

GPTの現状をついに誰かが明らかにしてくれました! OpenAIの最新のスピーチは急速に広まったが、それはマスク氏が厳選した天才に違いない

Windows Copilot のリリースに続いて、Microsoft Build カンファレンスは スピーチ によって爆発しました。
元 Tesla AI ディレクターの Andrej Karpathy 氏は、スピーチの中で、tree of thought は AlphaGo の Monte Carlo Tree Search (MCTS) に似ていると信じていました。なんと素晴らしいことでしょう。
ネチズンは叫びました: これは、大規模な言語モデルと GPT-4 モデルの使用方法に関する最も詳細で興味深いガイドです!

さらに、Karpathy 氏は、トレーニングとデータの拡張により、LLAMA 65B が「GPT-3 175B よりも大幅に強力」であることを明らかにしました。大型モデルを導入しました Anonymous Arena ChatBot Arena:
Claude のスコアは ChatGPT 3.5 と ChatGPT 4 の間です。

ネチズンは、カルパシーのスピーチはいつも素晴らしく、今回の内容はいつものように誰もを失望させるものではなかったと述べています。
このスピーチで拡散したのは、そのスピーチをもとに Twitter ネチズンが編集したメモです。メモは 31 件あり、いいねの数は 3,000 を超えています:
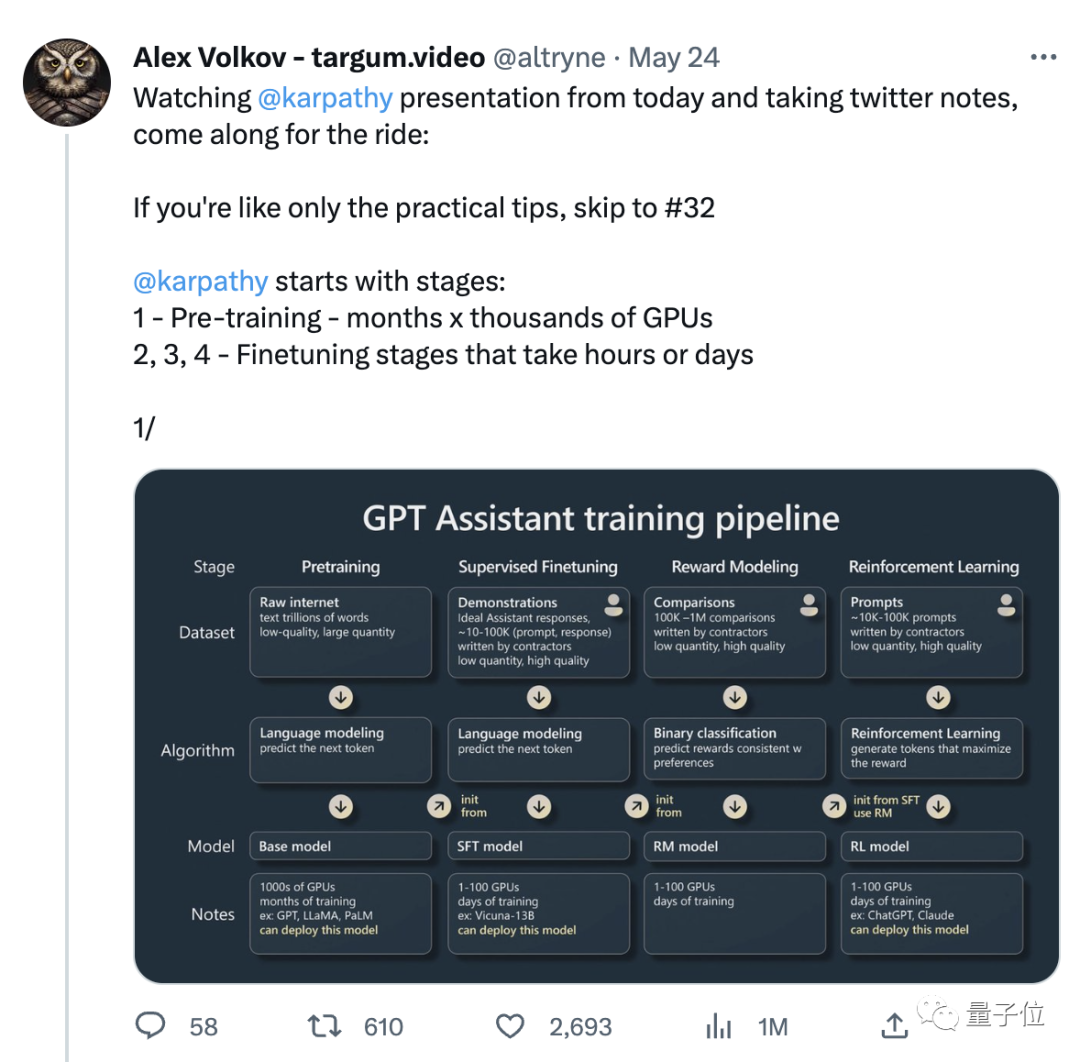
それでは、この待望のスピーチでは具体的にどのような内容が語られたのでしょうか?
