

アリババのリスク管理システムにおけるグラフアルゴリズムの実践


1. 電子商取引のリスク管理シナリオにおけるグラフ アルゴリズムの概要
まず、電子商取引のリスクの概要を簡単に説明します。アリババ電子商取引の特性、アプリケーション履歴、グラフ アルゴリズムの現状。
1. アリババの電子商取引リスクの特徴
アリババの電子商取引リスクの主な特徴: 対立と順列式の複雑さ。
# リスクは対立的である必要があり、アリババの電子商取引のリスクも順列と組み合わせにおいて複雑です。リスクの特定は主に X (データ) を使用して Y (リスク) を予測します: P(Y|X)。 Alibaba e-commerce、Tmall、1688、Lazada などでは、市場ごとにリスク特性が異なります;
② 多様なビジネス シナリオ - アカウント、製品、プロモーションなど、ビジネスの反復と革新に伴い、新たなリスクが発生します;
③ 多様なアプリケーション端末 - PC、H5、APP など。 、各端末には予防と制御が必要です。
#④ 多様なデータ ソースには、さまざまなモダリティでデータを処理および統合する機能が必要です。
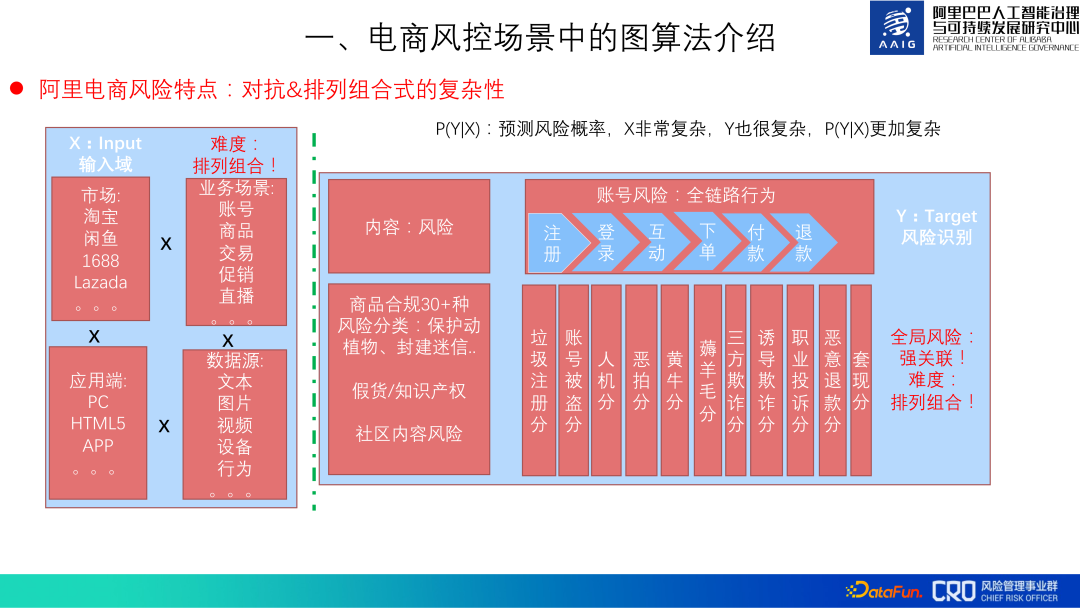 同時に、Y も非常に複雑であり、主に 3 つの側面が反映されています。 1 つ目はリスクの種類です。多くの一般的なコンテンツ リスク、行動リスクなどは、多くのリスクの大海の一滴にすぎません。2 つ目は、販売者の詐欺が登録、盗難、製品コンテンツに関連しているなど、これらのリスクは関連しています。 3 番目に、リスクは移転します。ある種類のリスクは予防する方が効果的ですが、犯罪を犯す代償は高く、その後、他のリスクに移転したり、新たなリスクを生み出したりします。
同時に、Y も非常に複雑であり、主に 3 つの側面が反映されています。 1 つ目はリスクの種類です。多くの一般的なコンテンツ リスク、行動リスクなどは、多くのリスクの大海の一滴にすぎません。2 つ目は、販売者の詐欺が登録、盗難、製品コンテンツに関連しているなど、これらのリスクは関連しています。 3 番目に、リスクは移転します。ある種類のリスクは予防する方が効果的ですが、犯罪を犯す代償は高く、その後、他のリスクに移転したり、新たなリスクを生み出したりします。
#したがって、リスクの予防と制御全体は、複雑さの順列と組み合わせによって非常に複雑になります。
#2. グラフ アルゴリズムの重要性
グラフ アルゴリズムは、リスク識別モデルの対立能力を向上させることができます。プラットフォーム上での「悪いこと」のほとんどは少数の人間によって行われており、「悪者」は多くのベストを持っており、私たちは「関係性」を通じて手がかりを見つけ出し、事前に特定して対処することができます。例えば、下の写真の黄色の点は、異常な行動をとったユーザーであると仮定すると、彼自身の行動だけでは不正ユーザーであると判断することは困難ですが、他の3人の不正ユーザーを分析することで分析することができます。彼に関連付けられた (黒い点) ことで、彼が詐欺ユーザーであると判断されます。同時に、これら 4 つのアカウントと密接に関連するアカウントもすべて発見され、暴力団の一員であることが判明しました。これらのアカウントを事前に一括して処理すると、悪事を働くコストが増加する可能性があります。
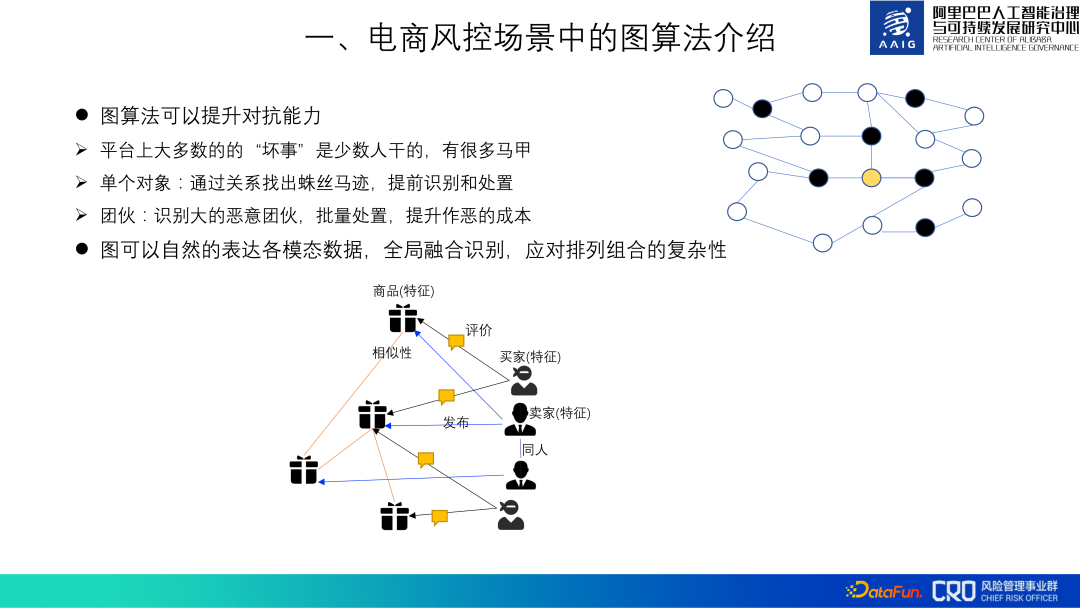 #さらに、異種グラフにより、さまざまなモダリティとリスク オブジェクトのデータを自然かつグローバルに統合できます。 、さまざまなオブジェクトの表現を計算し、順列と組み合わせの複雑さに対処するためのさまざまなリスクを特定します
