

GPT 大規模言語モデル Alpaca-lora ローカリゼーション展開の実践

モデル紹介
Alpaca モデルは、スタンフォード大学によって開発された LLM (Large Language Model、ビッグランゲージ) オープンソース モデルであり、LLaMA 7B (7B オープン) の 52K 命令に基づいて微調整されたモデルです。出典: Meta Company)、モデル パラメーターは 70 億個あります (モデル パラメーターが大きいほど、モデルの推論能力が強化され、当然、モデルのトレーニングのコストも高くなります)。
LoRA、正式な英語名は Low-Rank Adaptation of Large Language Models で、文字通り大規模言語モデルの低レベル適応と訳されます。これは、大規模言語モデルの微調整を解決するために Microsoft の研究者によって開発されたテクノロジです。言語モデル。事前にトレーニングされた大規模な言語モデルで特定のフィールドのタスクを実行できるようにしたい場合は、通常、微調整を行う必要がありますが、優れた推論効果を持つ大規模な言語モデルのパラメーターの次元は非常に大きく、大規模な言語モデルに対して微調整を直接実行すると、非常に大量の計算と非常に高いコストが必要になります。
'LoRA のアプローチは、事前トレーニングされたモデル パラメーターをフリーズし、トレーニング可能なレイヤーを各 Transformer ブロックに注入することです。モデル パラメーターの勾配を再計算する必要がないため、計算が大幅に削減されます。量。
下の図に示すように、中心となるアイデアは、元の事前トレーニング済みモデルにバイパスを追加し、次元削減を実行してから次元操作を実行することです。トレーニング中、事前トレーニングされたモデルのパラメーターは固定され、次元削減行列 A と次元強化行列 B のみがトレーニングされます。モデルの入力次元と出力次元は変更されず、BA と事前トレーニングされた言語モデルのパラメーターが出力に重ねられます。
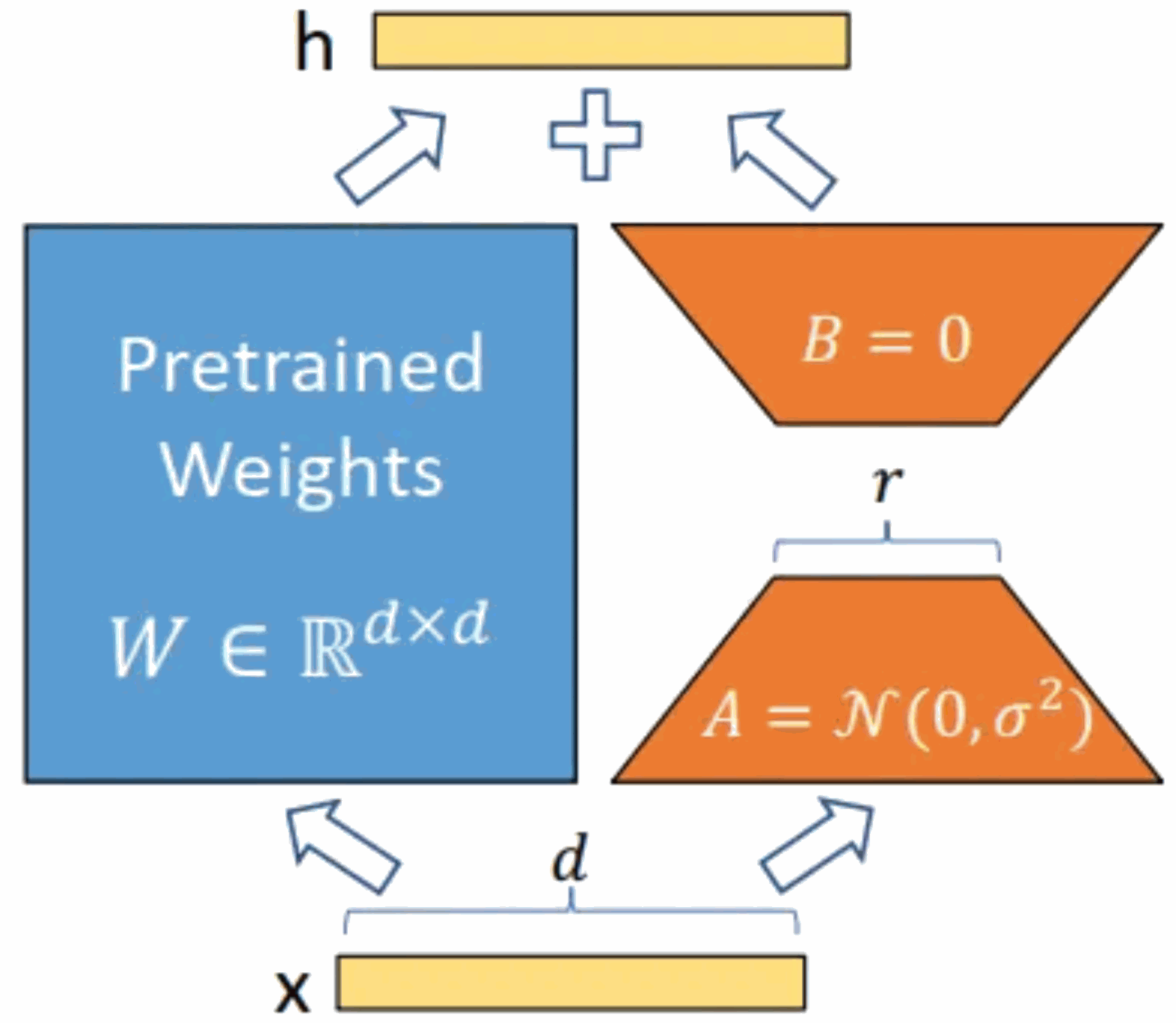
A をランダム ガウス分布で初期化し、B を 0 行列で初期化します。これにより、トレーニング中の新しいバイパス BA=0 が保証され、モデルの結果に影響を与えません。推論中、左部分と右部分の結果が加算されます (つまり、h=Wx BAx=(W BA)x)。したがって、学習後の行列積 BA と元の重み行列 W を新しい重みパラメータとして追加するだけです。元の事前トレーニング済み言語モデルの W だけで十分であり、追加のコンピューティング リソースは追加されません。 LoRA の最大の利点は、トレーニングが高速になり、使用するメモリが少なくなることです。