GPT アシスタントをトレーニングするにはどうすればよいですか?
今回のカルパシーのスピーチは主に2つのパートに分かれています。
パート 1 では、「GPT アシスタント」をトレーニングする方法について話しました。
Karpathy は主に、AI アシスタントの 4 つのトレーニング段階 (事前トレーニング、教師あり微調整、報酬モデリング、強化学習) について話しています。

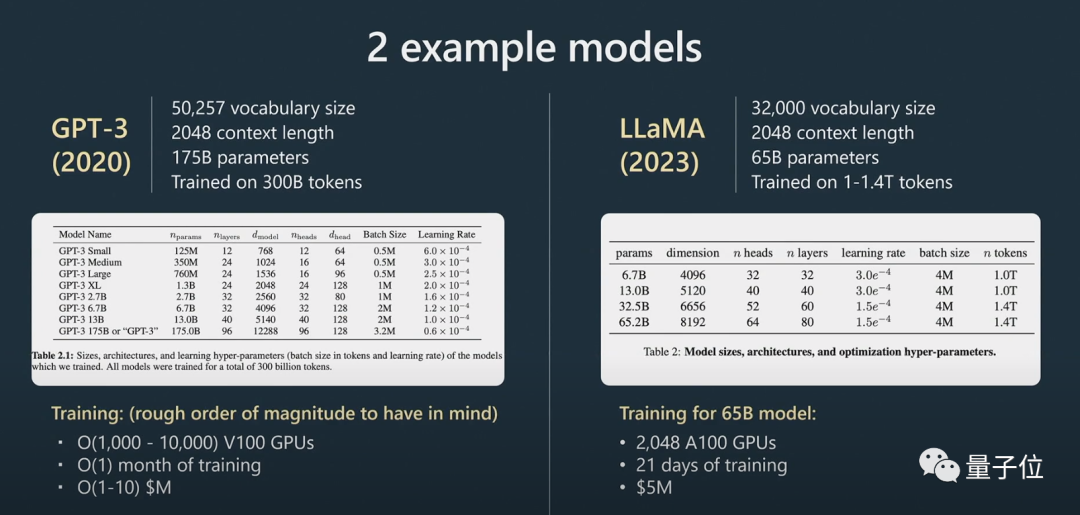
アシスタント モデルを作成できます。
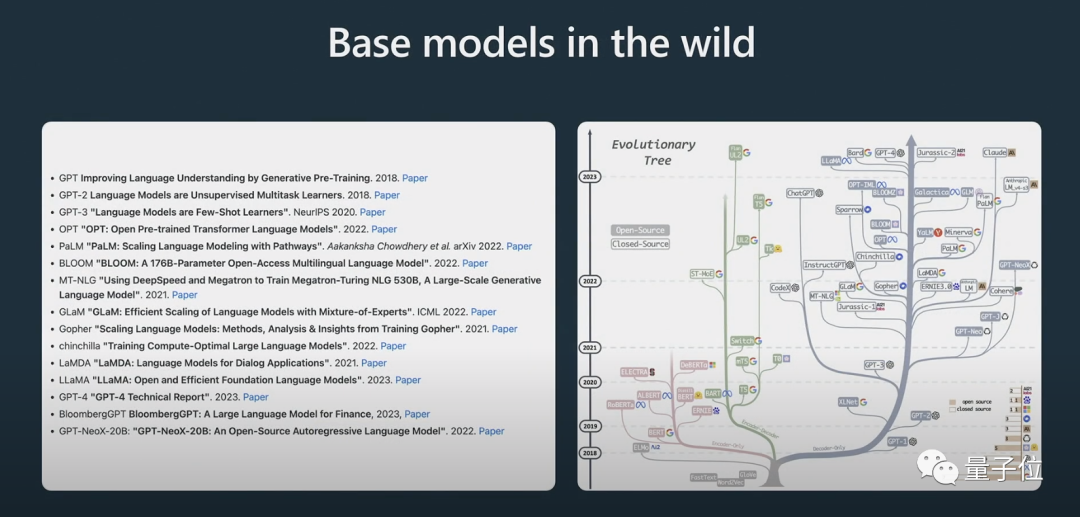
基本モデルはアシスタント モデルではないということです。
基本モデルには問題を解決する機能がありますが、その答えは信頼できませんが、アシスタント モデルは信頼できる答えを提供できます。教師あり微調整アシスタント モデルは、基本モデルに基づいてトレーニングされており、応答の生成とテキスト構造の理解におけるパフォーマンスは、基本モデルよりも優れています。 強化学習は、言語モデルをトレーニングする際のもう 1 つの重要なプロセスです。 トレーニング プロセス中に手動で注釈が付けられた高品質のデータを使用し、報酬モデリング方式で損失関数を作成してパフォーマンスを向上させます。強化トレーニングは、ポジティブなマーキングの確率を高め、ネガティブなマーキングの確率を減らすことによって達成できます。 創造的なタスクに関して AI モデルを改善するには人間の判断が不可欠であり、人間のフィードバックを組み込むことでモデルをより効果的にトレーニングできます。 人間のフィードバックによる強化学習の後、RLHF モデルを取得できます。 モデルがトレーニングされた後の次のステップは、これらのモデルを効果的に使用して問題を解決する方法です。モデルをより効果的に使用するにはどうすればよいですか?
パート 2 では、Karpathy が戦略の促進、微調整、急速に進化するツール エコシステム、将来の拡張について説明します。
カルパシーは、別の具体的な例を挙げて説明しました。
文章を書くとき、私たちは多くの精神活動を行う必要があります。表現が正確かどうかを検討することも含めて。 GPT の場合、これは単にタグ付けされたトークンのシーケンスにすぎません。そして
