

Redis ブルーム フィルター サイズのアルゴリズム式は何ですか?

1. はじめに
クライアント: このキーは存在しますか?
サーバー: 存在しません/わかりません
ブルーム フィルターは比較的賢い確率的データ構造であり、その本質はデータ構造です。効率的な挿入とクエリが特徴です。しかし、特定の構造にキーが存在するかどうかを確認したい場合、ブルームフィルターを使用すると、「このキーは存在してはいけない、または存在する可能性がある」ことがすぐにわかります。 List、Set、Map などの従来のデータ構造と比較すると、より効率的で使用するスペースが少なくなりますが、返される結果は確率的で不正確です。
ブルーム フィルターは、コレクション内のメンバーシップをテストするためにのみ使用されます。古典的なブルーム フィルターの例は、存在しないキーに対する高価なディスク (またはネットワーク) の検索を削減することで効率を向上させることです。ご覧のとおり、ブルーム フィルターは O(k) 定数時間 (k はハッシュ関数の数) でキーを検索でき、キーが存在しないことのテストは非常に高速になります。
2. アプリケーション シナリオ
2.1 キャッシュの侵入
アクセス効率を向上させるために、一部のデータを Redis キャッシュに置きます。データクエリを実行する場合、データベースを読み取ることなく、まずキャッシュからデータを取得できます。これにより、パフォーマンスを効果的に向上させることができます。
データをクエリする場合は、まずキャッシュにデータがあるかどうかを判断し、データがある場合はキャッシュから直接データを取得します。
ただし、データがない場合は、データベースからデータを取得してキャッシュに入れる必要があります。多数のアクセスがキャッシュにヒットしない場合、データベースに多大な負荷がかかり、データベースがクラッシュする原因になります。ブルーム フィルターを使用すると、存在しないキャッシュにアクセスするときに、すぐに戻ってキャッシュや DB のクラッシュを回避できます。
2.2 大量のデータに特定のデータが存在するかどうかを確認する
