MySQLインデックスの構文は何ですか


インデックス定義
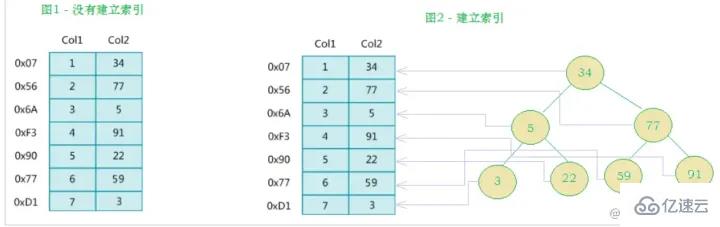
インデックスは、MySQL がデータを効率的に取得するのに役立つ順序付けされたデータ構造であり、MySQL 公式のインデックスの定義です。クエリの効率を向上させるために、インデックスはデータベース テーブルのフィールドに追加されるメカニズムです。データベース システムは、データに加えて、特定の検索アルゴリズムを満たすデータ構造も維持します。これらのデータ構造は、何らかの方法でデータを参照 (ポイント) するため、これらのデータ構造に高度な検索アルゴリズムを実装できます。このデータ構造は、索引。 。以下の図に示すように:
実際、簡単に言うと、インデックスはソートされたデータ構造です。
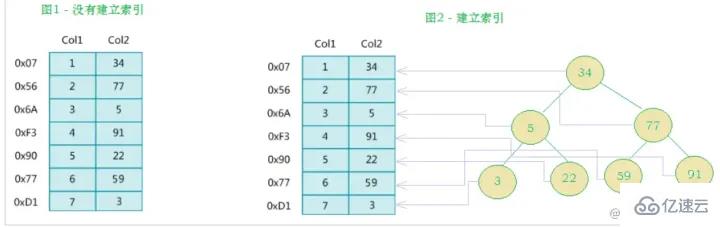
左側データ テーブルには合計 2 列と 7 つのレコードがあり、一番左はデータ レコードの物理アドレスです (論理的に隣接するレコードがディスク上で物理的に隣接しているとは限らないことに注意してください)。 Col2 の検索を高速化するために、右に示すようにバイナリ検索ツリーを維持できます。各ノードには、インデックス キー値と、対応するデータ レコードの物理アドレスへのポインタが含まれています。 なので、二分検索を使用して、対応するデータをすばやく取得できます。
インデックスの利点検索とソートの速度を高速化し、データベースのIOコストを削減します。 CPU 消費量
- 一意のインデックスを作成すると、データベース テーブル内のデータの各行の一意性を確保できます。
- インデックスは実際には
テーブルであり、主キー、インデックスのフィールド、ポイントが保存されます。エンティティへのクラス レコード自体がスペースを占有する必要があります
- クエリの効率は向上しますが、追加、削除、変更のために、テーブルが変更されるたびにインデックスを更新する必要があります。追加: 当然、インデックス ツリーに存在する必要があります。 新しいノードの削除: インデックス ツリーでポイントされているレコードが無効になる可能性があります。これは、このインデックス ツリー内の多くのノードが無効であることを意味します。 変更:
を指す インデックス ツリーのノードを変更する必要がある場合があります
しかし実際には、MySQL に保存するために二分探索ツリーでは、ここのノードは 1 つのデータのみを保存でき、ノードは MySQL のディスク ブロックに対応するため、毎回 1 つのディスク ブロックを読み取ることを知っておく必要があります。データは 1 つしか取得できず、効率が非常に悪いので、バイナリ検索ツリー を使用しません。なぜでしょうか?
