

Spring Cache に基づいて Caffeine+Redis の 2 次キャッシュを実装する方法

詳細は次のとおりです:
1. ハードコーディングされたキャッシュとは何ですか?
Spring Cache を学ぶ前、私はハードコーディングされた方法でキャッシュをよく使用していました。
実際の例を見てみましょう。ユーザー情報のクエリ効率を向上させるために、ユーザー情報のキャッシュを使用します。サンプルコードは次のとおりです。
@Autowire
private UserMapper userMapper;
@Autowire
private RedisCache redisCache;
//查询用户
public User getUserById(Long userId) {
//定义缓存key
String cacheKey = "userId_" + userId;
//先查询redis缓存
User user = redisCache.get(cacheKey);
//如果缓存中有就直接返回,不再查询数据库
if (user != null) {
return user;
}
//没有再查询数据库
user = userMapper.getUserById(userId);
//数据存入缓存,这样下次查询就能到缓存中获取
if (user != null) {
stringCommand.set(cacheKey, user);
}
return user;
}多くの学生が書いたと思います。このコードのスタイルは、プロセス指向のプログラミングの考え方に沿っており、非常に理解しやすいものです。しかし、これにはいくつかの欠点もあります。
コードは十分にエレガントではありません。ビジネス ロジックには、ストレージ、読み取り、変更、および削除という 4 つの典型的なアクションがあります。各操作ではキャッシュ キーを定義し、キャッシュ コマンドの API を呼び出す必要があります。これにより、繰り返しコードが大量に生成されます。
キャッシュ操作とビジネス ロジック間のコードの結合度が高く、非常に侵入的です。ビジネスロジックに。この侵入性は、主に次の 2 つの点を反映しています。
開発および共同デバッグ段階では、キャッシュを削除する必要があり、キャッシュのオペレーション コードはコメント化または一時的にのみ可能です。削除され、エラーが発生する可能性もあります;
シナリオによっては、キャッシュ コンポーネントを交換する必要があります。各キャッシュ コンポーネントには独自の API があり、交換コストがかかりますかなり高いです。
こうなったら、もっとエレガントになると思いませんか?
@Mapper
public interface UserMapper {
/**
* 根据用户id获取用户信息
*
* 如果缓存中有直接返回缓存数据,如果没有那么就去数据库查询,查询完再插入缓存中,这里缓存的key前缀为cache_user_id_,+传入的用户ID
*/
@Cacheable(key = "'cache_user_id_' + #userId")
User getUserById(Long userId);
}実装クラスをもう一度見てください
@Autowire
private UserMapper userMapper;
//查询用户
public User getUserById(Long userId) {
return userMapper.getUserById(userId);
}キャッシュから完全に分離されているかどうかを確認してみましょう。開発および共同デバッグの段階でキャッシュを削除する必要がある場合は、コメントアウトしてください。注釈を直接貼り付けますよね? 非常に完璧です。
そして、この実装セット全体を手動で記述する必要はありません。Spring Cache は関連する理解とインターフェイスをすでに定義しているので、上記の関数を簡単に実装できます。
2. Spring Cache の概要
Spring Cache は、Spring-context パッケージで提供されるアノテーションベースのキャッシュ コンポーネントです。いくつかの標準インターフェイスを定義しています。これらのインターフェイスを実装することで、次のことができます。
メソッドにアノテーションを追加してキャッシュを実装します。これにより、キャッシュ コードとビジネス処理の結合の問題が回避されます。
Spring Cache のコア インターフェイスは 2 つだけです: Cache と CacheManager
1. キャッシュ インターフェイス
このインターフェイスの定義キャッシュの配置、読み取り、クリーニングなどのキャッシュの特定の操作を提供します:
package org.Springframework.cache;
import java.util.concurrent.Callable;
public interface Cache {
// cacheName,缓存的名字,默认实现中一般是CacheManager创建Cache的bean时传入cacheName
String getName();
//得到底层使用的缓存,如Ehcache
Object getNativeCache();
