

MySQL の一時テーブルに重複した名前が付けられる理由は何ですか?

今日は次の質問から始めます: 一時テーブルの特徴は何ですか? どのようなシナリオに適していますか?
ここで、最初に誤解されやすい問題を明確にする必要があります。一時テーブルはメモリ テーブルであると考える人もいるかもしれません。ただし、これら 2 つの概念はまったく異なります。
メモリ テーブルは、Memory エンジンを使用するテーブルを指します。テーブルを作成するための構文は、create table …engine です。 =メモリ 。 **この種のテーブルのデータはメモリに保存され、システムの再起動時に消去されますが、テーブル構造はまだ存在します。 **「奇妙に見える」これら 2 つの機能を除けば、他の機能から見ると、これは通常のテーブルです。
一時テーブル、さまざまなエンジン タイプを使用できます。 InnoDB エンジンまたは MyISAM エンジンの一時テーブルを使用する場合、データは書き込み時にディスクに書き込まれます。もちろん、一時テーブルでもメモリ エンジンを使用できます。
メモリ テーブルと一時テーブルの違いを明確にした後、一時テーブルの特性を見てみましょう。
一時テーブルの特性
理解を容易にするために、次の一連の操作を見てみましょう:

できる限り一時テーブルを参照してください。これには次のような特徴があります:
テーブルを作成するための構文は createtemporary table … です。
他のスレッドはセッションによって作成された一時テーブルにアクセスできず、そのセッションにのみ表示されます。したがって、図のセッション A によって作成された一時テーブル t は、セッション B には見えません。
一時テーブルには、通常のテーブルと同じ名前を付けることができます。
セッション A に一時テーブルと同名の通常テーブルが存在する場合、showcreate ステートメントと add、delete、modify、query ステートメントは一時テーブルにアクセスします。
showtables コマンドは一時テーブルを表示しません。
一時テーブルにはそれを作成したセッションのみがアクセスできるため、一時テーブル はセッションが終了すると自動的に削除されます。
一時テーブルにはこの機能があるため、前の記事の結合最適化シナリオは一時テーブルの使用に特に適しています。なぜ?理由は主に次の 2 つの側面が含まれます:
異なるセッションの一時テーブルは同じ名前を持つことができます. 複数のセッションが同時に結合の最適化を実行している場合テーブル名が重複するとテーブル作成に失敗しますので、ご安心ください。
データの削除を心配する必要はありません。通常のテーブルを使用する場合、プロセス実行中にクライアントが異常切断された場合、またはデータベースが異常再起動された場合、中間プロセスで生成されたデータテーブルをクリーンアップする必要があります。一時テーブルは自動的にリサイクルされるため、この追加の操作は必要ありません。
スレッド間の重複名の競合を心配する必要がないため、一時テーブルは複雑なシステムの最適化プロセスでよく使用されます。クエリ。中でも、サブデータベースとサブテーブルシステムのクロスデータベースクエリは代表的な利用シナリオです。
データベースとテーブルのシャーディングの一般的なシナリオは、論理的に大きなテーブルを異なるデータベース インスタンスに分散することです。例えば。特定のフィールド f について、大きなテーブル ht を 1024 のサブテーブルに分割し、これらのサブテーブルを 32 のデータベース インスタンスに分散します。次の図に示すように: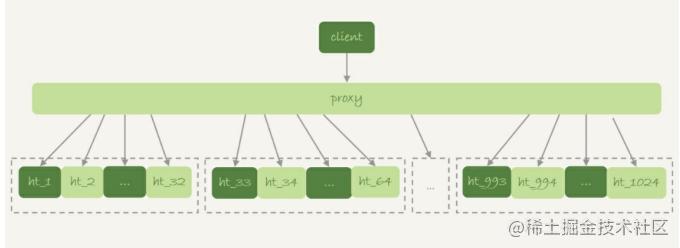
select v from ht where f=N;
select v from ht where k >= M order by t_modified desc limit 100;
最初のアイデアは です。これは、プロキシ層のプロセス コードでソートを実装します。この方法の利点は処理速度が速く、サブデータベースからデータを取得した後、メモリ上の計算に直接参加できることです。ただし、このソリューションの欠点も明らかです。
- は比較的大量の開発作業を必要とします。例として挙げたステートメントは比較的単純ですが、グループ化や結合などの複雑な操作が含まれる場合、中間層の開発能力は比較的高くなります。
对proxy端的压力比较大,尤其是很容易出现内存不够用和CPU瓶颈的问题。
另一种思路就是,把各个分库拿到的数据,汇总到一个MySQL实例的一个表中,然后在这个汇总实例上做逻辑操作。
比如上面这条语句,执行流程可以类似这样:
在汇总库上创建一个临时表temp_ht,表里包含三个字段v、k、t_modified;
在各个分库上执行
select v,k,t_modified from ht_x where k >= M order by t_modified desc limit 100;把分库执行的结果插入到temp_ht表中;
执行
select v from temp_ht order by t_modified desc limit 100;
得到结果。 这个过程对应的流程图如下所示:
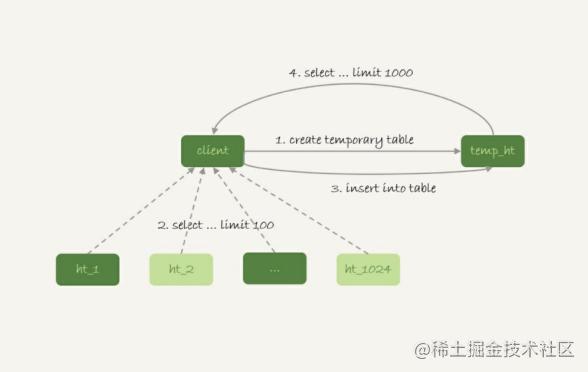
在实践中,我们往往会发现每个分库的计算量都不饱和,所以会直接把临时表temp_ht放到32个分库中的某一个上。
为什么临时表可以重名?
你可能会问,不同线程可以创建同名的临时表,这是怎么做到的呢?
我们在执行
create temporary table temp_t(id int primary key)engine=innodb;
这个语句的时候,MySQL要给这个InnoDB表创建一个frm文件保存表结构定义,还要有地方保存表数据。
这个frm文件放在临时文件目录下,文件名的后缀是.frm,前缀是“#sql{进程id}_ {线程id}_ 序列号”。
从文件名的前缀规则,我们可以看到,其实创建一个叫作t1的InnoDB临时表,MySQL在存储上认为我们创建的表名跟普通表t1是不同的,因此同一个库下面已经有普通表t1的情况下,还是可以再创建一个临时表t1的。
先来举一个例子。