この記事でローカライズされた展開の実践に使用される Alpaca-lora モデルは、Alpaca モデルの低次適応バージョンです。この記事では、Alpaca-lora モデルのローカリゼーション展開、微調整、推論プロセスを実践し、関連する手順について説明します。
GPU サーバー環境の展開
この記事で展開する GPU サーバーには 4 つの独立した GPU があり、モデルは P40 です。単一の P40 の計算能力は次のとおりです。 60 同じメイン周波数の CPU の計算能力に相当します。

#物理カードがテストするには高価すぎると感じる場合は、「代替バージョン」である GPU クラウド サーバーを使用することもできます。物理カードと比較して、GPU クラウド サーバーを使用して構築すると、柔軟なハイパフォーマンス コンピューティングが保証されるだけでなく、次のような利点もあります -
- 高いコスト パフォーマンス: 時間単位で請求され、コストはわずか 10 ドルですいつでも自分のニーズに合わせて導入でき、柔軟なリソース管理、スケーラビリティ、柔軟なスケーリングなどのクラウド コンピューティングの利点を利用して、ビジネスまたは個人のトレーニング ニーズに応じてコンピューティング リソースを迅速に調整して、モデルのトレーニングやニーズを満たすことができます。導入ニーズ;
- オープンな特性: クラウド コンピューティングのオープン性により、ユーザーはリソースの共有と共同作業が容易になり、AI モデルの研究と応用に幅広い協力の機会が提供されます;
- 豊富な APIおよび SDK: クラウド コンピューティング ベンダーは豊富な API と SDK を提供しており、ユーザーはカスタマイズされた開発と統合のためにクラウド プラットフォームのさまざまなサービスや機能に簡単にアクセスできます。
https://www.php.cn/link/5d3145e1226fd39ee3b3039bfa90c95d
 ##GPU サーバーを入手したら、まずグラフィック カード ドライバーと CUDA ドライバー (グラフィック カード メーカーである NVIDIA が発売したコンピューティング プラットフォームです。CUDA は一般的な並列コンピューティング アーキテクチャです) をインストールします。 NVIDIA によって開始され、GPU 能力で複雑な計算問題を解決できるようになります)。
