

Mysql を使用して JSON データをクエリおよび変更する方法

json データのクエリと変更
フィールド ->「$.json 属性」を使用して条件をクエリする
json_extract 関数を使用してクエリを実行します。json_extract(field, "$.json attributes")
json 配列に基づいてクエリを実行するには、JSON_CONTAINS(field) を使用します。 、JSON_OBJECT( 'json 属性', "content")): [{}]この形式の json 配列をクエリします
MySQL5.7 以降は JSON 操作をサポートし、JSON ストレージ タイプを追加します
一般に、データベースは JSON 型データを保存するために JSON 型または TEXT 型を使用します
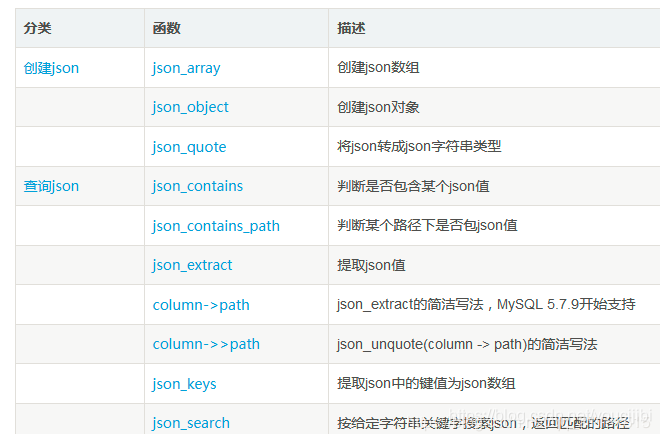
いくつかの関連関数
例

ここでは json フィールド形式を作成しませんでしたが、テキストを使用して json を保存しました。
注意: JSON タイプを使用する場合、列に格納されるデータは JSON 形式に準拠している必要があります。準拠していない場合はエラーが発生します。 2) JSON データ型にはデフォルト値がありません。
json 形式のデータをこの列に挿入します:
{"age": "28", "pwd": "lisi", "name": "李四"}Query
1,
select * from `offcn_off_main` where json_extract(json_field,"$.name") = '李四'
2,
select * from `offcn_off_main` where json_field->'$.name' = '李四'
Useインデックスが使用できないことを確認するために説明します。
したがって、これを変更する必要があります:
mysql は、json 列の属性インデックス付けをネイティブにサポートしていませんが、mysql の仮想列を通じて間接的に json 内の特定の項目にインデックスを付けることができます。属性のインデックスを作成する原理は、json で属性の仮想列を作成し、次にその仮想列のインデックスを作成することにより、間接的に属性のインデックスを作成することです。
MySQL 5.7 では、仮想生成列と保存された生成列の 2 種類の生成列がサポートされています。前者は生成列をデータ ディクショナリ (テーブルのメタデータ) に保存するだけで、この列は保存されませんディスクに永続化します。後者は、生成された列を読み取られるたびに計算するのではなく、ディスクに永続化します。明らかに、後者は既存のデータから計算できるデータを保存し、より多くのディスク領域を必要とし、仮想列に比べて利点がありません----(実際、必要なクエリ計算が少なくて済むので、まだ利点があると思います) . )
したがって、MySQL 5.7 では、生成されたカラムのタイプは指定されておらず、デフォルトは仮想カラムです。
Stored Generated Golumn が必要な場合は、Virtual Generated Column にインデックスを作成する方が適切かもしれません。通常の状況では、MySQL のデフォルトの方法でもある Virtual Generated Column が使用されます。
形式は次のとおりです:
fieldname <type> [ GENERATED ALWAYS ] AS ( <expression> ) [ VIRTUAL|STORED ] [ UNIQUE [KEY] ] [ [PRIMARY] KEY ] [ NOT NULL ] [ COMMENT <text> ]
ここにいます:
ALTER TABLE 'off_main' `names_virtual` VARCHAR(20) GENERATED ALWAYS AS (`json_field` ->> '$.name') not null;
注: 参照には「>>」演算子を使用できます。 JSON フィールドのキー (KEY)。この例では、仮想フィールド names_virtual が null 非許容として定義されています。実際の業務では、具体的な状況に応じて判断する必要があります。 JSON 自体は構造が弱いデータ オブジェクトであるためです。言い換えれば、その構造は固定されていません。
仮想フィールドにインデックスを追加します:
CREATE INDEX `names` ON `off_main`(`names_virtual`);
仮想フィールドがテーブルの作成時に追加されず、後でインデックスを追加するときに追加される場合、仮想フィールドが一部の行は null ですが、null ではないように設定されている場合、インデックスを正常に作成できず、プロンプト列を null にすることはできません。
インデックスを追加した後、説明してください。インデックスが使用され、仮想フィールドの値は変更されると自動的に変更されます。json フィールドのプロパティは変更されると自動的に変更されます。
変更内容を見てみましょう
update off_main set json_field = json_set(json_field,'$.phone', '132') WHERE id = 45 //同时修改多个 UPDATE offcn_off_main set json_field = json_set(json_field,'$.name',456,'$.age','bbb') WHERE id = 45
存在する json_set() メソッドは上書きされ、存在しないメソッドは追加されます。
削除
UPDATE offcn_off_main set json_field = json_remove(json_field,'$.pwd','$.phone') WHERE id = 45
挿入
UPDATE offcn_off_main set json_field = json_insert(json_field,'$.pwd','111') WHERE id = 45
挿入と更新の違いは、挿入が存在しない場合は追加され、存在する場合は追加されないことです。
Mysql は json データを処理します。
1. データ量が少ない場合は、json データを mysql の json フィールドに直接コピーします。データが大きすぎる場合は、 Java およびその他のバックグラウンド フォームを通じて JSON データを解析し、データベースに書き込みます。
クエリ操作
select *,json->'$.features[0].geometry.rings' as rings from JSON;
あるテーブルからデータの一部を読み取り、別のテーブルに格納します (1 つのデータ)
insert into DT_village(name, border) SELECT json->'$.features[0].attributes.CJQYMC',json->'$.features[0].geometry.rings' from JSON;
json データを読み取り、データベース(この時メソッドは定義された関数の形式で実行され、量も定義可能)
#清空数据库
TRUNCATE table DT_village;
#定义存储过程
delimiter //
DROP PROCEDURE IF EXISTS insert_test_val;
##num_limit 要插入数据的数量,rand_limit 最大随机的数值
CREATE PROCEDURE insert_test_val()
BEGIN
DECLARE i int default 0;
DECLARE a,b varchar(5000);
WHILE i<10 do
set a=CONCAT('$.features[',i,'].attributes.CJQYMC');
set b=CONCAT('$.features[',i,'].geometry.rings');
insert into DT_village(name, border) select
#json->'$.features[0].attributes.CJQYMC',json->'$.features[0].geometry.rings'
# (json->a),(json->b)
json_extract(json,a),json_extract(json,b)
from JSON;
set i = i + 1;
END WHILE;
END
//
#调用存储过程
call insert_test_val();カーソルを呼び出してjsosnデータの行を取得し、挿入操作を実行します
rreee以上がMysql を使用して JSON データをクエリおよび変更する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7463
7463
 15
1376
52
77
11
18
17
15
1376
52
77
11
18
17

