

Redis クラスターのマスター/スレーブ モードを構成する方法


#1. クラスターが必要な理由は何ですか?
実際の開発では、次の理由により、エンジニアリング プロジェクトで Redis を 1 つだけ使用することはできません。
2. マスター/スレーブ モードはじめに( 1) 構造の観点から見ると、単一の Redis サーバーには単一障害点のリスクがあり、1 つのサーバーがすべてのリクエストの負荷を負担する必要があるため、比較的高い負荷がかかります
#(2) より 容量的には、単一の Redis サーバーのメモリ容量には限りがあり、Redis サーバーのメモリ容量が 256G であっても、すべてのメモリを Redis ストレージ メモリとして使用することはできません。単一の Redis サーバーで使用される容量は 20G を超えてはなりません。
(3) 単一の Redis サーバーの読み取りおよび書き込みパフォーマンスには限界があり、クラスターを使用することで読み取りおよび書き込み機能を向上させることができます。
現在、Redis には 3 つのクラスター モードがあります。モード 、センチネル モード、クラスター モード; マスター スレーブ モードは 3 つのモードの中で最も単純です。マスター スレーブ レプリケーションでは、1 つの Redis サーバーのデータを他の Redis サーバーにコピーすることを指します。最初のノードはマスター ノード (マスター/リーダー) と呼ばれ、2 番目のノードはスレーブ ノード (スレーブ/フォロワー) と呼ばれます。
注:
(1) データ レプリケーションは一方向であり、マスター ノードからスレーブへのみです。ノードノード。マスターは主に書き込み用、スレーブは主に読み取り用です。 (2) デフォルトでは、各 Redis サーバーはマスター ノードです;
(3) マスター ノードは複数のスレーブ ノードを持つことができます (またはスレーブ ノードを持たないこともできます) が、スレーブ ノードはマスター ノードを 1 つだけ持つことができます。 。
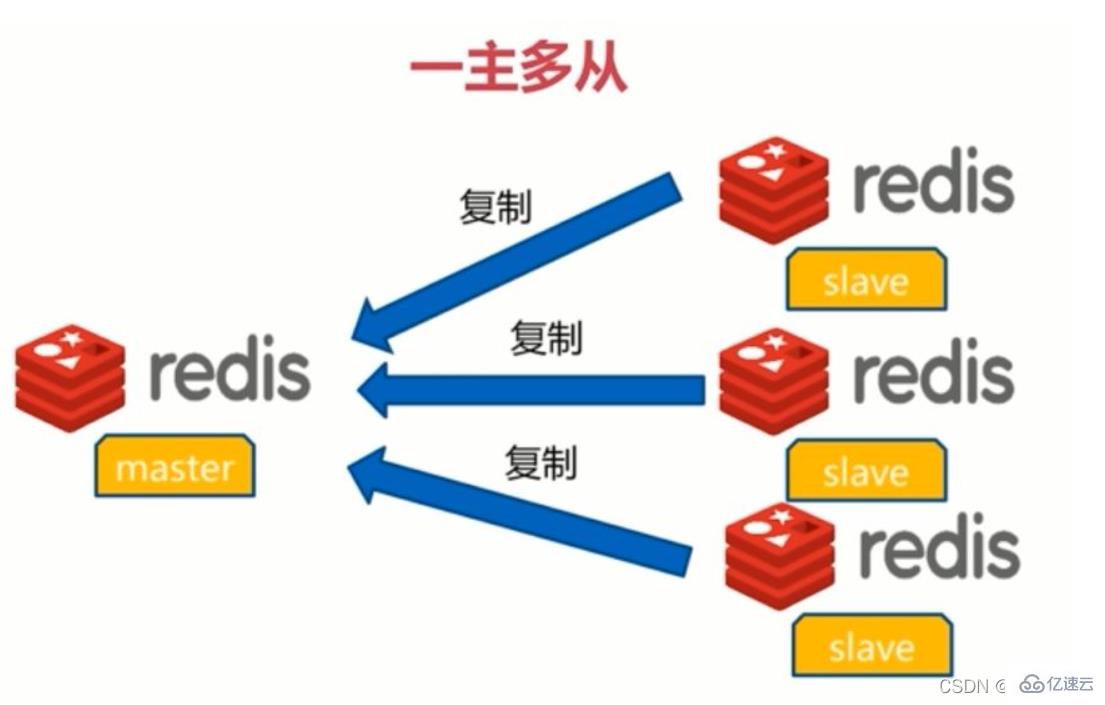
1.たとえば、当社の電子商取引 Web サイトで、データ冗長化: マスタスレーブレプリケーションによりデータ冗長化を実現 Hotバックアップは、永続化以外のデータ冗長化方法です。 2.