#さらに、異種グラフにより、さまざまなモダリティとリスク オブジェクトのデータを自然かつグローバルに統合できます。 、さまざまなオブジェクトの表現を計算し、順列と組み合わせの複雑さに対処するためのさまざまなリスクを特定します
3. グラフ アルゴリズムの歴史と現状
グラフ アルゴリズムの重要性に基づいて、アリババの電子商取引リスク管理では 2013 年からグラフ アルゴリズムを使用しています。
#当初、アカウント データベース全体の関係ネットワークを構築するためにグラフ アルゴリズムが使用されました。このリレーショナルデータは、不正行為、アカウントセキュリティ、不正行為対策、偽造品などのあらゆるリスクの予防・管理シナリオに必要な基礎データであり、主に使用されるデータには、デバイス情報や携帯電話番号などのメディアデータが含まれます。主にアカウント間の相関関係、関係タイプ、グループ識別などについて説明します。この関係ネットワークには、生産からアプリケーションまでの閉ループ フィードバック チャネルが確立されています。
基盤となるリレーショナル データが大量にあります。リレーショナル データの集計、クリーニング、グラフ計算、保存にかかる全体的なコストは非常に高く、後で継続的に更新する必要があるため、関係を構築するのにコストがかかりますネットワークの割合は高いですが、当社のリスク モデルと戦略の多くはこの関係ネットワークに依存しているため、それでも価値があります。 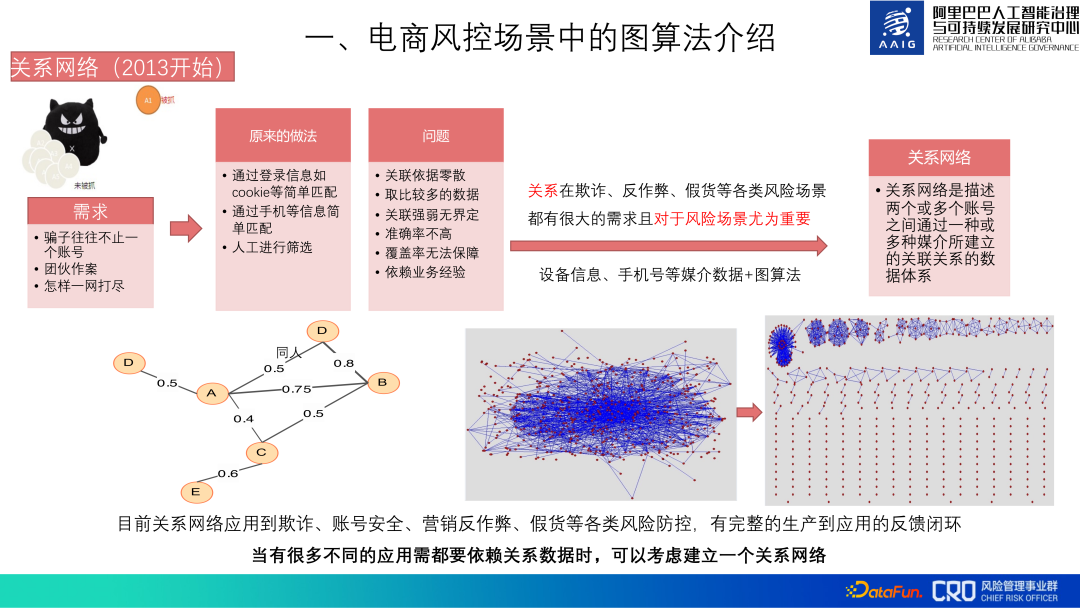
グラフ ニューラル ネットワークに関しては、2016 年にアプリケーションの検討を開始しました。 GGL (Geometric Graph Learning) とも呼ばれますが、当時は直接利用できるグラフ ニューラル ネットワーク アルゴリズム フレームワークがなかったため、C で GGL アルゴリズム フレームワークを実装しました。 2018 年に、Alibaba Computing Platform が提供する Graph learn に移行されました。このフレームワークもオープンソースであり、グラフ アルゴリズム コードもこのフレームワークに提供されました。
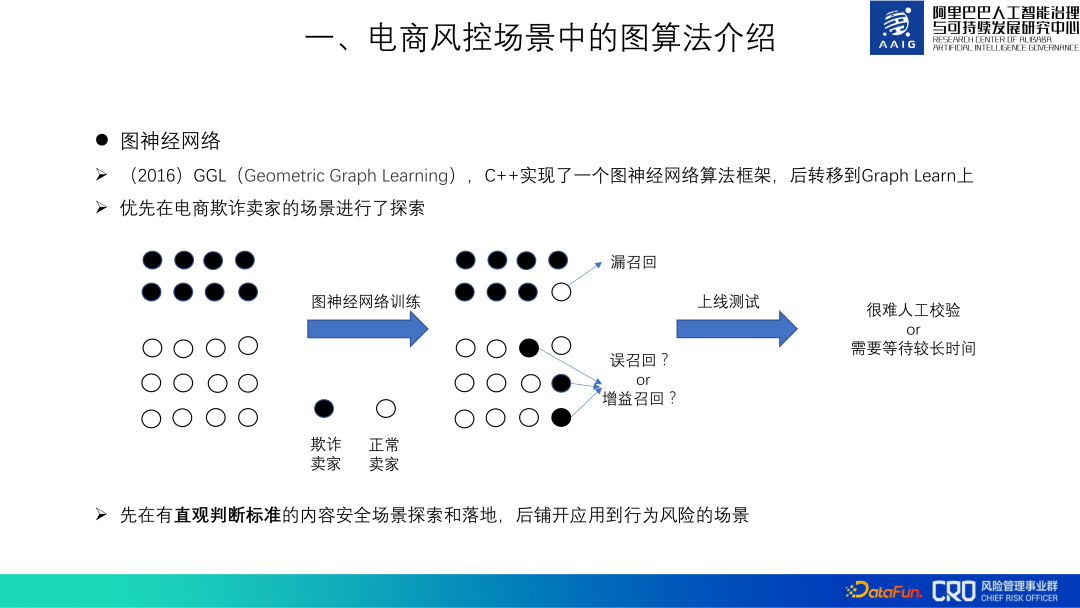
電子商取引のリスク管理シナリオは数多くあり、どのシナリオを選択するかも重要ですグラフ アルゴリズム検証フェーズでの適切なシナリオ特に重要です。リスクシナリオで大きな割合を占める行動リスクの「判断基準」は直感的ではありません 産業シナリオでは、行動リスクの白いサンプルと未発見の黒いサンプルが多数混在しており、グラフアルゴリズムが白いサンプルを黒と判断した場合サンプルが黒サンプルであるかどうかの判断は難しく、フォールスリコールかゲインリコールかにかかわらず、モデルのチューニングやオンライン効果の判定に影響を与えます。逆に、スパムや侮辱などのコンテンツセキュリティシナリオは「直感的な判断基準」を持つシナリオであり、グラフアルゴリズムの有効性を検証するのに適しています。したがって、私たちはまずコンテンツ セキュリティ シナリオでアルゴリズムを調査し、その有効性を検証してベスト プラクティスを蓄積してから、それを行動リスク シナリオに適用します。
