
バックエンド開発者の場合、単一の SQL を使用してリスト クエリ インターフェイスを実装できます。クエリ条件が複雑で、テーブル データベースの設計が無理がある場合、クエリは困難になります。この記事では、その方法を説明します。 Redis を使用して検索インターフェイスを実装します。
まずは例から始めましょう。これはショッピング サイトの検索条件です。このような検索インターフェイスを実装するように頼まれた場合、どのように実装しますか?
もちろん、と言いました。 Elasticsearch などの検索エンジンの助けを借りれば、間違いなくそれを行うことができます。しかし、ここで私が言いたいのは、自分で実装したい場合はどうするかということです?

上の図からわかるように、検索は合計 6 つのカテゴリに分かれています、および各カテゴリはさまざまなサブカテゴリに分かれています。
この場合、フィルタリング プロセスは、条件の主要カテゴリの交差部分を取得し、各サブカテゴリの単一選択、複数選択、およびカスタマイズを考慮して、条件を満たす結果セットを出力します。
さて、要件が明確になったので、実装を始めましょう。
実装 1
最初に登場するのは学生 A です。彼は SQL を書くことの「専門家」です。 A 君は自信満々に「ただのクエリインターフェイスではないですか? 条件はたくさんありますが、SQL の経験が豊富な私には問題ありません。」
そこで私は次のコードを書きました。 (ここでは MySQL を例にします):
select ... from table_1 left join table_2 left join table_3 left join (select ... from table_x where ...) tmp_1 ... where ... order by ... limit m,n
コードをテスト環境で実行し、結果が一致しているように見えたので、プレリリースの準備をしました。このプレローンチでは、問題が浮上し始めました。
プレリリースではオンライン環境をできるだけリアルに再現するため、当然データ量はテストよりもかなり多くなります。したがって、このような複雑な SQL の実行効率は想像できます。テストのクラスメートは、思い切ってリトル A のコードを打ち返しました。
実装 2
Little A の失敗から学んだ教訓を要約すると、Little B は SQL の最適化を開始し、まず SQL パフォーマンス分析用の Explain キーワードを渡しました。インデックスが追加される場所には必ずインデックスも追加されます。
複雑なSQLを複数のSQLに同時に分割し、計算結果をプログラムメモリ上で計算します。
疑似コードは次のとおりです:
$result_1 = query('select ... from table_1 where ...');
$result_2 = query('select ... from table_2 where ...');
$result_3 = query('select ... from table_3 where ...');
...
$result = array_intersect($result_1, $result_2, $result_3, ...);このソリューションは、パフォーマンスの点で最初のソリューションより明らかに優れていますが、関数の受け入れ中に、プロダクト マネージャーは依然としてクエリ速度が遅いと感じています。十分な速さではありません。
Little B 自身も、各クエリがデータベースに対して複数回クエリを実行すること、および歴史的な理由により、特定の条件下では単一テーブル クエリを実行できないことを知っています。そのため、クエリの待ち時間は避けられません。
実装 3
Little C は、上記のソリューションから最適化の余地があることに気づきました。 B 君は自分の思考に問題がないことがわかり、複雑な条件を分割し、各サブディメンションの結果セットを計算し、最後にすべてのサブ結果セットを要約してマージして、最終的に望ましい結果を取得しました。
