

Redis最適化例の分析

メモリ ディメンション
キーの長さの制御
キーは通常文字列であり、文字列の基礎となるデータ構造は SDS です。SDS 構造には文字列の長さ、割り当てが含まれます。スペースサイズなどのメタデータ情報。キー文字列の長さが増加すると、SDS 内のメタデータもより多くのメモリスペースを占有します。キーが占めるスペースを減らすために、ビジネス名に応じて対応する英語の略語を使用できます。それを表すために。たとえば、ユーザーは u で表され、メッセージは m で表されます。
bigkey の保存を避ける
キーの長さと値のサイズの両方に注意する必要があります。Redis はデータの読み取りと書き込みに単一のスレッドを使用します。読み取りおよび書き込み操作bigkey を使用するとスレッドがブロックされ、コストが削減され、Redis の処理効率が向上します。
bigkey をクエリする方法
--bigkey コマンドを使用して、Redis にある bigkey 情報を表示できます。具体的なコマンドは次のとおりです:
redis-cli -h 127.0.0.1 -p 6379 -a 'xxx' --bigkeys
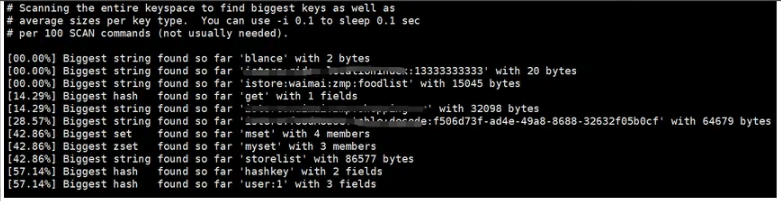
上の図に示すように、Redis のキーは 32098 バイトを占めており、最適化する必要があることがわかります。
推奨事項:
キーが文字列型の場合、値に格納される値のサイズは約 10KB にすることをお勧めします。 。
キーが List/Hash/Set/ZSet タイプの場合、格納される要素の数は 10,000 未満に制御することをお勧めします。
適切なデータ型の選択
Redis は、保存するデータ型に合わせて最適化され、それに応じてメモリも最適化されます。データ結果に関する関連知識については、以前の記事を参照してください。
例: String と set は、int データを格納するときに整数エンコーディングを使用します。 Hash と ZSet は、要素の数が比較的少ない場合は圧縮リスト (ziplist) ストレージを使用し、比較的大量のデータが格納される場合はハッシュ テーブルとジャンプ テーブルに変換します。
効率的なシリアル化と圧縮方法を採用する
Redis の文字列はバイナリセーフなバイト配列を使用して保存されるため、ビジネスをバイナリにシリアル化し、それを Redis に書き込むことができますが、別のシリアル化を使用すると、占有スペースが異なります。 Protostuff のシリアル化は、Java の組み込みシリアル化よりも効率的で、占有するスペースも少なくなります。スペース使用量を削減するために、JSON および XML データ形式を圧縮して保存できます。オプションの圧縮アルゴリズムには、Gzip や Snappy が含まれます。
Redis の最大メモリと排除戦略の設定
Redis メモリが継続的に拡張されて過剰なリソース使用量が発生することを避けるために、ビジネス データの量に基づいてメモリ サイズを事前に見積もります。 。
# 消去戦略の設定方法については、実際のビジネス特性に基づいて選択する必要があります:
#volatile-lru / allkeys- lru: 最近アクセスされたデータを優先する
- ##volatile-lfu / allkeys-lfu:
最も頻繁にアクセスされるデータを優先する
- volatile-ttl:
期限切れが近づいているデータの削除を優先します
- volatile-random / allkeys-random:
ランダム削除データ
Redis インスタンスのサイズを制御する
単一 Redis インスタンスのメモリ サイズは 2 ~ 6GB に設定することをお勧めします。 RDBスナップショットやマスタ・スレーブクラスタのデータ同期は高速に完了できるため、通常のリクエストの処理が妨げられることはありません。
メモリの断片を定期的にクリアする
新しい変更を頻繁に行うとメモリの断片が増加するため、メモリの断片は適時にクリーンアップする必要があります。
Redis には、次のようなメモリ使用量情報を表示するための Info メモリ コマンドが用意されています。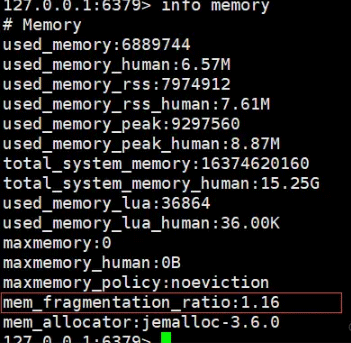
- used_memory_rss は、オペレーティング システムによって Redis に実際に割り当てられた物理メモリ領域です。
- used_memory は、データを保存するために Redis によって実際に適用されるスペースです。
- mem_fragmentation_ratio=used_memory_rss/ used_memory
- mem_fragmentation_ratio は 1 より大きく 1.5 未満です。この状況は合理的です。
- mem_fragmentation_ratio が 1.5 より大きい場合、メモリの断片化率が 50% を超えていることを意味します。この場合、通常、メモリの断片化率を減らすために何らかの措置を講じる必要があります。具体的なメモリクリーニング対策については、以降の記事で解説します。
- パフォーマンス ディメンション
KEYS、FLUSHALL、および FLUSHDB コマンドの使用は禁止されています
- KEYS はキーに応じて一致します内容と一致を返します 一致 条件のキーと値のペア このコマンドでは、Redis グローバル ハッシュ テーブルのフル テーブル スキャンが必要であり、これにより Redis メイン スレッドが大幅にブロックされます。
- FLUSHALL は、Redis インスタンス上のすべてのデータを削除します。データの量が多い場合、Redis メイン スレッドが大幅にブロックされます。