进程号为1234的进程,它的线程id分别为4和5,分别属于会话A和会话B。因此,可以看出,session A和session B创建的临时表在磁盘上的文件名不会冲突。
MySQL维护数据表,除了物理上要有文件外,内存里面也有一套机制区别不同的表,每个表都对应一个table_def_key。
一个普通表的table_def_key的值是由“库名+表名”得到的,所以如果你要在同一个库下创建两个同名的普通表,创建第二个表的过程中就会发现table_def_key已经存在了。
而对于临时表,table_def_key在“库名+表名”基础上,又加入了“server_id+thread_id”。
也就是说,session A和session B创建的两个临时表t1,它们的table_def_key不同,磁盘文件名也不同,因此可以并存。
在实现上,每个线程都维护了自己的临时表链表。这样每次session内操作表的时候,先遍历链表,检查是否有这个名字的临时表,如果有就优先操作临时表,如果没有再操作普通表;在session结束的时候,对链表里的每个临时表,执行 “DROPTEMPORARY TABLE +表名”操作。
你会注意到,在binlog中也有DROP TEMPORARY TABLE命令的记录。你一定会觉得奇怪,临时表只在线程内自己可以访问,为什么需要写到binlog里面?这,就需要说到主备复制了。
临时表和主备复制
既然写binlog,就意味着备库需要。 你可以设想一下,在主库上执行下面这个语句序列:
create table t_normal(id int primary key, c int)engine=innodb;/*Q1*/ create temporary table temp_t like t_normal;/*Q2*/ insert into temp_t values(1,1);/*Q3*/ insert into t_normal select * from temp_t;/*Q4*/
如果关于临时表的操作都不记录,那么在备库就只有create table t_normal表和insert intot_normal select * fromtemp_t这两个语句的binlog日志,备库在执行到insert into t_normal的时候,就会报错“表temp_t不存在”。
你可能会说,如果把binlog设置为row格式就好了吧?因为binlog是row格式时,在记录insert intot_normal的binlog时,记录的是这个操作的数据,即:write_rowevent里面记录的逻辑是“插入一行数据(1,1)”。
确实是这样。如果当前的binlog_format=row,那么跟临时表有关的语句,就不会记录到binlog里。也就是说,只在binlog_format=statment/mixed的时候,binlog中才会记录临时表的操作。
在这种情况下,执行创建临时表语句的操作会被传递到备用数据库进行处理,从而触发备用数据库的同步线程创建相应的临时表。主库在线程退出的时候,会自动删除临时表,但是备库同步线程是持续在运行的。因此,我们需要在主数据库中再运行一个DROP TEMPORARY TABLE命令以便备用数据库执行。
メイン データベース上の別のスレッドが同じ名前の一時テーブルを作成しても問題ありませんが、実行のためにスタンバイ データベースへの転送をどのように処理すればよいでしょうか?
ここで例を示します。次のシーケンスでは、インスタンス S が M のスタンバイ データベースです。

