアクセス許可を使用して構成ファイルを開く(nanoなど):sudonano/etc/apache2/apache2.conf
 Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian Systemsでは、OpenSSLは暗号化、復号化、証明書管理のための重要なライブラリです。中間の攻撃(MITM)を防ぐために、以下の測定値をとることができます。HTTPSを使用する:すべてのネットワーク要求がHTTPの代わりにHTTPSプロトコルを使用していることを確認してください。 HTTPSは、TLS(Transport Layer Security Protocol)を使用して通信データを暗号化し、送信中にデータが盗まれたり改ざんされたりしないようにします。サーバー証明書の確認:クライアントのサーバー証明書を手動で確認して、信頼できることを確認します。サーバーは、urlsessionのデリゲート方法を介して手動で検証できます
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Debian Hadoopログ管理を行う方法
Apr 13, 2025 am 10:45 AM
Debian Hadoopログ管理を行う方法
Apr 13, 2025 am 10:45 AM
DebianでHadoopログを管理すると、次の手順とベストプラクティスに従うことができます。ログ集約を有効にするログ集約を有効にします。Yarn.log-Aggregation-set yarn-site.xmlファイルでは、ログ集約を有効にします。ログ保持ポリシーの構成:yarn.log-aggregation.retain-secondsを設定して、172800秒(2日)などのログの保持時間を定義します。ログストレージパスを指定:Yarn.Nを介して
