

MySQL の主キーの自動インクリメントで遭遇する落とし穴を解決する方法

1. UUID を使用しない理由
したがって、UUID 文字列を主キーとして使用する場合、データが挿入されるたびに、B ツリー内で独自の位置を検索する必要があります。 (配列にレコードを挿入するのと同じように) 後続ノードを移動することは可能ですが、後続ノードを移動するとページ分割が発生する可能性があり、挿入効率が低下します。
一方、非クラスター化インデックスでは、リーフ ノードに主キーの値が格納されます。主キーが長い UUID 文字列の場合、(int および In と比較して) より大きな記憶領域を占有します。言い換えると)、同じリーフ ノードで保存できる主キー値の数が減り、ツリーが高くなる可能性があります。これは、クエリ中の IO 数が増加し、クエリ効率が低下することを意味します。 上記の分析に基づいて、MySQL では UUID を主キーとして使用しないようにしています。UUID がないと、自動インクリメントに主キーを使用できるのではないかと考える人もいるかもしれません。 主キーの自動インクリメントにより、UUID を主キーとして使用するときに発生する 2 つの問題が明らかに解決されます。主キーは自動インクリメントされます。毎回ツリーの最後に追加するだけで済みます。基本的に、ページ分割の問題は発生しません。主キーの自動インクリメントとは、主キーが数値であり、占有されるストレージ領域は比較的小さく、非クラスター化の場合、インデックス作成の影響も小さくなります。 では、主キーの自動インクリメントが最善の解決策なのでしょうか?主キーを自動でインクリメントする場合に注意すべき点はありますか? 2. 主キーの自動インクリメントの問題次の内容には、テーブルに主キーの自動インクリメントがあるという共通の前提があります。
一般に、主キーの自動インクリメントには問題はありません。ただし、同時実行性の高い環境では問題が発生します。 まず第一に、最も簡単に考えられるのは、大量の同時挿入中に発生するテール ホットスポットの問題です。同時挿入中、全員がこの値をクエリしてから、独自の主キー値を計算する必要があります。次に、上位キーの値を計算する必要があります。主キーの境界はホットデータとなり、同時挿入時にここでロック競合が発生します。 この問題を解決するには、適切なinnodb_autoinc_lock_mode を選択する必要があります。
insert into user(name)values('javaboy')
またはreplace into user(name)values('javaboy')、入れ子になったクエリはありません。挿入する行数を決定できます挿入は simple insert と呼ばれますが、INSERT ... ON DUPLICATE KEY UPDATEはとしてカウントされないことに注意してください。単純にを挿入します。- load data
または
insert into user select ... from ....、これらはbulk と呼ばれるバッチ挿入ですinsert、この一括挿入の特徴の 1 つは、挿入されるデータの数が最初は不明であることです。 - user(id,name) に挿入 value(null,'javaboy'),(null,'江南一宜店')
、これもバッチ挿入です, しかし、2 番目のものとは異なります。この型には、いくつかの自動的に生成された値 (この場合の主キーは自動インクリメントされます) が含まれており、合計で何行挿入されるかを決定できます。この型は
と呼ばれます。混合挿入、上記の最初の点で述べたINSERT ... ON DUPLICATE KEY UPDATEについては、混合挿入とみなすこともできます。 データ挿入は主に主キーが自動インクリメントされる場合、ロック処理スキームが異なるため、これらの 3 つのカテゴリに分類されます。
2.2 innodb_autoinc_lock_mode
主キーが自動インクリメントされるときの MySQL ロック処理のアイデアは、innodb_autoinc_lock_mode 変数の値を制御することで制御できます。
innodb_autoinc_lock_mode 変数には 3 つの異なる値があります:
- 0: これは従来のモードを表します。このモードでは、SQL を挿入するときに、上記の 3 つの異なる値が使用されます。自動インクリメント ロックのソリューションも同じで、挿入された SQL ステートメントの先頭でテーブル レベルの AUTO-INC ロックが取得され、挿入された SQL の実行が完了するとロックが解放されます。これは、バッチ挿入中に自動インクリメントされる主キーが連続していることを保証できるためです。
- 1: これは連続を意味します。このモードでは、
- simple insert
(挿入される行の特定の数を決定でき、上記の 2 つの状況 1 と 3 に対応します)
simple insertは挿入する行数を簡単に計算できるため、複数の連続した値を一度に生成し、対応する挿入 SQL ステートメントで使用できるため、AUTO- INC ロックによりロック待ちが軽減され、同時挿入効率が向上します。 2: これはインターリーブを意味します。この場合、AUTO-INC ロックはありません。それぞれが 1 つずつ処理されます。バッチで挿入する場合、プライマリキーがインクリメントされますが、存在しません。質問の連続です。
上記の紹介からわかるように、実際には 3 番目のタイプ、つまり innodb_autoinc_lock_mode の値が 2 の場合、同時実行効率が最も高くなります。そのため、innodb_autoinc_lock_mode を設定するのはどうでしょうか。 =2?
状況によります。
Songge は以前記事を書き、MySQL binlog ログ ファイルの 3 つの形式を友人に紹介しました。
row: binlog に記録されるのは特定の値です。元の SQL の代わりに、簡単な例を挙げると、テーブル内のフィールドが UUID で、ユーザーによって実行される SQL が
insert into user(username,uuid) names('javaboy',uuid() であると仮定します。 )、最終的に binlog に記録された SQL はinsert into user(username,uuid)values('javaboy',‘0212cfa0-de06-11ed-a026-0242ac110004’)になります。ステートメント: binlog に記録されるのは元の SQL です。行内の SQL を例に取ると、最終的に binlog に記録されるのは
insert into user(username) ,uuid) value( 'javaboy',uuid()).mixed: このモードでは、MySQL は特定の SQL ステートメントに基づいてログ形式を決定します。つまり、ステートメントと行の間で 1 つを選択します。
これら 3 つの異なるモードでは、ステートメント モードがマスター/スレーブ レプリケーション中にマスター/スレーブ データに不整合を引き起こす可能性があることは明らかなので、現在、MySQL のデフォルトのバイナリ ログ形式は行です。
質問に戻ります:
binlog 形式が行の場合、データの同時実行性を最大限に高めるために、innodb_autoinc_lock_mode の値を 2 に設定できます。エクステント挿入機能により、マスターとスレーブのデータの不整合の問題は発生しません。
binlog 形式がステートメントの場合は、
simple insertの同時挿入機能が向上するように、innodb_autoinc_lock_mode の値を 1 に設定することをお勧めします。最初に AUTO-INC ロックを取得し、挿入が成功したらロックを解除します。これにより、マスターとスレーブのデータの不整合を回避し、データ レプリケーションのセキュリティを確保することもできます。上記の 2 点は主に InnoDB ストレージ エンジンに関するものですが、MyISAM ストレージ エンジンの場合は、最初に AUTO-INC ロックが取得され、挿入が完了したら解放されます。これは、innodb_autoinc_lock_mode 変数の値のペアに相当します。MyISAM は機能しません。
2.3 実践
次に、簡単な SQL を使用して、innodb_autoinc_lock_mode のさまざまな値がさまざまな結果にどのように対応するかを友人に示してみましょう。
次の SQL クエリを使用して、現在の innodb_autoinc_lock_mode 設定を表示できます:

ご覧のとおり、バージョン 8.0.32 の現在のデフォルト値は、私が使っているのは2です。
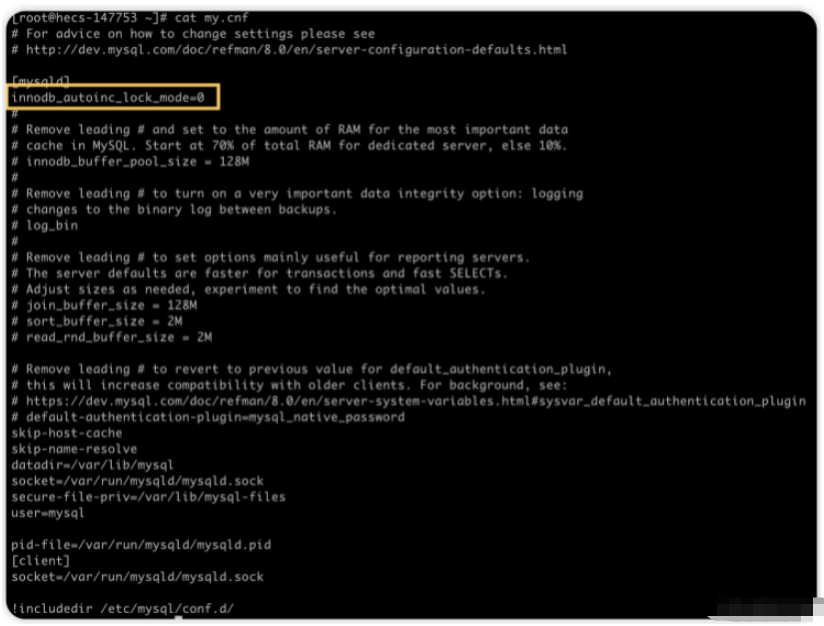
最初にこれを 0 に変更します。変更方法は、/etc/my.cnf## に innodb_autoinc_lock_mode=0:

CREATE TABLE `user` ( `id` int unsigned NOT NULL AUTO_INCREMENT, `username` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=100 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
insert into user(id,username) values(1,'javaboy'),(null,'江南一点雨'),(3,'www.javaboy.org'),(null,'lisi');


simple insert
を実行して挿入すると、システムは 4 つのレコードを挿入したいことを認識し、事前に 4 つの ID を直接取り出しました。それぞれ 100、101、102、103 です。その結果、SQL では実際に 2 つの ID のみが使用され、残りの 2 つは役に立ちませんが、次の挿入は引き続き 104 から始まります。以上がMySQL の主キーの自動インクリメントで遭遇する落とし穴を解決する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7451
7451
 15
1374
52
77
11
14
9
15
1374
52
77
11
14
9

 MySQLユーザーとデータベースの関係
Apr 08, 2025 pm 07:15 PM
MySQLユーザーとデータベースの関係
Apr 08, 2025 pm 07:15 PM
MySQLデータベースでは、ユーザーとデータベースの関係は、アクセス許可と表によって定義されます。ユーザーには、データベースにアクセスするためのユーザー名とパスワードがあります。許可は助成金コマンドを通じて付与され、テーブルはCreate Tableコマンドによって作成されます。ユーザーとデータベースの関係を確立するには、データベースを作成し、ユーザーを作成してから許可を付与する必要があります。
 RDS MySQL Redshift Zero ETLとの統合
Apr 08, 2025 pm 07:06 PM
RDS MySQL Redshift Zero ETLとの統合
Apr 08, 2025 pm 07:06 PM
データ統合の簡素化:AmazonrdsmysqlとRedshiftのゼロETL統合効率的なデータ統合は、データ駆動型組織の中心にあります。従来のETL(抽出、変換、負荷)プロセスは、特にデータベース(AmazonrdsmysQlなど)をデータウェアハウス(Redshiftなど)と統合する場合、複雑で時間がかかります。ただし、AWSは、この状況を完全に変えたゼロETL統合ソリューションを提供し、RDSMYSQLからRedshiftへのデータ移行のための簡略化されたほぼリアルタイムソリューションを提供します。この記事では、RDSMysQl Zero ETLのRedshiftとの統合に飛び込み、それがどのように機能するか、それがデータエンジニアと開発者にもたらす利点を説明します。
 mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
MySQLには、無料のコミュニティバージョンと有料エンタープライズバージョンがあります。コミュニティバージョンは無料で使用および変更できますが、サポートは制限されており、安定性要件が低く、技術的な能力が強いアプリケーションに適しています。 Enterprise Editionは、安定した信頼性の高い高性能データベースを必要とするアプリケーションに対する包括的な商業サポートを提供し、サポートの支払いを喜んでいます。バージョンを選択する際に考慮される要因には、アプリケーションの重要性、予算編成、技術スキルが含まれます。完璧なオプションはなく、最も適切なオプションのみであり、特定の状況に応じて慎重に選択する必要があります。
 MySQLのクエリ最適化は、特に大規模なデータセットを扱う場合、データベースのパフォーマンスを改善するために不可欠です
Apr 08, 2025 pm 07:12 PM
MySQLのクエリ最適化は、特に大規模なデータセットを扱う場合、データベースのパフォーマンスを改善するために不可欠です
Apr 08, 2025 pm 07:12 PM
1.正しいインデックスを使用して、データの量を削減してデータ検索をスピードアップしました。テーブルの列を複数回検索する場合は、その列のインデックスを作成します。あなたまたはあなたのアプリが基準に従って複数の列からのデータが必要な場合、複合インデックス2を作成します2。選択した列のみを避けます。必要な列のすべてを選択すると、より多くのサーバーメモリを使用する場合にのみサーバーが遅くなり、たとえばテーブルにはcreated_atやupdated_atやupdated_atなどの列が含まれます。
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 MySQLのユーザー名とパスワードを入力する方法
Apr 08, 2025 pm 07:09 PM
MySQLのユーザー名とパスワードを入力する方法
Apr 08, 2025 pm 07:09 PM
MySQLのユーザー名とパスワードを入力するには:1。ユーザー名とパスワードを決定します。 2。データベースに接続します。 3.ユーザー名とパスワードを使用して、クエリとコマンドを実行します。
 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