B-tree 構造を使用して格納することを考えます。
インデックス構造インデックスは、サーバー層ではなく、MySQL のストレージ エンジン層に実装されます。したがって、インデックスはストレージ エンジン間で異なる場合があり、すべてのエンジンがすべての種類のインデックスをサポートしているわけではありません。BTREE インデックス: 最も一般的なインデックス タイプで、ほとんどのインデックスが B ツリー インデックスをサポートします。
HASH Index: メモリ エンジンによってのみサポートされており、使用シナリオは簡単です。
R ツリー インデックス (空間インデックス) : 空間インデックスは MyISAM エンジンの特殊なインデックス タイプで、主に地理空間データ タイプに使用されますが、通常はあまり使用されません。特別な紹介は行いません。
フルテキスト (フルテキスト インデックス) : フルテキスト インデックスも MyISAM の特殊なインデックス タイプで、主にフルテキスト インデックスに使用されます。 Mysql5.6 バージョンから全文インデックスをサポートします。
| #INNODB エンジン | #MYISAM エンジン |
##メモリ エンジン | ##BTREE インデックス |
|||||||||||
| サポート | サポート済み | HASH インデックス | ##サポートされていません||||||||||||
| ## サポートされていません | サポートされている | R ツリー インデックス | サポートされていません | |||||||||||
| サポート | サポート対象外 | 全文 | バージョン 5.6 以降でサポートされます | |||||||||||
| サポートされます | サポートされません |
明示的に指定しない限り、通常参照するインデックスは、B ツリー (多方向検索ツリー、必ずしもバイナリである必要はない) 構造を使用して編成されています。クラスター化インデックス、複合インデックス、プレフィックス インデックス、およびインデックスと呼ばれる一意のインデックスはすべて、デフォルトで B ツリー インデックスを使用します。 BTREEマルチパスバランス検索ツリー、m 次 (m フォーク) BTREE は次の条件を満たします:
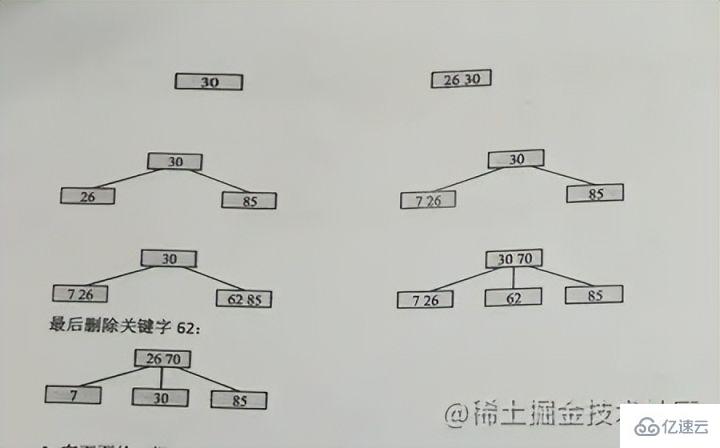
#キーワード case の挿入
つまり: になります。 70 を再度図に挿入すると、たまたま 70 が中央の上の位置になり、その後 62 が維持され、再び 85 になります 新しいノードを分割します
同じ理由で上方向に分割し続けます
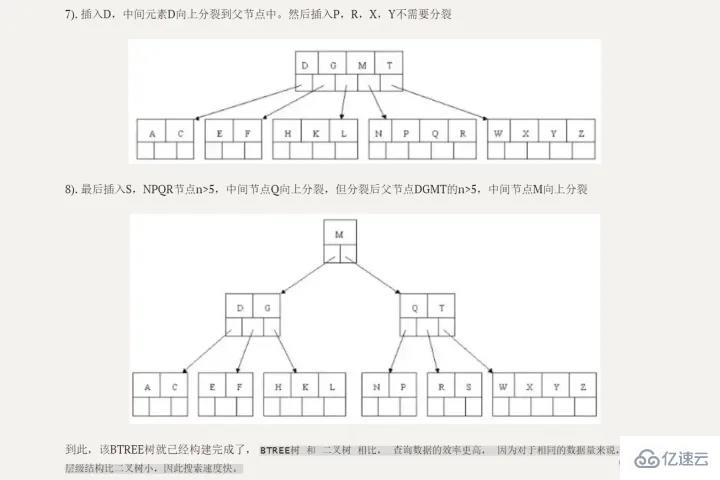
B Tree のクエリ効率はより安定しています
が形成され、シーケンシャル ポインタを備えた B ツリーが形成され、改善されます。インターバルアクセスのパフォーマンス。 注意深い生徒なら、この図と二分探索ツリー図の最大の違いは何であるかがわかるでしょうか?
