| 23
| redis-cli -p 6379
|
2. 主従関係の設定
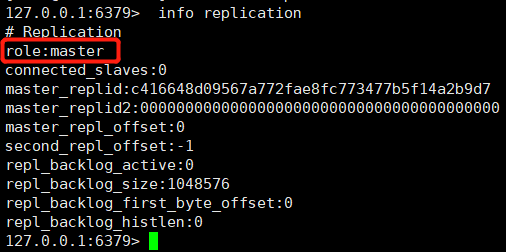
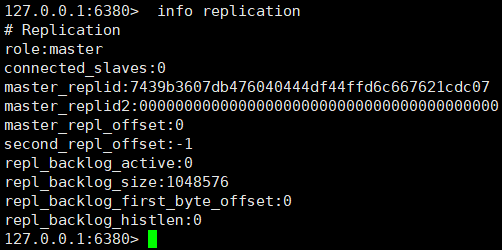
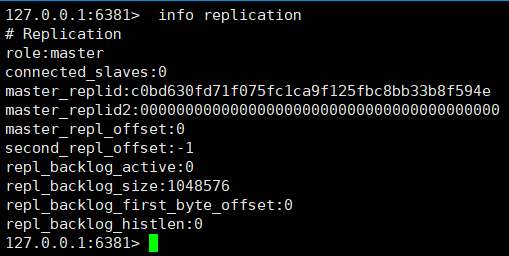
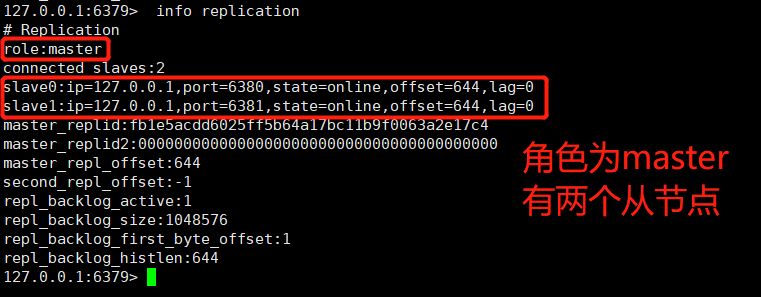
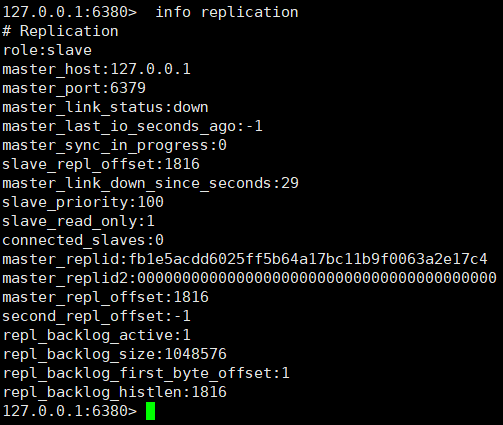
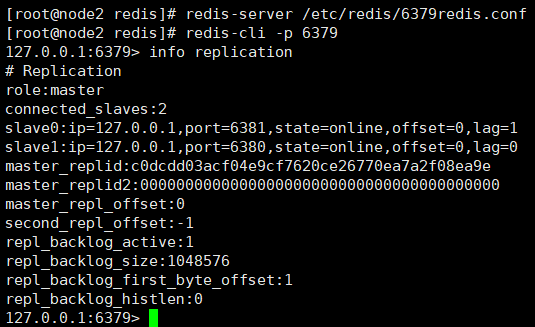
①、情報レプリケーションコマンドによるノードロールの表示

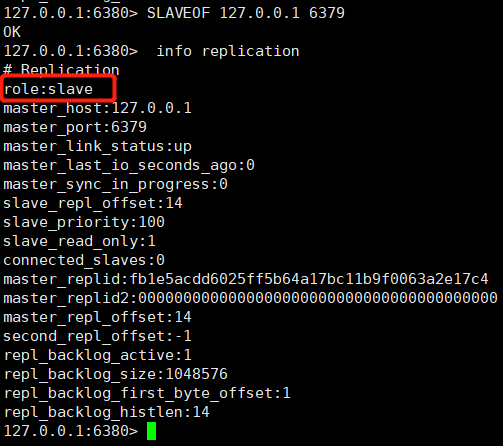
これら 3 つのノードはすべてマスターの役割を果たしていることがわかりました。ノード 6380 と 6381 をスレーブ ノードの役割に変換するにはどうすればよいですか?