##GPU サーバーを入手したら、まずグラフィック カード ドライバーと CUDA ドライバー (グラフィック カード メーカーである NVIDIA が発売したコンピューティング プラットフォームです。CUDA は一般的な並列コンピューティング アーキテクチャです) をインストールします。 NVIDIA によって開始され、GPU 能力で複雑な計算問題を解決できるようになります)。
グラフィック カード ドライバーは、NVIDIA の公式 Web サイトにアクセスして、対応するグラフィック カード モデルと適応する CUDA バージョンを見つける必要があります。ダウンロード アドレス:
https://www.nvidia.com/Download/index.aspx , [対応するグラフィックス カードと CUDA バージョンのドライバー ファイルをダウンロードできます] を選択します。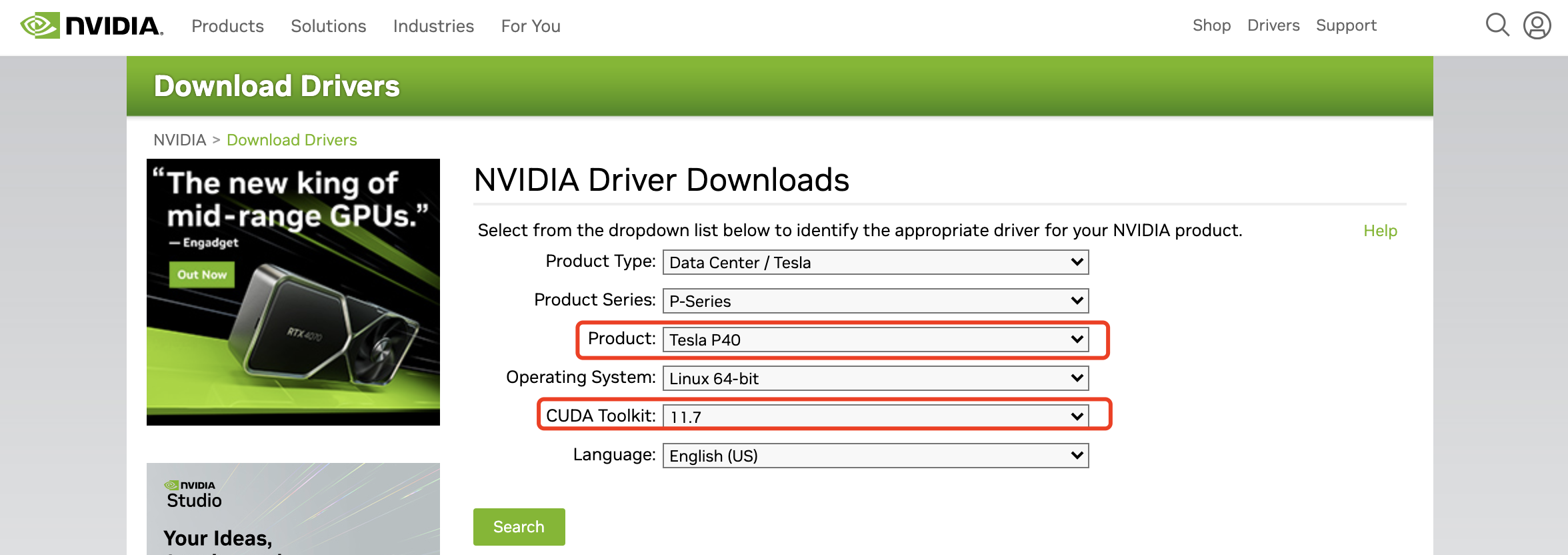
です
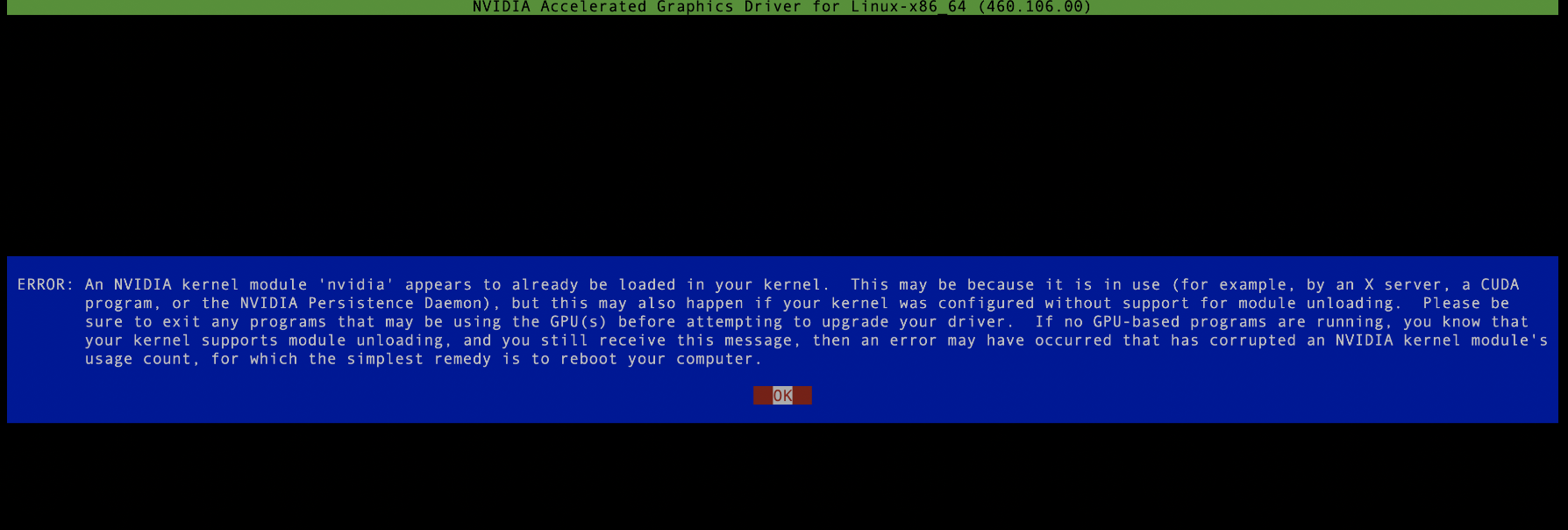
NVIDIA-Linux-x86_64-515.105.01.run、これは実行可能ファイルであり、root 権限で実行できます。ドライバーのインストール プロセス中に nvidia プロセスを実行できないことに注意してください。必要に応じて、すべてのプロセスを強制終了してください。それ以外の場合は、次の図に示すように、インストールに失敗します:
次に、次へ進みます。エラーが報告されなければ、インストールは成功です。後でグラフィックス カードのリソースを確認するには、nvitop などの別のグラフィックス カード監視ツールをインストールするのが最善です。単に pip install nvitop を使用します。サーバーごとに Python のバージョンが異なるため、anaconda をインストールするのが最善であることに注意してください。実行時にさまざまな奇妙なエラーが発生するのを防ぐために、独自のプライベート Python スペースをデプロイします 具体的な手順は次のとおりです:
1. anaconda をインストールします ダウンロード方法: wget
https://repo.anaconda.com /archive/Anaconda3-5.3.0-Linux-x86_64 .sh。インストール コマンド: sh Anaconda3-5.3.0-Linux-x86_64.sh インストール手順ごとに「yes」を入力し、conda init 後に最後にインストールを完了します。これにより、インストール ユーザーのセッションに入るたびに、自分のセッションを直接入力することになります。 Python環境。インストールの最後のステップで no を選択した場合、つまり conda init が実行されなかった場合は、後でsource /home/jd_ad_sfxn/anaconda3/bin/activate を通じてプライベート Python 環境に入ることができます。