HBase には非常に大量のデータが格納されます。特定の ROWKEYS または特定の列が存在するかどうかを確認するには、ブルーム フィルターを使用します。特定のデータが存在するかどうかをすばやく取得します。しかし、一定の誤判断率は存在します。ただし、キーが存在しない場合は、正確である必要があります。
3. HashMap の問題
要素が存在するかどうかを判断するには、HashMap を使用すると効率が非常に高くなります。 HashMap は、値を HashMap キーにマッピングすることで、O(1) の定数時間計算量を実現できます。
ただし、保存されているデータの量が非常に多い場合 (例: 数億のデータ)、HashMap は非常に大量のメモリを消費します。そして、大量のデータを一度にメモリに読み込むことはまったく不可能です。
4. ブルーム フィルターの動作原理図を理解する
:
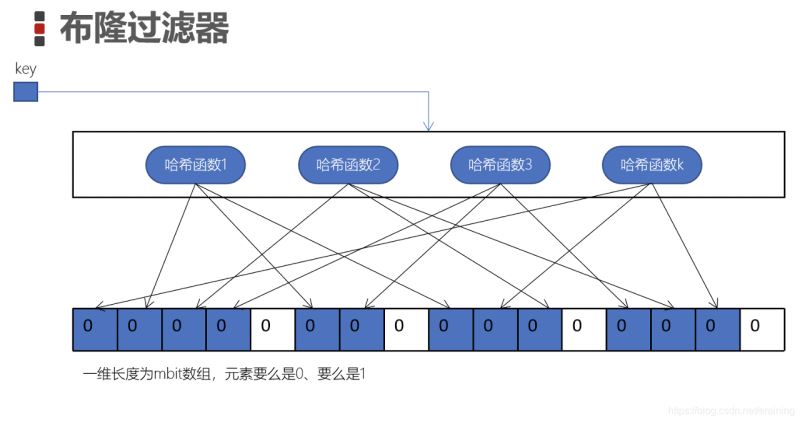
ブルーム フィルターはビット配列またはビット バイナリ ベクトルです
この配列の要素は 0 または 1 です。
k 個のハッシュ関数は互いに独立しており、各ハッシュ関数の計算結果は配列の長さ m を法として、対応するビットを 1 に設定します (青いセル)
このようにセルに各キーを設定します。これが「ブルームフィルター」です
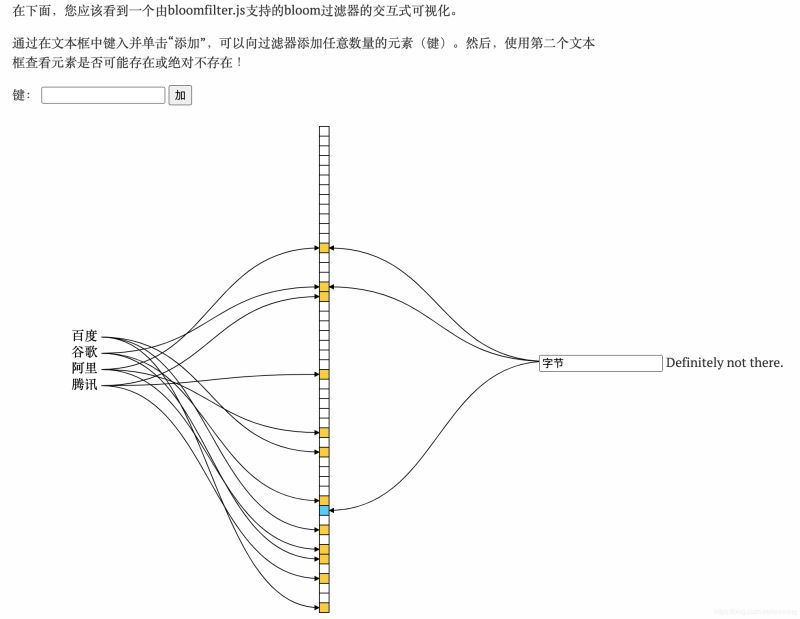
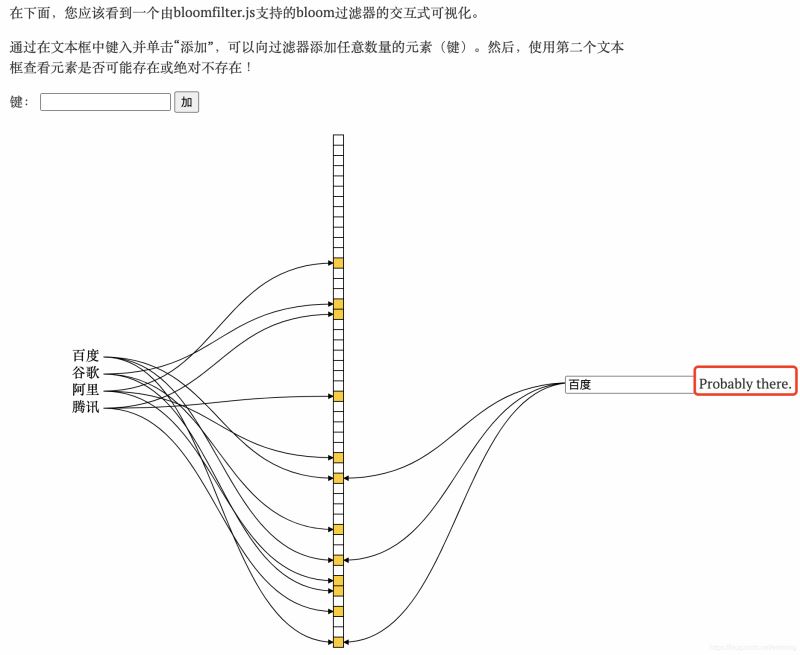
5. クロスのロングフィルタークエリ要素に従って
キーがが入力されたら、前の k 個のハッシュ関数を使用してハッシュを見つけ、k 個の値を取得します。
k 個の値がすべて青であるかどうかを判断します。1 つが青でない場合、キーは存在してはなりません
両方とも青色の場合、キーが存在する可能性があります (ブルームフィルターにより誤判定が発生します)
入力オブジェクトが多く、セットが比較的小さい場合は、結果として、コレクション内のほとんどの位置が青色で塗りつぶされます。すると、あるキーが青にチェックされると、たまたまある位置が青に設定されてしまい、このときそのキーがコレクション内にあると誤解されてしまいます。