 MySQLユーザーとデータベースの関係
Apr 08, 2025 pm 07:15 PM
MySQLユーザーとデータベースの関係
Apr 08, 2025 pm 07:15 PM
MySQLデータベースでは、ユーザーとデータベースの関係は、アクセス許可と表によって定義されます。ユーザーには、データベースにアクセスするためのユーザー名とパスワードがあります。許可は助成金コマンドを通じて付与され、テーブルはCreate Tableコマンドによって作成されます。ユーザーとデータベースの関係を確立するには、データベースを作成し、ユーザーを作成してから許可を付与する必要があります。
 RDS MySQL Redshift Zero ETLとの統合
Apr 08, 2025 pm 07:06 PM
RDS MySQL Redshift Zero ETLとの統合
Apr 08, 2025 pm 07:06 PM
データ統合の簡素化:AmazonrdsmysqlとRedshiftのゼロETL統合効率的なデータ統合は、データ駆動型組織の中心にあります。従来のETL(抽出、変換、負荷)プロセスは、特にデータベース(AmazonrdsmysQlなど)をデータウェアハウス(Redshiftなど)と統合する場合、複雑で時間がかかります。ただし、AWSは、この状況を完全に変えたゼロETL統合ソリューションを提供し、RDSMYSQLからRedshiftへのデータ移行のための簡略化されたほぼリアルタイムソリューションを提供します。この記事では、RDSMysQl Zero ETLのRedshiftとの統合に飛び込み、それがどのように機能するか、それがデータエンジニアと開発者にもたらす利点を説明します。
 MySQLのユーザー名とパスワードを入力する方法
Apr 08, 2025 pm 07:09 PM
MySQLのユーザー名とパスワードを入力する方法
Apr 08, 2025 pm 07:09 PM
MySQLのユーザー名とパスワードを入力するには:1。ユーザー名とパスワードを決定します。 2。データベースに接続します。 3.ユーザー名とパスワードを使用して、クエリとコマンドを実行します。
 MySQLのクエリ最適化は、特に大規模なデータセットを扱う場合、データベースのパフォーマンスを改善するために不可欠です
Apr 08, 2025 pm 07:12 PM
MySQLのクエリ最適化は、特に大規模なデータセットを扱う場合、データベースのパフォーマンスを改善するために不可欠です
Apr 08, 2025 pm 07:12 PM
1.正しいインデックスを使用して、データの量を削減してデータ検索をスピードアップしました。テーブルの列を複数回検索する場合は、その列のインデックスを作成します。あなたまたはあなたのアプリが基準に従って複数の列からのデータが必要な場合、複合インデックス2を作成します2。選択した列のみを避けます。必要な列のすべてを選択すると、より多くのサーバーメモリを使用する場合にのみサーバーが遅くなり、たとえばテーブルにはcreated_atやupdated_atやupdated_atなどの列が含まれます。
 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 mysqlを表示する方法
Apr 08, 2025 pm 07:21 PM
mysqlを表示する方法
Apr 08, 2025 pm 07:21 PM
次のコマンドでmysqlデータベースを表示します。サーバーに接続します:mysql -u username -pパスワードrun showデータベース。すべての既存のデータベースを取得するコマンド[データベース]を選択します。データベース名を使用します。テーブルを表示:表を表示します。テーブル構造を表示:テーブル名を説明してください。データを表示:[テーブル名]から[ *]を選択します。
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICAT自体はデータベースパスワードを保存せず、暗号化されたパスワードのみを取得できます。解決策:1。パスワードマネージャーを確認します。 2。NAVICATの「パスワードを記憶する」機能を確認します。 3.データベースパスワードをリセットします。 4.データベース管理者に連絡してください。