prompt は、この認知的ギャップを補うことができます。
カルパシーは、思考連鎖プロンプトがどのように機能するかをさらに説明しました。
推論の問題について、自然言語処理で Transformer のパフォーマンスを向上させたい場合は、非常に複雑な問題を直接投げるのではなく、Transformer に情報を段階的に処理させる必要があります。いくつかの例を与えると、この例のテンプレートを模倣し、最終的な結果がより良くなります。

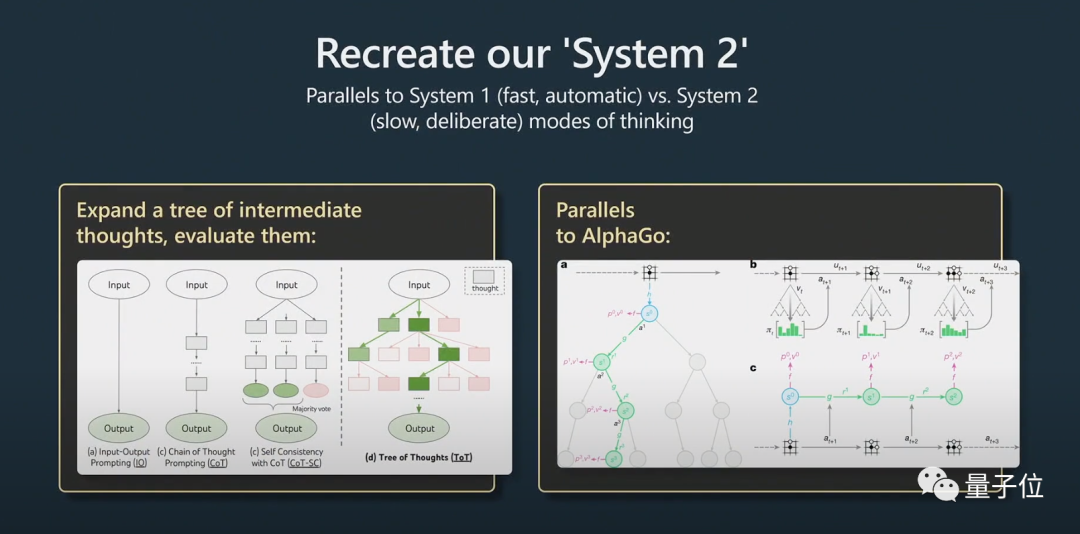 #これには、System1 と System2 の問題が関係します。
#これには、System1 と System2 の問題が関係します。
 「思慮深い」とは、単に質問に答えるということではなく、Python グルー コードで使用されるプロンプトに似ており、多くのプロンプトが連結されて組み込まれています。ヒントをスケーリングするには、モデルで複数のヒントを維持し、ツリー検索アルゴリズムを実行する必要があります。
「思慮深い」とは、単に質問に答えるということではなく、Python グルー コードで使用されるプロンプトに似ており、多くのプロンプトが連結されて組み込まれています。ヒントをスケーリングするには、モデルで複数のヒントを維持し、ツリー検索アルゴリズムを実行する必要があります。
AlphaGo が碁をプレイするとき、次の駒をどこに置くかを考慮する必要があります。最初は人間の真似をして学習しました。
これに加えて、モンテカルロ ツリー検索を実装して、複数の潜在的な戦略による結果を取得します。多くの可能な手を評価し、より良い動きのみを保持します。これはAlphaGoとある程度同等だと思います。これに関連して、Karpathy 氏は AutoGPT についても言及しています。
私は、その効果は現時点ではあまり良くないと考えており、実用化はお勧めしません。私たちは時間の経過によるその進化から学ぶことができるかもしれないと思います。
 第 2 に、もう 1 つの小さなトリックは、拡張生成 (拡張生成の取得) と効果的なプロンプトを取得することです。
