

Mysql は、グループごとに区別した後、各グループの上位数を取得する SQL の書き方を実装します。

データをグループ化し、各グループの最初の 10 個のデータを取得する必要があるシナリオに遭遇しました。最初は group by を使用することを考えましたが、問題は次のとおりです。グループ化後のデータを知る方法 データはグループ内でランク付けされます。
1. テーブルを作成し、関連するテスト データを挿入します
CREATE TABLE `score` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `subject` varchar(20) DEFAULT NULL COMMENT '科目', `student_id` int(11) DEFAULT NULL COMMENT '学生id', `student_name` varchar(20) NOT NULL COMMENT '学生姓名', `score` double DEFAULT NULL COMMENT '成绩', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=16 DEFAULT CHARSET=utf8;
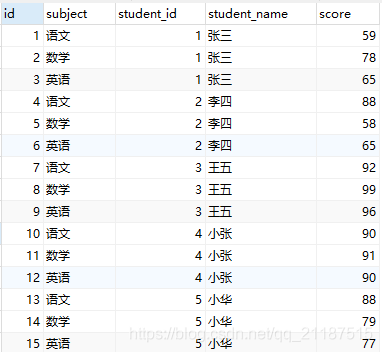
注: 挿入されたデータ SQL は最後にあり、友人はそれを確認できます。 sql
2. 各科目の上位 3 つのスコアのレコードをクエリします
データが利用可能になったので、SQL を記述します。SQL は次のとおりです:
###每科成绩前三名 SELECT * FROM score s1 WHERE ( SELECT count( * ) FROM score s2 WHERE s1.`subject` = s2.`subject` AND s1.score < s2.score ) < 3 ORDER BY SUBJECT, score DESC
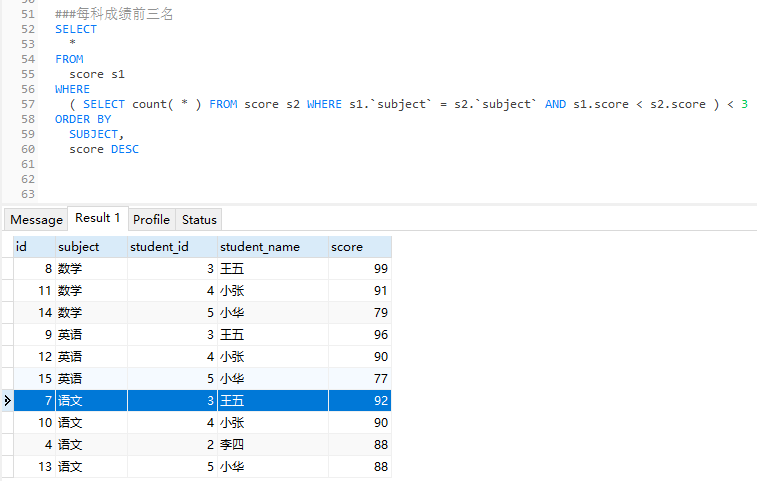
分析:
サブクエリがその中で使用されており、コア SQL は where の後の条件です:
( SELECT count( * ) FROM score s2 WHERE s1.subject = s2.subject AND s1.score < s2.score ) < 3
この SQL の意味は次のとおりです。 。 。
私の言語で説明するのは少し難しいと思うので、使い慣れた Java コードを使用して上記の SQL を説明します。これはおそらく 2 回トラバースする for ループであり、同じ科目は 2 番目の for ループでカウントされます。生徒の記録、s1 よりも高いスコアを持つ生徒の数です。この数値が 3 未満の場合、s1 が上位 3 位にランクされていることを意味します。## を理解するには、次のコードを見てください。 #
public class StudentTest {
public static void main(String[] args) {
List<Student> list = new ArrayList<>();
//初始化和表结构一致的数据
initData(list);
//记录查询出来的结果
List<Student> result = new ArrayList<>();
for(Student s1 : list){
int num = 0;
//两次for循环遍历,相当于sql里面的子查询
for(Student s2:list){
//统计同一科目,且分数s2分数大于s1的数量,简单理解就是同一科目的学生记录,比s1的学生分数高的数量
if(s1.getSubject().equals(s2.getSubject())
&&s1.getScore()<s2.getScore()){
num++;
}
}
//比s1的学生分数高的数量,如果小于3的话,说明s1这个排名前三
// 举例:num=0时,说明同一科目,没有一个学生成绩高于s1学生, s1学生的这科成绩排名第一
// num =1,时,s1学生排名第二,num=3时:说明排名同一科目有三个学生成绩高过s1,s1排第四,所以只统计前三的学生,条件就是num<3
if(num < 3){
result.add(s1);
}
}
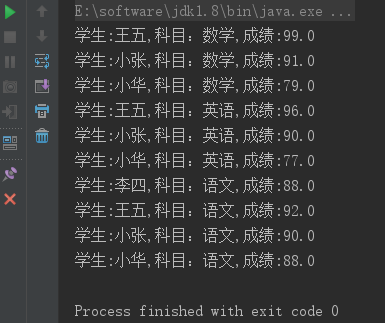
//输出各科成绩前三的记录
result.stream()
.sorted(Comparator.comparing(Student::getSubject))
.forEach(
s-> System.out.println(String.format("学生:%s,科目:%s,成绩:%s",s.getName(),s.getSubject(),s.getScore()))
);
}
public static void initData(List<Student> list) {
list.add(new Student(1,"语文","张三",59));
list.add(new Student(2,"数学","张三",78));
list.add(new Student(3,"英语","张三",65));
list.add(new Student(4,"语文","李四",88));
list.add(new Student(5,"数学","李四",58));
list.add(new Student(6,"英语","李四",65));
list.add(new Student(7,"语文","王五",92));
list.add(new Student(8,"数学","王五",99));
list.add(new Student(9,"英语","王五",96));
list.add(new Student(10,"语文","小张",90));
list.add(new Student(11,"数学","小张",91));
list.add(new Student(12,"英语","小张",90));
list.add(new Student(13,"语文","小华",88));
list.add(new Student(14,"数学","小华",79));
list.add(new Student(15,"英语","小华",77));
}
@Data
public static class Student {
private int id;
private String subject;
private String name;
private double score;
//想当于表结构
public Student(int id, String subject, String name, double score) {
this.id = id;
this.subject = subject;
this.name = name;
this.score = score;
}
} ##3. スコアが高い学生の記録をクエリします。各科目の得点が 90 点以上である
##3. スコアが高い学生の記録をクエリします。各科目の得点が 90 点以上である
テーブルとデータが利用可能です。ところで、このタイプの SQL 質問をいくつか要約してください
質問が次のレコードをクエリすることである場合上の表で各科目の得点が90点以上の場合、SQLはどのように書くのでしょうか?