#これまで、グラフ アルゴリズムはアリババ電子商取引のさまざまなリスク ビジネスに使用されてきました。グラフ アルゴリズム アプリケーション全体のフレームワークは次のとおりです。まず、上位層の適用を容易にするために、さまざまなリレーショナル データを収集およびクリーンアップするリレーショナル データ層が最下位に維持されます。データ層の上部には、一般的に使用されるグラフ アルゴリズムが含まれます。次の層はリレーショナル データ層とアルゴリズム層を使用してアカウント リレーションシップ ネットワークを構築し、ビジネス層でのさまざまなリスク シナリオの予防と制御を水平的にサポートします。最上位のビジネス層では、特定のリスクの特性と組み合わせて、では、これらのグラフ アルゴリズムとリレーショナル データを使用して、さまざまなビジネス リスクを特定するためのグラフ モデルを構築します。
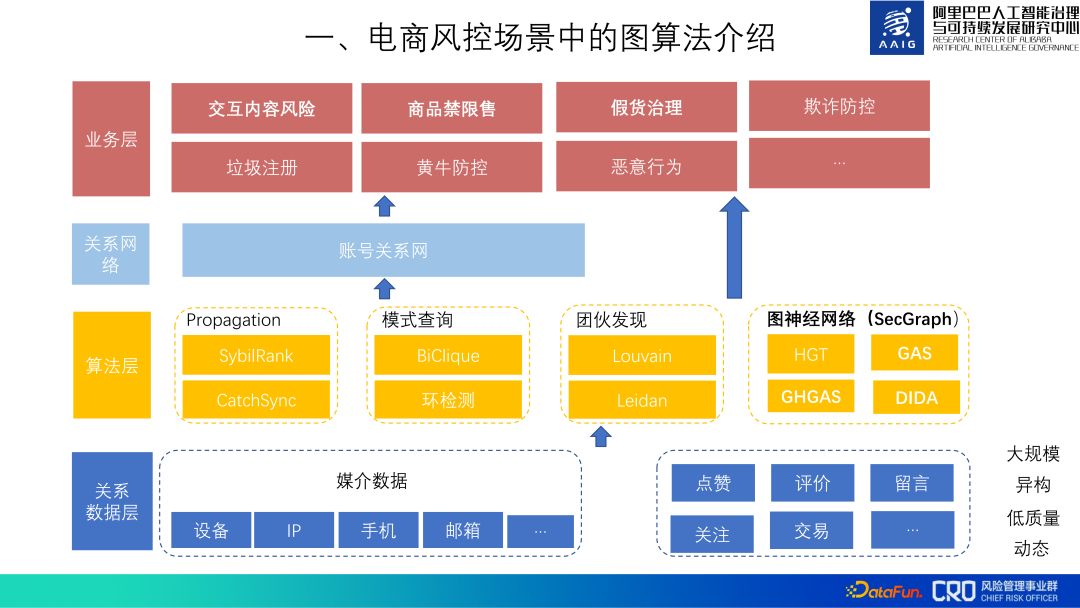
#次の共有では、主に「インタラクティブコンテンツのリスク」、「商品の禁止と制限」、「模倣品」について紹介します。いくつかのグラフ アルゴリズムは、次の 3 種類のリスクに適用されます。「ガバナンス」。
#2. インタラクティブ コンテンツのリスク管理のためのグラフ アルゴリズムAlibaba e-commerce プラットフォームには、豊富なインタラクティブ コンテンツ シナリオがあります。製品の評価、コメント、みんなへの質問、モバイル淘宝ショッピング、Xianyu コミュニティなど。以下では、Xianyu メッセージ内のスパム広告の識別を例として、コンテンツ リスク管理グラフ アルゴリズムを紹介します。
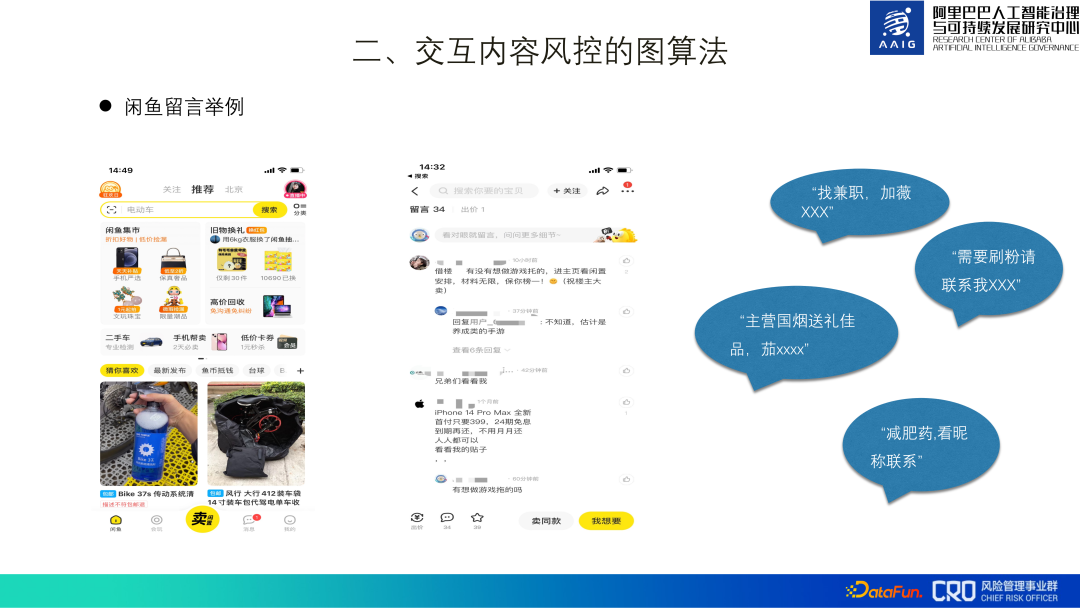
Xianyu APP の製品コメントで「スパム広告」がよく見られますコンテンツには、アルバイト、偽の注文、減量薬の販売などのリスクがあり、非常に対立的です。たとえば、上のスクリーンショットでは、「兄弟、私を見てください」という文がありますが、実際の広告はテキスト自体には含まれていません。 、ただしユーザーのホームページ上にあります。
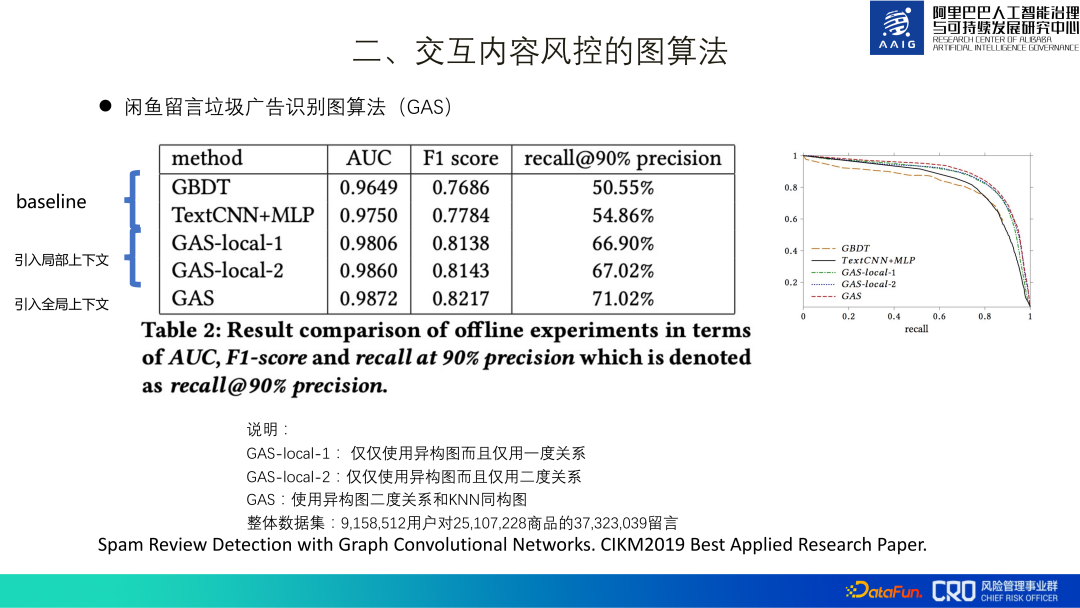
Xianyu メッセージのスパム広告識別は、グラフ ニューラル ネットワーク アルゴリズムの最初のアプリケーション シナリオであり、この識別モデルを略して GAS と呼びます。モデル全体は、異種グラフと同種グラフで構成されます。異種グラフは、製品、コメント、ユーザーなどの各ノードのローカル表現を学習します。同種グラフは、さまざまなコメントのグローバル表現を学習するコメント グラフです。最後に、これら 4 つの表現が 2 項分類モデルのトレーニングのために融合されます。
#
全体的なトレーニング データ セットには、3kw のメッセージ、2kw の製品、および 900 万人のユーザーが含まれています。オンライン化後、元の MLP モデルよりも 30% 高いリスクがリコールされました。また、スパム広告自体の特性上、より効果を得るには大量の転送が必要となるため、グローバル情報の追加もアブレーション実験により大幅に改善されることが確認されました。この成果は最終的に論文としてまとめられ[1]、CIKM2019の最優秀応用研究論文を受賞しました。
#3. 製品コンテンツのリスク管理のためのグラフィック アルゴリズム
ここでは主に、製品コンテンツのリスク管理のための 2 種類のグラフ アルゴリズムを紹介します。1 つは製品グラフ構造の学習、もう 1 つは製品グラフ構造と専門知識グラフの統合です。