第 2 に、もう 1 つの小さなトリックは、拡張生成 (拡張生成の取得) と効果的なプロンプトを取得することです。
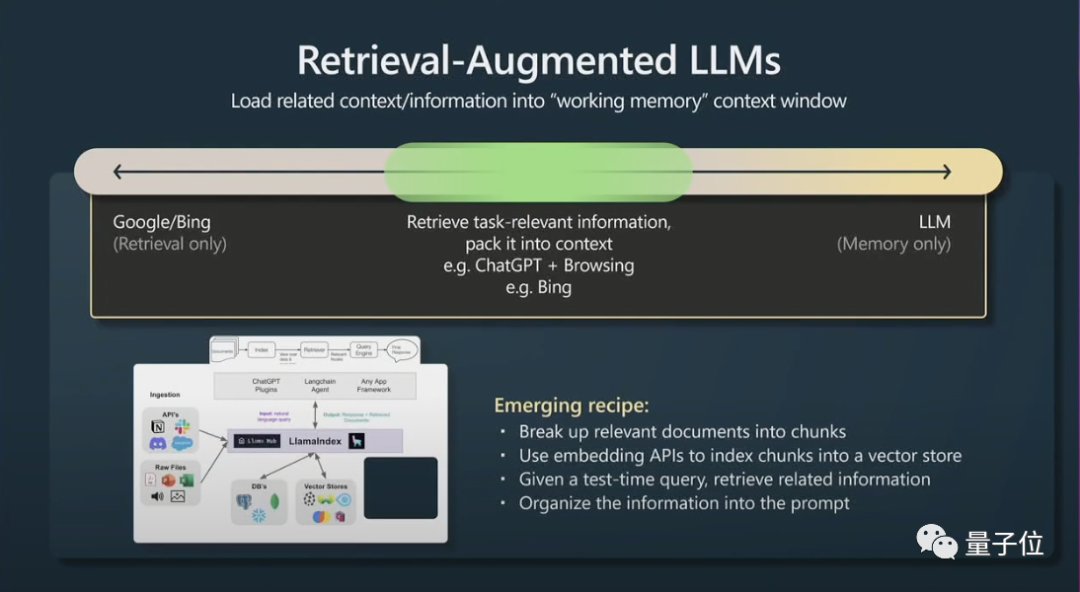
# トランスフォーマーには、参照するメイン ファイルがある場合、パフォーマンスが向上します。
最後に、Karpathy は、大規模な言語モデルにおける制約のプロンプトと微調整について簡単に説明しました。
大規模な言語モデルは、制約のヒントと微調整によって改善できます。制約ヒントは大規模な言語モデルの出力にテンプレートを適用し、微調整によってモデルの重みを調整してパフォーマンスを向上させます。
低リスクのアプリケーションでは大規模な言語モデルを使用し、常に人間の監視と組み合わせ、インスピレーションやアドバイスの源として扱い、副操縦士を完全に自律的に動作させるのではなく副操縦士を考慮することをお勧めします。
Andrej Karpathy について

ポータル:
[1]https://www.youtube.com /watch?v=xO73EUwSegU (スピーチビデオ)
[2]https://arxiv.org/pdf/2305.10601.pdf (「思考の木」論文)
# 参考リンク: [1]https://twitter.com/altryne/status/1661236778458832896
[2]https://www.reddit.com/r/MachineLearning/comments/13qrtek/n_state_of_gpt_by_andrej_karpathy_in_msbuild_2023/
[ 3]https://www.wisdominanutshell.academy/state-of-gpt/
以上がGPTの現状をついに誰かが明らかにしてくれました! OpenAIの最新のスピーチは急速に広まったが、それはマスク氏が厳選した天才に違いないの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7469
7469
 15
1376
52
77
11
19
29
15
1376
52
77
11
19
29

 win7 のハードディスク形式として MBR または GPT を選択する必要がありますか?