障害回復: マスター ノードで問題が発生した場合、スレーブ ノードは迅速な障害回復を実現するためのサービスを提供できます。これは実際には一種のサービスの冗長化です。 3.
高可用性の基礎 (クラスター) : マスター/スレーブ レプリケーションは依然としてセンチネルとクラスターの実装の基礎であるため、マスター/スレーブ レプリケーションは Redis の高可用性の基礎です。 4.
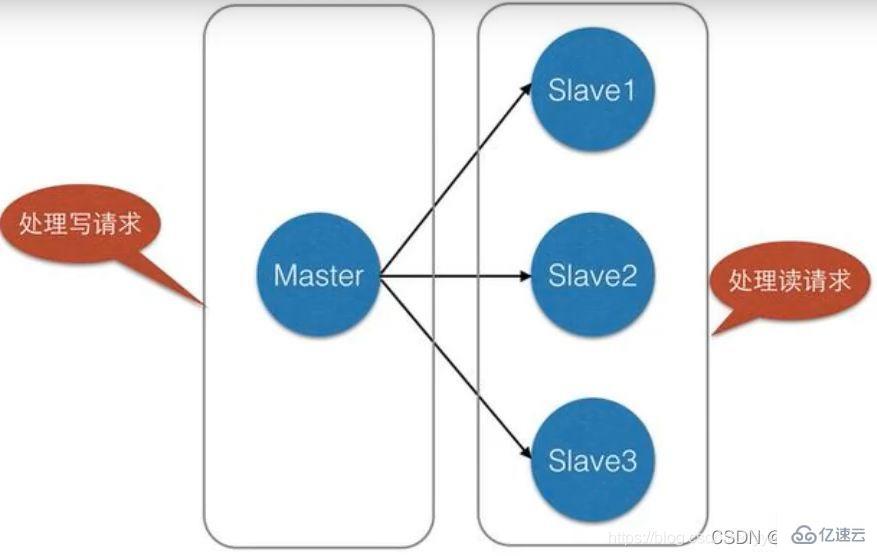
ロードバランシング: マスター/スレーブレプリケーションに基づいて、読み取り/書き込み分離と組み合わせることで、マスターノードは書き込みサービスを提供し、スレーブノードは読み取りサービスを提供できます(つまり、 Redis データを書き込む場合、アプリケーションはマスター ノードに接続し、Redis データを読み取る場合、アプリケーションはスレーブ ノードに接続します)サーバーの負荷を共有します。特に、書き込みが少なく読み取りが多いシナリオでは、複数のスレーブ ノードを通じて読み取り負荷を共有します。 Redis サーバーの同時実行性を大幅に向上させることができます。
商品をアップロードする必要があるのは 1 回だけですが、ユーザーは複数回閲覧できる ということがわかります。 , "write Readless and read more" この場合、マスター/スレーブ レプリケーションを使用して読み取りと書き込みを分離できます,プレッシャーを軽減しますサーバー上で #:
3. マスター/スレーブ クラスターを構築します
3.1. 準備作業
1. コピー 3 つの構成ファイル (元の名前: redis.conf) が、redis79.conf、redis80.conf、redis81.conf に名前変更されました。

# (1) redis79.conf
# を変更します。##ポート番号を変更します
port 6379
バックグラウンドで実行するように設定します
daemonize:yes
ログの名前を設定しますfile
logfile “6379.log"
db ファイル名を設定します
dbfilename dump6379.rdb
#(2) redis80.conf を変更します
#ポート番号を変更します port 6380
daemonize:yes
pidfile /var/run/redis_6380.pid
