

MySQL の B ツリー インデックスと B+ ツリー インデックスの違いは何ですか?

インデックス データ構造としてツリーを使用する場合、データを検索するたびに、ツリーの 1 つのノード (ページ) がディスクから読み取られます。ただし、バイナリ ツリーの各ノードには 1 つの部分のみが保存されます。データ量が多く、ページを埋めることができません。ストレージ スペースがある場合、余分なストレージ スペースが無駄になっていませんか?バイナリ平衡検索ツリーのこの欠点を解決するには、単一ノードにより多くのデータを格納できるデータ構造、つまり多方向検索ツリーを探す必要があります。
1. マルチパス検索ツリー
1. 完全なバイナリ ツリーの高さ: O(log2N) (2 は対数、各レベルのノード数)ツリーの;
2. 完全な M 方向検索ツリーの高さ: O(logmN)、M は対数、つまりツリーの各レベルのノードの数です。 ;
M-way 検索ツリーは、保存されたデータの量が多すぎて一度にメモリにロードできないシナリオに適しています。レイヤーあたりのノード数を増やし、各ノードに保存するデータを増やすことで、1 つのレイヤーにさらに多くのデータを保存します。これにより、ツリーの高さが減り、データ ルックアップ中のディスク アクセスの数が減ります。
したがって、各ノードに含まれるキーワードの数とレベルごとのノードの数が増加すると、ツリーの高さは減少します。各ノードのデータ決定にはさらに時間がかかりますが、B ツリーの焦点はディスク パフォーマンスのボトルネックを解決することであるため、単一ノード上のデータ検索のコストは無視できます。
2. B ツリー - マルチパスバランス検索ツリー
B ツリーは M-way 検索ツリーであり、B ツリーは主に不均衡な M-way 検索の問題を解決するために使用されます。高、これはバイナリ ツリーのリンク リストへの縮退によって引き起こされるパフォーマンスの問題と同じです。 B ツリーは、ノードの分離、ノードの結合、1 つの層がいっぱいになったときに新しい層を追加するために親ノードを上方に分割するなどの操作など、各層のノードを制御および調整することにより、M-way 検索ツリーのバランスを確保します。
B ツリーでは、各ノードはディスク ブロック (ページ) であり、順序またはパス番号 M はノード内の子ノードの最大数を指定します。各非リーフ ノードはキーワードとサブツリーへのポインタを格納します。具体的な数は次のとおりです: M 次の B ツリー、各非リーフ ノードは M-1 個のキーワードとサブツリーへの M ポインタを格納します。この図は、5 次の B ツリー構造の概略図を示しています:

