

GPT や PaLM などの大規模な言語モデルは、数学的、記号的、常識的、知識推論などのタスクの処理にますます熟練してきています。おそらく驚くべきことに、これらすべての進歩の基礎は、テキストを生成するための元の自己回帰メカニズムのままです。トークンごとに決定を行い、左から右の形式でテキストを生成します。このような単純なメカニズムは、一般的な問題解決ツールの言語モデルを構築するのに十分ですか?そうでない場合、どのような問題が現在のパラダイムに挑戦し、どのような代替メカニズムを採用する必要があるのでしょうか?
人間の認知に関する文献には、これらの質問に答えるためのヒントがいくつかあります。 「デュアルプロセス」モデルに関する研究によると、人は意思決定をする際に 2 つのモードがあることが示されています: 1 つは、速く、自動的に、無意識に行われるモード (システム 1)、もう 1 つは、ゆっくりと、意図的に行われ、意識的に行われるモード (システム 2) です。 。これら 2 つのパターンは、これまで機械学習で使用されるさまざまな数学モデルに関連付けられていました。たとえば、人間や他の動物の強化学習に関する研究では、人間や他の動物が連想的な「モデルフリー」学習を行うか、より意図的な「モデルベース」計画を行うかを調査します。言語モデルの単純な連想トークンレベルの選択も「システム 1」に似ているため、単に 1 つを選択するのではなく、現在の選択に対する複数の代替案を維持および探索する、より思慮深い「システム 2」の計画プロセスの強化から恩恵を受ける可能性があります。 。さらに、現在の状態を評価し、よりグローバルな意思決定を行うために積極的に将来または過去を振り返ります。
このような計画プロセスを設計するために、プリンストン大学と Google DeepMind の研究者は、まず人工知能 (および認知科学) の起源を見直し、ニューウェルの研究を活用することにしました。ショーとサイモン 1950 年代に検討された計画プロセスのインスピレーション。 Newellらは、問題解決をツリーとして表現される組み合わせ問題空間の探索として説明している。そこで彼らは、一般的な問題解決のための言語モデルに適応した Tree of Thought (ToT) フレームワークを提案しました。

紙のリンク: https://arxiv.org/pdf/2305.10601 .pdf
プロジェクトアドレス: https://github.com/ysymyth/tree-of-thought-llm
図 1 に示すように、既存の手法は連続的な言語シーケンスをサンプリングすることで問題を解決しますが、ToT は問題解決の中間ステップとして、各思考が一貫した言語シーケンスである思考ツリーを積極的に維持します (表 1)。
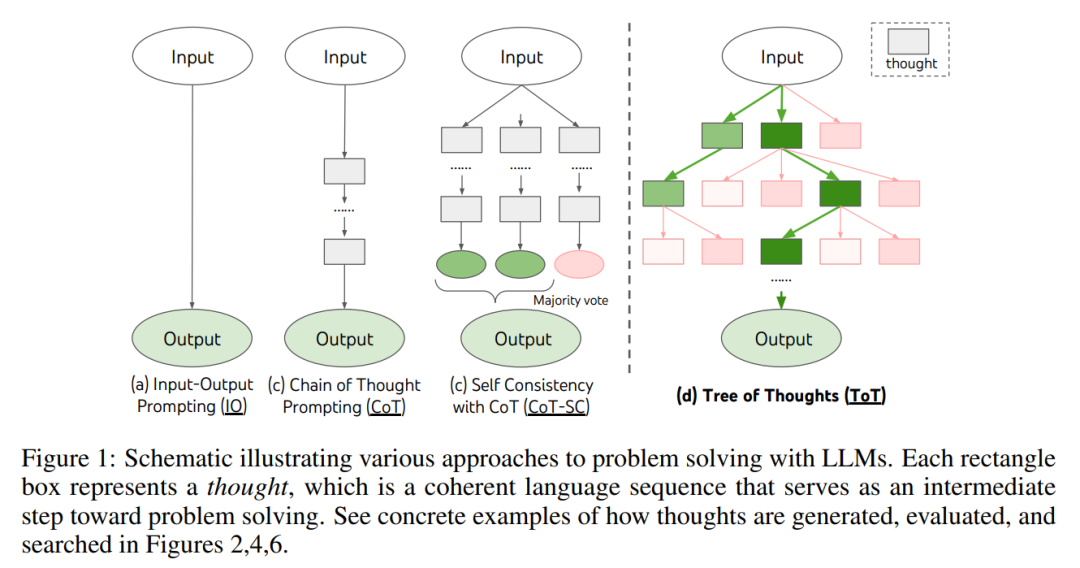

