

Redis データ構造タイプのサンプル コード分析

intset
セット コレクションに整数が格納される場合、エンコードは intset 型 (小さい整数のコレクション)
typedef struct intset {
int32 encoding;
int32 length;
int contents[];
}| Description | 説明 | |
|---|---|---|
| 整数のビット幅が 16 ビット、32 ビット、または 64 ビットのいずれであるかを決定します。 | 列挙表現 | |
| 要素数 | ||
| 整数配列, 要素の値を保存する |
hash-max-ziplist-entries 512 # 当hash元素个数小于512时
hash-max-ziplist-value 64 # 当hash键或值长度小于64时
zset-max-ziplist-entries 128 # 当zset元素个数小于128时
zset-max-ziplist-value 64 # 当zset值小于64时
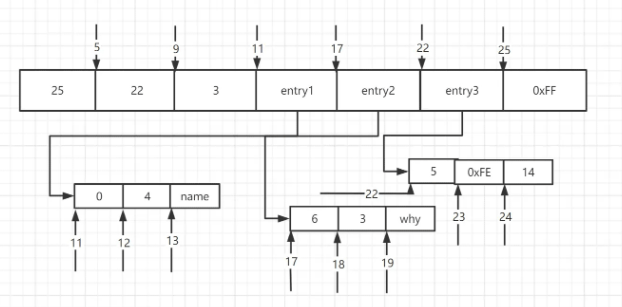
ログイン後にコピーtypedef struct ziplist {
int32 zlbytes;
int32 zltail_offset;
int16 zllength;
T[] entries;
int8 zlend;
}
typedef struct entry {
int<var> prevlen;
int<var> encoding;
byte[] content;
}ログイン後にコピー
##フィールドhash-max-ziplist-entries 512 # 当hash元素个数小于512时 hash-max-ziplist-value 64 # 当hash键或值长度小于64时 zset-max-ziplist-entries 128 # 当zset元素个数小于128时 zset-max-ziplist-value 64 # 当zset值小于64时
typedef struct ziplist {
int32 zlbytes;
int32 zltail_offset;
int16 zllength;
T[] entries;
int8 zlend;
}
typedef struct entry {
int<var> prevlen;
int<var> encoding;
byte[] content;
}| 説明 | zlbytes | |
|---|---|---|
| ##zltail_offset | 圧縮リストの開始位置からの最後の要素のオフセット||
| zllength | 要素の数 | |
| entries | 圧縮された要素||
| ##zlend | の終わりをマークします。圧縮リスト | |
| ##フィールド |
| 前のエントリのバイト長 | 最初のエントリは常に 0 であり、バイト長は動的に変化します。 254 場合は 1 バイトを使用し、それ以外の場合は 5 バイトを使用します。 | |||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| エンコーディング タイプ | エンコーディング タイプは要素の内容に応じて動的に変化します。は非常に複雑です。この記事では詳しく説明しません。ziplist エンコード タイプ | |||||||||||||||||||||||||||||||||||||
| 要素のコンテンツ (オプション | #) を検索できます。 | |||||||||||||||||||||||||||||||||||||
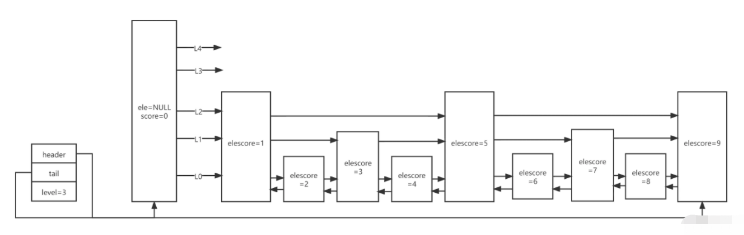
| 字段 | 描述 | 说明 |
|---|---|---|
| header | 指向跳跃列表的头指针 | value固定为NULL,score固定为0,backward为null |
| tail | 指向跳跃列表的尾指针 | |
| maxLevel | 当前跳跃表最大层数 | 最大为64 |
| value | 用于存储字符串类型的数据 | |
| score | 用于存储分值 | |
| backward | 回退节点 | 图中的←箭头 |
| forwards | 前进节点 | 图中的→箭头,每一层对应一个 |
| span | 跨度,存储一个节点跳到下一个节点中间跳过了多少节点 | 如score1指向score5,则span值为4,这是排名的实现原理 |
最小分值的backward固定null,对于每一个新插入的节点,会调用一个随机算法,来给它分配一个合理的层数
level1的概率为1-0.25=0.75,实际为100%,因为跳跃列表的最小层数为1
level2的概率为0.75*0.25=0.1875level3的概率为0.1875*0.25=0.0468 ......
leveln的概率为(1-0.25)*Math.pow(0.25,n-1)
总结
Redis作为单线程内存服务,在响应、数据结构上作出了很多的优化,值得我们学习
| 对象类型 | 编码类型 |
|---|---|
| string | int、raw、embstr |
| list | quicklist |
| hash | dict、ziplist |
| set | intset、dict |
| zset | ziplist、skiplist+dict |
HyperLogLog
HyperLogLog的原理为伯努利试验,即丢硬币,根据连续出现反面的次数X,推算出一共丢了2的X次方次硬币,当X很大时,推算出来的总数与实际总数误差就很接近了。具体可查询其他文章。
pfadd
element经过hash算法之后是一个64位的固定值
低14位为桶
查找高50位第一个为1的位数,如果大于当前桶的位数,就将其设置为当前桶的位数
假设hash值是 :{此处省略45位}01100 00000000000101
低14位的二进制转为10进制,值为5(regnum),即我们把数据放在第5个桶
高50位第一个1的位置是3,即count值为3
registers[5]取出历史值oldcount
如果count > oldcount,则更新 registers[5] = count
如果count <= oldcount,则不做任何处理
HyperLogLog用了16384个桶,每个桶占用6bit,因此说一个HyperLogLog所占用内存是12K。
调和平均数:
假设我的工资为10_000,马云的工资为1_000_000,那我和马云的平均工资为505_000,我肯定是不认同的。。。
如果使用调和平均数,则为2/(1/10_000+1/1_000_000)=19_801
同理,桶位数的平均数为:n/(1/桶1位数+1/桶2位数+...+1/桶n位数)
桶的平均个数为:Math.pow(2,桶位数的平均数)
总数量:const*桶总数n*桶的平均个数,其中constant为不定值,与桶个数有关,假设m为桶个数,取对数
pfcount
p=log2m
switch (p) {
case 4:
constant = 0.673 * m * m;
case 5:
constant = 0.697 * m * m;
case 6:
constant = 0.709 * m * m;
default:
constant = (0.7213 / (1 + 1.079 / m)) * m * m;
}以上がRedis データ構造タイプのサンプル コード分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7716
7716
 15
1641
14
1396
52
1289
25
1233
29
15
1641
14
1396
52
1289
25
1233
29

