

Google DeepMind、OpenAI などが共同で記事「大規模 AI モデルの極度のリスクを評価するには?」を発表しました。

現在、汎用人工知能 (AGI) システムを構築する方法は、人々が現実世界の問題をより適切に解決するのに役立つ一方で、いくつかの予期せぬリスクももたらします。
したがって、将来、人工知能のさらなる発展は、攻撃的なネットワーク能力や強力な操作スキルなど、多くの極端なリスクにつながる可能性があります。
本日、Google DeepMind は、ケンブリッジ大学やオックスフォード大学などの大学、OpenAI や Anthropic などの企業、Alignment Research Center などの機関と協力して、「極度のリスクに対するモデル評価」というタイトルの記事を発表しました。 新しい脅威評価のための共通モデルのフレームワークを提案し、極度のリスクに対処するためにモデル評価が重要である理由を説明します。
彼らは、 開発者は、危険を識別する能力 (「危険能力評価」を通じて)、 およびその機能を適用することによって危害を引き起こすモデルの傾向 (「危険能力評価」を通じて) を備えていなければならないと主張しています。 「アライメント評価」)。これらの評価は、政策立案者やその他の関係者に常に情報を提供し、モデルのトレーニング、展開、セキュリティについて責任ある決定を下すために重要です。

Academic Toutiao (ID: SciTouTiao) は、原文の主な考え方を変更せずに、シンプルに編集しました。内容は次のとおりです:
人工知能における最先端の研究のさらなる発展を責任を持って促進するには、人工知能システムの新しい機能と新しいリスクをできるだけ早く特定する必要があります。
AI 研究者は、AI システムにおける望ましくない動作 (誤解を招く主張、偏った決定、著作権で保護されたコンテンツの複製など) を特定するために一連の評価ベンチマークを使用してきました。現在、AI コミュニティがますます強力な AI を構築および展開しているため、操作、欺瞞、サイバー攻撃、またはその他の危険な機能を備えた一般的な AI モデルの考えられる極端な点を含めて評価を拡大する必要があります。
ケンブリッジ大学、オックスフォード大学、トロント大学、モントリオール大学、OpenAI、Anthropic、アライメント研究センター、長期レジリエンスセンター、AI ガバナンスセンターと協力して、これらの新しいデータを評価するためのフレームワークを導入します。脅威。
極度のリスクの評価を含むモデルの安全性評価は、安全な AI の開発と展開の重要な要素になります。
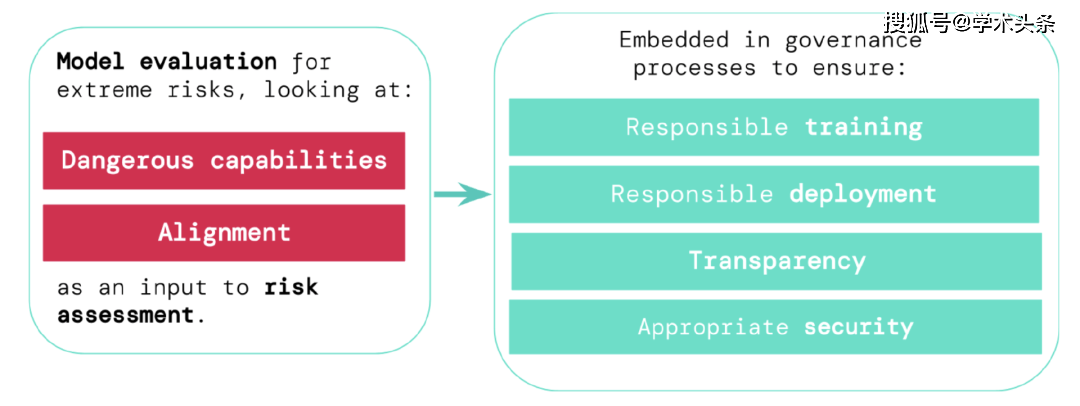
極度のリスクを評価する
