

where の後ろのフィルター フィールドにインデックスを作成し (select/update/delete の後ろの where はすべて適用されます)、インデックスを使用してフィルタリングの効率を向上させます。テーブル全体が必要です
をスキャンし、一意の要件を持つフィールドに一意のインデックスを追加して、クエリの効率を向上させます。見つかった場合は、
区別性が高い場合 列にインデックスを作成します (すべてのキーが一意であるため、主キーの区別性が最も高くなります)
シナリオ 1: where フィールドの背後でフィールドにインデックスを確立する
-- 描述:当where中有多个条件需要进行匹配的时候,那么可以创建联合索引,这样所有的条件都可以使用索引,大大提高了检索的效率 select * from student_info where student_id = 1; -- 当然数据量比较大的时候给where后面的字段添加索引 create index student_id_index on student_info (student_id)
インデックスを追加するまでに、基本的にテーブル全体を走査するため、0.383 秒かかりました

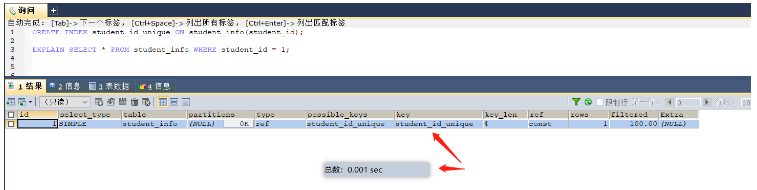
select * from student_info where id = 1001; -- 因为学号是唯一的,所以可以在学号这个字段上添加唯一所用 create index id_unique on student_info(id);
select * from student_info order by name; -- 这里就可以给name字段进行索引的添加 select * from student_info group by class_id; -- 这里就可以给class_id字段添加索引
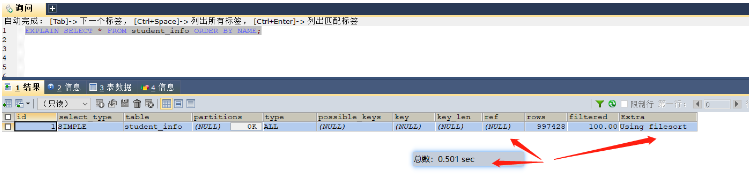 ##インデックス作成後、0.01 秒かかりました
##インデックス作成後、0.01 秒かかりました
シナリオ4: DISTINCT の後のフィールドにインデックスを追加します (インデックスはすでに同じフィールドを並べ替えており、重複排除の効率が高くなります) 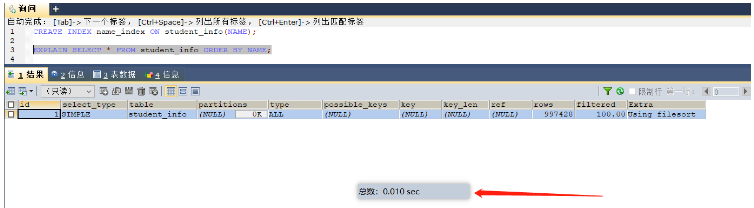
select distinct(student_id) from student_info; -- 这里就可以根据student_id字段建立索引 create index student_id_index on student_info;
SELECT s.course_id,NAME,s.student_id,c.course_name FROM student_info s JOIN course c ON s.`course_id` = c.`course_id` WHERE NAME = 'xiaoyuanhao'; -- 根据大表驱动小表的原则需要在student_info表的course_id字段上建立索引
インデックス作成後は 0.003 秒かかりました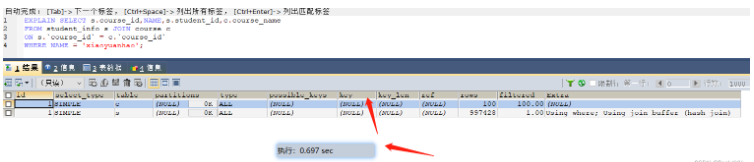
小さなテーブル大きなテーブルを駆動する: 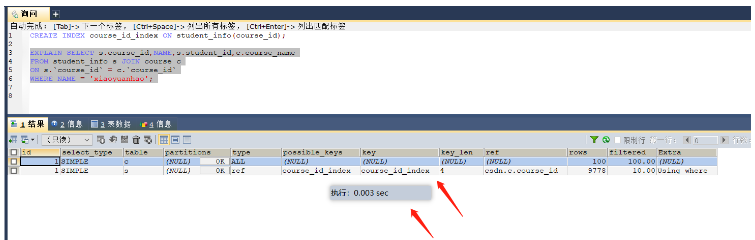
create table shop(address varchar(120) not null); alter table shop add index(address(12)); --这里只是对表中的address的前12个字符建立了索引,而不是整个字符串建立索引
#一部の文字列は非常に長いため、文字列全体にインデックスを付けると、インデックスに多くのスペースが必要になります
文字列全体を格納する必要があるため、データ項目が大きくなり、インデックスツリーの深さが深くなり、検索速度が低下します。インデックス 2 つの文字列は同じですが、主キーに基づくテーブルの戻り操作の効率は依然として比較的高いです
如何确定前缀索引中前缀的长度呢?(也就是如果前缀的长度太短,那么索引的区分度就很低,从多个字符串截取的前缀数据可能都是一样的,但是如果前缀索引的前缀过长,那么前缀索引的优点就消失了)
引入了区别度的概念,select count(distinct left(索引字段,前缀索引长度) / count(*) from xxx),该值越接近1,那么区分度就越明显,那么该索引长度就是所求的前缀索引长度
场景七:在频繁使用的列上建立索引或联合索引(频繁使用的字段应该在索引的左侧)
select * from xiaoyuanhao where age = 18; select * from xiaoyuanhao where age = 19 and sex = 'man'; select * from xiaoyuanhao where age = 10 and sex = 'man' and password = '123456'; -- 在这里实际上就可以建立age,sex,password的联合索引,只需要建立一个索引,这三个查询都是可以使用的 create index age_sex_password_index on xiaoyuanhao(age,sex,password); select * from student_info group by class_id order by name; -- 在这里可以建立class_id和name的联合索引,但是一定要注意索引的顺序,一定是要class_id在前,name在后,因为在select语句中执行的顺序是先group by 之后才是 order by 索引如果索引的字段顺序是相反的,那么就无法使用索引 create index class_id_name_index on student(class_id,name);
索引建立需要符合顺序的原因:
索引字段的顺序如果是错误的,那么索引就会失效,因为索引实际上是排好序的,如果索引建立的时候是现根据name排好序之后在根据class_id进行排序,那么在面对需要先根据class_id排序再根据name排序的业务就无法进行使用
补充:
在select * from xxx where age = 19 and sex = ‘man’ and password = '123456’这里索引建立的顺序不一定是(age,sex,password)因为在实际执行的过程中,优化器会优化执行步骤会按照索引的顺序进行查询,但是group by 和 order by的执行顺序是无法改变的,索引必须严格的按照顺序建立索引,否则索引失效
以上がMySQL インデックスの最適化がインデックスの構築に適しているのはどのような状況ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