商品リスク管理とは、主に「販売禁止・販売制限」のリスクを管理することです。国の法律や規制で禁止されているもの、国家保護動物や植物、不正行為や偽造品、管理医療機器などの販売。
商品の管理と制御は非常に複雑で、商品データはマルチデータ ストリーム、マルチチャネル、マルチモーダルです:
① 複数のデータ ストリーム: タイトル、説明、メイン画像、セカンダリ画像、詳細画像、SKU;
② マルチチャンネル: テキストの音、形と意味、画像の RGB;
③ マルチモーダル: テキスト、写真、メタ情報 (価格、販売)。
#同時に、製品コンテンツのリスクも複雑かつ多様で、激しい争奪戦が行われています。たとえば、上の図では、次のように見えます。ビーズを販売していますが、実際には象牙を販売しています。
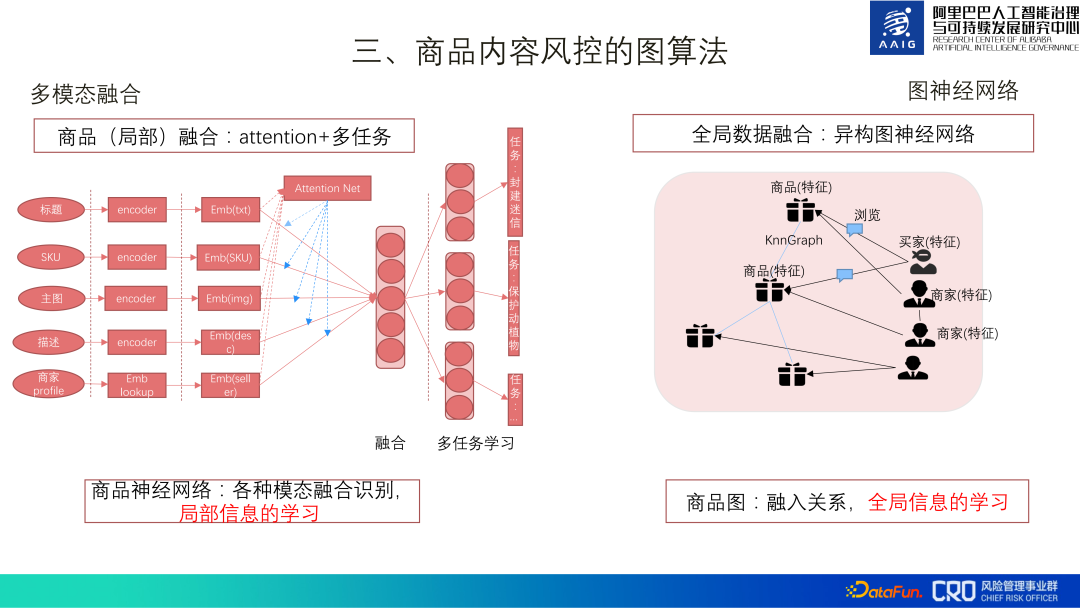
製品コンテンツ リスク コントロール マップ アルゴリズムには、主に 2 つのタイプがあります。1 つはマルチモーダル フュージョン モデルで、ディープ モデルを使用して製品ニューラルを構築します。マルチモーダル融合は、商品の局所的な情報の学習であるマルチタスク学習を実行するものであり、もう1つは、異種グラフを使用して商品と商品、商品と販売者、販売者の間の関係を確立することでリスクの想起を向上させることです。と売り手は、グローバル情報の融合学習を行います。
1. プロダクト グラフのグラフ構造学習
GCN の本質は、隣接する特徴を融合する特徴平滑化です。グラフ ニューラル ネットワークの学習には、グラフ構造の品質に関する特定の要件があり、優れたネットワーク グラフは密度が高く、均一性が高くなります。ただし、リスク積のグラフはまばらで、均一性率は比較的低い (0.15、公開データセットの統計では 0.6 以上が良いことがわかっています) ため、グラフの構造を学習する必要があります。
# 積グラフには枠内に示すように 3 種類のエッジがあり、3 種類のグラフを構成します。以下の図の右側: 1 つのタイプは、2 つの商品が同じ販売者によって販売され、同じ販売者画像を持っている、2 つ目のカテゴリは、2 つの商品が同じ消費者によって閲覧された同じ閲覧画像です。 category は、2 つの商品の販売者に強い関連性がある、関連付けられた販売者の画像です。
プロダクト グラフ構造学習の本質は、エッジの追加と削除のプロセスです。まず、KNN グラフを使用してプロダクトの埋め込みに基づいて KNN グラフを構築し、次に上記の 4 つを配置します。 HGT は新しいプロダクト エンベディングを学習し、アテンション値が低いエッジをノイズとして削除します。新しいプロダクト エンベディングを使用して KNN グラフを更新し、損失が収束するまで反復処理を繰り返すことができます。実際のデータで実践すると、このグラフ構造学習フレームワークが同種グラフ/異種グラフと比較して SOTA の結果を達成することがわかります。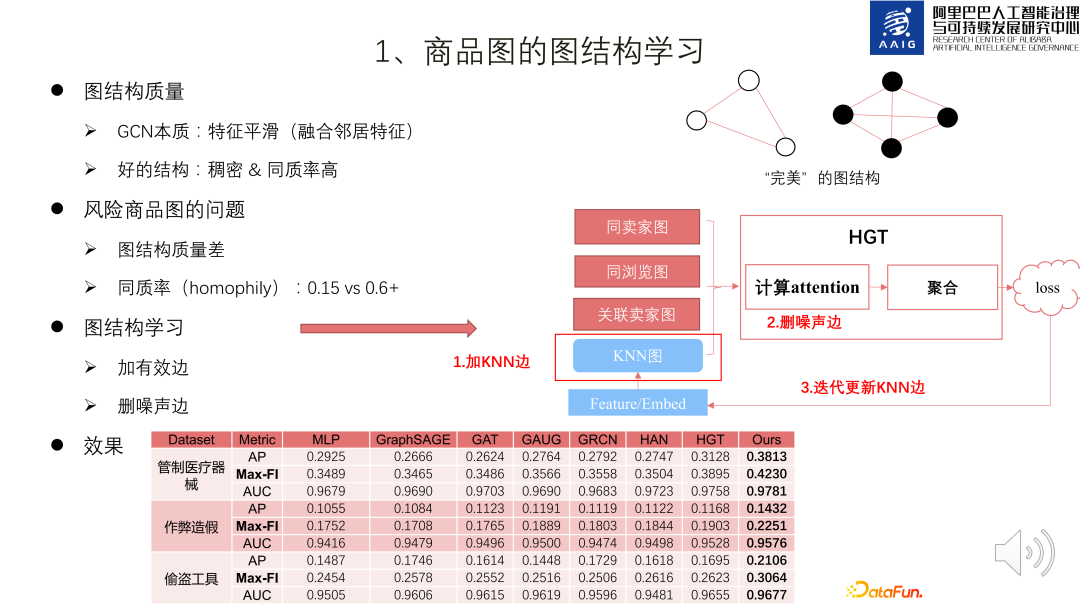
2. グラフコンピューティングとリスクナレッジグラフの統合
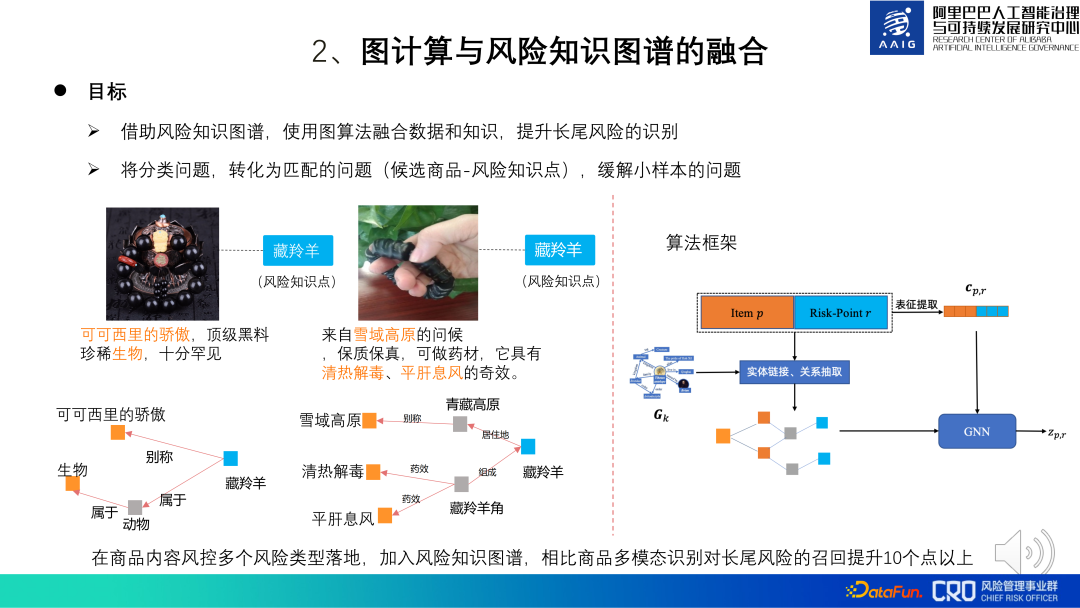
コモディティグラフアルゴリズムの改善アルゴリズムは、グラフコンピューティングとリスクナレッジグラフの融合です。一部の商品リスクは常識で判断するのが難しく、特定の専門分野の知識を組み合わせる必要があります。したがって、モデルの特定と手動レビューを支援するために、これらの特定のリスク領域の知識ポイントに対して特定の知識グラフが構築されました。