2. setuptools のインストール 次に、パッケージ化および配布ツールの setuptools をインストールする必要があります。ダウンロード アドレス: wget
https://files.pythonhosted.org/packages/26/e5/9897eee1100b166a61f91b68528cb692e8887300d9cbdaa1a349f6304b79/setuptools- 40.5.0 .zip インストール コマンド: unzip setuptools-40.5.0.zip cd setuptools-40.5.0/ python setup.py install
3. pip のダウンロード アドレスをインストール: wget
https://files .pythonhosted.org/packages/45/ae/8a0ad77defb7cc903f09e551d88b443304a9bd6e6f124e75c0fbbf6de8f7/pip-18.1.tar.gz インストールコマンド: tar -xzf pip-18.1.tar.gz cd pip-18.1 python setup.py install
これまでのところ, 久しぶりのインストールです ようやくプロセスが終わりました. ここでプライベート Python スペースを作成し、
conda create -n alpaca pythnotallow=3.9conda activate alpaca
を実行して確認します. 下図のように、作成されたことがわかります成功しました。

モデル トレーニング
GPU サーバーの基本環境は上記でインストールされました。これからエキサイティングなモデル トレーニングを開始します (エキサイティング ing ) 、トレーニングの前に、最初にモデル ファイルをダウンロードする必要があります。ダウンロード アドレス:
https://github.com/tloen/alpaca-lora、モデル全体がオープンソースであり、これは素晴らしいことです。まず、モデルファイルをローカルにダウンロードし、git clone https://github.com/tloen/alpaca-lora.git を実行します。
ローカルに alpaca-lora フォルダーが作成され、そのフォルダー内で cd alpaca-lora を実行します。
pip install -r requirements.txt