// 通过key获取缓存值,注意返回的是ValueWrapper,为了兼容存储空值的情况,将返回值包装了一层,通过get方法获取实际值
ValueWrapper get(Object key);
// 通过key获取缓存值,返回的是实际值,即方法的返回值类型
<T> T get(Object key, Class<T> type);
// 通过key获取缓存值,可以使用valueLoader.call()来调使用@Cacheable注解的方法。当@Cacheable注解的sync属性配置为true时使用此方法。
// 因此方法内需要保证回源到数据库的同步性。避免在缓存失效时大量请求回源到数据库
<T> T get(Object key, Callable<T> valueLoader);
// 将@Cacheable注解方法返回的数据放入缓存中
void put(Object key, Object value);
// 当缓存中不存在key时才放入缓存。返回值是当key存在时原有的数据
ValueWrapper putIfAbsent(Object key, Object value);
// 删除缓存
void evict(Object key);
// 清空缓存
void clear();
// 缓存返回值的包装
interface ValueWrapper {
// 返回实际缓存的对象
Object get();
}
}2. CacheManager インターフェイス
は主に、cacheName を通じてアクセスできるキャッシュ実装 Bean の作成を提供します。キャッシュは分離されており、各キャッシュ名はキャッシュ実装に対応します。
package org.Springframework.cache;
import java.util.Collection;
public interface CacheManager {
// 通过cacheName创建Cache的实现bean,具体实现中需要存储已创建的Cache实现bean,避免重复创建,也避免内存缓存
//对象(如Caffeine)重新创建后原来缓存内容丢失的情况
Cache getCache(String name);
// 返回所有的cacheName
Collection<String> getCacheNames();
}3. 一般的に使用されるアノテーション
@Cacheable: 主にデータのクエリ方法に適用されます。
public @interface Cacheable {
// cacheNames,CacheManager就是通过这个名称创建对应的Cache实现bean
@AliasFor("cacheNames")
String[] value() default {};
@AliasFor("value")
String[] cacheNames() default {};
// 缓存的key,支持SpEL表达式。默认是使用所有参数及其计算的hashCode包装后的对象(SimpleKey)
String key() default "";
// 缓存key生成器,默认实现是SimpleKeyGenerator
String keyGenerator() default "";
// 指定使用哪个CacheManager,如果只有一个可以不用指定
String cacheManager() default "";
// 缓存解析器
String cacheResolver() default "";
// 缓存的条件,支持SpEL表达式,当达到满足的条件时才缓存数据。在调用方法前后都会判断
String condition() default "";
// 满足条件时不更新缓存,支持SpEL表达式,只在调用方法后判断
String unless() default "";
// 回源到实际方法获取数据时,是否要保持同步,如果为false,调用的是Cache.get(key)方法;如果为true,调用的是Cache.get(key, Callable)方法
boolean sync() default false;
}@CacheEvict: キャッシュをクリアします。主にデータの削除に使用されます。 Cacheable と比較すると、キャッシュに入れられる属性
public @interface CacheEvict {
// ...相同属性说明请参考@Cacheable中的说明
// 是否要清除所有缓存的数据,为false时调用的是Cache.evict(key)方法;为true时调用的是Cache.clear()方法
boolean allEntries() default false;
// 调用方法之前或之后清除缓存
boolean beforeInvocation() default false;
}@CachePut がさらに 2 つあり、主にデータの更新に使用されます。属性の説明については、@Cacheable
@Caching: 1 つのメソッドで複数のアノテーションを構成するために使用されます
@EnableCaching: Spring キャッシュを有効にするキャッシュ、一般的なスイッチとして、このアノテーションを有効にするには、SpringBoot スタートアップ クラスまたは構成クラスに追加する必要があります。
3. 2 次キャッシュを使用するときに考慮する必要がある問題は何ですか?