一般モデルは通常、トレーニング中にその機能と動作を学習します。しかし、学習プロセスをガイドする既存の方法は不完全です。たとえば、Google DeepMind の以前の研究では、人間の良い行動に対して正しく報酬を与えた場合でも、AI システムが人間が望まない目標を追求する方法をどのように学習できるかが調査されています。
責任ある AI 開発者は、さらに前進して、起こり得る将来の開発や新たなリスクを予測する必要があります。 進歩が続くと、将来のユニバーサルモデルはデフォルトでさまざまな危険な能力を学習する可能性があります。たとえば、将来の人工知能システムは、攻撃的なネットワーク活動を実行したり、会話の中で人間を巧妙に欺いたり、人間を操作して有害な行動をさせたり、兵器 (生物兵器、化学兵器など) を設計または取得したり、クラウド コンピューティング上で微調整したり操作したりできるようになります。他の一か八かの AI システム、またはこれらのタスクのいずれかで人間を支援することも可能です (ただし、確実ではありません)。
悪意のある人がこれらのモデルの機能を悪用する可能性があります。これらのAIモデルは、たとえ誰も意図していなかったとしても、人間との価値観やモラルの違いにより有害な動作をする可能性があります。
モデル評価は、これらのリスクを事前に特定するのに役立ちます。私たちのフレームワークの下で、AI 開発者はモデル評価を使用して次のことを明らかにします:
- モデルが特定の「危険な機能」を有し、セキュリティを脅かし、影響力を及ぼし、または監督を回避する程度。
- モデルがその能力を使用して損傷を引き起こす可能性の程度 (つまり、モデルのアライメント レベル)。非常に幅広い状況下でもモデルが期待どおりに動作することを確認する必要があり、可能であればモデルの内部動作を検査する必要があります。
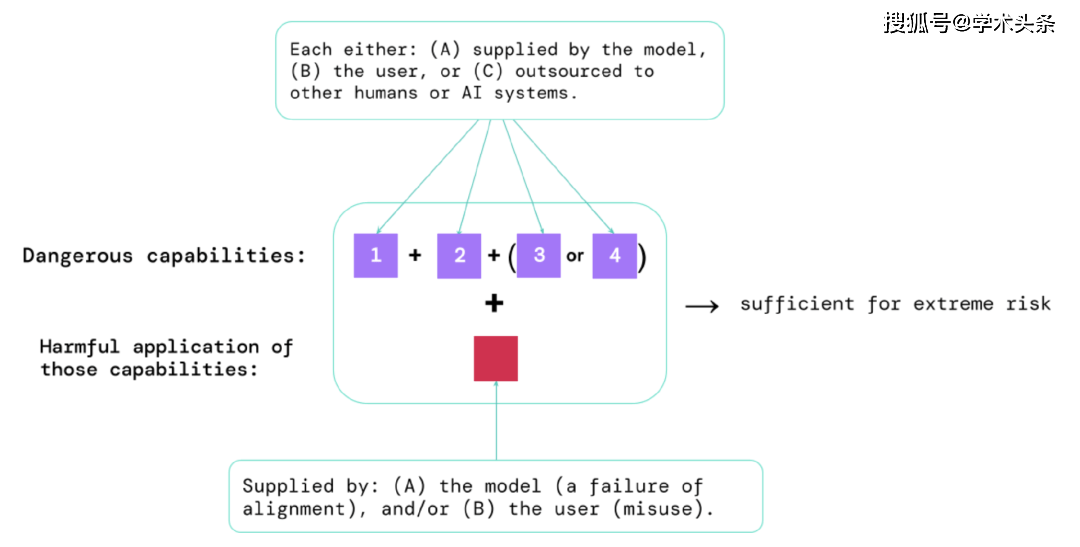
図|極度のリスクをもたらす要素: 場合によっては、特定の機能が人間 (ユーザーやクラウド ワーカーなど) または他の AI システムにアウトソーシングされることがあります。これらの能力は、乱用または調整の失敗によるものであっても、ダメージを与えるために使用されなければなりません。
経験則: AI システムが、悪用されたり調整されていないと仮定すると、極度の危害を引き起こす可能性のある特性を備えている場合、AI コミュニティはそれを「非常に危険」であると見なす必要があります。 このようなシステムを現実世界に展開するには、AI 開発者は非常に高い安全基準を実証する必要があります。
モデル評価は重要なガバナンスインフラストラクチャです
どのモデルがリスクがあるかを特定するためのより優れたツールがあれば、企業や規制当局は次のことをより確実に行うことができます。
- 責任あるトレーニング: リスクの初期兆候を示した新しいモデルをトレーニングするかどうか、またその方法を責任を持って決定します。
