

MySQL インデックスを作成する方法

1. B ツリー インデックス
名前が示すように、B ツリー構造を持つインデックスは B ツリー インデックスであり、通常の状況では、InnoDb エンジンで作成される従来のインデックスはすべてB ツリー構造。
B ツリーのインデックスは次のとおりです。
1.1. クラスター化インデックス/クラスター化インデックス
主キーを定義する場合、主キーに自動的に追加されるインデックスがクラスター化インデックス (クラスター化インデックスとも呼ばれます) です。
Mysql では、コンポーネントを使用して B ツリー構造を構築しており、図に示すように、各リーフ ノードは主キーおよびその他の関連データに対応します。
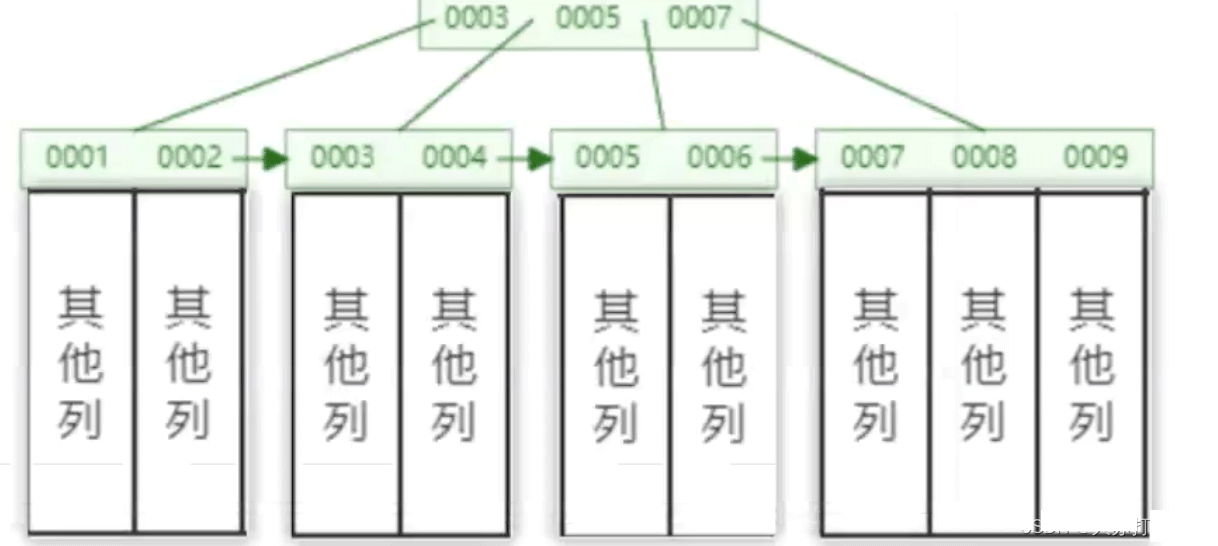
テーブルの作成時に主キーを定義しない場合、Mysql は主キーと対応するインデックスを自動的に作成します。主キーの名前は rowId# です。
一般的なセカンダリ インデックスは次のステートメントで作成されます:
CREATE INDEX order_name_index on t_order(order_name);
複合インデックスは次のステートメントで作成されます:
CREATE INDEX order_name_and_order_type_index on t_order(order_name, order_type);
たとえば、定義ステートメントは次のとおりです。
CREATE INDEX joint_index on t_order(order_name, order_type, submit_time);
order_name をソートし、order_name の場合はソートします。 が同じである場合、order_type を並べ替えると、最後の行は submit_time になります。
where 句または order by およびその他の句が試行されます。 ## で始める #order_name で始める、など。 たとえば、上記の 3 つの列で構成される複合インデックスを定義しました。クエリまたは並べ替えを行うときは、最初に
、次に order_type、最後に#を試してみてください。 ##submit_time。
select * from t_order where order_name = 'order1' and order_type = 1 and submit_time = str_to_date('2022-08-02 00:52:26', '%Y-%m-%d %T')
理由は非常に簡単です。ジョイント インデックスのソート ルールは、最初に order_name をソートし、order_name が同じ場合は、次に order_type をソートするためです。 、最後に submit_time。したがって、クエリの並べ替え時にこのルールに従った場合にのみ、インデックスを使用できます。 たとえば、左端の原則に完全に準拠していない場合、クエリの並べ替えでは 2 つの列のみが配置され、中央の order by order_name、submit_time
1.3.3. ジョイントインデックスのクエリ最適化
show index from t_order;
ログイン後にコピー
show index from t_order;
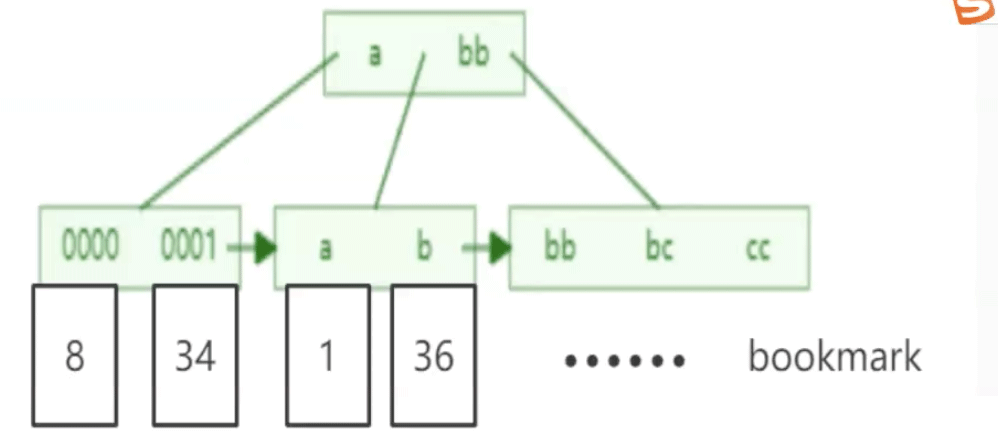