- FLUSHDB は、現在のデータベースのデータを削除します。データの量が多い場合、Redis メイン スレッドがブロックされます。
- 最適化の提案
これらのコマンドをオンラインで無効にする必要があります。具体的な方法は、管理者が rename-command コマンドを使用して設定ファイル内のこれらのコマンドの名前を変更し、クライアントがこれらのコマンドを使用できないようにすることです。
慎用全量操作的命令
对于集合类型的来说,在未清楚集合数据大小的情况下,慎用查询集合中的全量数据,例如Hash的HetALL、Set的SMEMBERS命令、LRANGE key 0 -1 或者ZRANGE key 0 -1等命令,因为这些命令会对Hash或者Set类型的底层数据进行全量扫描,当集合数据量比较大时,会阻塞Redis的主线程。
优化建议:
当元素数据量较多时,可以用SSCAN、HSCAN 命令分批返回集合中的数据,减少对主线程的阻塞。
慎用复杂度过高命令
Redis执行复杂度过高的命令,会消耗更多的 CPU 资源,导致主线程中的其它请求只能等待。常见的复杂命令如下:SORT、SINTER、SINTERSTORE、ZUNIONSTORE、ZINTERSTORE 等聚合类命令。
优化建议:
当需要执行排序、交集、并集操作时,可以在客户端完成,避免让Redis进行过多计算,从而影响Redis性能。
设置合适的过期时间
Redis通常用于保存热数据。热数据一般都有使用的时效性。因此,在数据存储的过程中,应根据业务对数据的使用时间合理地设置数据的过期时间。否则写入Redis的数据会一直占用内存,如果数据持续增增长,会达到机器的内存上限,造成内存溢出,导致服务崩溃。
采用批量命令代替个命令
当我们需要一次性操作多个key时,可以使用批量命令来处理,批量命令可以减少客户端与服务端的来回网络IO次数。
String或者Hash类型可以使用 MGET/MSET替代 GET/SET,HMGET/HMSET替代HGET/HSET
其它数据类型使用Pipeline命令,一次性打包发送多个命令到服务端执行。
Pipeline具体使用:
redisTemplate.executePipelined(new RedisCallback<String>() {
@Override
public String doInRedis(RedisConnection connection) throws DataAccessException {
for (int i = 0; i < 5; i++)
{
connection.set(("test:" + i).getBytes(), "test".getBytes());
}
return null;
}
});高可用维度
按照业务部署不同的实例
不同的业务线来部署 Redis 实例,这样当其中一个实例发生故障时,不会影响到其它业务。
避免单点问题
业务上根据实际情况采用主从、哨兵、集群方案,避免单点故障,影响业务的正常使用。
合理的设置相关参数
针对主从环境,我们需要合理设置相关参数,具体内容如下:
合理的设置repl-backlog参数:如果repl-backlog设置过小,当写流量比较大的场景下,主从复制中断可能会引发全量复制数据的风险。
合理设置slave client-output-buffer-limit:当从库复制发生问题时,过小的 buffer会导致从库缓冲区溢出,从而导致复制中断。
以上がRedis最適化例の分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 Windows 11 10.0.22000.100 のインストール時の 0x80242008 エラーの解決策
May 08, 2024 pm 03:50 PM
Windows 11 10.0.22000.100 のインストール時の 0x80242008 エラーの解決策
May 08, 2024 pm 03:50 PM
1. [スタート]メニューを起動し、[cmd]と入力し、[コマンドプロンプト]を右クリックし、[管理者として実行]を選択します。 2. 次のコマンドを順番に入力します (注意してコピーして貼り付けてください): SCconfigwuauservstart=auto、Enter キーを押す SCconfigbitsstart=auto、Enter キーを押す SCconfigcryptsvcstart=auto、Enter キーを押す SCconfigtrustedinstallerstart=auto、Enter キーを押す SCconfigwuauservtype=share、Enter キーを押す netstopwuauserv 、enter netstopcryptS を押す
 Golang API のキャッシュ戦略と最適化
May 07, 2024 pm 02:12 PM
Golang API のキャッシュ戦略と最適化
May 07, 2024 pm 02:12 PM
GolangAPI のキャッシュ戦略により、パフォーマンスが向上し、サーバーの負荷が軽減されます。一般的に使用される戦略は、LRU、LFU、FIFO、TTL です。最適化手法には、適切なキャッシュ ストレージの選択、階層型キャッシュ、無効化管理、監視とチューニングが含まれます。実際には、データベースからユーザー情報を取得する API を最適化するために LRU キャッシュが使用されます。それ以外の場合は、データベースからデータを取得した後にキャッシュを更新できます。
 PHP 開発におけるキャッシュ メカニズムとアプリケーションの実践
May 09, 2024 pm 01:30 PM