 従来のブルーム フィルターは削除操作をサポートしていません。ただし、Counting Bloom フィルターと呼ばれるバリアントを使用すると、要素カウント数が特定のしきい値より絶対に小さいかどうかをテストでき、要素の削除がサポートされます。 Counting Bloom Filter の記事の原理と実装については非常に詳しく書かれており、詳しく読むことができます。
従来のブルーム フィルターは削除操作をサポートしていません。ただし、Counting Bloom フィルターと呼ばれるバリアントを使用すると、要素カウント数が特定のしきい値より絶対に小さいかどうかをテストでき、要素の削除がサポートされます。 Counting Bloom Filter の記事の原理と実装については非常に詳しく書かれており、詳しく読むことができます。
7. ハッシュ関数の数とブルーム フィルターの長さの選択方法
明らかに、ブルーム フィルターが小さすぎると、すぐにすべてのビットが 1 になり、その後は任意の値が可能になります。クエリを実行すると、すべてが「存在する可能性があります」を返します。これでは、フィルタリングの目的が無効になります。ブルーム フィルターの長さが増加するにつれて、その誤検出率は減少します。
さらに、ハッシュ関数の数も考慮する必要があります。数が多いほど、ブルーム フィルターのビット位置が 1 に設定される速度が速くなり、ブルーム フィルターの効率が低下します。少なすぎる場合、誤警報率が高くなります。
上の図からわかるように、ハッシュ関数 k の数を増やすと、エラー率 p が大幅に減少します。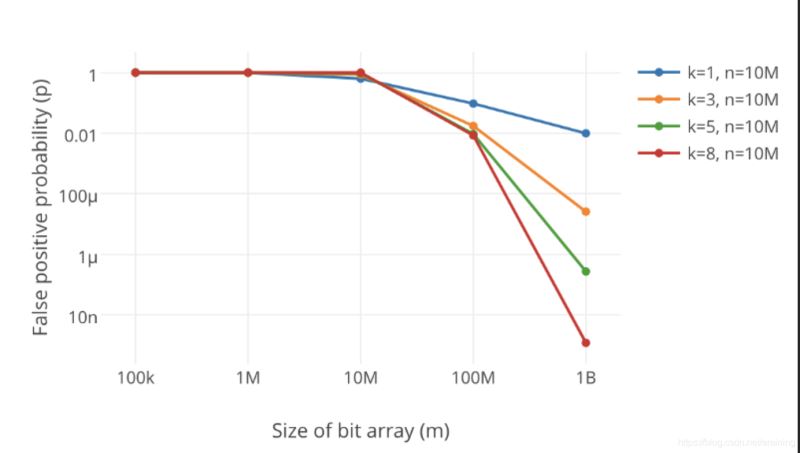
心配しないでください。実際には、m と k の値を確認する必要があります。次に、フォールト トレランス p と要素の数 n を指定すると、これらのパラメーターは次の式を使用して計算できます。
これらのパラメーターは、フィルターのサイズ m、ハッシュの数に基づいて計算できます。関数 k と挿入された要素の数 n 誤警報率 p を計算するための式は次のとおりです。 上記に基づいて、ビジネスに適した k と m の値をどのように選択するか?