3. B ツリー インデックス
最初にユーザーを作成します。テーブル:
create table user( id int, name varchar, primary key(id) ) ROW_FORMAT=COMPACT;
B ツリーを使用してテーブル内のユーザー レコードのインデックスを作成する場合:
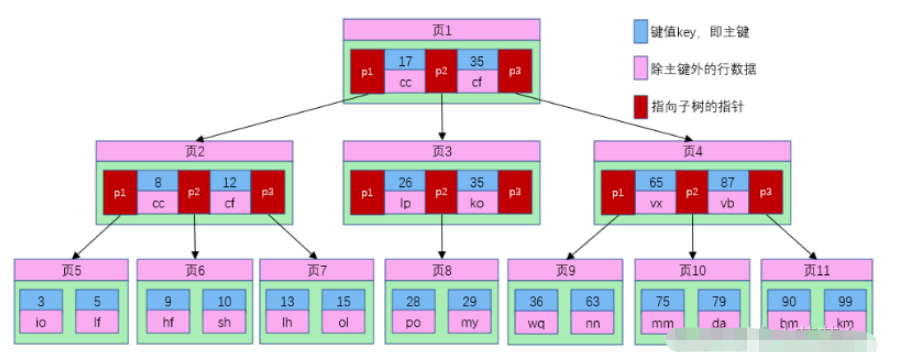
各ノードB ツリーの 1 つのディスク ブロックはページでもあります。上の図からわかるように、バランスのとれたバイナリ ツリーと比較して、B ツリーの各ノードにはより多くの主キーとデータが格納され、各ノードにはより多くの子ノードがあります。 . ノードの数を一般に次数と呼びますが、上図のBツリーは3次のBツリーとなり、高さも低くなります。 id=28 のユーザー情報を見つけたい場合、検索プロセスは次のようになります:
1. ルート ノードに従ってページ 1 を見つけ、それをメモリに読み込みます。 [ディスク I/O 操作 1 回目]
2. 区間 (17,35) のキー値 28 を比較し、ページ 1 のポインタ p2 を見つけます;
3. ページを見つけますp2 ポインタに基づく 3. メモリに読み取ります。 [ディスク I/O 操作 2 回目]
4. 区間 (26,35) のキー値 28 を比較し、ページ 3 のポインタ p2 を見つけます。
5. p2 ポインタに従ってページ 8 を検索し、メモリに読み込みます。 [ディスク I/O 操作 3 回目]
6. 8 ページのキー値リストでキー値 28 を見つけます。キー値に対応するユーザー情報は (28,po);
# です。##B-Tree AVLTree と比較してノード数が減り、ディスク I/O が使用されるたびにメモリからデータを取得するため、クエリが改善されます。効率。
1. 非リーフ ノードのサブツリー ポインタはキーワードの数と同じです; 2. すべてのリーフ ノードにリンク ポインタを追加します; 3. すべてのキーワードはin リーフ ノードが表示され、リンクされたリスト内のキーワードがたまたま順序どおりになっている;4. 非リーフ ノードはリーフ ノードのインデックスに相当し、リーフ ノードはデータを格納するデータ層に相当します。 (キーワード) data;InnoDB ストレージ エンジンは、B Tree を使用してインデックス構造を実装します。 B-ツリー構造図では、各ノードにはデータのキー値に加えてデータ値も含まれていることがわかります。各ページの記憶容量は限られており、データデータが大きい場合、各ノード (つまり 1 ページ) に保存できるキーの数は非常に少なくなります。 to B- ツリーの深さが大きくなり、クエリ中のディスク I/O の数が増加し、クエリの効率に影響します。 B Treeでは、すべてのデータレコードノードがキー値順に同じ階層のリーフノードに格納され、非リーフノードにはキー値情報のみが格納されるため、各ノードに格納されるキー値の数を大幅に増やすことができます。 . B ツリーの高さを下げます。
B ツリーには、B ツリーと比較していくつかの違いがあります:
1. 非リーフ ノードは、キー値の情報と子ノードのページ番号へのポインターのみを保存します。2. すべてのリーフ ノード間にリンク ポインタがあります; 3. データ レコードはリーフ ノードに保存されます;
上の図に基づいて、B ツリーと B ツリーの違いを見てみましょう。
(2) B ツリー、非リーフ ノードはキー値のみを保存しますが、B ツリー ノードはキー値とデータの両方を保存します。
ページ サイズは固定されており、InnoDB のデフォルトのページ サイズは 16 KB です。データが保存されていない場合、より多くのキー値が保存され、対応するツリーの順序が大きくなり、ツリーが太く短くなり、その結果、データの検索に必要なディスク IO 回数が増加します。データクエリの効率もさらに速くなります。
さらに、B ツリーの 1 つのノードが 1000 個のキー値を保存できる場合、3 層 B ツリーは 1000×1000×1000=10 億個のデータを保存できます。一般に、ルート ノードはメモリ内に常駐します (ルート ノードを初めて取得するときにディスクを読み取る必要はありません)。そのため、10 億のデータを検索するのに必要なディスク IO は 2 回だけです。
(2) B-tree インデックスのすべてのデータはリーフ ノードに格納され、データは順番に配置されます。
B ツリー内のページは双方向リンク リストを介して接続され、リーフ ノードのデータは一方向リンク リストを介して接続されます。このようにして、テーブル内のすべてのデータは、見つけられた。 B ツリーを使用すると、範囲クエリ、並べ替えクエリ、グループ クエリ、および重複排除クエリが非常に簡単になります。 B ツリーではデータがさまざまなノードに分散しているため、これを実現するのは簡単ではありません。
以上がMySQL の B ツリー インデックスと B+ ツリー インデックスの違いは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7476
7476
 15
1377
52
77
11
19
32
15
1377
52
77
11
19
32

 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICAT自体はデータベースパスワードを保存せず、暗号化されたパスワードのみを取得できます。解決策:1。パスワードマネージャーを確認します。 2。NAVICATの「パスワードを記憶する」機能を確認します。 3.データベースパスワードをリセットします。 4.データベース管理者に連絡してください。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 MySQLでテーブルをコピーする方法
Apr 08, 2025 pm 07:24 PM
MySQLでテーブルをコピーする方法
Apr 08, 2025 pm 07:24 PM
MySQLでテーブルをコピーするには、新しいテーブルの作成、データの挿入、外部キーの設定、インデックスのコピー、トリガー、ストアドプロシージャ、および機能が必要です。特定の手順には、同じ構造を持つ新しいテーブルの作成が含まれます。元のテーブルからデータを新しいテーブルに挿入します。同じ外部キーの制約を設定します(元のテーブルに1つがある場合)。同じインデックスを作成します。同じトリガーを作成します(元のテーブルに1つがある場合)。同じストアドプロシージャまたは関数を作成します(元のテーブルが使用されている場合)。
 mysqlを表示する方法
Apr 08, 2025 pm 07:21 PM
mysqlを表示する方法
Apr 08, 2025 pm 07:21 PM
次のコマンドでmysqlデータベースを表示します。サーバーに接続します:mysql -u username -pパスワードrun showデータベース。すべての既存のデータベースを取得するコマンド[データベース]を選択します。データベース名を使用します。テーブルを表示:表を表示します。テーブル構造を表示:テーブル名を説明してください。データを表示:[テーブル名]から[ *]を選択します。
 MariadBのNAVICATでデータベースパスワードを表示する方法は?
Apr 08, 2025 pm 09:18 PM
MariadBのNAVICATでデータベースパスワードを表示する方法は?
Apr 08, 2025 pm 09:18 PM
Passwordが暗号化された形式で保存されているため、MariadbのNavicatはデータベースパスワードを直接表示できません。データベースのセキュリティを確保するには、パスワードをリセットするには3つの方法があります。NAVICATを介してパスワードをリセットし、複雑なパスワードを設定します。構成ファイルを表示します(推奨されていない、高リスク)。システムコマンドラインツールを使用します(推奨されません。コマンドラインツールに習熟する必要があります)。
 NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する手順:データベースに接続します。 SQLエディターウィンドウを作成します。 SQLクエリまたはスクリプトを書きます。 [実行]ボタンをクリックして、クエリまたはスクリプトを実行します。結果を表示します(クエリが実行された場合)。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