logfile “6380.log"
dbfilename dump6380.rdb
## ポート番号を変更します
port 6381
daemonize:yes
pidfile /var/run/redis_6381.pid
logfile “6381.log"
dbfilename dump6381.rdb
これらの属性の機能は次のとおりです。
pid(ポート ID): プロセスの ID が記録され、ファイルにはロック。プログラムが複数回起動されるのを防ぎます。
logfile: ログ ファイルの場所をクリアしますdbfilename: dumpxxx.file #永続ファイルの場所 port: プロセスが占有しているポート番号
3.2、搭建一主二从
启动Redis服务器
注意:默认情况下,每台Reids服务器都是主节点,而我们要搭建主从只需要在从机那本搭建即可。
现在分别启动redis79,redis80,redis81服务器。
redis-server redis79.conf redis-server redis80.conf redis-server redis81.conf
使用以下命令,查看是否启动成功:
ps -ef|grep redis

打开三个客户端窗口,分别对应操作三个Redis服务器。
输入命令:
注意要指定端口,才知道我们要打开哪一个Redis。
窗口一:
redis-cli -p 6379
窗口二:
redis-cli -p 6380
窗口三:
redis-cli -p 6381
设置主从关系
我们将redis79设置为主节点,而将redis80和redis81设置为从结点。
配置主机的IP地址和端口号,相当于想认其为自己的老大。
redis80:
#SLAVEOF IP地址 端口 127.0.0.1:6380> slaveof 127.0.0.1 6379 OK
redis81:
#SLAVEOF IP地址 端口 127.0.0.1:6381> slaveof 127.0.0.1 6379 OK
这个时候,我们在从机使用INFO命令就可以查看主从关系了:
info replication
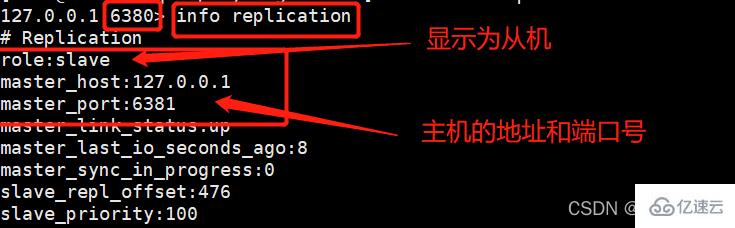
而此时我们去主机redis79中使用同样的命令进行查看:
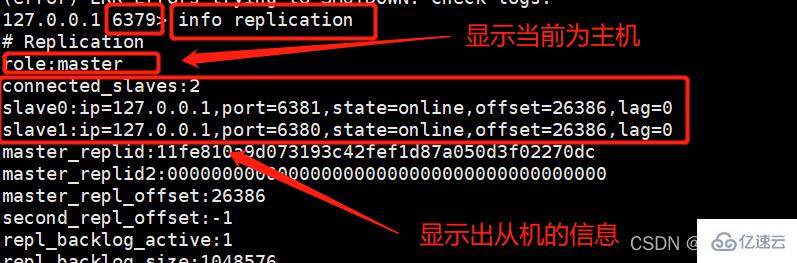
现在我们的一主二从的关系就成功搭建好了!