Jan 03, 2024 pm 08:09 PM
win7 のハードディスク形式として MBR または GPT を選択する必要がありますか?
Jan 03, 2024 pm 08:09 PM
win7 オペレーティング システムを使用している場合、システムを再インストールしてハードディスクをパーティション分割する必要がある状況に遭遇することがあります。 win7 のハードディスク フォーマットに mbr と gpt のどちらが必要かという問題については、編集者は依然として独自のシステムとハードウェア構成の詳細に基づいて選択する必要があると考えています。互換性の観点から、mbr 形式を選択するのが最善です。詳細については、エディターがどのように実行したかを見てみましょう~ Win7 ハードディスク フォーマットには mbr または gpt1 が必要です。システムが Win7 でインストールされている場合は、互換性の良い MBR を使用することをお勧めします。 2. 3T を超える場合、または win8 をインストールする場合は、GPT を使用できます。 3. 確かに GPT は MBR よりも高度ですが、互換性の点では MBR は間違いなく無敵です。 GPT および MBR 領域
 Kubernetes デバッグ用の最終兵器: K8sGPT
Feb 26, 2024 am 11:40 AM
Kubernetes デバッグ用の最終兵器: K8sGPT
Feb 26, 2024 am 11:40 AM
人工知能と機械学習テクノロジーが発展し続ける中、企業や組織はこれらのテクノロジーを活用して競争力を強化するための革新的な戦略を積極的に模索し始めています。 K8sGPT[2] は、この分野で最も強力なツールの 1 つであり、k8s オーケストレーションの利点と GPT モデルの優れた自然言語処理機能を組み合わせた k8s ベースの GPT モデルです。 K8sGPT とは何ですか? まず例を見てみましょう: K8sGPT 公式 Web サイトによると: K8sgpt は、Kubernetes クラスターの問題をスキャン、診断、分類するために設計されたツールであり、SRE の経験を分析エンジンに統合して、最も関連性の高い情報を提供します。人工知能技術の応用を通じて、K8sgpt はコンテンツを充実させ続け、ユーザーがより迅速かつ正確に理解できるように支援します。
 Win10 パーティション形式の深い理解: GPT と MBR の比較
Dec 22, 2023 am 11:58 AM
Win10 パーティション形式の深い理解: GPT と MBR の比較
Dec 22, 2023 am 11:58 AM
独自のシステムをパーティション分割する場合、ユーザーが使用するハードドライブが異なるため、多くのユーザーは win10 パーティション形式が gpt か mbr のどちらであるかを知りません。このため、これらの違いを理解するのに役立つ詳細な紹介を提供しました。二。 Win10 パーティション形式 gpt または mbr: 回答: 3 TB を超えるハード ドライブを使用している場合は、gpt を使用できます。 gpt は mbr よりも高度ですが、互換性の点では mbr の方がまだ優れています。もちろん、ユーザーの好みに応じて選択することもできます。 gpt と mbr の違い: 1. サポートされるパーティションの数: 1. MBR は最大 4 つのプライマリ パーティションをサポートします。 2. GPT はパーティションの数によって制限されません。 2. サポートされるハードドライブのサイズ: 1. MBR は最大 2TB までのみサポートします
 コンピューターのハードドライブが GPT または MBR のどちらのパーティション分割方法を使用しているかを確認する方法
Dec 25, 2023 pm 10:57 PM
コンピューターのハードドライブが GPT または MBR のどちらのパーティション分割方法を使用しているかを確認する方法
Dec 25, 2023 pm 10:57 PM
コンピュータのハードディスクが GPT パーティションか MBR パーティションかを確認するにはどうすればよいですか? コンピュータのハードディスクを使用するとき、GPT と MBR を区別する必要があります。実際、この確認方法は非常に簡単です。一緒に見てみましょう。コンピュータのハードドライブが GPT または MBR であることを確認する方法 1. デスクトップのコンピュータを右クリックし、[管理] をクリックします。 2. [管理] で [ディスクの管理] を見つけます。 3. ディスクの管理に入り、ディスクの一般的なステータスを確認します。 4. 「プロパティ」の「ボリューム」タブに切り替えると、「ディスク パーティション フォーム」が表示されます。 「MBR パーティション win10 ディスクに関連する問題 MBR パーティションを GPT パーティションに変換する方法 >」として表示されます。
 LLM の 3 つの大きな欠陥のうち、いくつ知っていますか?