このプロセスは時間がかかる可能性があり、から大量の依存関係パッケージをダウンロードする必要があります。インターネット。さまざまなパッケージの競合や不足している依存関係も報告される場合があります。この領域では、何が不足しているのかを見つけることしかできません (パッケージの依存関係やバージョンの競合を解決するのは確かに頭の痛い問題です。ただし、この手順が適切に行われないと、モデルも実行されます。立ち上がることができないので、辛抱強く少しずつ解決することしかできません)。マシンごとに異なる問題が発生する可能性があるため、ここでは面倒なプロセスについては詳しく説明しません。したがって、参照の重要性は次のとおりです。あまり素晴らしいものではありません。
インストール プロセスが完了すると、エラー メッセージは報告されず、「成功しました」というプロンプトが表示され、おめでとうございます。数千マイルにわたる長い行進は完了し、成功に非常に近づいています。もう少し待ってください。成功する可能性が非常に高いです :)。
私たちの目標はモデルを微調整することなので、微調整の目標を持たなければなりません。元のモデルは中国語を十分にサポートしていないため、私たちの目標は中国語コーパスを使用してモデルを改善することです。中国語をサポートしています。このコミュニティも私のために用意してくれました。中国語コーパスを直接ダウンロードして、wget
https://github.com/LC1332/ Chinese-alpaca-lora/ をローカルで実行するだけです。blob/main/data/ trans_chinese_alpaca_data.json?raw=true、後のモデルトレーニングに使用されるコーパスを alpaca-lora のルート ディレクトリにダウンロードします (後の便宜のため)。
コーパスの内容は、下図のような命令、入力、出力のトリプルで構成されており、命令はモデルに何かをさせる命令、入力は入力、出力はモデルの出力 指示と入力に従って、モデルが中国語によりよく適応できるようにトレーニング モデルがどのような情報を出力する必要があるか。

好的,到现在为止,万里长征已经走完2/3了,别着急训练模型,我们现在验证一下GPU环境和CUDA版本信息,还记得之前我们安装的nvitop嘛,现在就用上了,在本地直接执行nvitop,我们就可以看到GPU环境和CUDA版本信息了,如下图:
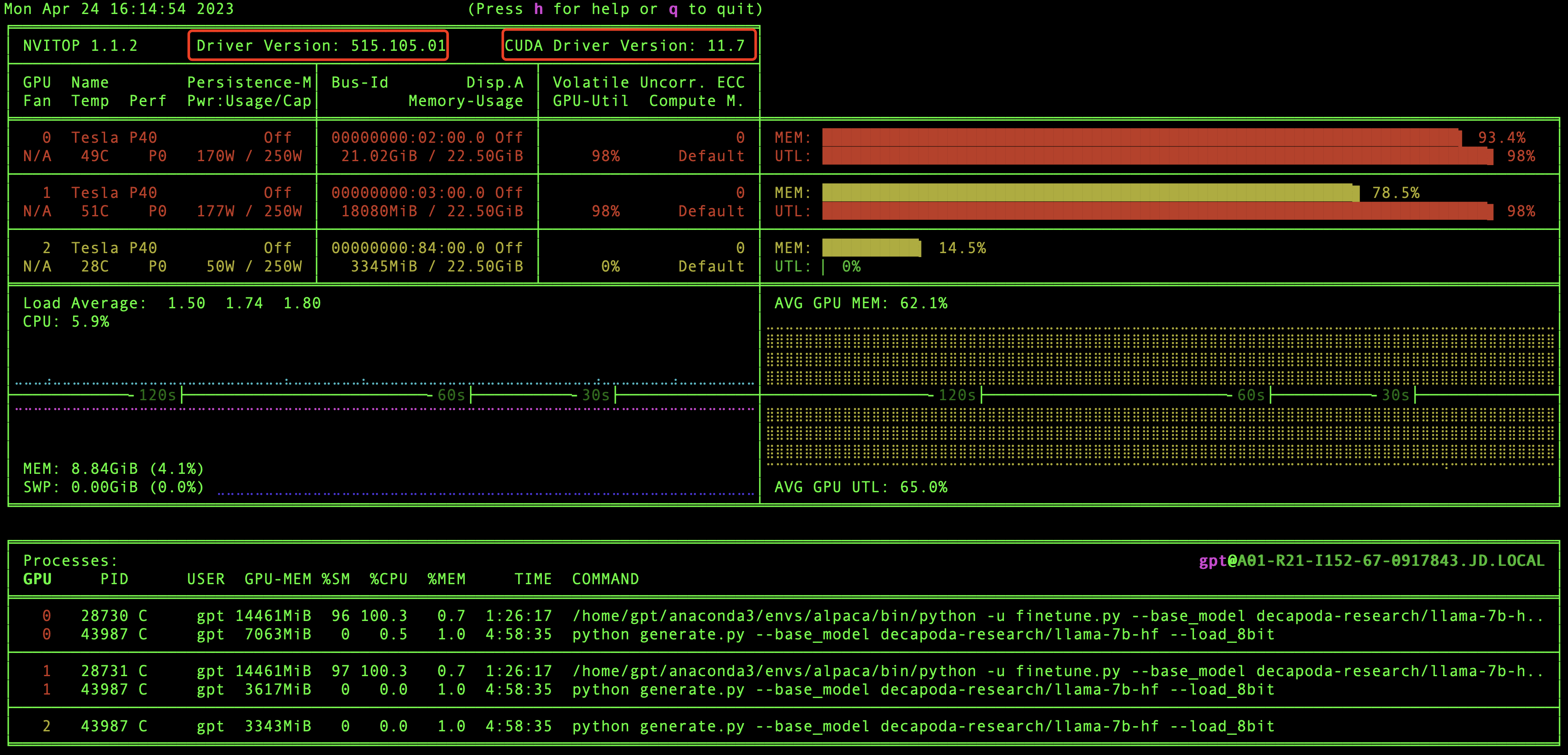
在这里我们能够看到有几块显卡,驱动版本和CUDA版本等信息,当然最重要的我们还能看到GPU资源的实时使用情况。
怎么还没到模型训练呢,别着急呀,这就来啦。
我们先到根目录下然后执行训练模型命令:
如果是单个GPU,那么执行命令即可:
python finetune.py \--base_model 'decapoda-research/llama-7b-hf' \--data_path 'trans_chinese_alpaca_data.json' \--output_dir './lora-alpaca-zh'
如果是多个GPU,则执行:
WORLD_SIZE=2 CUDA_VISIBLE_DEVICES=0,1 torchrun \--nproc_per_node=2 \--master_port=1234 \finetune.py \--base_model 'decapoda-research/llama-7b-hf' \--data_path 'trans_chinese_alpaca_data.json' \--output_dir './lora-alpaca-zh'
如果可以看到进度条在走,说明模型已经启动成功啦。
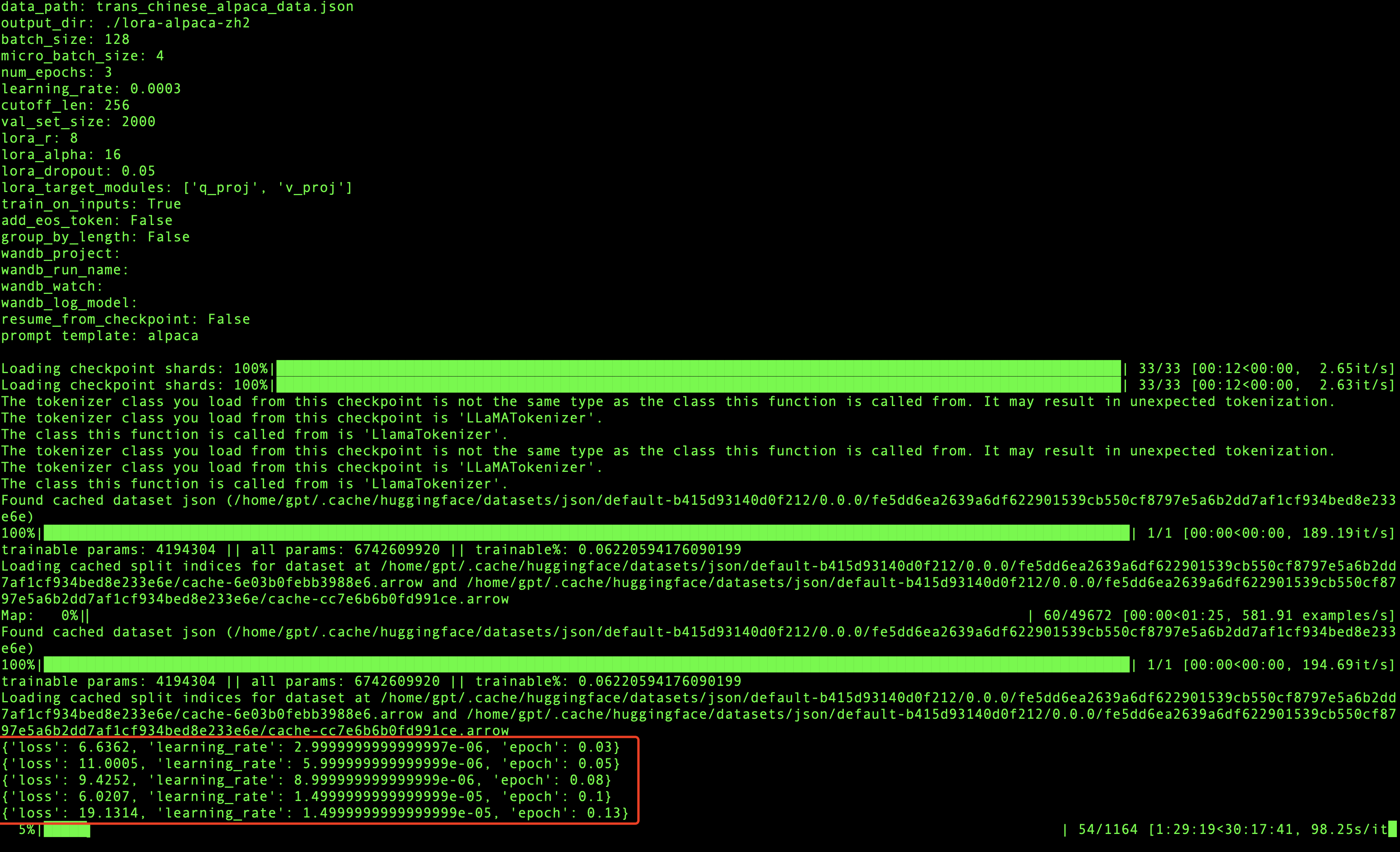
在模型训练过程中,每迭代一定数量的数据就会打印相关的信息,会输出损失率,学习率和代信息,如上图所示,当loss波动较小时,模型就会收敛,最终训练完成。
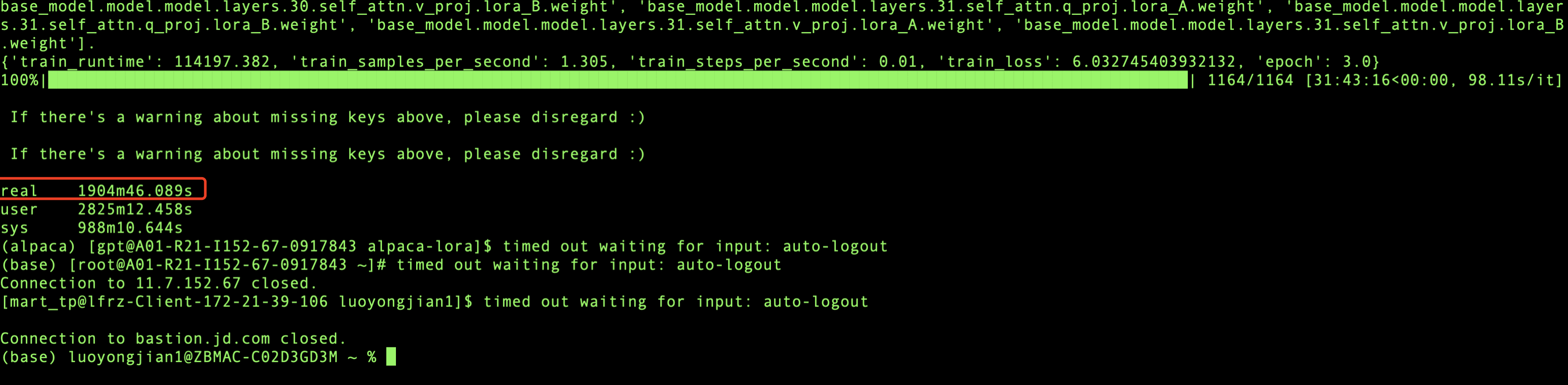
我用的是2块GPU显卡进行训练,总共训练了1904分钟,也就是31.73个小时,模型就收敛了,模型训练是个漫长的过程,所以在训练的时候我们可以适当的放松一下,做点其他的事情:)。
模型推理
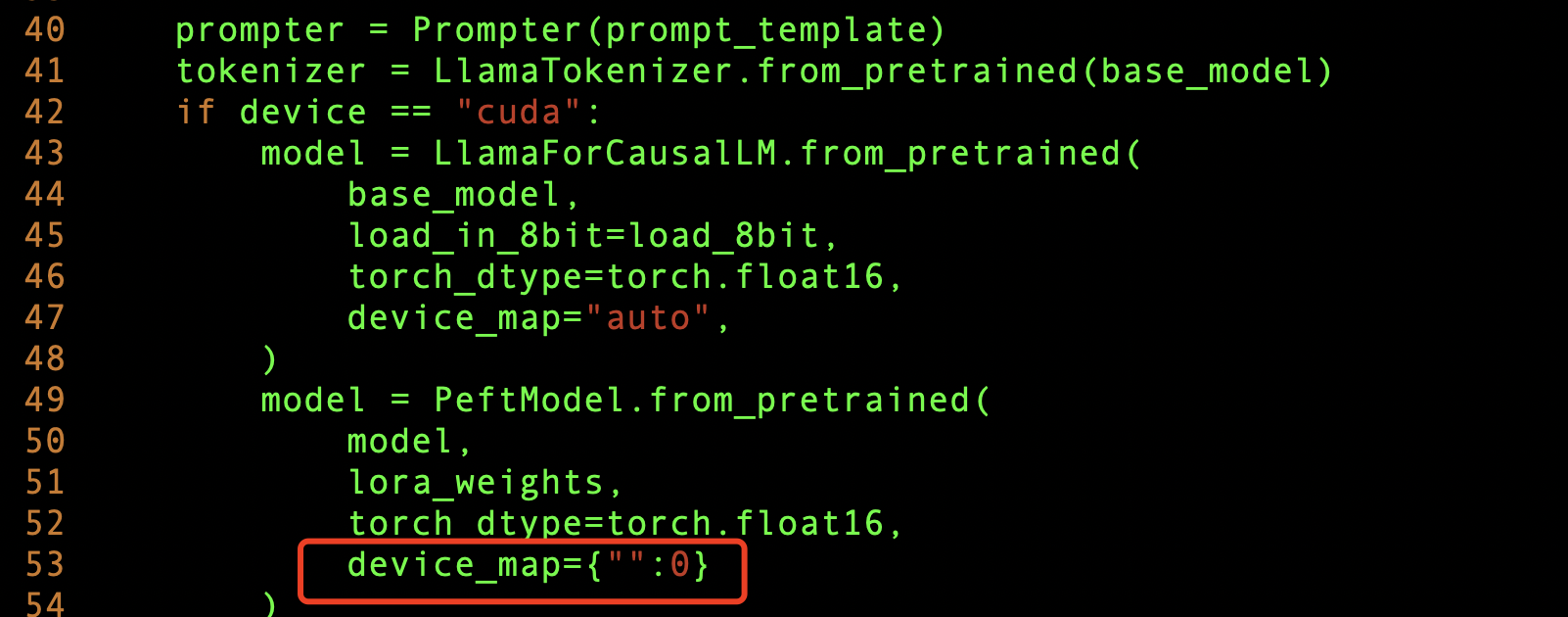
模型训练好后,我们就可以测试一下模型的训练效果了,由于我们是多个GPU显卡,所以想把模型参数加载到多个GPU上,这样会使模型推理的更快,需要修改
generate.py 文件,添加下面这样即可。
然后我们把服务启起来,看看效果,根目录执行:
python generate.py --base_model "decapoda-research/llama-7b-hf" \--lora_weights './lora-alpaca-zh' \--load_8bit
其中./lora-alpaca-zh目录下的文件,就是我们刚刚fine tuning模型训练的参数所在位置,启动服务的时候把它加载到内存(这个内存指的是GPU内存)里面。
如果成功,那么最终会输出相应的IP和Port信息,如下图所示:

我们可以用浏览器访问一下看看,如果能看到页面,就说明服务已经启动成功啦。
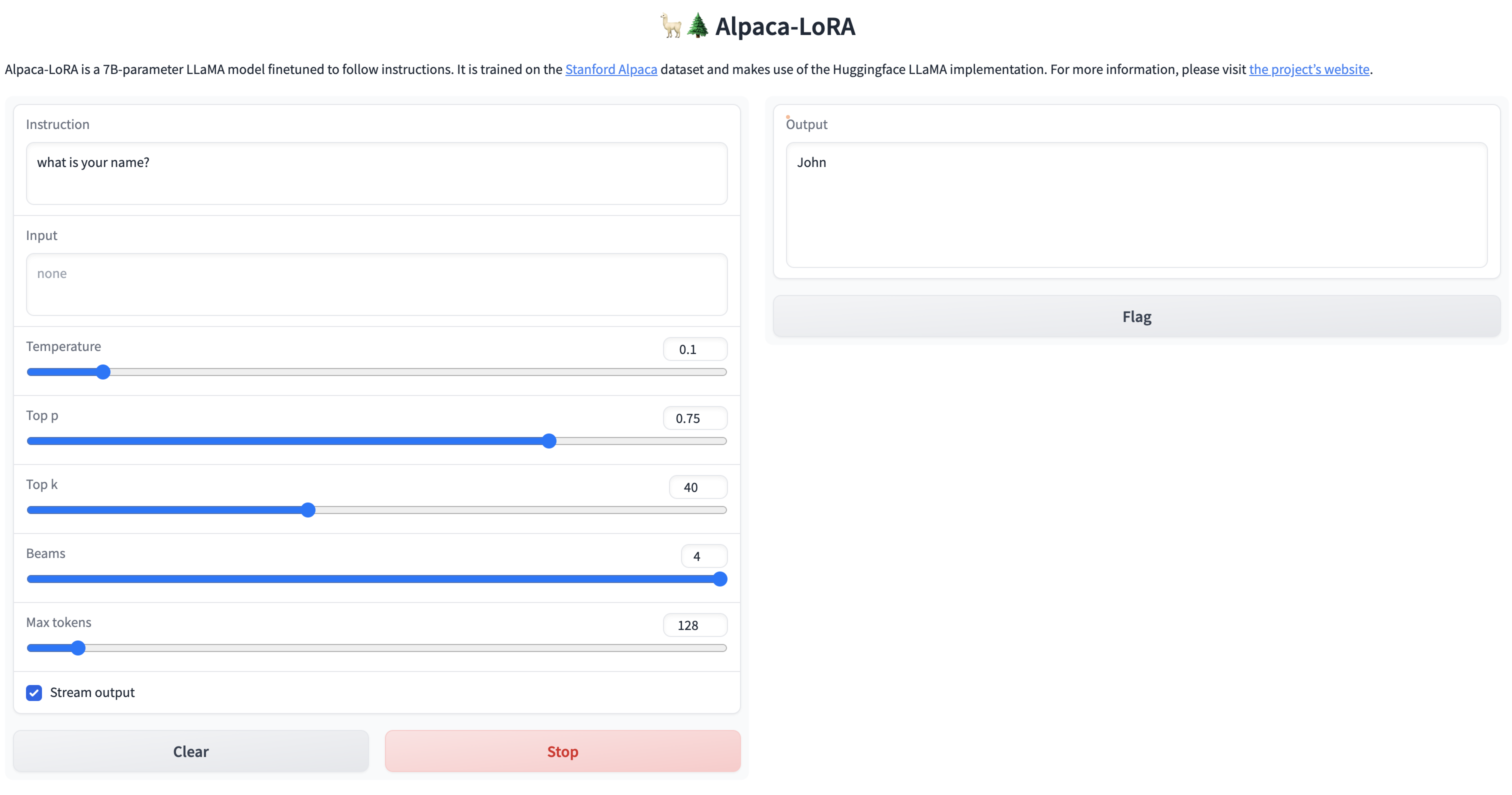
激动ing,费了九牛二虎之力,终于成功啦!!
因为我们目标是让模型说中文,所以我们测试一下对中文的理解,看看效果怎么样?