提示:如果要将从机变成主机,我们只需要在从机执行以下命令,即可让自己变为主机。
SLAVEOF no one
四、知识讲解
知识一
主机可以进行读写操作,而从机只能读操作。
注意:主机中的所有信息和数据,都会自动被从机保存。
主机:
127.0.0.1:6379> set key1 v1 OK 127.0.0.1:6379> get key1 "v1"
从机:
127.0.0.1:6380> get key1 "v1" 127.0.0.1:6380> set key2 v2 #进行写操作就会报错,提示从机只能进行读操作 (error) READONLY You can't write against a read only replica.
知识二
主机如果宕机了,从机依旧可以读取到主机宕机前的数据,但仍然没有写操作,如果主机恢复过来了,从机依旧可以获取到主机写的数据。
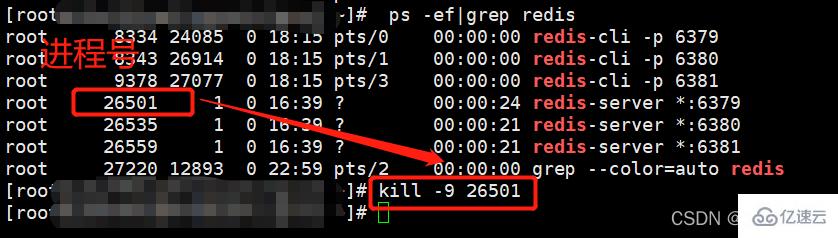
(1)停止主机进程(演示主机宕机了)
停止进程的命令:
kill -9 pid #pid为redis进程号
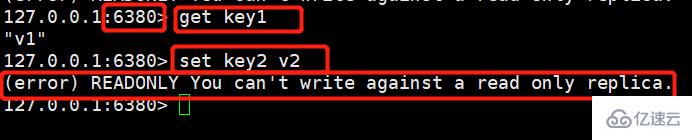
(2)从机获取宕机前主机写入的数据
可以发现,能够顺利拿到,但仍然是无法进行写操作的。
(3)恢复主机
redis-server redis79.conf
(4)主机重新写入数据,从机获取最新数据。
主机写入数据:
127.0.0.1:6379> set k2 yixin OK
从机读取最新数据:
127.0.0.1:6380> get k2 "yixin"
知识三
两种配置方式下的从机断开情况
a、命令行设置主从关系
从机断开了,其重新连接后变为主机,能拿到断开之前的数据,但拿不到主机新写入的值,如果重新设置主从关系,就可以拿到主机全部的数据了。
(1)停止从机进程。
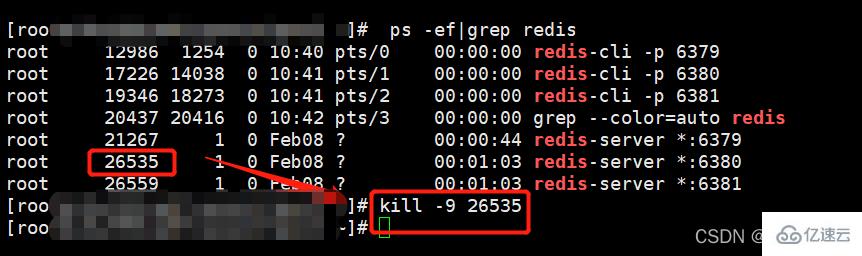
(2)主机写入新数据。
127.0.0.1:6379> set k3 new OK
(3)重新启动从机服务器。
redis-server redis80.conf
(4)尝试获取从机宕机前主机写入的数据,发现可以拿到。
127.0.0.1:6380> get k1 "v1"
(5)尝试获取从机宕机期间主机写入的数据,发现无法拿到了。
127.0.0.1:6380> get k3 (nil)
此次我们可以进行查看主从关系,由于是命令行配置的,所以重启之后又变回主机了。
127.0.0.1:6380> info replication # Replication role:master connected_slaves:0
(6)如果要拿到主机的所有数据,只要执行以下命令重新配置主从关系就可以了。
slaveof 127.0.0.1 6379
b、配置文件设置的主从关系
从机断开后,重新连接,也是可以拿到主机的全部数据的。
(1)修改配置文件redis80.conf,添加主从关系。
#指定主机的ip与port slaveof 127.0.0.1 6379
(2)主机添加新数据
127.0.0.1:6379> set k5 hello OK
(3)重新启动redis80服务器。
redis-server redis80.conf
(4)获取从机宕机期间主机新写入的数据,发现现在可以顺利拿到了。
127.0.0.1:6380> get k5 "hello"
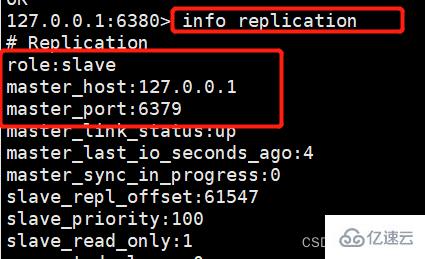
我们来查看6380的主从关系,可以发现在重启的时候就已经设置好主从关系了。
五、复制原理
(1)Slave 启动成功连接到 Master 后会发送一个sync同步命令
(2)Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
(3)全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
(4)增量复制:Master 继续将新的所有收集到的修改命令依次传给slave,完成同步。
注意:只要是重新连接master,一次完全同步(全量复制)将被自动执行! 我们的数据一定可以在从机中看到。
六、主从模式的优缺点
优点
(1)同一个Master可以同步多个Slaves。