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisを使用して操作をロックするには、setnxコマンドを介してロックを取得し、有効期限を設定するために有効期限コマンドを使用する必要があります。特定の手順は次のとおりです。(1)SETNXコマンドを使用して、キー価値ペアを設定しようとします。 (2)expireコマンドを使用して、ロックの有効期限を設定します。 (3)Delコマンドを使用して、ロックが不要になったときにロックを削除します。
 Centos RedisでLUAスクリプト実行時間を構成する方法
Apr 14, 2025 pm 02:12 PM
Centos RedisでLUAスクリプト実行時間を構成する方法
Apr 14, 2025 pm 02:12 PM
Centosシステムでは、Redis構成ファイルを変更するか、Redisコマンドを使用して悪意のあるスクリプトがあまりにも多くのリソースを消費しないようにすることにより、LUAスクリプトの実行時間を制限できます。方法1:Redis構成ファイルを変更し、Redis構成ファイルを見つけます:Redis構成ファイルは通常/etc/redis/redis.confにあります。構成ファイルの編集:テキストエディター(VIやNANOなど)を使用して構成ファイルを開きます:sudovi/etc/redis/redis.conf luaスクリプト実行時間制限を設定します。
 Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインツール(Redis-Cli)を使用して、次の手順を使用してRedisを管理および操作します。サーバーに接続し、アドレスとポートを指定します。コマンド名とパラメーターを使用して、コマンドをサーバーに送信します。ヘルプコマンドを使用して、特定のコマンドのヘルプ情報を表示します。 QUITコマンドを使用して、コマンドラインツールを終了します。
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