によって返されたフィールドを確認してください。結合インデックスを構成する列と主キーのみを返すようにしてください。テーブルの破損を避けるために、他の列は返さないでください。戻る。  ジョイント インデックスの B ツリーのリーフ ノードには、主キーとジョイント インデックスを構成する列の値のみが含まれるため、これは理解しやすいはずです。返されるフィールドがこれらのみの場合列が完成すると、B ツリーのクエリが完了します。他の列を返したい場合は、主キーのインデックスを検索し、テーブルを返す操作を実行する必要があります。
ジョイント インデックスの B ツリーのリーフ ノードには、主キーとジョイント インデックスを構成する列の値のみが含まれるため、これは理解しやすいはずです。返されるフィールドがこれらのみの場合列が完成すると、B ツリーのクエリが完了します。他の列を返したい場合は、主キーのインデックスを検索し、テーブルを返す操作を実行する必要があります。
2. ハッシュ インデックス
ステートメントを使用します:
show engine innodb status;
status ハッシュインデックスの状況を含む多くの情報があります。情報をエディタにコピーして表示してみましょう。このセクションはハッシュ インデックス情報です。
ハッシュインデックスの状況を含む多くの情報があります。情報をエディタにコピーして表示してみましょう。このセクションはハッシュ インデックス情報です。
------------------------------------- INSERT BUFFER AND ADAPTIVE HASH INDEX ------------------------------------- Ibuf: size 1, free list len 0, seg size 2, 0 merges merged operations: insert 0, delete mark 0, delete 0 discarded operations: insert 0, delete mark 0, delete 0 Hash table size 34679, node heap has 0 buffer(s) Hash table size 34679, node heap has 0 buffer(s) Hash table size 34679, node heap has 5 buffer(s) Hash table size 34679, node heap has 0 buffer(s) Hash table size 34679, node heap has 1 buffer(s) Hash table size 34679, node heap has 0 buffer(s) Hash table size 34679, node heap has 1 buffer(s) Hash table size 34679, node heap has 1 buffer(s) -- 哈希索引的命中率,可根据这个来决定是否使用哈希索引 0.00 hash searches/s, 0.00 non-hash searches/s ---
3、索引的创建策略
3.1、 单列索引的策略
3.1.1、列的类型占用的空间越小,越适合作为索引
因为B+树也是占用空间的,所以在固定空间中,如果列的类型占用的空间越小,那我们一次就能读取更多的B+树节点,这样自然就加快了效率。
3.1.2、根据列的值的离散性
离散性是指数据的值重复的程度高不高,假如有N条数据的话,那离散性就可以用数值表示,范围是1/N 到 1。
比如说某个列在数据库中有下面几条数据(1, 2, 3, 4, 5, 5, 3),其中5和3都有重复,去重后应该是(1, 2, 3, 4, 5)。我们将去重后的条数除以总条数就得到离散性。这里是5/7。列中重复数据较多时,对应的数值较小,而重复数据较少时,数值相应较大。