##二分探索ツリー図:
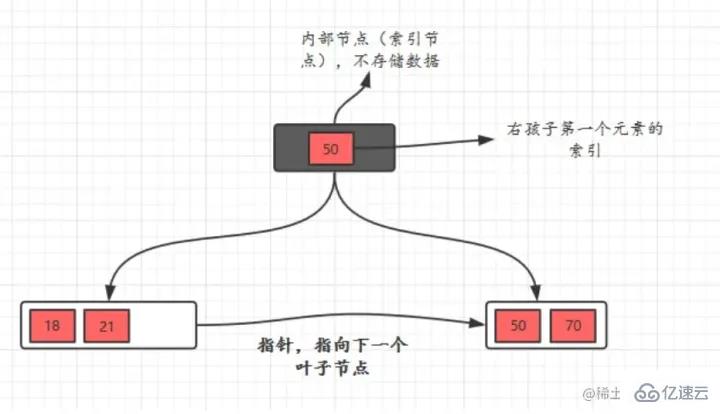
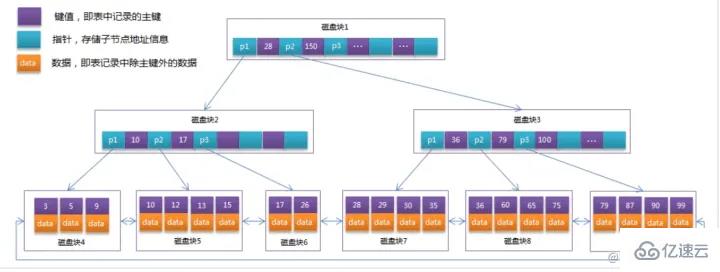
インデックスの原理 BTree インデックス: たとえば、ディスク ブロック 1 には、ポインター P1、P2、および P3 を含むデータ項目 17 と 35 が含まれています。P1 は、17 ブロック未満のディスクを表します。 、P2 は 17 ~ 35 のディスク ブロックを表し、P3 は 35 より大きいディスク ブロックを表します。
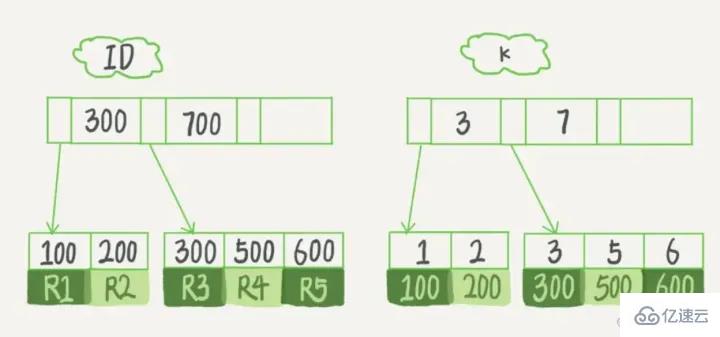
検索プロセスデータ項目 29 を検索する場合、最初にディスク ブロック 1 がディスクからメモリにロードされ、この時点で IO が発生します。メモリ内で二分探索を使用して、29 が 17 ~ 35 の間にあることを確認し、ディスク ブロック 1 の P2 ポインタをロックします。メモリ時間は (ディスクの IO と比較して) 非常に短いため、無視できます。ディスクを使用します。ディスク ブロック 1 からディスク ブロック 3 の P2 ポインタのアドレスがディスクからメモリにロードされます。2 番目の IO が発生します。29 は 26 と 30 の間にあります。ディスク ブロック 3 の P2 ポインタはロックされています。ディスク ブロック 8 がロードされます。ポインタを介してメモリにアクセス 3 回目の IO が発生 同時にメモリが通過 二分検索が 29 に達してクエリが終了し、合計 3 回の IO が発生します。 インデックスの分類インデックス構成テーブルとは、主キー順にインデックスとして格納されるテーブルで、InnoDB エンジンに適した方式です。 InnoDB は B ツリー インデックス モデルを使用するため、データは B ツリーに保存されます。 各インデックスは InnoDB の B ツリーに対応します。 mysql> create table T( id int primary key, k int not null, name varchar(16), index (k))engine=InnoDB; 复制代码 ログイン後にコピー テーブル内のR1~R5の(ID,k)値は(100,1)、(200,2)、 (300,3)、(500,5)、および (600,6)、2 つのツリーの図の例は次のとおりです。図からはわかりにくいですが、リーフ ノードの内容に応じて、インデックス タイプが主キー インデックスと非主キー インデックスに分けられます。 主キー インデックス
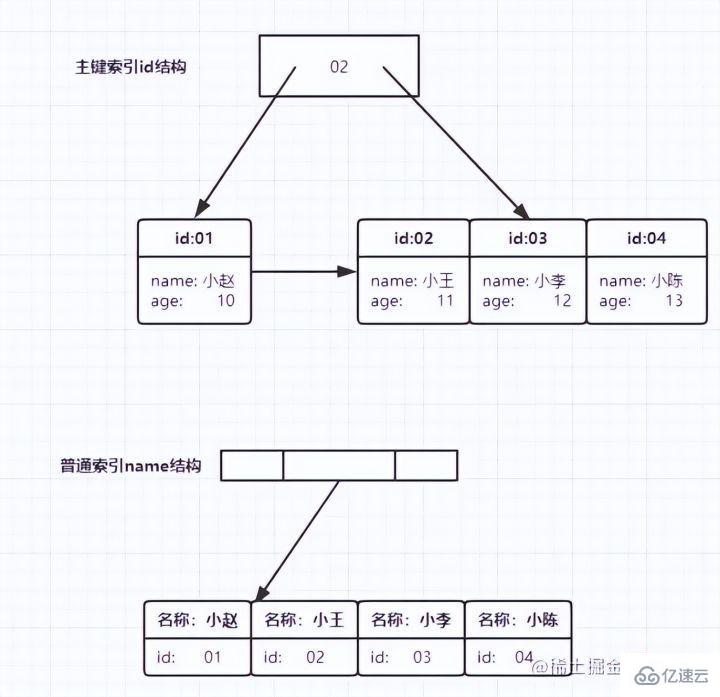
データ行全体が格納されます。 InnoDB では、主キー インデックスはクラスター化インデックス の値です。 InnoDB では、補助インデックスはSecondary Index (セカンダリ インデックス) とも呼ばれます。 以下に示すように:
ステートメントが select * from T where ID=500 (主キー クエリ メソッド) の場合、ID の B ツリーを検索するだけで済みます。
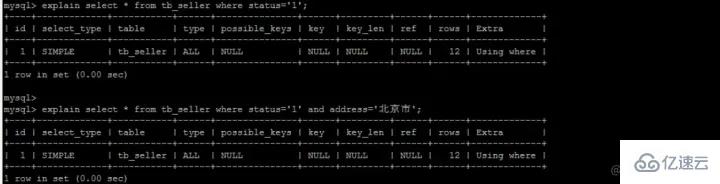
拡張機能 -- インデックス プッシュダウンいわゆるプッシュダウンは、その名前が示すように、実際には テーブルの戻り操作を延期します。MySQL はそれを許可しません。とてももったいないので簡単にテーブルに戻ります。それはどういう意味ですか?次の例を考えてみましょう。 複合インデックス (名前、ステータス、アドレス) を確立しました。これも、次の図のように、このフィールドに従って保存されます。 複合インデックス ツリー (インデックス列とアドレスのみを保存します)主キーはテーブルを返すために使用されます)