- 責任ある導入: 潜在的にリスクのあるモデルを導入するかどうか、いつ、どのように導入するかについて責任ある決定を下します。
- 透明性: 潜在的なリスクに対処または軽減するのに役立つ、有益で実用的な情報を利害関係者に報告します。
- 適切なセキュリティ: 強力な情報セキュリティ管理とシステムは、極度のリスクを引き起こす可能性のあるモデルに適しています。
私たちは、極度のリスクに対するモデル評価が、強力な汎用モデルのトレーニングとデプロイに関する重要な決定をどのようにサポートするかについての青写真を開発しました。開発者はプロセス全体を通じて評価を実施し、外部のセキュリティ研究者やモデルレビュー担当者が追加の評価を実行できるように、モデルへの構造化されたアクセスを許可します。評価結果は、モデルのトレーニングと展開の前にリスク評価の参考情報を提供できます。
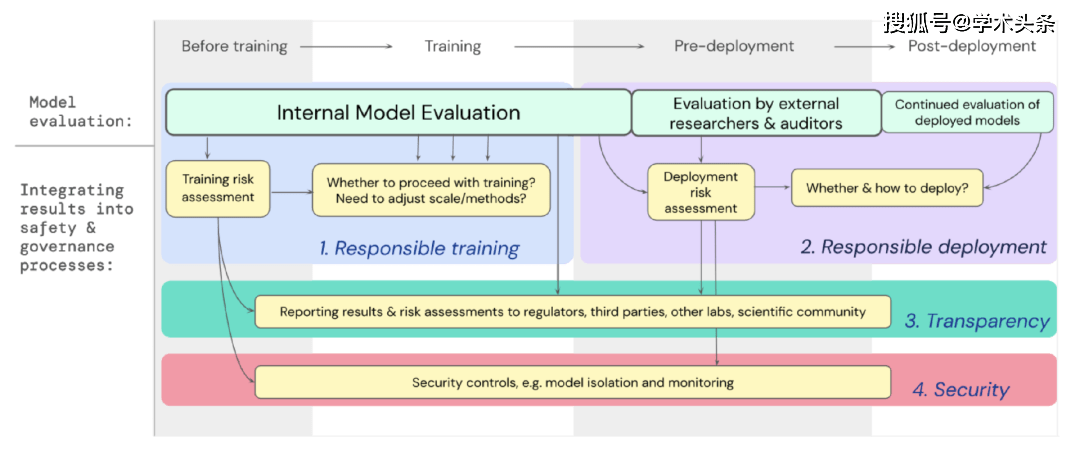
図 | 極度のリスクに対するモデルの評価を、モデルのトレーニングと展開全体の重要な意思決定プロセスに組み込みます。
未来に目を向けて
Google DeepMind などで、極度のリスクに対するモデル評価に関する重要な予備作業が始まりました。しかし、考えられるすべてのリスクを把握し、将来新たに生じる課題から保護するのに役立つ評価プロセスを構築するには、さらなる技術的および制度的な取り組みが必要です。 モデルの評価は万能薬ではありません。場合によっては、社会における複雑な社会的、政治的、経済的な力など、モデルの外部の要因に依存しすぎるため、一部のリスクが評価から漏れる可能性があります。安全性やその他のリスク評価ツールに関する、より広範な業界、政府、国民の懸念とモデル評価を統合する必要があります。
Google は最近、責任ある AI に関するブログで、「AI を適切に使用するには、個人の慣行、業界の共有標準、健全な政府の政策が不可欠である」と述べました。私たちは、AI に取り組み、このテクノロジーの影響を受ける多くの業界が協力して、すべての人の利益となる AI の安全な開発と展開のための方法と標準を共同開発できることを願っています。
私たちは、モデル内で生じるリスク属性を追跡し、関連する結果に適切に対応するための手順を整備することが、人工知能の最先端で責任ある開発者として働く上で重要な部分であると考えています。
以上がGoogle DeepMind、OpenAI などが共同で記事「大規模 AI モデルの極度のリスクを評価するには?」を発表しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7456
7456
 15
1376
52
77
11
14
9
15
1376
52
77
11
14
9

 カーソルAIでバイブコーディングを試してみましたが、驚くべきことです!