式:
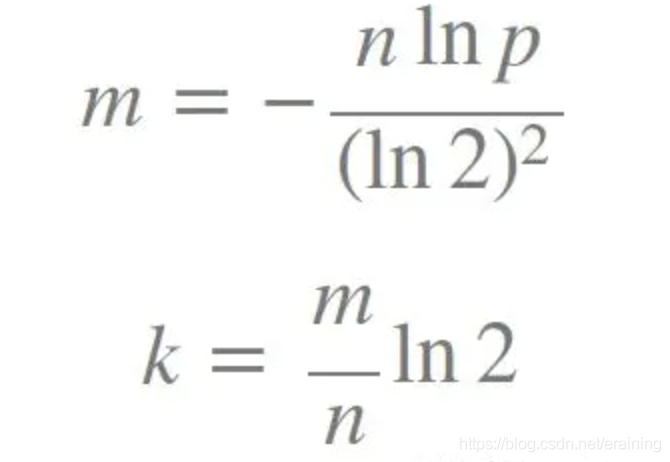
k はハッシュ関数の数、m はブルーム フィルターの長さ、n は挿入された要素の数、p は誤検知率です。
この公式の導出方法については、Zhihuに記事を掲載しましたので、興味のある方は読んでいただければと思いますが、興味のない方は上の公式を覚えておいてください。
ここでもう一つ重要な点についても触れておきたいと思います。ブルームフィルターを使用する唯一の目的は検索を高速化することなので、遅いハッシュ関数を使用することはできません。暗号化ハッシュ関数 (Sha-1、MD5 など) は少し遅いため、ブルーム フィルターには適していません。したがって、より高速なハッシュ関数実装のより良い選択肢は、murmur、fnv ファミリ ハッシュ、Jenkins ハッシュ、および HashMix です。
その他のアプリケーション シナリオ
指定された例では、これを使用してユーザーに脆弱なパスワードを入力することを警告できることがわかりました。
ブルーム フィルターを使用すると、ユーザーが悪意のある Web サイトにアクセスするのを防ぐことができます。
SQL データベースにクエリを実行して、特定の電子メールを持つユーザーが存在するかどうかを確認する代わりに、まず Bloom ブルーム フィルターを使用して簡単な検索チェックを行うことができます。メールが存在しない場合でも問題ありません。存在する場合は、データベースに対して追加のクエリを実行する必要がある場合があります。同様の操作を行って、「ユーザー名はすでに使用されています」を検索することもできます。
Web サイト訪問者の IP アドレスに基づいてブルーム フィルターを保持し、Web サイトのユーザーが「リピーター」であるか「新規ユーザー」であるかを確認できます。 「リピーター」による誤検知がいくつかあったとしても、害を及ぼすことはありません。
ブルーム フィルターを使用して辞書の単語を追跡することで、スペル チェックを行うこともできます。
以上がRedis ブルーム フィルター サイズのアルゴリズム式は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7680
7680
 15
1393
52
1209
24
91
11
15
1393
52
1209
24
91
11

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisを使用して操作をロックするには、setnxコマンドを介してロックを取得し、有効期限を設定するために有効期限コマンドを使用する必要があります。特定の手順は次のとおりです。(1)SETNXコマンドを使用して、キー価値ペアを設定しようとします。 (2)expireコマンドを使用して、ロックの有効期限を設定します。 (3)Delコマンドを使用して、ロックが不要になったときにロックを削除します。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインツール(Redis-Cli)を使用して、次の手順を使用してRedisを管理および操作します。サーバーに接続し、アドレスとポートを指定します。コマンド名とパラメーターを使用して、コマンドをサーバーに送信します。ヘルプコマンドを使用して、特定のコマンドのヘルプ情報を表示します。 QUITコマンドを使用して、コマンドラインツールを終了します。
 Centos RedisでLUAスクリプト実行時間を構成する方法
Apr 14, 2025 pm 02:12 PM
Centos RedisでLUAスクリプト実行時間を構成する方法
Apr 14, 2025 pm 02:12 PM
Centosシステムでは、Redis構成ファイルを変更するか、Redisコマンドを使用して悪意のあるスクリプトがあまりにも多くのリソースを消費しないようにすることにより、LUAスクリプトの実行時間を制限できます。方法1:Redis構成ファイルを変更し、Redis構成ファイルを見つけます:Redis構成ファイルは通常/etc/redis/redis.confにあります。構成ファイルの編集:テキストエディター(VIやNANOなど)を使用して構成ファイルを開きます:sudovi/etc/redis/redis.conf luaスクリプト実行時間制限を設定します。