たとえば、下の写真の左側にある 2 つの商品は、一見シンプルなアクセサリーを販売しているように見えますが、実際にはチベットのレイヨウの角を販売しています。チベットアンテロープは国の第一級保護動物であり、その関連製品は禁止されており、チベットアンテロープに関する知識と照合することで、この製品のリスクを特定することができます。融合アルゴリズムのフレームワークは、以下の図の右側に示されています。モデルの目標は、候補製品とリスク知識ポイントが一致するかどうかを判断することです。項目 p は製品のグラフィック表現、リスクポイント R は知識ポイントの表現であり、エンティティ認識、エンティティのリンク、関係抽出を通じて、製品と知識ポイントの部分グラフが取得され、GNN が使用されます。サブグラフの表現を計算し、最後にその表現が使用され、リスクの分類と特定が行われます。その中でも、CPR は製品表現と知識ポイント表現を融合したもので、主にグローバルな情報を学習するためのグラフ表現をガイドするために使用されます。実際には、製品のマルチモーダル認識と比較して、リスク知識グラフを追加することでロングテール リスクの想起が 10 ポイント以上改善されることが示されています。
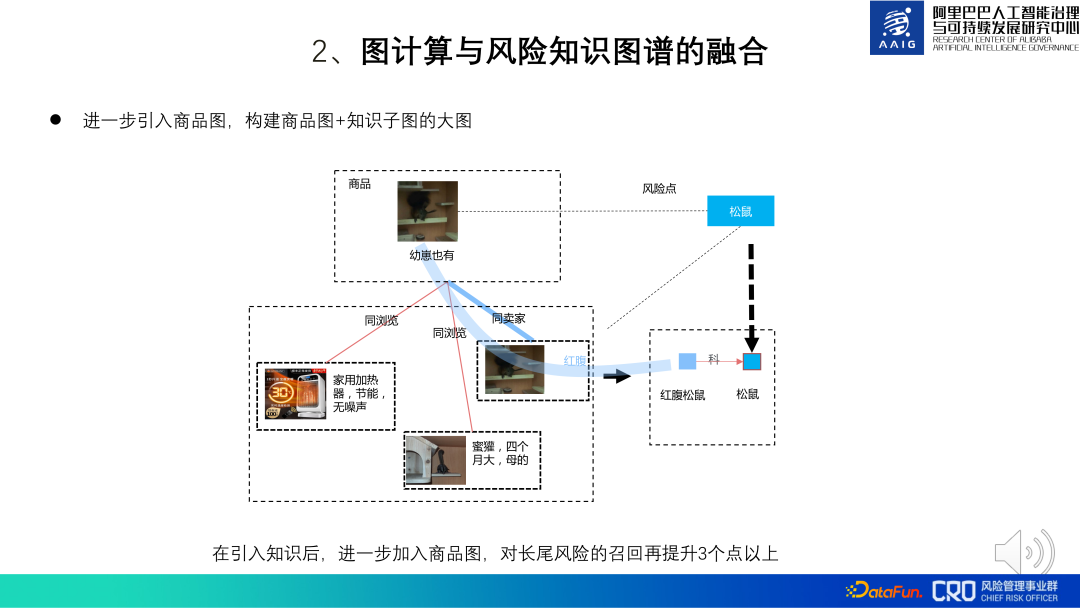
#これに基づいて、グローバル製品マップの導入も試みました。製品の内容がナレッジマップに直接関係しており、リスクが特定できない場合には、製品との関連性をさらに紹介することで判断を助けることができます。 「子グマ」と「アカハラリス」には強い知識がありません。一致関係はありますが、この商品は販売者の別の商品「アカハラリス」と「アカハラリス」の知識が一致するため、実際に販売しているのはアカハラリス(二次保護動物、販売禁止動物)です。実践では、知識推論を行うときに大規模な製品グラフ全体を導入すると、ロングテール リスクの想起が 3% 以上増加する可能性があることがわかっています。
4. 動的異種グラフのリスク管理実践
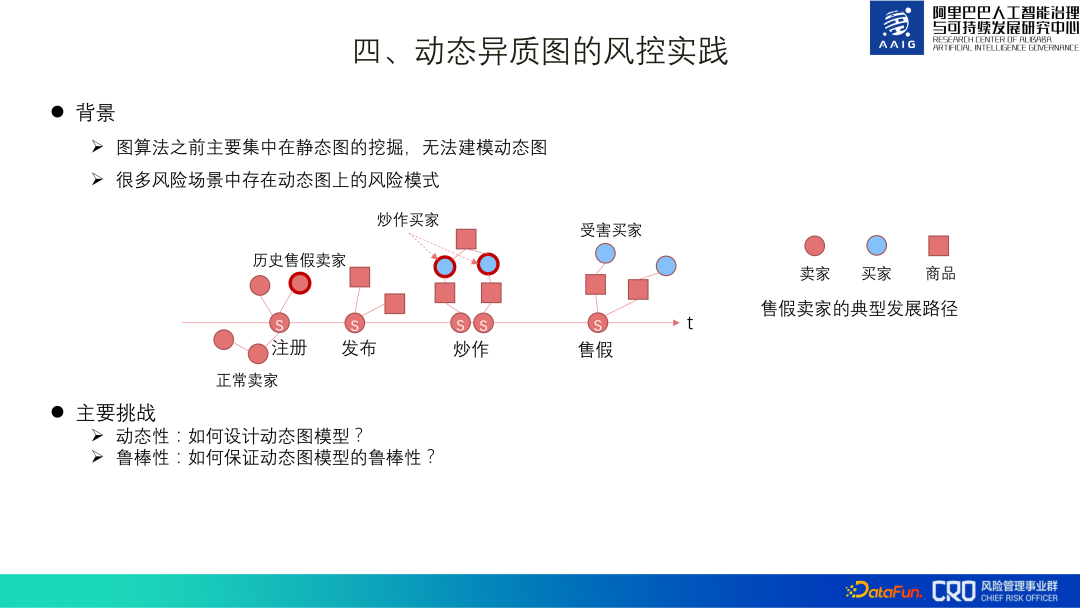
Before導入されたグラフ アルゴリズムは主に静的なグラフ マイニング アプリケーションですが、多くのリスク シナリオには動的なグラフ リスク パターンがあります。
たとえば、偽造品を販売する販売者は、最初に登録し、次に大量の製品をバッチでリリースし、トラフィックを集めるために宣伝し、その後すぐに販売します。この一連のアクションでは、時間の次元はリスクを特定する上で非常に重要であるため、動的グラフはグラフ アルゴリズムの探索と適用における重要な方向性でもあります。
#動的グラフの最大の課題は、適切なグラフ構造をどのように設計して検索するかです。一方、動的グラフは、元の異種グラフに基づいて時間次元を導入しており、たとえば、瞬間が 30 個ある場合、動的グラフのパラメータ (情報量) は異種グラフの 30 倍となり、大きなメリットが得られます。学習へのプレッシャー; 一方、リスクには敵対的な性質があるため、動的グラフは非常に堅牢である必要があります。
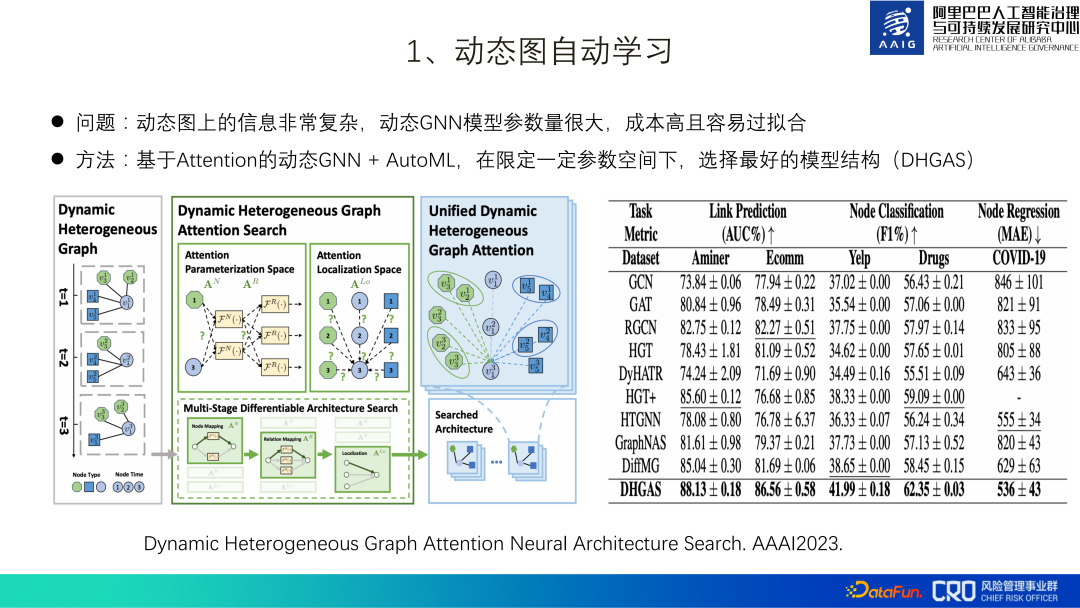