リレーショナル データベース (Mysql) のデータは最終的にディスクに保存されることがわかっていますが、毎回データベースから読み取る場合、読み取り速度はディスク自体の IO に影響されるため、
redis のようなメモリ キャッシュ。
メモリ キャッシュによりクエリ速度は確かに大幅に向上しますが、同じクエリの同時実行性が非常に高く、redis クエリが頻繁に行われる場合、明らかなネットワーク IO 消費も発生します。
この種の場合非常に頻繁にクエリされるデータ (ホットキー) については、カフェインなどのアプリケーション内キャッシュに保存することを検討できますか。
アプリケーション内キャッシュに修飾されたデータがある場合、ネットワーク経由で Redis からデータを取得することなく直接使用できるため、2 レベルのキャッシュが形成されます。
アプリケーション内キャッシュは第 1 レベル キャッシュと呼ばれ、リモート キャッシュ (redis など) は第 2 レベル キャッシュと呼ばれます。
プロセス全体は次のとおりです。
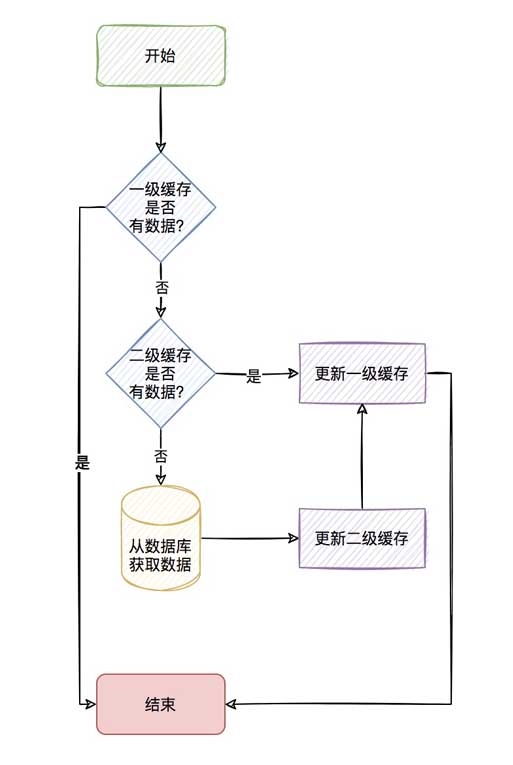
このプロセスは非常に新鮮に見えますが、実際には 2 次キャッシュには考慮すべき点がたくさんあります。
1.分散ノードの 1 次キャッシュの一貫性を確保するにはどうすればよいですか?
一次キャッシュはアプリケーション内キャッシュであるため、プロジェクトが複数のノードにデプロイされている場合、特定のキーを変更または削除したときに他のノードが確実に変更または削除されるようにするにはどうすればよいですか
の 1 次キャッシュの一貫性はどうですか?
2.null 値を格納することはできますか?
これは確かに考慮する必要がある点です。特定のクエリがキャッシュまたはデータベースにない場合、頻繁なデータベース クエリが発生し、データベースがダウンすることになるためです。これは、
がよくキャッシュ ペネトレーションと呼ぶものでもあります。
ただし、null 値を格納すると、大量の null 値が格納され、キャッシュが大きくなる可能性があるため、これを設定可能にして、ビジネスに応じて有効にするかどうかを決定するのが最善です。
3.キャッシュの予熱は必要ですか?
也就是说,我们会觉得某些key一开始就会非常的热,也就是热点数据,那么我们是否可以一开始就先存储到缓存中,避免缓存击穿。
4.一级缓存存储数量上限的考虑?
既然一级缓存是应用内缓存,那你是否考虑一级缓存存储的数据给个限定最大值,避免存储太多的一级缓存导致OOM。
5.一级缓存过期策略的考虑?
我们说redis作为二级缓存,redis是淘汰策略来管理的。具体可参考redis的8种淘汰策略。那你的一级缓存策略呢?就好比你设置一级缓存
数量最大为5000个,那当第5001个进来的时候,你是怎么处理呢?是直接不保存,还是说自定义LRU或者LFU算法去淘汰之前的数据?
6.一级缓存过期了如何清除?
我们说redis作为二级缓存,我们有它的缓存过期策略(定时、定期、惰性),那你的一级缓存呢,过期如何清除呢?