このような高度なセマンティック ユニットにより、LM は思慮深い推論プロセスを通じて、問題解決の進行に対するさまざまな中間思考の貢献を自己評価できます (図 2、4、6)。以前の検索ヒューリスティックはプログラムまたは学習されていたため、LM の自己評価と熟考を通じて検索ヒューリスティックを実装することは、新しいアプローチです。


実験段階では、研究者らは 3 つのタスク、つまり 24 ポイント ゲーム、クリエイティブ ライティング、クロスワード パズルを設定しました (表 1)。これらの問題は、たとえ GPT- 4も例外ではありません。これらのタスクには、演繹的、数学的、一般的な知識、語彙推論のスキル、および体系的な計画や検索を組み込む方法が必要です。実験結果によると、ToT はさまざまなレベルの思考、思考の生成と評価のさまざまな方法をサポートするのに十分な多用途性と柔軟性を備え、問題のさまざまな性質に適応できるため、これら 3 つのタスクで優れた結果を達成します。著者らは、系統的な実験的アブレーション解析を通じて、これらの選択がモデルのパフォーマンスにどのような影響を与えるかを調査し、トレーニングと LM の使用に関する将来の方向性についても議論しています。 真の問題解決プロセスには、入手可能な情報を繰り返し使用して探索を開始し、最終的な発見に至るまでさらに多くの情報が明らかになることが含まれます。ソリューションを実装する方法が作成されます。 ——Newell et al 人間の問題解決に関する研究では、人間が組み合わせ問題空間を探索することによって問題を解決していることが示されています。これはツリーとして見ることができ、ノードは部分的な解決策を表し、分岐はそれらを変更する演算子に対応します。どの分岐が選択されるかは、問題空間をナビゲートし、問題解決者を解決の方向に導くのに役立つヒューリスティックによって決定されます。この視点は、一般的な問題を解決するために言語モデルを使用する既存のアプローチの 2 つの重要な欠点を強調しています。1) 局所的には、思考プロセスのさまざまな継続、つまりツリーの枝を探索しません。 2) 世界的に見て、これらには、これらのさまざまな選択肢を評価するための計画、先を見据え、または後戻りすること、つまり人間の問題解決の特徴と思われるヒューリスティックに基づく探索のようなものが含まれていません。 これらの問題を解決するために、著者は思考の木 (ToT) を導入します。これは、言語モデルが思考経路上で複数の推論方法を探索できるようにするパラダイムです (図 1) (c))。 ToT はあらゆる問題をツリーの探索として構成します。各ノードは状態 s = [x, z_1・・・i ] であり、これまでの入力と一連の思考による部分的な解決策を表します。 ToT の具体例には、次の 4 つの質問に答えることが含まれます: 1. 思考の分解。 CoT は明示的な分解を行わずに一貫した思考をサンプリングしますが、ToT は問題の特性を利用して中間の思考ステップを設計および分解します。表 1 に示すように、問題に応じて、思考はいくつかの単語 (クロスワード パズル)、方程式 (24 ドット ゲーム)、または執筆計画 (クリエイティブ ライティング) になります。一般的に言えば、LM が期待される多様なサンプルを生成できるように、思考は十分に「小さく」なければなりません (一貫性を保つには「大きすぎる」本を生成するなど) が、思考は十分に「大きく」なければなりません。 LM は、問題解決の見通しを評価できます (たとえば、トークンの生成は通常、評価するには小さすぎます)。 2. 思考ジェネレータ G (p_θ, s, k)。木の状態 s = [x, z_1・・・i] が与えられた場合、この研究では 2 つの戦略を利用して、次の思考ステップのための k 個の候補を生成します。 3. 状態評価器 V (p_θ, S)。さまざまな状態の境界を考慮して、状態評価者は問題解決に向けた進捗状況を評価して、どの状態をどの順序で調査し続ける必要があるかを決定します。ヒューリスティックは検索問題を解決する標準的な方法ですが、多くの場合、プログラムによるもの (DeepBlue など) または学習によるもの (AlphaGo など) のいずれかです。この記事では、言語を使用して意図的に状態について推論するという 3 番目の選択肢を提案します。該当する場合、このような思慮深いヒューリスティックは、プログラミング ルールよりも柔軟であり、学習モデルよりも効率的です。 思考ジェネレーターと同様に、状態を個別にまたは一緒に評価する 2 つの戦略を検討します。 これら 2 つの戦略は、LM に価値を統合するか、州として投票するよう複数回促すことができます。結果、時間、リソース、コストは、より信頼性が高く堅牢なヒューリスティックと交換されます。 4. 検索アルゴリズム。最後に、ToT フレームワーク内では、ツリー構造に基づいてさまざまな検索アルゴリズムをプラグ アンド プレイすることができます。この記事では、2 つの比較的単純な検索アルゴリズムについて説明し、より高度なアルゴリズムは将来の研究のために残しておきます。