以上がMySQLインデックスの構文は何ですかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。 このウェブサイトの声明
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。

ホットAIツール
Undresser.AI Undressリアルなヌード写真を作成する AI 搭載アプリ 
AI Clothes Remover写真から衣服を削除するオンライン AI ツール。 
Undress AI Tool脱衣画像を無料で 
Clothoff.ioAI衣類リムーバー 
Video Face Swap完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。 
人気の記事
アサシンのクリードシャドウズ:シーシェルリドルソリューション
3週間前
By DDD
Windows11 KB5054979の新しいものと更新の問題を修正する方法
3週間前
By DDD
Atomfallのクレーンコントロールキーカードを見つける場所
3週間前
By DDD
<🎜>:Dead Rails-すべての課題を完了する方法
4週間前
By DDD
Atomfall Guide:アイテムの場所、クエストガイド、およびヒント
1 か月前
By DDD
ホットツール
メモ帳++7.3.1使いやすく無料のコードエディター 
SublimeText3 中国語版中国語版、とても使いやすい 
ゼンドスタジオ 13.0.1強力な PHP 統合開発環境 
ドリームウィーバー CS6ビジュアル Web 開発ツール 
SublimeText3 Mac版神レベルのコード編集ソフト(SublimeText3)
ホットトピック
Gmailメールのログイン入り口はどこですか?
 7694
7694
 15
15
Java チュートリアル
1640
14
CakePHP チュートリアル
1393
52
Laravel チュートリアル
1287
25
PHP チュートリアル
1229
29
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。  MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。  MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます  なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。  Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。  DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerでMySQLを起動するプロセスは、次の手順で構成されています。MySQLイメージをプルしてコンテナを作成および起動し、ルートユーザーパスワードを設定し、ポート検証接続をマップしてデータベースを作成し、ユーザーはすべての権限をデータベースに付与します。  MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
WebアプリケーションにおけるMySQLの主な役割は、データを保存および管理することです。 1.MYSQLは、ユーザー情報、製品カタログ、トランザクションレコード、その他のデータを効率的に処理します。 2。SQLクエリを介して、開発者はデータベースから情報を抽出して動的なコンテンツを生成できます。 3.MYSQLは、クライアントサーバーモデルに基づいて機能し、許容可能なクエリ速度を確保します。  Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。 
|