PHP 開発におけるキャッシュ メカニズムとアプリケーションの実践
May 09, 2024 pm 01:30 PM
PHP 開発では、キャッシュ メカニズムにより、頻繁にアクセスされるデータがメモリまたはディスクに一時的に保存され、データベース アクセスの数が削減され、パフォーマンスが向上します。キャッシュの種類には主にメモリ、ファイル、データベース キャッシュが含まれます。キャッシュは、組み込み関数またはサードパーティのライブラリ (cache_get() や Memcache など) を使用して PHP に実装できます。一般的な実用的なアプリケーションには、データベース クエリ結果をキャッシュしてクエリ パフォーマンスを最適化したり、ページ出力をキャッシュしてレンダリングを高速化したりすることが含まれます。キャッシュ メカニズムにより、Web サイトの応答速度が効果的に向上し、ユーザー エクスペリエンスが向上し、サーバーの負荷が軽減されます。
 Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法_Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法
May 08, 2024 pm 05:10 PM
Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法_Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法
May 08, 2024 pm 05:10 PM
まず、システム言語を簡体字中国語表示に設定して再起動する必要があります。もちろん、以前に表示言語を簡体字中国語に変更したことがある場合は、この手順をスキップできます。次に、レジストリ regedit.exe の操作を開始し、左側のナビゲーション バーまたは上部のアドレス バーで HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsLanguage に直接移動し、InstallLanguage キーの値と Default キーの値を 0804 に変更します (英語に変更する場合)。まずシステムの表示言語を en-us に設定し、システムを再起動してから、すべてを 0409 に変更します) この時点でシステムを再起動する必要があります。
 PHP 配列のページネーションで Redis キャッシュを使用するにはどうすればよいですか?
May 01, 2024 am 10:48 AM
PHP 配列のページネーションで Redis キャッシュを使用するにはどうすればよいですか?
May 01, 2024 am 10:48 AM
Redis キャッシュを使用すると、PHP 配列ページングのパフォーマンスを大幅に最適化できます。これは、次の手順で実現できます。 Redis クライアントをインストールします。 Redisサーバーに接続します。キャッシュ データを作成し、データの各ページをキー「page:{page_number}」を持つ Redis ハッシュに保存します。キャッシュからデータを取得し、大規模な配列での高コストの操作を回避します。
 Win11でダウンロードしたアップデートファイルの探し方_Win11でダウンロードしたアップデートファイルの場所を共有する
May 08, 2024 am 10:34 AM
Win11でダウンロードしたアップデートファイルの探し方_Win11でダウンロードしたアップデートファイルの場所を共有する
May 08, 2024 am 10:34 AM
1. まず、デスクトップ上の[このPC]アイコンをダブルクリックして開きます。 2. 次に、マウスの左ボタンをダブルクリックして [C ドライブ] に入ります。システム ファイルは通常、自動的に C ドライブに保存されます。 3. 次に、C ドライブで [windows] フォルダーを見つけ、ダブルクリックしてに入ります。 4. [windows]フォルダーに入ったら、[SoftwareDistribution]フォルダーを見つけます。 5. 入力後、win11 のダウンロード ファイルとアップデート ファイルがすべて含まれている [ダウンロード] フォルダーを見つけます。 6. これらのファイルを削除したい場合は、このフォルダー内で直接削除してください。
 PHP Redis キャッシュ アプリケーションとベスト プラクティス
May 04, 2024 am 08:33 AM
PHP Redis キャッシュ アプリケーションとベスト プラクティス
May 04, 2024 am 08:33 AM
Redis は、高性能のキー/値キャッシュです。 PHPRedis 拡張機能は、Redis サーバーと対話するための API を提供します。 Redis に接続し、データを保存および取得するには、次の手順を使用します。 接続: Redis クラスを使用してサーバーに接続します。ストレージ: set メソッドを使用してキーと値のペアを設定します。取得: get メソッドを使用してキーの値を取得します。
 Docker環境にPECLを使用して拡張機能をインストールするときにエラーが発生するのはなぜですか?それを解決する方法は?
Apr 01, 2025 pm 03:06 PM
Docker環境にPECLを使用して拡張機能をインストールするときにエラーが発生するのはなぜですか?それを解決する方法は?
Apr 01, 2025 pm 03:06 PM
エラーの原因とソリューションPECLを使用してDocker環境に拡張機能をインストールする場合、Docker環境を使用するときに、いくつかの頭痛に遭遇します...