24 ドット数学ゲーム 表 2 に示すように、IO、CoT、および CoT-SC プロンプト手法を使用すると、タスクのパフォーマンスが低く、成功率は 7.3%、4.0%、および 9.0% にとどまりました。比較すると、b(breadth) = 1 の ToT では 45% の成功率が達成され、b = 5 では 74% に達します。また、k 個のサンプル (1 ≤ k ≤ 100) の中の最良の値を使用して成功率を計算するための IO/CoT のオラクル設定も考慮しました。 IO/CoT (k 最良の結果) と ToT を比較するために、研究者らは ToT の各タスクで訪問したツリー ノードの数を数えることを検討します。ここで、b = 1・・・5、そして、IO/CoT (k 個の最良の結果) をギャンブル マシンの k 個のノードを訪問したものとして扱い、5 つの成功率を図 3 (a) にマッピングします。当然のことながら、CoT は IO よりもスケーラブルであり、最良の 100 個の CoT サンプルでは 49% の成功率が達成されましたが、それでも ToT でより多くのノードを探索するよりもはるかに低い値です (b > 1)。
以下の図 5 (a) は、100 タスク間の GPT-4 の平均スコアを示しています。ToT (7.56) は、IO (6.19) および CoT (6.93) よりも多くの結果を生成します。 。このような自動測定にはノイズが多い可能性がありますが、図 5(b) では、100 継代ペアのうち 41 ペアでヒトが CoT よりも ToT を好むことが確認されていますが、ToT よりも CoT を好むのは 21 ペアだけです (他の 38 ペアも同様に一貫性があることがわかりました)。 最後に、反復最適化アルゴリズムはこの自然言語タスクでより良い結果を達成し、IO 一貫性スコアが 6.19 から 7.67 に増加し、ToT 一貫性スコアが 7.56 から 7.91 に増加しました。研究者らは、これは ToT フレームワークにおける 3 番目の思考生成方法とみなすことができ、逐次生成ではなく、古い思考の洗練から新しい思考を生成できると考えています。 ミニクロスワードパズル 「24 ポイントの数学ゲーム」やクリエイティブ ライティングでは、ToT は比較的単純です。最終的な出力を達成するまでに、最大 3 つの思考ステップが必要です。研究者らは、自然言語に関する検索質問のより難しい層として、5×5 ミニクロスワード パズルを調査します。繰り返しになりますが、今回の目標は単にタスクを解くことではありません。一般的なクロスワード パズルは、LM の代わりに大規模な検索を活用する特殊な NLP パイプラインによって簡単に解くことができます。代わりに、研究者は、一般的な問題解決手段としての言語モデルの限界を探求し、言語モデル自体の考え方を探求し、その探求を導くためのヒューリスティックとして厳密な推論を使用することを目指しています。 以下の表 3 に示すように、IO および CoT プロンプト手法のパフォーマンスは低く、単語レベルの成功率は 16% 未満でしたが、ToT はすべての指標を大幅に改善し、単語レベルの 60% を達成しました。成功率、20 試合中 4 試合解決。 IO と CoT には、さまざまなキューを試したり、決定を変更したり、バックトラックしたりするメカニズムがないことを考えると、この改善は驚くべきことではありません。 シンキング ツリー: 思慮深い問題解決のための言語モデルの活用
## 概念的には、ToT は言語モデルとして機能します。一般的な問題を解決するためのメソッドは次のとおりです。いくつかの利点: (1) 普遍性。 IO、CoT、CoT-sc、および自己洗練は、ToT の特殊なケースと見なすことができます (つまり、深さと幅が制限されたツリー、図 1);
研究では、最も高度な言語モデル GPT-4 を使用した場合でも、標準的な IO プロンプトまたは思考チェーン (CoT) を通じて 3 つのタスクが提案されました。サンプリングが必要になるため、これらの作業は依然として困難です。 


以上が考えて、考えて、止まらずに考えて Thinking Tree ToT '軍事訓練' LLMの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