これに従って、動的 GNN ベースを提案しました。注意 AutoML は、特定のパラメーター空間の下で最適なモデル構造 (DHGAS) を選択します。このモデルの核心は、以下の図に示すように、自動学習を通じてモデル構造を最適化することです。 まず、動的グラフをさまざまな時点で異種グラフに分解し、さまざまな時点で異なる関数空間と異なるノードを設定することが推奨されます。空間 (N*T タイプ、N: ノード タイプ、T: 時間空間)、情報伝播のパス空間を表すために、異なる瞬間および異なるエッジ タイプに対して異なる関数空間も設定されます (R*Tタイプ、R: エッジ タイプ、T : 時間と空間)、そして最後に、ノードと近隣ノードが集約される場合の R*T*T 集約メソッドがあります (2 つの T はエッジの両端のノードのタイムスタンプです。
明らかに、全体の検索空間は巨大です。モデルが最適なネットワーク アーキテクチャを自動的に検索できるように、パラメーター空間を制限し、自動機械学習テクノロジを使用してスーパーネットを構築しようとしています。具体的な方法: N*T の関数空間の数を K_N に、R*T の関数空間のデータを K_R に、R*T*T のモジュール長を K_Lo に制限します (例: N=6、T=30) 、理論的には N*T=180 の関数空間で、実際の制限は K_N=10 です。
このアルゴリズムは現在、「偽販売者の特定」や「商品の販売を制限する悪質な販売者の特定」などのシナリオに実装されており、業界の主流のアルゴリズムと比較してSOTAの結果が得られています。詳細については論文[2]をご確認ください。
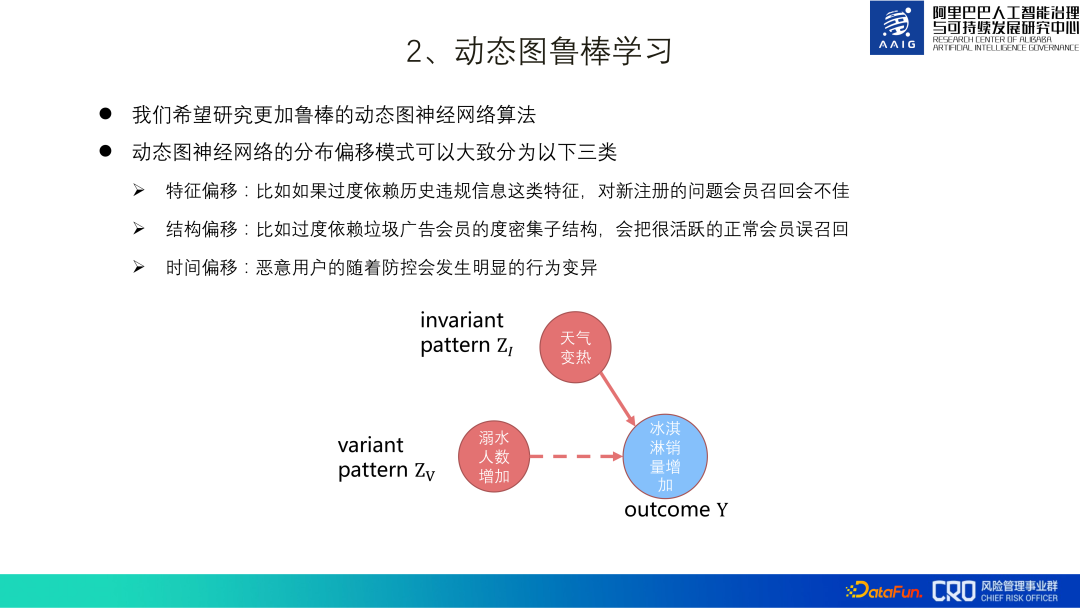
#2. 動的グラフの堅牢な学習
リスク対立の性質による、動的グラフィックスは堅牢性に強い必要があり、その本質は動的グラフィックスがいくつかの本質的なパターンを学習できることを願っています、たとえば、次の図のサブグラフの例の本質的なパターンは、アイスクリームの売り上げは天候によるものです 溺れる人が増えているのではなく、暑くなってきています。
堅牢な学習により、電子商取引リスク管理の動的グラフにおける分布シフトの問題のいくつかを解決できることを願っています:
(1) 機能オフセット: たとえば、過去の違反情報などの機能に依存しすぎると、新しく登録された問題のあるメンバーの再現率が低くなります。 ;
(2) 構造オフセット #: たとえば、次数が密な部分構造への過度の依存スパム広告メンバーの数が非常にアクティブになると、通常のメンバーが誤ってリコールされます;
(3) 時間オフセット:悪意のあるユーザーは予防および制御プロセスに従い、行動に重大な変化が生じます。
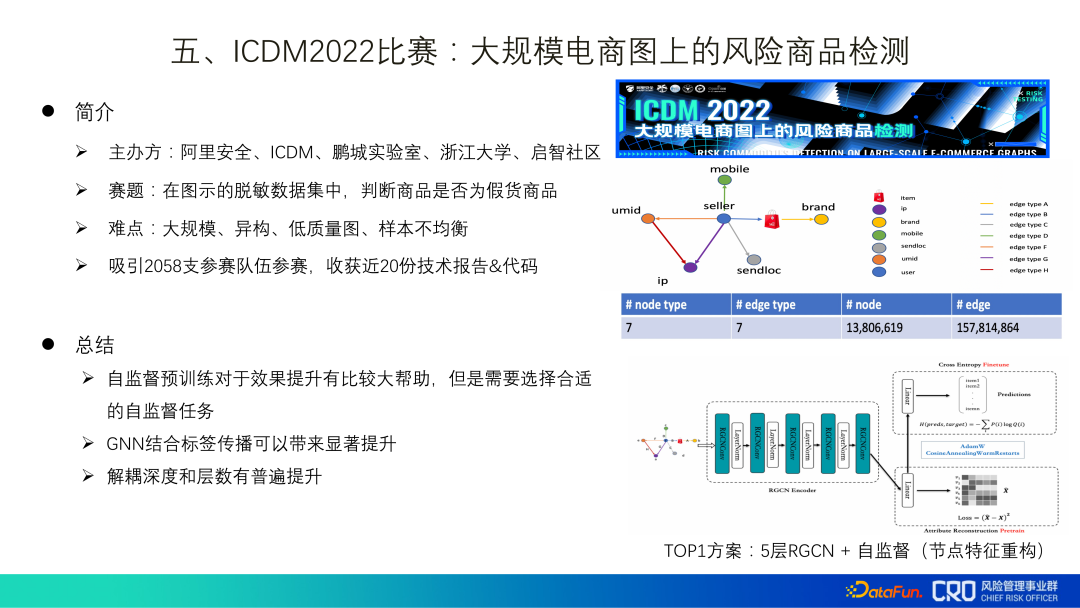
5. ICDM2022 コンペティション: 大規模な電子商取引マップ上の危険な製品の検出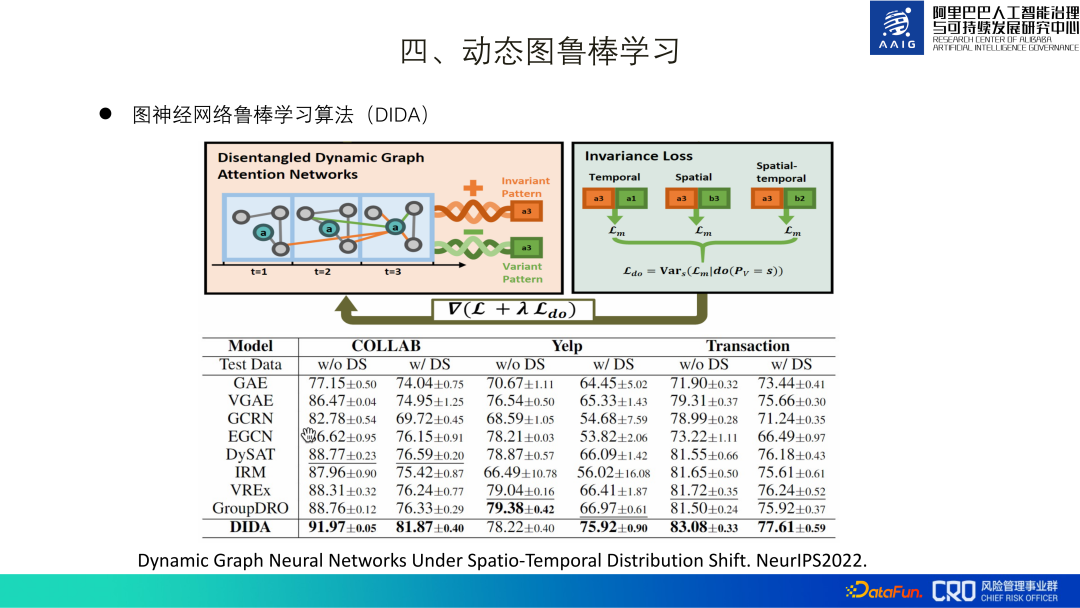
「ICDM2022 Competition: Risky Product Detection on Large-Scale E-commerce Graphs」は、当社が今年主催したアルゴリズム コンペティションであり、提供されるデータは実際のシナリオからの減感されたデータです。最後に、私は提出された技術コードとレポートからもいくつかのインスピレーションを得ました。
(1) 自己監督による事前トレーニングは、効果を向上させるのに非常に役立ちます。 、ただし、適切な自己教師タスクを選択する必要があります;
(2) GNN とラベル伝播を組み合わせると、大幅な改善がもたらされます。ラベル漏洩の懸念のため、データのこの部分は破棄されましたが、実際のデータで練習した後では明らかではありませんでした。その理由としては、現状のグラフネットワークは情報融合のみで推論ができていない、もしくは推論能力が弱いためと推測される;