(2)Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力。因此我们可以将Redis的Replication架构视为图结构。
(3)Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求。
(4)Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据。
(5)为了分载Master的读操作压力,Slave服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成。即便如此,系统的伸缩性还是得到了很大的提高。
(6)Master可以将数据保存操作交给Slaves完成,从而避免了在Master中要有独立的进程来完成此操作。
(7)支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点
(1) Redis 主从模式不具备自动容错和恢复功能,如果主节点宕机,Redis 集群将无法工作,此时需要人为干预,将从节点提升为主节点。
(2) 如果主机宕机前有一部分数据未能及时同步到从机,即使切换主机后也会造成数据不一致的问题,从而降低了系统的可用性。
(3) 因为只有一个主节点,所以其写入能力和存储能力都受到一定程度地限制。
(4) 在进行数据全量同步时,若同步的数据量较大可能会造卡顿的现象。
以上がRedis クラスターのマスター/スレーブ モードを構成する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7322
7322
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29

 Windows 11 10.0.22000.100 のインストール時の 0x80242008 エラーの解決策
May 08, 2024 pm 03:50 PM
Windows 11 10.0.22000.100 のインストール時の 0x80242008 エラーの解決策
May 08, 2024 pm 03:50 PM
1. [スタート]メニューを起動し、[cmd]と入力し、[コマンドプロンプト]を右クリックし、[管理者として実行]を選択します。 2. 次のコマンドを順番に入力します (注意してコピーして貼り付けてください): SCconfigwuauservstart=auto、Enter キーを押す SCconfigbitsstart=auto、Enter キーを押す SCconfigcryptsvcstart=auto、Enter キーを押す SCconfigtrustedinstallerstart=auto、Enter キーを押す SCconfigwuauservtype=share、Enter キーを押す netstopwuauserv 、enter netstopcryptS を押す
 PHP機能のボトルネックを分析し、実行効率を向上
Apr 23, 2024 pm 03:42 PM
PHP機能のボトルネックを分析し、実行効率を向上
Apr 23, 2024 pm 03:42 PM
PHP 関数のボトルネックはパフォーマンスの低下につながります。これは、ボトルネック関数を特定し、パフォーマンス分析ツールを使用するという手順で解決できます。結果をキャッシュして再計算を減らします。タスクを並列処理して実行効率を向上させます。文字列の連結を最適化し、代わりに組み込み関数を使用します。カスタム関数の代わりに組み込み関数を使用します。
 Golang API のキャッシュ戦略と最適化
May 07, 2024 pm 02:12 PM
Golang API のキャッシュ戦略と最適化
May 07, 2024 pm 02:12 PM
GolangAPI のキャッシュ戦略により、パフォーマンスが向上し、サーバーの負荷が軽減されます。一般的に使用される戦略は、LRU、LFU、FIFO、TTL です。最適化手法には、適切なキャッシュ ストレージの選択、階層型キャッシュ、無効化管理、監視とチューニングが含まれます。実際には、データベースからユーザー情報を取得する API を最適化するために LRU キャッシュが使用されます。それ以外の場合は、データベースからデータを取得した後にキャッシュを更新できます。
 erlang と golang ではどちらのパフォーマンスが優れていますか?