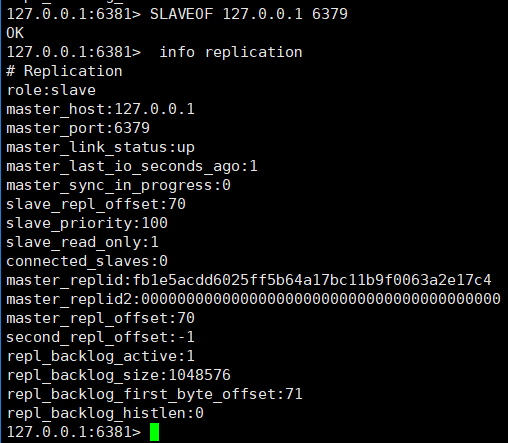
②. ポート 6380 とポート 6381 を選択し、コマンドを実行します: SLAVEOF 127.0.0.1 6379
6379 ノード情報を見てみましょう。
サービスを再起動すると、コマンドで設定した主従関係は無効になります。この関係は、redis.conf ファイルを構成することで永続的に保存できます。
3. マスターとスレーブの関係をテストします
①.増分レプリケーション
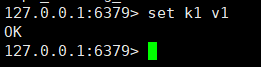
マスター ノードは set k1 v1 コマンドを実行します。 k1を取得しますか?
上の写真を見ると、取得できることがわかります。
②、フルコピー
SLAVEOF 127.0.0.1 6379を実行すると、マスターノード6379の前にキーがまだある場合、コマンド実行後、スレーブノードがノードは前の情報をコピーします。すべての情報をコピーしましたか?
答えは「はい」です。テスト結果はここには掲載しません。
③. マスターとスレーブの読み取りと書き込みの分離
マスターノードは書き込みコマンドを実行でき、スレーブノードは書き込みコマンドを実行できますか?
この理由は、設定ファイル 6381redis.conf のスレーブ読み取り専用の設定です。
Ifこれを no に変更すると、書き込みコマンドを実行できるようになります。
ただし、スレーブノード書き込みコマンドのデータはスレーブノードやマスターノードからは取得できません。
④. マスターノードのダウンタイム
マスターノードのマスターがハングアップした場合、2 つのスレーブノードの役割は変わりますか?
上の図から、マスター ノード Master がハングアップした後、スレーブ ノードの役割は変わらないことがわかります。 。
⑤. マスターノードダウン後の復旧
マスターノードMasterがハングアップしたら、すぐにホストMasterを起動してください。マスターノードはまだ役割を果たしていますか?マスター?