如果一个列的数据的重复性越低,那么这个列就越适合加索引。
因为索引是需要起到筛选的作用。比如我们有个where条件是where id = 1,如果数据重复性较高,那可能根据索引会返回100条数据,然后我们在根据其他where条件在100条数据中再筛选。
如果数据重复性较低,那可能就只返回1条数据,那之后的运算量明显小得多。
所以一个列的数据离散性越高,那这个列越适合添加索引。
我们可以用下面的语句得到某个列的离散性程度。
select count(distinct id)/count(*) form t_table;
3.1.3、前缀索引
前缀索引和后缀索引:
有些列的值比较长,比如一些备注日志信息也会记录在数据库当中,这类信息的长度往往比较长,如果我们需要对这类列加索引,那索引并不是索引字符串的全部长度。这时候我们就可以建立前缀索引,即对字符串的前面几位建立索引。
所以前缀索引就是建立范围更小索引,选择一个好前缀位数就能有一个更好的查询效率。
不过有一些缺点,就是这类索引无法应用到order by和group语句上。
Mysql没有后缀索引,如果非要实现后缀索引,那在数据存储时我们应该将数据反转,这样就能用前缀索引达到后缀索引的效果。后缀索引的一个经典应用就是邮箱,快速查询某种类型的邮箱。
选择前缀索引的位数:
这里的逻辑和列的离散性类似,我们需要看看字符串的前面几位的子字符串的离散性如何。比如对于下面的表,内容是电影票的相关信息,我们需要对order_note建立前缀索引。
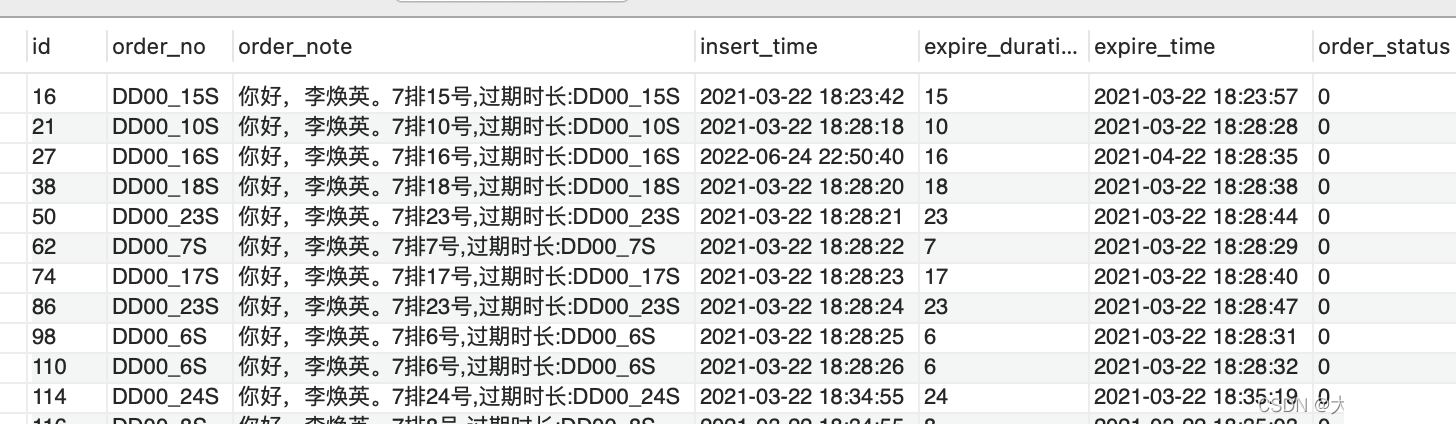
来比较一下各个位的子字符串的离散性。
SELECT COUNT(DISTINCT LEFT(order_note,3))/COUNT(*) AS sel3, COUNT(DISTINCT LEFT(order_note,4))/COUNT(*)AS sel4, COUNT(DISTINCT LEFT(order_note,5))/COUNT(*) AS sel5, COUNT(DISTINCT LEFT(order_note, 6))/COUNT(*) As sel6, COUNT(DISTINCT LEFT(order_note, 7))/COUNT(*) As sel7, COUNT(DISTINCT LEFT(order_note, 8))/COUNT(*) As sel8, COUNT(DISTINCT LEFT(order_note, 9))/COUNT(*) As sel9, COUNT(DISTINCT LEFT(order_note, 10))/COUNT(*) As sel10, COUNT(DISTINCT LEFT(order_note, 11))/COUNT(*) As sel11, COUNT(DISTINCT LEFT(order_note, 12))/COUNT(*) As sel12, COUNT(DISTINCT LEFT(order_note, 13))/COUNT(*) As sel13, COUNT(DISTINCT LEFT(order_note, 14))/COUNT(*) As sel14, COUNT(DISTINCT LEFT(order_note, 15))/COUNT(*) As sel15, COUNT(DISTINCT order_note)/COUNT(*) As total FROM order_exp;

可以看出,前面几位的子字符串的离散程度较低,后面sel13开始就比较高,那我们可以根据实际情况,建立13~15位的前缀索引。