这里4、5、6小点如果说用我们传统的Map显然实现是很费劲的,但现在有更好用的一级缓存库那就是Caffeine。
四、Caffeine 简介
Caffeine,一个用于Java的高性能缓存库。
缓存和Map之间的一个根本区别是缓存会清理存储的项目。
1、写入缓存策略
Caffeine有三种缓存写入策略:手动、同步加载和异步加载。
2、缓存值的清理策略
Caffeine有三种缓存值的清理策略:基于大小、基于时间和基于引用。
基于容量:当缓存大小超过配置的大小限制时会发生回收。
基于时间:
写入后到期策略。
访问后过期策略。
到期时间由 Expiry 实现独自计算。
基于引用:启用基于缓存键值的垃圾回收。
Caffeine可以将值封装为弱引用或软引用,并且Java中还有强引用和虚引用这两种引用类型。
软引用:如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。
弱引用:在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会
回收它的内存。
3、统计
Caffeine提供了一种记录缓存使用统计信息的方法,可以实时监控缓存当前的状态,以评估缓存的健康程度以及缓存命中率等,方便后
续调整参数。
4、高效的缓存淘汰算法
缓存淘汰算法的目的是利用有限的资源,尽量预测哪些数据将会在短期内被频繁使用,以此来提高缓存的命中率。常用的缓存淘汰算法有
LRU、LFU、FIFO等。
FIFO:先进先出。选择最先进入的数据优先淘汰。 LRU:最近最少使用。选择最近最少使用的数据优先淘汰。 LFU:最不经常使用。选择在一段时间内被使用次数最少的数据优先淘汰。
LRU(Least Recently Used)算法认为最近访问过的数据将来被访问的几率也更高。
LRU通常使用链表来实现,如果数据添加或者被访问到则把数据移动到链表的头部,链表的头部为热数据,链表的尾部如冷数据,当
数据满时,淘汰尾部的数据。
LFU(Least Frequently Used)算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问
的频率也更高”。根据LFU的思想,如果想要实现这个算法,需要额外的一套存储用来存每个元素的访问次数,会造成内存资源的浪费。
Caffeine采用了一种结合LRU、LFU优点的算法:W-TinyLFU,其特点:高命中率、低内存占用。
5、其他说明
底层数据存储使用了ConcurrentHashMap。因为Caffeine面向JDK8,在jdk8中ConcurrentHashMap增加了红黑树,在hash冲突
严重时也能有良好的读性能。
五、基于Spring Cache实现二级缓存(Caffeine+Redis)
前面说了,使用了redis缓存,也会存在一定程度的网络传输上的消耗,所以会考虑应用内缓存,但有点很重要的要记住:
应用内缓存可以理解成比redis缓存更珍惜的资源,所以,caffeine 不适用于数据量大,并且缓存命中率极低的业务场景,如用户维度的缓存。
当前项目针对应用都部署了多个节点,一级缓存是在应用内的缓存,所以当对数据更新和清除时,需要通知所有节点进行清理缓存的操作。
可以有多种方式来实现这种效果,比如:zookeeper、MQ等,但是既然用了redis缓存,redis本身是有支持订阅/发布功能的,所以就
不依赖其他组件了,直接使用redis的通道来通知其他节点进行清理缓存的操作。
只需通过发布订阅机制通知其他节点删除该key在本地一级缓存中的条目,即可在key更新或删除操作后实现同步。
具体具体项目代码这里就不再粘贴出来了,这样只粘贴如何引用这个starter包。
1、maven引入使用
<dependency>
<groupId>com.jincou</groupId>
<artifactId>redis-caffeine-cache-starter</artifactId>
<version>1.0.0</version>
</dependency>2、application.yml
添加二级缓存相关配置
# 二级缓存配置
# 注:caffeine 不适用于数据量大,并且缓存命中率极低的业务场景,如用户维度的缓存。请慎重选择。
l2cache:
config:
# 是否存储空值,默认true,防止缓存穿透
allowNullValues: true
# 组合缓存配置
composite:
# 是否全部启用一级缓存,默认false
l1AllOpen: false
# 是否手动启用一级缓存,默认false
l1Manual: true
# 手动配置走一级缓存的缓存key集合,针对单个key维度
l1ManualKeySet:
- userCache:user01
- userCache:user02
- userCache:user03
# 手动配置走一级缓存的缓存名字集合,针对cacheName维度
l1ManualCacheNameSet:
- userCache
- goodsCache
# 一级缓存
caffeine:
# 是否自动刷新过期缓存 true 是 false 否
autoRefreshExpireCache: false
# 缓存刷新调度线程池的大小
refreshPoolSize: 2
# 缓存刷新的频率(秒)
refreshPeriod: 10
# 写入后过期时间(秒)
expireAfterWrite: 180
# 访问后过期时间(秒)
expireAfterAccess: 180
# 初始化大小
initialCapacity: 1000
# 最大缓存对象个数,超过此数量时之前放入的缓存将失效
maximumSize: 3000
# 二级缓存
redis:
# 全局过期时间,单位毫秒,默认不过期
defaultExpiration: 300000
# 每个cacheName的过期时间,单位毫秒,优先级比defaultExpiration高
expires: {userCache: 300000,goodsCache: 50000}
# 缓存更新时通知其他节点的topic名称 默认 cache:redis:caffeine:topic
topic: cache:redis:caffeine:topic3、启动类上增加@EnableCaching
/**
* 启动类
*/
@EnableCaching
@SpringBootApplication
public class CacheApplication {
public static void main(String[] args) {
SpringApplication.run(CacheApplication.class, args);
}