- temporaryセッション A t1 のテーブル、スタンバイ データベースの table_def_key は次のとおりです: ライブラリ名 t1 "M のサーバー ID" "セッション A のスレッド ID";
- セッション B の一時テーブル t1、スタンバイ データベースの table_def_keyスタンバイ データベースは次のとおりです: ライブラリ名 t1 "M のサーバー ID" "セッション B の thread_id"。
以上がMySQL の一時テーブルに重複した名前が付けられる理由は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7478
7478
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICAT自体はデータベースパスワードを保存せず、暗号化されたパスワードのみを取得できます。解決策:1。パスワードマネージャーを確認します。 2。NAVICATの「パスワードを記憶する」機能を確認します。 3.データベースパスワードをリセットします。 4.データベース管理者に連絡してください。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 MySQLでテーブルをコピーする方法
Apr 08, 2025 pm 07:24 PM
MySQLでテーブルをコピーする方法
Apr 08, 2025 pm 07:24 PM
MySQLでテーブルをコピーするには、新しいテーブルの作成、データの挿入、外部キーの設定、インデックスのコピー、トリガー、ストアドプロシージャ、および機能が必要です。特定の手順には、同じ構造を持つ新しいテーブルの作成が含まれます。元のテーブルからデータを新しいテーブルに挿入します。同じ外部キーの制約を設定します(元のテーブルに1つがある場合)。同じインデックスを作成します。同じトリガーを作成します(元のテーブルに1つがある場合)。同じストアドプロシージャまたは関数を作成します(元のテーブルが使用されている場合)。
 MariadBのNAVICATでデータベースパスワードを表示する方法は?
Apr 08, 2025 pm 09:18 PM
MariadBのNAVICATでデータベースパスワードを表示する方法は?
Apr 08, 2025 pm 09:18 PM
Passwordが暗号化された形式で保存されているため、MariadbのNavicatはデータベースパスワードを直接表示できません。データベースのセキュリティを確保するには、パスワードをリセットするには3つの方法があります。NAVICATを介してパスワードをリセットし、複雑なパスワードを設定します。構成ファイルを表示します(推奨されていない、高リスク)。システムコマンドラインツールを使用します(推奨されません。コマンドラインツールに習熟する必要があります)。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
 NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する手順:データベースに接続します。 SQLエディターウィンドウを作成します。 SQLクエリまたはスクリプトを書きます。 [実行]ボタンをクリックして、クエリまたはスクリプトを実行します。結果を表示します(クエリが実行された場合)。
 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