つまり、マスター ノードがハングアップした後、再起動してマスター ノードとしての役割を再開します。
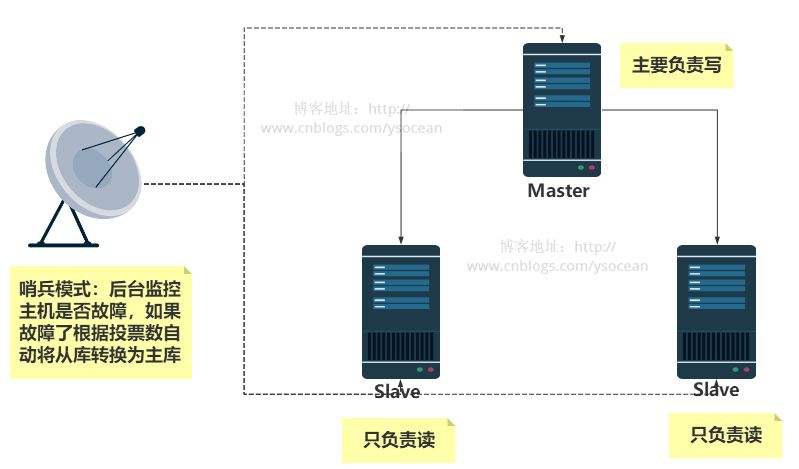
4. Sentinel モード
前の設定では、マスター ノードは 1 つだけあり、マスター ノードがハングアップすると、スレーブ ノードはマスター ノードのタスクを引き継ぐことができなくなり、システム全体が実行できなくなります。ここからセンチネル モードが誕生しました。スレーブ ノードが自動的にマスター ノードの役割を引き継ぎ、マスター ノードのダウンタイムの問題を解決できるからです。
セントリー モードは、redis が期待どおりに適切に実行されているかどうかを時々監視します (少なくともマスター ノードが存在することを確認するため)。ホストに問題がある場合、セントリーは自動的にホストを削除します。ホスト配下のスレーブ マシンを新しいホストとして設定し、他のスレーブが新しいホストとマスター/スレーブ関係を確立できるようにします。
Sentinel モードの構築手順:
①設定ファイルディレクトリに、名前を間違えないように新しい Sentinel.conf ファイルを作成し、設定を行います。対応するコンテンツ
1 |
センチネル モニター 監視対象マシンの名前 (自分で名前を付けます) IP アドレス ポート番号 投票数
|
監視対象の名前、IP アドレス、ポート番号、投票数をそれぞれ設定します。マスター マシンがダウンした場合、スレーブ マシンは誰がマスター マシンとして引き継ぐかを決定するために投票する必要があります。投票数が 1 に達した場合、マスター マシンになるには十分ではありません。マスターになるには 1 を超える必要があります。 machine.
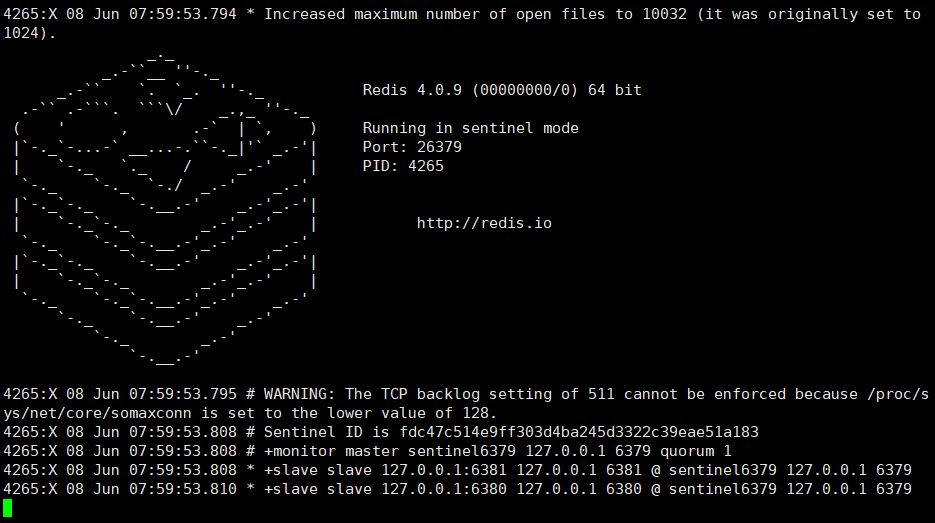
②.sentinelを起動
1 |
##redis-sentinel / etc/redis/sentinel.conf |
起動インターフェイス:
次に、ホスト 6379 を強制終了し、スレーブ ノードでどのような変化が起こるかを確認します。
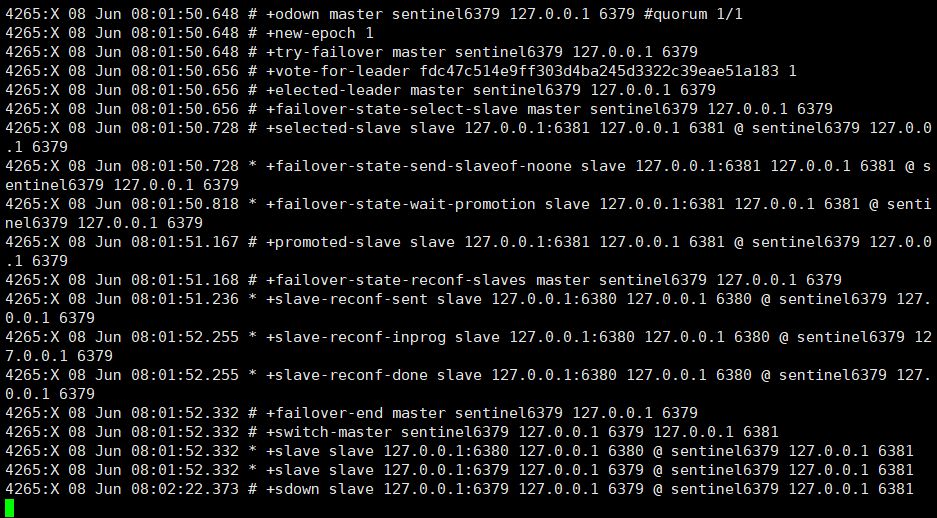
マスター ノードを強制終了した後、バックグラウンド印刷ログを確認したところ、6381 人がマスター ノードになることに投票したことがわかりました。
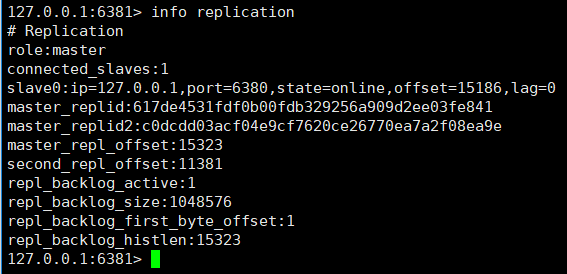
このとき、スレーブノード 6381 のノード情報を確認します。
6381 ノードは自動的にスレーブノード 6381 になります。マスターノード。