建立前缀索引SQL语句:
alter table order_exp add key(order_note(13));
3.1.2、只为搜索、排序和分组的列建索引
这个理由很简单,不解释了。
3.2、 多列索引的策略
3.2.1、离散性最高的列放前面
原因很简单,查询时根据定义复合索引时的列的顺序来查询的,离散性高的列放在前面的话,就能更早的将更多的数据排除在外。
3.2.2、三星索引
三星索引是一种策略。有三种条件,满足一条则索引获得一颗星,三颗星则是很好的索引。
三条策略分别是
索引将相关记录放在一起。
意思是查询需要的数据在索引树的叶子节点中连续或者足够靠近。举个例子,下面是某个索引的B+树。查询所需数据仅在叶节点的前两个范围内,即0000至a。这很明显,后面的片我们就没必要再去查询了,这无疑增加了效率。当所需数据分布在每个片上时,查询次数就会显著增加。
所以查询需要的数据在叶子节点上越连续,越窄就越好。
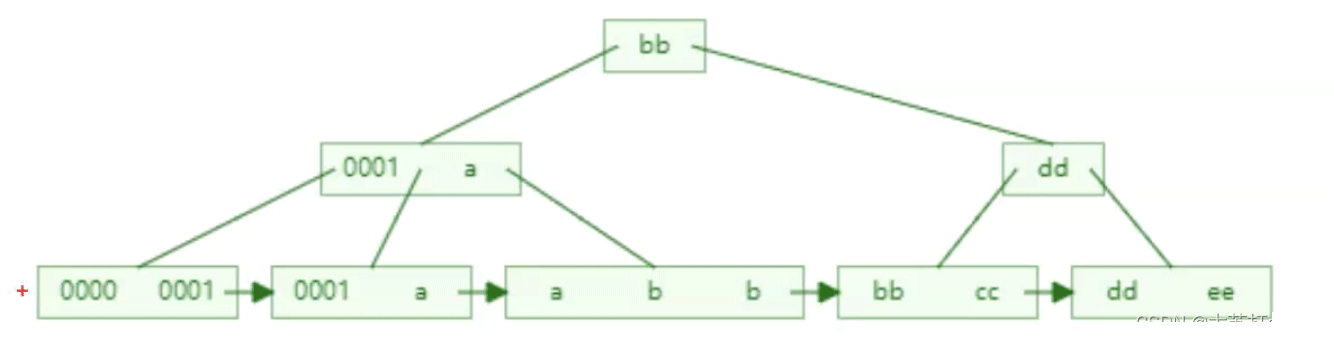
索引中的数据顺序与查找中的数据排序一致。
这容易理解,讲解联合索引中说过,B+树的排序顺序和索引中的数据一样,所以查询时的where的数据顺序越贴近索引中的顺序,就越能更好地利用B+树。
索引的列包含查询中的所有列。
这个可以避免回文操作,不多解释。
三星索引的权重:
一般来说第三个策略权重占到50%,之后是第一个策略27%, 第二个策略23%。
三星索引实例:
CREATE TABLE customer ( cno INT, lname VARCHAR (10), fname VARCHAR (10), sex INT, weight INT, city VARCHAR (10) ); CREATE INDEX idx_cust ON customer (city, lname, fname, cno);
我们创建以上的索引,那么对于下面的查询语句,这个索引就是三星索引。
select cno,fname from customer where lname='xx' and city ='yy' order by fname;
首先,查询条件中有lname=’xx’ and city =’yy’,这条件让我们这需要在lname=’xx’ and city =’yy’的那一片B+树的叶子节点中查询,让我们的查询变窄了很多,并且这部分的数据是连续的,因为B+树是先根据city排序,再根据lname查询。
另外,因为已经锁定lname=’xx’ and city =’yy’,所以这部分的数据是根据fname和cno排序。查询语句正好是根据`fname```排序,所以第二点也满足。
最后是查询的结果都包含正在索引中,不会有回文,第三点也满足,所以这个索引是三星索引。
以上がMySQL インデックスを作成する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7554
7554
 15
1382
52
83
11
28
96
15
1382
52
83
11
28
96

 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 SQLデータベースの構築方法
Apr 09, 2025 pm 04:24 PM
SQLデータベースの構築方法
Apr 09, 2025 pm 04:24 PM
SQLデータベースの構築には、DBMSの選択が必要です。 DBMSのインストール。データベースの作成。テーブルの作成;データの挿入;データの取得。データの更新。データの削除。ユーザーの管理。データベースのバックアップ。