}4、在需要缓存的方法上增加@Cacheable注解
/**
* 测试
*/
@Service
public class CaffeineCacheService {
private final Logger logger = LoggerFactory.getLogger(CaffeineCacheService.class);
/**
* 用于模拟db
*/
private static Map<String, UserDTO> userMap = new HashMap<>();
{
userMap.put("user01", new UserDTO("1", "张三"));
userMap.put("user02", new UserDTO("2", "李四"));
userMap.put("user03", new UserDTO("3", "王五"));
userMap.put("user04", new UserDTO("4", "赵六"));
}
/**
* 获取或加载缓存项
*/
@Cacheable(key = "'cache_user_id_' + #userId", value = "userCache")
public UserDTO queryUser(String userId) {
UserDTO userDTO = userMap.get(userId);
try {
Thread.sleep(1000);// 模拟加载数据的耗时
} catch (InterruptedException e) {
e.printStackTrace();
}
logger.info("加载数据:{}", userDTO);
return userDTO;
}
/**
* 获取或加载缓存项
* <p>
* 注:因底层是基于caffeine来实现一级缓存,所以利用的caffeine本身的同步机制来实现
* sync=true 则表示并发场景下同步加载缓存项,
* sync=true,是通过get(Object key, Callable<T> valueLoader)来获取或加载缓存项,此时valueLoader(加载缓存项的具体逻辑)会被缓存起来,所以CaffeineCache在定时刷新过期缓存时,缓存项过期则会重新加载。
* sync=false,是通过get(Object key)来获取缓存项,由于没有valueLoader(加载缓存项的具体逻辑),所以CaffeineCache在定时刷新过期缓存时,缓存项过期则会被淘汰。
* <p>
*/
@Cacheable(value = "userCache", key = "#userId", sync = true)
public List<UserDTO> queryUserSyncList(String userId) {
UserDTO userDTO = userMap.get(userId);
List<UserDTO> list = new ArrayList();
list.add(userDTO);
logger.info("加载数据:{}", list);
return list;
}
/**
* 更新缓存
*/
@CachePut(value = "userCache", key = "#userId")
public UserDTO putUser(String userId, UserDTO userDTO) {
return userDTO;
}
/**
* 淘汰缓存
*/
@CacheEvict(value = "userCache", key = "#userId")
public String evictUserSync(String userId) {
return userId;
}
}以上がSpring Cache に基づいて Caffeine+Redis の 2 次キャッシュを実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7493
7493
 15
1377
52
77
11
19
41
15
1377
52
77
11
19
41

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisサーバーを起動する手順には、以下が含まれます。オペレーティングシステムに従ってRedisをインストールします。 Redis-Server(Linux/Macos)またはRedis-Server.exe(Windows)を介してRedisサービスを開始します。 Redis-Cli ping(Linux/macos)またはRedis-Cli.exePing(Windows)コマンドを使用して、サービスステータスを確認します。 Redis-Cli、Python、node.jsなどのRedisクライアントを使用して、サーバーにアクセスします。
 Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示するには、3つの方法があります。キーコマンドを使用して、指定されたパターンに一致するすべてのキーを返します。スキャンコマンドを使用してキーを繰り返し、キーのセットを返します。情報コマンドを使用して、キーの総数を取得します。
 基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
Redisはハッシュテーブルを使用してデータを保存し、文字列、リスト、ハッシュテーブル、コレクション、注文コレクションなどのデータ構造をサポートします。 Redisは、スナップショット(RDB)を介してデータを維持し、書き込み専用(AOF)メカニズムを追加します。 Redisは、マスタースレーブレプリケーションを使用して、データの可用性を向上させます。 Redisは、シングルスレッドイベントループを使用して接続とコマンドを処理して、データの原子性と一貫性を確保します。 Redisは、キーの有効期限を設定し、怠zyな削除メカニズムを使用して有効期限キーを削除します。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisを使用して操作をロックするには、setnxコマンドを介してロックを取得し、有効期限を設定するために有効期限コマンドを使用する必要があります。特定の手順は次のとおりです。(1)SETNXコマンドを使用して、キー価値ペアを設定しようとします。 (2)expireコマンドを使用して、ロックの有効期限を設定します。 (3)Delコマンドを使用して、ロックが不要になったときにロックを削除します。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