PS: Sentinel モードにも単一障害点の問題があります。Sentinel マシンがハングアップすると、監視は不可能になります。解決策は、Sentinel もクラスターを確立することです。Redis Sentinel モードはクラスターをサポートします。
5. マスター/スレーブのレプリケーション原理
Redis のレプリケーション機能には、同期 (sync) とコマンド伝播 (コマンド伝播) の 2 つの操作が含まれます。
①、旧バージョンの同期
スレーブノードがSLAVEOFコマンドを発行して、スレーブサーバーにマスターサーバーのコピーを要求すると、スレーブサーバーは、 SYNC コマンドをマスターサーバーに送信します。このコマンドを実行する手順: 1. スレーブ サーバーからマスター サーバー
に SYNC コマンドを送信します。 2. SYNC コマンドを受信したマスター サーバーは、BGSAVE コマンドを実行し、バックグラウンドで RDB ファイルを生成し、バッファには最初から実行されたすべての書き込みコマンドが記録されます。
3. マスターサーバーのBGSAVEコマンドが完了すると、マスターサーバーはBGSAVEコマンドで生成したRDBファイルをスレーブサーバーに送信し、スレーブサーバーは RDB ファイルを受信し、サーバーのステータスを RDB ファイルに記録されたステータスに更新します。
4. マスターサーバーもバッファ内のすべての書き込みコマンドをスレーブサーバーに送信し、スレーブサーバーは対応するコマンドを実行します。
②. コマンドの伝播 同期操作が完了すると、マスターサーバーはそれに応じてコマンドを変更します。マスターサーバーが不整合になります。
マスター サーバーとスレーブ サーバーのステータスの一貫性を保つために、マスター サーバーはスレーブ サーバー上でコマンド伝播操作を実行する必要があります。マスター サーバーは独自の書き込みコマンドをスレーブ サーバーに送信します。実行のために。スレーブ サーバーが対応するコマンドを実行した後も、マスター サーバーとスレーブ サーバーのステータスは一貫した状態を保ちます。
概要: 同期操作とコマンド伝播機能を通じて、マスター/スレーブの一貫性機能を十分に保証できます。
しかし、問題が考えられます。マスター サーバーとの同期中にスレーブ サーバーが突然切断され、この時点でマスター サーバーが書き込み操作を実行すると、スレーブ サーバーは接続を復元します。マスター サーバーから RDB ファイルを再生成し、スレーブ サーバーにロードする必要があります。一貫性は確保できますが、実際には、接続が切断される前はマスター サーバーとスレーブ サーバーの状態は一貫しています。不整合はスレーブ サーバーが切断されたときに発生します。マスターサーバーはいくつかの書き込みコマンドを実行しましたが、スレーブサーバーが接続を復元した後、RDB スナップショット全体ではなく書き込みコマンドのみを切断できますか?