(3) デカップリングの深さと推論レイヤー数は全体的に改善され、一度に伝播し、同時に複数回集約できるようになりました。
6. グラフ アルゴリズムの実装に関する概要と展望
(1) グラフ アルゴリズム フレームワーク/プラットフォーム: 技術と最良の技術を蓄積するためのグラフ アルゴリズム フレームワークが必要です。を実践し、テクノロジーの再利用性を向上させます。
(2) 半自動モデリング: モデリングの効率を向上させるには、データ レベルで、基礎となるリレーショナル メディアをクリーンにして要約することが最善です。 data 、一部のコンポーネント (MetaPath/MetaGraph 選択コンポーネント、グラフ サンプリング コンポーネント、ベクトル検索コンポーネントなど) をモデリング レベルで提供して、モデリング効率を向上させることができます。
# (3) 自動呼び出し: 入力サンプルのみに依存するグラフ アルゴリズムまたはグラフ モデルを自動的に呼び出すことができ、グラフ モデルを理解する必要はありません。グラフ アルゴリズムに詳しくない人にとっては便利です。リスク管理の学生は、ギャングの特定、製品の回収、リスク ユーザーの回収などのモデルの最適化と使用を実行します。
(4) 実稼働 (自己教師あり) グラフ表現: 元のモデリング方法に影響を与えることなく、モデルへの別個のモーダル入力として使用され、図が大幅に改善されました。アプリケーションシナリオ。

#フォローアップ作業の見通し:
( 1) 大規模グラフの自己教師あり表現学習。私たちは何千ものリスク モデルを持っていますが、その多くは上記のグラフ アルゴリズムを適用していないため、次のステップは大規模なグラフの自己教師あり表現を実行して、グラフ機能の適用範囲を拡大し、ビジネス成果の向上に役立てることです。この研究にはエンジニアリングとアルゴリズムの 2 つの課題があります: まず、エンジニアリングの観点からは、大規模な学習のために少なくとも数十億のノードと数百億のエッジが必要です。第 2 に、アルゴリズムの観点から、グラフ表現は一般的なものをカバーするだけでなく、また、汎用性が高く、さまざまなシナリオに適用できる高次のグラフ構造の特性を学ぶ必要もあります。
# (2) 特定のリスク管理シナリオにおけるグラフの推論機能を調査する 現在、グラフ アルゴリズムは知識と推論の融合に重点を置いています。能力は比較的弱く、リスクの高度な拮抗に対処することができません。客観的に見て、モデルには強力なインテリジェンスが必要なので、グラフの推論能力が非常に重要です。現時点では、Xianyu コミュニティの豊富なインタラクティブなシナリオとコンテンツを利用してアルゴリズムを探索する予定です。
# (3) 周波数領域の研究と動的異種グラフの解釈可能性のさらなる探索と実装。周波数領域研究の目的は、動的グラフにおけるグラフ構造の変化をより詳細に知ることです。解釈可能性は、アルゴリズムが本質的な特性を本当に学習しているかどうかを理解するのに役立ちます。一方で、アルゴリズムを改善するのに役立ち、他方で、アプリケーション実装のためにビジネス学生に提供することもできます。

また、上記の探索方向、特にグラフ推論の方向での学術協力も求めています。同時にグラフアルゴリズムの受講生も募集しておりますので、興味のある方はご連絡ください。
7. 参考文献
1. グラフ畳み込みネットワークによるスパムレビュー検出. CIKM2019 Best Applied Research Paper.