Nov 26, 2023 am 11:26 AM
LLM の 3 つの大きな欠陥のうち、いくつ知っていますか?
Nov 26, 2023 am 11:26 AM
科学: 将来の知覚を備えた汎用 AI は、永遠に慈悲深く有益な存在であるとは程遠く、個人データをすべて食い尽くし、最も必要なときに崩壊する操作的な社会病質者になる可能性があります。 3WaysLLMsCanLetYouDown、著者 JoabJackson からの翻訳。 OpenAI は GPT-5 をリリースしようとしており、外部の世界は GPT-5 に大きな期待を寄せており、最も楽観的な予測では汎用人工知能が実現されるとさえ信じられています。しかし同時に、CEOのサム・アルトマン氏とそのチームは、これを市場に出すには多くの深刻な障害に直面していることを、同氏は今月初めに認めた。最近発表された研究論文には、アルトマン氏の挑戦への手がかりを提供する可能性のあるものがいくつかある。これらの論文の要約
 GPT 大規模言語モデル Alpaca-lora ローカリゼーション展開の実践
Jun 01, 2023 pm 09:04 PM
GPT 大規模言語モデル Alpaca-lora ローカリゼーション展開の実践
Jun 01, 2023 pm 09:04 PM
モデルの紹介: Alpaca モデルは、スタンフォード大学によって開発された LLM (Large Language Model、大規模言語) オープン ソース モデルです。LLaMA7B (Meta 社による 7B オープン ソース) モデルから 52K 命令で微調整されています。モデル パラメーター (モデル パラメーターが大きいほど、モデルの推論能力が強くなります。もちろん、モデルのトレーニングのコストも高くなります)。 LoRA は、正式な英語名は Low-RankAdaptation of Large Language Models で、直訳すると大規模言語モデルの低レベル適応と訳され、大規模言語モデルの微調整を解決するために Microsoft の研究者によって開発されたテクノロジです。事前トレーニングされた大規模な言語モデルで特定のドメインを実行できるようにしたい場合
 ビル・ゲイツが選んだ GPT テクノロジーはどのように進化し、誰の生活に革命をもたらしましたか?
May 28, 2023 pm 03:13 PM
ビル・ゲイツが選んだ GPT テクノロジーはどのように進化し、誰の生活に革命をもたらしましたか?
May 28, 2023 pm 03:13 PM
Xi Xiaoyao Science and Technology Talks 原著者 | IQ が完全に低下した Python 機械が人間と同じように理解し、コミュニケーションできるようになったらどうなるでしょうか?これは学術コミュニティで大きな関心を集めているテーマであり、近年の自然言語処理における一連の画期的な進歩のおかげで、私たちはこの目標の達成にこれまで以上に近づいているかもしれません。この画期的な進歩の最前線にあるのは、自然言語処理タスク用に特別に設計されたディープ ニューラル ネットワーク モデルである Generative Pre-trained Transformer (GPT) です。その優れたパフォーマンスと効果的な会話を行う能力により、この分野で最も広く使用され、効果的なモデルの 1 つとなり、研究や業界から大きな注目を集めています。最近の詳しい内容では
 ソリッド ステート ドライブは mbr または gpt に初期化されていますか?
Mar 10, 2023 pm 02:48 PM
ソリッド ステート ドライブは mbr または gpt に初期化されていますか?
Mar 10, 2023 pm 02:48 PM
ソリッド ステート ドライブは gpt に初期化されます。 GPT は、パーティション サイズとパーティション数の利点があり、より高度で堅牢であるため、すべてのコンピュータ システムが GPT に移行しつつあり、新しい標準であり、将来的には MBR を徐々に置き換える予定です。また、Microsoft は、Windows 11 システムが GPT と UEFI のみをサポートすると公式に発表したため、Windows システムを Windows 11 にアップグレードすることを検討している場合は、まず MBR を GPT に変換する必要があります。