1. 最初の書き方: ポジティブ思考
各科目のスコアが 90 点を超える場合、最低点も 90 点以上である必要があります。 SQL は次のとおりです:
SELECT * FROM score WHERE student_id IN (SELECT student_id FROM score GROUP BY student_id HAVING min( score ) >= 90 )
2. 2 番目の書き方: 逆の考え方
最高スコアが 90 ポイント未満のレコードを除外します
SELECT * FROM score WHERE student_id NOT IN (SELECT student_id FROM score GROUP BY student_id HAVING max( score ) < 90 )
その他のナレーション
各科目の平均点が 80 点を超える生徒の記録を照会します
###查询学生各科平均分大于80分的记录
select * from score where student_id in(
select student_id from score GROUP BY student_id HAVING avg(score)>80
)各科目で不合格になった生徒の記録をクエリします
###查询一个学生每科分数不及格的记录 SELECT * FROM score WHERE student_id IN ( SELECT student_id FROM score GROUP BY student_id HAVING max( score ) < 60 )
添付ファイル: テーブル構造に挿入された SQL
CREATE TABLE `score` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `subject` varchar(20) DEFAULT NULL COMMENT '科目', `student_id` int(11) DEFAULT NULL COMMENT '学生id', `student_name` varchar(20) NOT NULL COMMENT '学生姓名', `score` double DEFAULT NULL COMMENT '成绩', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=16 DEFAULT CHARSET=utf8; INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (1, '语文', 1, '张三', 59); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (2, '数学', 1, '张三', 78); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (3, '英语', 1, '张三', 65); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (4, '语文', 2, '李四', 88); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (5, '数学', 2, '李四', 58); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (6, '英语', 2, '李四', 65); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (7, '语文', 3, '王五', 92); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (8, '数学', 3, '王五', 99); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (9, '英语', 3, '王五', 96); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (10, '语文', 4, '小张', 90); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (11, '数学', 4, '小张', 91); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (12, '英语', 4, '小张', 90); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (13, '语文', 5, '小华', 88); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (14, '数学', 5, '小华', 79); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (15, '英语', 5, '小华', 77);
以上がMysql は、グループごとに区別した後、各グループの上位数を取得する SQL の書き方を実装します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7480
7480
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICAT自体はデータベースパスワードを保存せず、暗号化されたパスワードのみを取得できます。解決策:1。パスワードマネージャーを確認します。 2。NAVICATの「パスワードを記憶する」機能を確認します。 3.データベースパスワードをリセットします。 4.データベース管理者に連絡してください。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 MariadBのNAVICATでデータベースパスワードを表示する方法は?
Apr 08, 2025 pm 09:18 PM
MariadBのNAVICATでデータベースパスワードを表示する方法は?
Apr 08, 2025 pm 09:18 PM
Passwordが暗号化された形式で保存されているため、MariadbのNavicatはデータベースパスワードを直接表示できません。データベースのセキュリティを確保するには、パスワードをリセットするには3つの方法があります。NAVICATを介してパスワードをリセットし、複雑なパスワードを設定します。構成ファイルを表示します(推奨されていない、高リスク)。システムコマンドラインツールを使用します(推奨されません。コマンドラインツールに習熟する必要があります)。
 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する手順:データベースに接続します。 SQLエディターウィンドウを作成します。 SQLクエリまたはスクリプトを書きます。 [実行]ボタンをクリックして、クエリまたはスクリプトを実行します。結果を表示します(クエリが実行された場合)。
 NAVICATは、MySQL/Mariadb/PostgreSQLおよびその他のデータベースに接続できません
Apr 08, 2025 pm 11:00 PM
NAVICATは、MySQL/Mariadb/PostgreSQLおよびその他のデータベースに接続できません
Apr 08, 2025 pm 11:00 PM
NAVICATがデータベースとそのソリューションに接続できない一般的な理由:1。サーバーの実行ステータスを確認します。 2。接続情報を確認します。 3.ファイアウォール設定を調整します。 4.リモートアクセスを構成します。 5.ネットワークの問題のトラブルシューティング。 6.許可を確認します。 7.バージョンの互換性を確保します。 8。他の可能性のトラブルシューティング。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