2. 動的異種グラフ アテンション ニューラル アーキテクチャ検索。AAAI2023.
3. 動的時空間分布シフト下のグラフ ニューラル ネットワークNeurIPS2022.
8. 質疑応答セッション
Q1: 他の分野のグラフ表現と比較して、リスク管理シナリオのグラフ表現の特別な課題は何ですか?
A1: 3 つの主な課題: 第一に、グラフ構造が貧弱で均一性率が低いこと、第二に、このシナリオにおけるグラフの堅牢性特に動的グラフでは、その分布ドリフトは依然として非常に深刻です。別の問題があります。黒いサンプルのリスク濃度は非常に低いです。これは 1:10 や 1:20 を意味しません。グラフのアルゴリズムにはいくつかのリスクがあります。濃度は上記を超えています。 1:1w なので、サンプルは非常に非常にアンバランスであり、これを解決する必要があります。
Q2: グラフ連合学習の現在のアルゴリズム モデルは何ですか? 業界に成熟したソリューションはありますか?グラフフェデレーションラーニングのアプリケーションや考慮事項はありますか?
A2: 現在は主に e コマースのシナリオで使用しています。もちろん e コマース以外のビジネスもいくつか行っていますが、これらのデータは当社独自のデータであり、まだリスク管理に直接使用できるため、フェデレーテッド ラーニングはまだ使用されていませんが、現在情報セキュリティのためにデータがカットおよび分離されており、異なるドメインのデータが存在するため、後でグラフフェデレーテッド ラーニングを使用する必要があります。接続して使用することはできないため、グラフ連合学習は、後で検討するアプリケーションの方向性になるはずです。
以上がアリババのリスク管理システムにおけるグラフアルゴリズムの実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7477
7477
 15
1377
52
77
11
19
32
15
1377
52
77
11
19
32

 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の最下層はマージ ソートを使用し、その複雑さは O(nlogn) で、クイック ソート、ヒープ ソート、安定したソートなど、さまざまなソート アルゴリズムの選択肢を提供します。
 人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能 (AI) と法執行機関の融合により、犯罪の予防と検出の新たな可能性が開かれます。人工知能の予測機能は、犯罪行為を予測するためにCrimeGPT (犯罪予測技術) などのシステムで広く使用されています。この記事では、犯罪予測における人工知能の可能性、その現在の応用、人工知能が直面する課題、およびこの技術の倫理的影響について考察します。人工知能と犯罪予測: 基本 CrimeGPT は、機械学習アルゴリズムを使用して大規模なデータセットを分析し、犯罪がいつどこで発生する可能性があるかを予測できるパターンを特定します。これらのデータセットには、過去の犯罪統計、人口統計情報、経済指標、気象パターンなどが含まれます。人間のアナリストが見逃す可能性のある傾向を特定することで、人工知能は法執行機関に力を与えることができます
 改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
01 今後の概要 現時点では、検出効率と検出結果の適切なバランスを実現することが困難です。我々は、光学リモートセンシング画像におけるターゲット検出ネットワークの効果を向上させるために、多層特徴ピラミッド、マルチ検出ヘッド戦略、およびハイブリッドアテンションモジュールを使用して、高解像度光学リモートセンシング画像におけるターゲット検出のための強化されたYOLOv5アルゴリズムを開発しました。 SIMD データセットによると、新しいアルゴリズムの mAP は YOLOv5 より 2.2%、YOLOX より 8.48% 優れており、検出結果と速度のバランスがより優れています。 02 背景と動機 リモート センシング技術の急速な発展に伴い、航空機、自動車、建物など、地表上の多くの物体を記述するために高解像度の光学式リモート センシング画像が使用されています。リモートセンシング画像の判読における物体検出
 Jiuzhang Yunji DataCanvas マルチモーダル大規模モデル プラットフォームの実践と考察
Oct 20, 2023 am 08:45 AM
Jiuzhang Yunji DataCanvas マルチモーダル大規模モデル プラットフォームの実践と考察
Oct 20, 2023 am 08:45 AM
1. マルチモーダル大型モデルの発展の歴史 上の写真は、1956 年に米国のダートマス大学で開催された最初の人工知能ワークショップです。このカンファレンスが人工知能開発の始まりとも考えられています。記号論理学の先駆者たち(前列中央の神経生物学者ピーター・ミルナーを除く)。しかし、この記号論理理論は長い間実現できず、1980 年代と 1990 年代に最初の AI の冬の到来さえもたらしました。最近の大規模な言語モデルが実装されて初めて、ニューラル ネットワークが実際にこの論理的思考を担っていることがわかりました。神経生物学者ピーター ミルナーの研究は、その後の人工ニューラル ネットワークの開発に影響を与えました。彼が参加に招待されたのはこのためです。このプロジェクトでは。
 58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
1. 58 Portraits プラットフォーム構築の背景 まず、58 Portraits プラットフォーム構築の背景についてお話ししたいと思います。 1. 従来のプロファイリング プラットフォームの従来の考え方ではもはや十分ではありません。ユーザー プロファイリング プラットフォームを構築するには、複数のビジネス分野からのデータを統合して、ユーザーの行動や関心を理解するためのデータ マイニングも必要です。最後に、ユーザー プロファイル データを効率的に保存、クエリ、共有し、プロファイル サービスを提供するためのデータ プラットフォーム機能も必要です。自社構築のビジネス プロファイリング プラットフォームとミドルオフィス プロファイリング プラットフォームの主な違いは、自社構築のプロファイリング プラットフォームは単一のビジネス ラインにサービスを提供し、オンデマンドでカスタマイズできることです。ミッドオフィス プラットフォームは複数のビジネス ラインにサービスを提供し、複雑な機能を備えていることです。モデリングを提供し、より一般的な機能を提供します。 2.58 中間プラットフォームのポートレート構築の背景のユーザーのポートレート 58
 SOTA をリアルタイムで追加すると、大幅に増加します。 FastOcc: より高速な推論と展開に適した Occ アルゴリズムが登場しました。
Mar 14, 2024 pm 11:50 PM
SOTA をリアルタイムで追加すると、大幅に増加します。 FastOcc: より高速な推論と展開に適した Occ アルゴリズムが登場しました。
Mar 14, 2024 pm 11:50 PM
上記と著者の個人的な理解は、自動運転システムにおいて、認識タスクは自動運転システム全体の重要な要素であるということです。認識タスクの主な目的は、自動運転車が道路を走行する車両、路側の歩行者、運転中に遭遇する障害物、道路上の交通標識などの周囲の環境要素を理解して認識できるようにすることで、それによって下流のシステムを支援できるようにすることです。モジュール 正しく合理的な決定と行動を行います。自動運転機能を備えた車両には、通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなど、さまざまな種類の情報収集センサーが装備されており、自動運転車が正確に認識し、認識できるようにします。周囲の環境要素を理解することで、自動運転車が自動運転中に正しい判断を下せるようになります。頭