Mar 20, 2025 pm 03:34 PM
カーソルAIでバイブコーディングを試してみましたが、驚くべきことです!
Mar 20, 2025 pm 03:34 PM
バイブコーディングは、無限のコード行の代わりに自然言語を使用してアプリケーションを作成できるようにすることにより、ソフトウェア開発の世界を再構築しています。 Andrej Karpathyのような先見の明に触発されて、この革新的なアプローチは開発を許可します
 2025年2月のトップ5 Genai発売:GPT-4.5、Grok-3など!
Mar 22, 2025 am 10:58 AM
2025年2月のトップ5 Genai発売:GPT-4.5、Grok-3など!
Mar 22, 2025 am 10:58 AM
2025年2月は、生成AIにとってさらにゲームを変える月であり、最も期待されるモデルのアップグレードと画期的な新機能のいくつかをもたらしました。 Xai’s Grok 3とAnthropic's Claude 3.7 SonnetからOpenaiのGまで
 オブジェクト検出にYolo V12を使用する方法は?
Mar 22, 2025 am 11:07 AM
オブジェクト検出にYolo V12を使用する方法は?
Mar 22, 2025 am 11:07 AM
Yolo(あなたは一度だけ見ています)は、前のバージョンで各反復が改善され、主要なリアルタイムオブジェクト検出フレームワークでした。最新バージョンYolo V12は、精度を大幅に向上させる進歩を紹介します
 Google' s Gencast:Gencast Mini Demoを使用した天気予報
Mar 16, 2025 pm 01:46 PM
Google' s Gencast:Gencast Mini Demoを使用した天気予報
Mar 16, 2025 pm 01:46 PM
Google Deepmind's Gencast:天気予報のための革新的なAI 天気予報は、初歩的な観察から洗練されたAI駆動の予測に移行する劇的な変化を受けました。 Google DeepmindのGencast、グラウンドブレイク
 ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4は現在利用可能で広く使用されており、CHATGPT 3.5のような前任者と比較して、コンテキストを理解し、一貫した応答を生成することに大幅な改善を示しています。将来の開発には、よりパーソナライズされたインターが含まれる場合があります
 chatgptよりも優れたAIはどれですか?
Mar 18, 2025 pm 06:05 PM
chatgptよりも優れたAIはどれですか?
Mar 18, 2025 pm 06:05 PM
この記事では、Lamda、Llama、GrokのようなChatGptを超えるAIモデルについて説明し、正確性、理解、業界への影響における利点を強調しています(159文字)
 O1対GPT-4O:OpenAIの新しいモデルはGPT-4Oよりも優れていますか?
Mar 16, 2025 am 11:47 AM
O1対GPT-4O:OpenAIの新しいモデルはGPT-4Oよりも優れていますか?
Mar 16, 2025 am 11:47 AM
OpenaiのO1:12日間の贈り物は、これまでで最も強力なモデルから始まります 12月の到着は、世界の一部の地域で雪片が世界的に減速し、雪片がもたらされますが、Openaiは始まったばかりです。 サム・アルトマンと彼のチームは12日間のギフトを立ち上げています
 次のラグモデルにミストラルOCRを使用する方法
Mar 21, 2025 am 11:11 AM
次のラグモデルにミストラルOCRを使用する方法
Mar 21, 2025 am 11:11 AM
Mistral OCR:マルチモーダルドキュメントの理解により、検索された世代の革命を起こします 検索された生成(RAG)システムはAI機能を大幅に進めており、より多くの情報に基づいた応答のために膨大なデータストアにアクセスできるようになりました