同期操作は、実際には非常に時間のかかる操作です。マスター サーバーは、まず BGSAVE コマンドで RDB ファイルを生成し、次にそのファイルをスレーブ サーバーに送信する必要があります。スレーブ サーバーはファイルをロードしますが、ロード中、スレーブ サーバーは他のコマンドを処理できません。
この問題を解決するために、Redis はバージョン 2.8 以降、SYNC コマンドの代わりに新しい同期コマンド
PSYNC を使用しています。このコマンドの部分再同期機能は、切断後の再レプリケーションの効率の問題を解決するために使用されます。つまり、スレーブサーバーが切断後にマスターサーバーに再接続するとき、マスターサーバーは切断後に実行された書き込みコマンドをスレーブサーバーに送信するだけであり、スレーブサーバーはマスターを維持するためにこれらの書き込みコマンドを受信して実行するだけで済みます。 -スレーブの一貫性。 6. マスター/スレーブ レプリケーションの欠点
マスター/スレーブ レプリケーションはマスター ノードの単一障害点の問題を解決しますが、すべての書き込み操作はマスター ノード上で実行され、マスター ノードに同期されます。スレーブ ノードの場合、同期にはある程度の遅延が発生します。システムが非常にビジーな場合、遅延の問題はさらに深刻になり、スレーブ ノードの数が増えるほどさらに深刻になります。

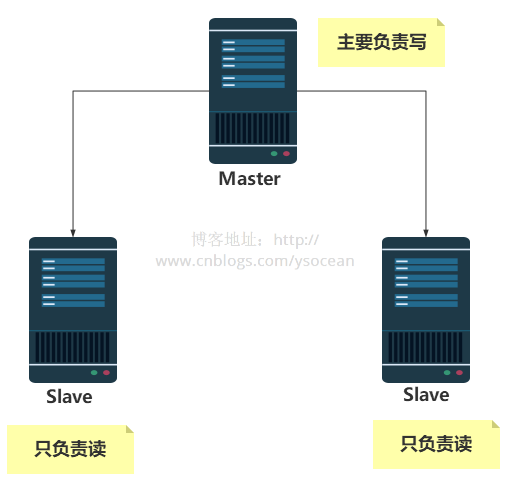





 6380redis.confを変更し、6381Redis.confを一度設定すれば設定は完了です。
6380redis.confを変更し、6381Redis.confを一度設定すれば設定は完了です。  コマンドを使用して、Redis が開始されているかどうかを確認します。
コマンドを使用して、Redis が開始されているかどうかを確認します。  次に、次のように 3 つの Redis クライアントを入力します。コマンドターミナル:
次に、次のように 3 つの Redis クライアントを入力します。コマンドターミナル: 


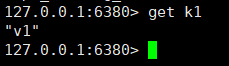
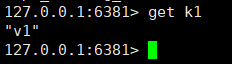


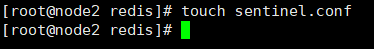















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