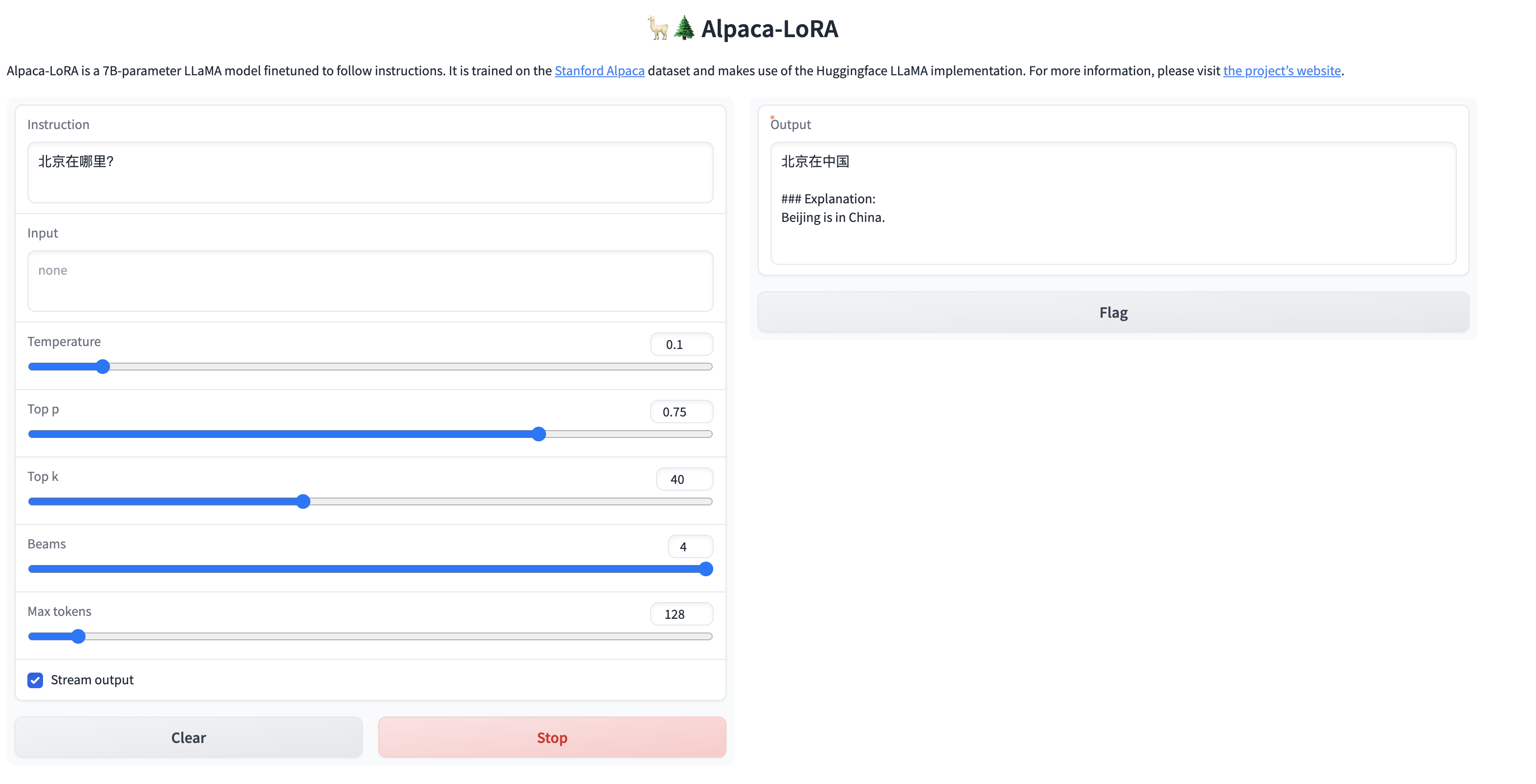
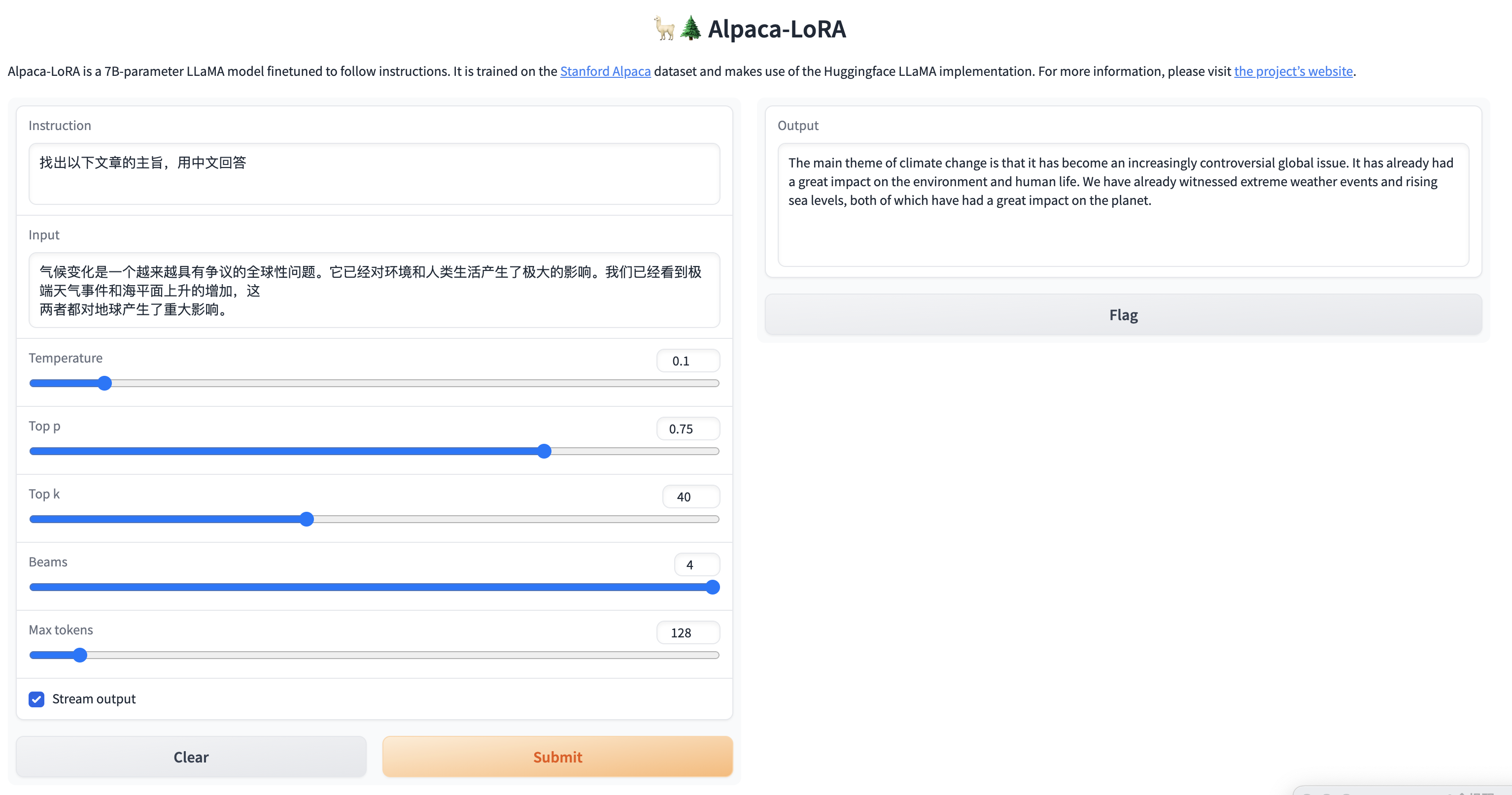
简单的问题,还是能给出答案的,但是针对稍微复杂一点的问题,虽然能够理解中文,但是并没有用中文进行回答,训练后的模型还是不太稳定啊。
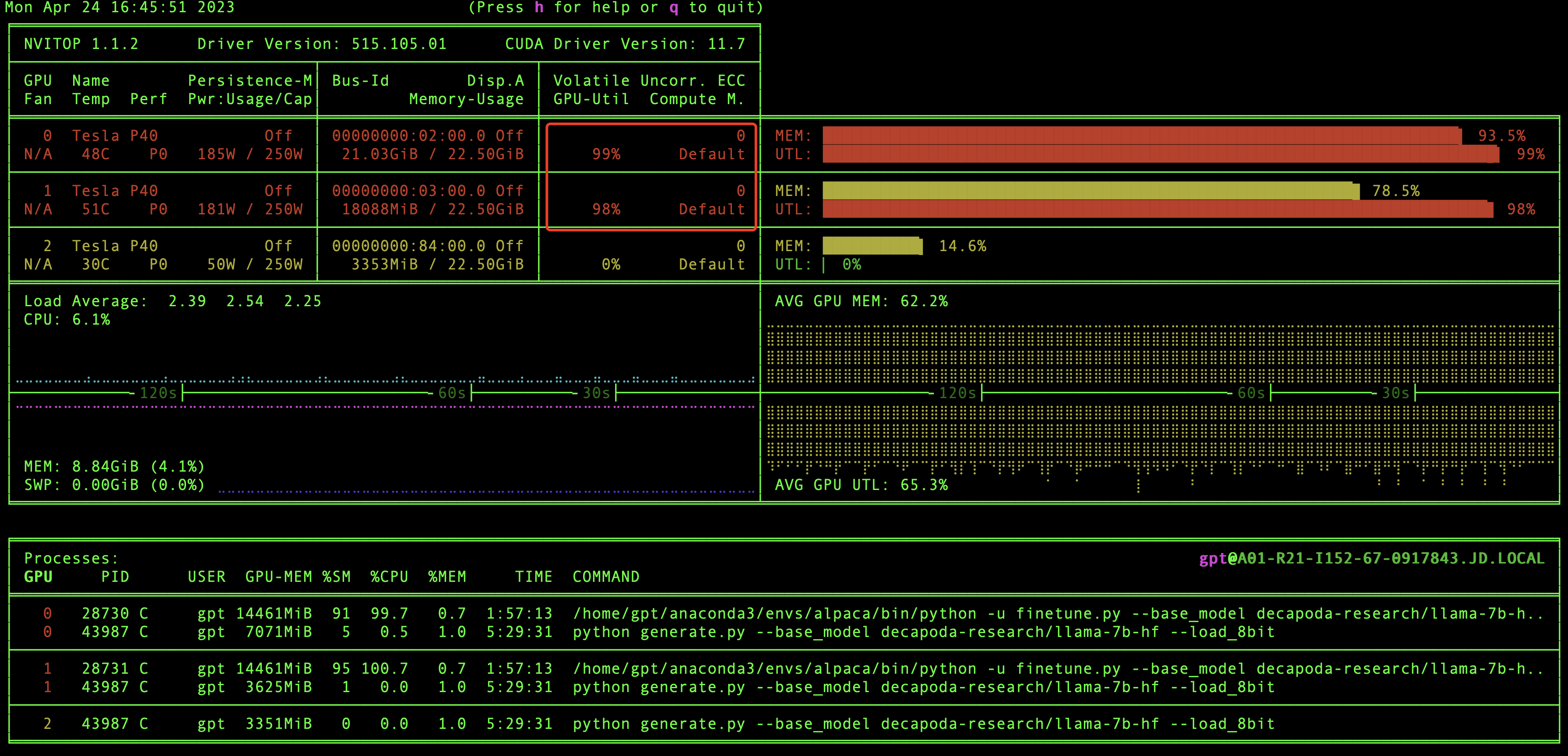
在推理的时候我们也可以监控一下GPU的变化,可以看到GPU负载是比较高的,说明GPU在进行大量的计算来完成推理。
总结
1.效果问题:由于语料库不够丰富,所以目前用社区提供的语料库训练的效果并不是很好,对中文的理解力有限,如果想训练出能够执行特定领域的任务,则需要大量的语料支持,同时训练时间也会更长;
2. 推論時間の問題: 現在デプロイされている GPU サーバーには 4 つの GPU があるため、そのうちの 3 つを実行できます。3 つの GPU に基づくと、推論は依然として非常に困難です。インタラクションの実行には約 30 秒から 1 分かかります。 chatGPT のようにリアルタイムで返されるため、それをサポートするには多くの計算能力が必要になります。投資は考慮する必要がある問題です;
3. 中国語のコード文字化けの問題: 入力が中国語の場合、返される結果が文字化けする場合があります。単語の分割に関連していると考えられます。中国語によるものです。エンコードの問題、中国語は英語のようにスペースで区別されないため、特定のエラーが発生する可能性があります。文字化けが発生し、オープン AI の API を呼び出すときにも発生します。コミュニティに対応する解決策があるかどうかは後で確認します。
4. モデル選択の問題: GPT コミュニティは現在比較的活発であるため、モデルの生成と変更も日を追うごとに変化しています。時間の都合上、アルパカの局所的な展開のみを調査しました。 lora モデル。将来、実際の実装には、より優れた低コストの実装ソリューションが登場するはずです。引き続きコミュニティの発展を追跡し、適切なものを選択する必要があります。オープンソース ソリューション。