そこで、彼は、各サブディメンションの結果セットを事前にキャッシュできるかどうかを突然考えました。これにより、毎回計算のためにデータベースをチェックすることなく、クエリ時に目的のサブセットを直接フェッチできるようになります。
ここでは、Little C はキャッシュ データの保存に Redis を使用しています。これを使用する主な理由は、Redis がさまざまなデータ構造を提供し、Redis のセットに対して交差演算や結合演算を実行するのが非常に簡単であることです。
具体的な計画は図のとおりです。
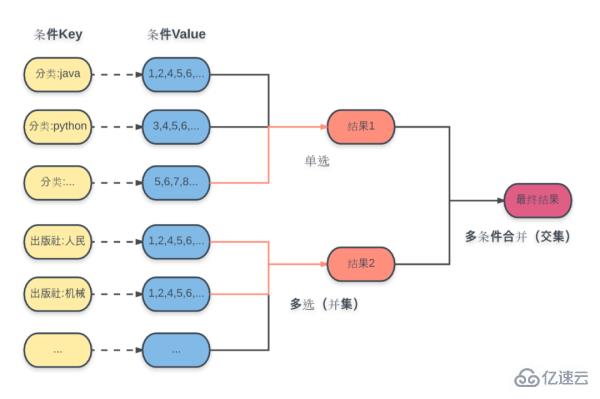
ここでの条件ごとに、あらかじめ計算された結果セットIDを対応するKeyに格納しておき、データ構造は集合(Set)です。
クエリ操作には以下が含まれます:
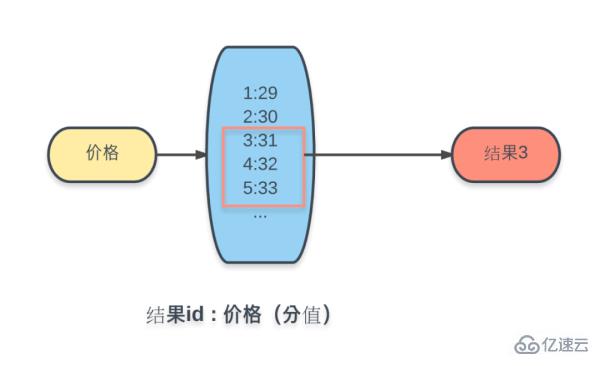
拡張機能
①ページング
ここで重大な機能上の欠陥を発見したかもしれません。ページングなしでリスト クエリを実行するにはどうすればよいでしょうか? 。はい、Redis がページングを実装する方法をすぐに見てみましょう。ページングでは主に並べ替えが行われますが、わかりやすくするために作成時間を例に挙げてみましょう。図に示すように:
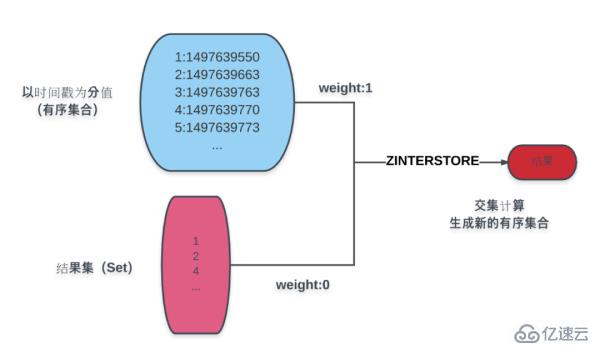
図の青色の部分は、作成時間に基づいて順序付けられた製品のコレクションです。青色の下にある結果セットは条件付き計算です。結果として、ZINTERSTORE コマンドにより、結果セットの重みは 0 に割り当てられ、積時間の結果は 1 になり、交差を取ることによって得られた結果セットは、作成時間スコアの新しい順序セットに割り当てられます。
新しい結果セットに対する操作により、ページングに必要なさまざまなデータを取得できます:
合計ページ数は次のとおりです: ZCOUNT コマンド。
現在のページの内容: ZRANGE コマンド。
逆順に並べると、ZREVRANGE コマンド。
②データ更新
インデックスデータ更新の問題に関しては、2 つの方法があります。 1 つは、製品データの変更によって更新操作を即座にトリガーする方法であり、もう 1 つは、スケジュールされたスクリプトを通じてバッチ更新を実行する方法です。
ここで注意すべき点は、インデックス内容の更新に関して、乱暴にKeyを削除した場合にはKeyをリセットする必要があることです。
Redis の 2 つの操作はアトミックに実行されないため、途中でギャップが生じる可能性があります。コレクション内の無効な要素のみを削除し、新しい要素を追加することをお勧めします。
③パフォーマンスの最適化
Redis はメモリレベルの操作であるため、単一のクエリは非常に高速です。ただし、実装で複数の Redis 操作が実行される場合、複数の Redis 接続時間が不要な時間を消費する可能性があります。
MULTI コマンドを使用して、トランザクションを開始し、複数の Redis 操作を 1 つのトランザクションに入れ、最後に EXEC を通じてアトミック実行を実行します。
注: ここでのいわゆるトランザクションは 1 つの接続で複数の操作を実行するだけであり、実行中に障害が発生してもロールバックされません。
概要
これは、Redis を使用してクエリ検索を最適化する単純なデモです。既存のオープンソース検索エンジンと比較して、より軽量であり、学習の必要性も少なくなります。より低い。
第二に、オープンソースの検索エンジンと考え方が似ており、単語解析を追加すれば全文検索と同様の機能も実現できます。
以上がRedis を使用して検索インターフェイスを実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