Apr 21, 2024 am 03:24 AM
erlang と golang ではどちらのパフォーマンスが優れていますか?
Apr 21, 2024 am 03:24 AM
Erlang と Go にはパフォーマンスの違いがあります。 Erlang は同時実行性に優れていますが、Go はより高いスループットとより高速なネットワーク パフォーマンスを備えています。 Erlang は高い同時実行性を必要とするシステムに適しており、Go は高スループットと低遅延を必要とするシステムに適しています。
 PHP 開発におけるキャッシュ メカニズムとアプリケーションの実践
May 09, 2024 pm 01:30 PM
PHP 開発におけるキャッシュ メカニズムとアプリケーションの実践
May 09, 2024 pm 01:30 PM
PHP 開発では、キャッシュ メカニズムにより、頻繁にアクセスされるデータがメモリまたはディスクに一時的に保存され、データベース アクセスの数が削減され、パフォーマンスが向上します。キャッシュの種類には主にメモリ、ファイル、データベース キャッシュが含まれます。キャッシュは、組み込み関数またはサードパーティのライブラリ (cache_get() や Memcache など) を使用して PHP に実装できます。一般的な実用的なアプリケーションには、データベース クエリ結果をキャッシュしてクエリ パフォーマンスを最適化したり、ページ出力をキャッシュしてレンダリングを高速化したりすることが含まれます。キャッシュ メカニズムにより、Web サイトの応答速度が効果的に向上し、ユーザー エクスペリエンスが向上し、サーバーの負荷が軽減されます。
 PHP 配列のページネーションで Redis キャッシュを使用するにはどうすればよいですか?
May 01, 2024 am 10:48 AM
PHP 配列のページネーションで Redis キャッシュを使用するにはどうすればよいですか?
May 01, 2024 am 10:48 AM
Redis キャッシュを使用すると、PHP 配列ページングのパフォーマンスを大幅に最適化できます。これは、次の手順で実現できます。 Redis クライアントをインストールします。 Redisサーバーに接続します。キャッシュ データを作成し、データの各ページをキー「page:{page_number}」を持つ Redis ハッシュに保存します。キャッシュからデータを取得し、大規模な配列での高コストの操作を回避します。
 Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法_Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法
May 08, 2024 pm 05:10 PM
Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法_Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法
May 08, 2024 pm 05:10 PM
まず、システム言語を簡体字中国語表示に設定して再起動する必要があります。もちろん、以前に表示言語を簡体字中国語に変更したことがある場合は、この手順をスキップできます。次に、レジストリ regedit.exe の操作を開始し、左側のナビゲーション バーまたは上部のアドレス バーで HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsLanguage に直接移動し、InstallLanguage キーの値と Default キーの値を 0804 に変更します (英語に変更する場合)。まずシステムの表示言語を en-us に設定し、システムを再起動してから、すべてを 0409 に変更します) この時点でシステムを再起動する必要があります。
 navicat は redis に接続できますか?
Apr 23, 2024 pm 05:12 PM
navicat は redis に接続できますか?
Apr 23, 2024 pm 05:12 PM
はい、Navicat は Redis に接続できます。これにより、ユーザーはキーの管理、値の表示、コマンドの実行、アクティビティの監視、問題の診断が可能になります。 Redis に接続するには、Navicat で「Redis」接続タイプを選択し、サーバーの詳細を入力します。