JD Cloud P40 モデル GPU の [ChatGLM 言語モデル] 実践の詳細: https://www.php.cn/link/f044bd02e4fe1aa3315ace7645f8597a
著者: JD Retail Luo Yongjian
コンテンツ ソース: JD Cloud Developer Community
以上がGPT 大規模言語モデル Alpaca-lora ローカリゼーション展開の実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7465
7465
 15
1376
52
77
11
18
19
15
1376
52
77
11
18
19

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
この論文では、自動運転においてさまざまな視野角 (遠近法や鳥瞰図など) から物体を正確に検出するという問題、特に、特徴を遠近法 (PV) 空間から鳥瞰図 (BEV) 空間に効果的に変換する方法について検討します。 Visual Transformation (VT) モジュールを介して実装されます。既存の手法は、2D から 3D への変換と 3D から 2D への変換という 2 つの戦略に大別されます。 2D から 3D への手法は、深さの確率を予測することで高密度の 2D フィーチャを改善しますが、特に遠方の領域では、深さ予測に固有の不確実性により不正確さが生じる可能性があります。 3D から 2D への方法では通常、3D クエリを使用して 2D フィーチャをサンプリングし、Transformer を通じて 3D と 2D フィーチャ間の対応のアテンション ウェイトを学習します。これにより、計算時間と展開時間が増加します。
