

MySQL のインデックス作成と最適化に関する知識ポイントは何ですか?

インデックスとは何ですか?
インデックスは、MySQL が効率的なクエリを実行するのに役立つデータ構造です。本の目次と同様に、クエリを高速化できます
インデックスの構造?
インデックスには、B-Tree インデックスとハッシュ インデックスを含めることができます。インデックスはストレージ エンジンに実装されます
InnoDB/MyISAM は B ツリー インデックスのみをサポートします
メモリ/ヒープは B ツリー インデックスとハッシュ インデックスをサポートします
- #B-TreeB-Tree は、ディスク操作に非常に適したデータ構造です。これは、多方向のバランスの取れた検索ツリーです。その高さは通常 2 ~ 4 で、その非リーフ ノードとリーフ ノードにデータが格納されます。そのすべてのリーフ ノードは同じレイヤー上にあります。下の図は B ツリーです
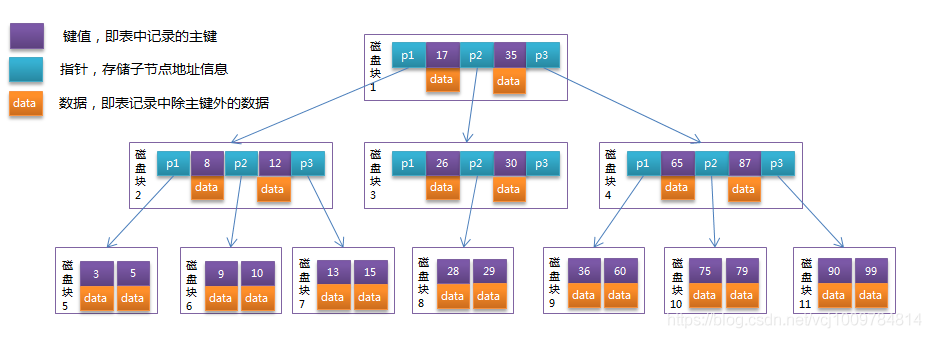
- ## B ツリー: B ツリーは、B ツリー最適化に基づくタイプです。 B ツリーとの主な違いは、B ツリーのすべてのデータがリーフ ノードに格納され、リーフ ノードがリンク リストによって結合されていることです。次の図は B ツリーです。
#InnoDB のページのサイズは 16 KB (ページは B ツリー上のノードです)テーブルの主キーが INT で、サイズが 4 バイトの場合、そのノードは 4K のキー値も格納できます。ポインターとキー値の両方が同じサイズを占めると仮定すると、高さ 3 の B ツリーは次のようになります。第 2 層には 2048 ノード、第 3 層には 2048 ノードがあり、層内のリーフ ノードの数は 2048*2048 = 4194304 で、1 つのノードは 16KB なので、合計 67108864KB、つまり 65536MB、つまり 64G のデータを格納できます。収容されました。 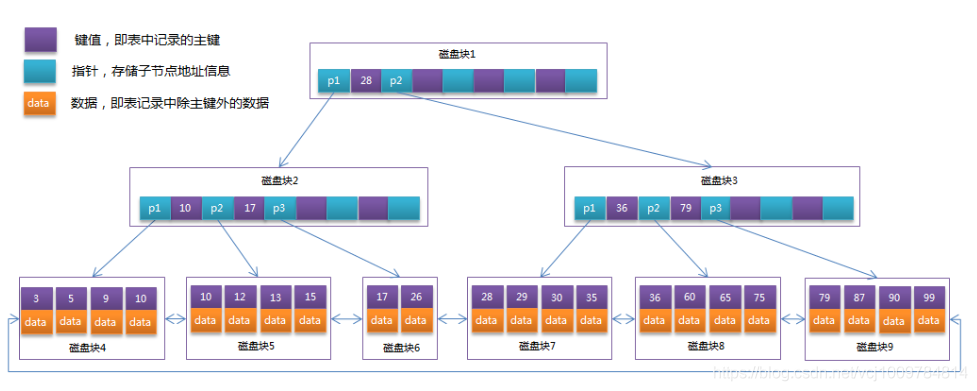
- MyISAM インデックスとデータは別々に保存されます。 MyISAM の主キー インデックスでは、レコード アドレスが B ツリーのリーフ ノードに格納されるため、MyISAM はインデックス クエリを介して 2 回の IO を実行する必要があります。
- ##MyISAM の補助インデックスは主キー インデックスと同じです。唯一の違いは、補助インデックスのキーは繰り返すことができますが、主キー インデックスのキーは繰り返すことができないことです。
InnoDB インデックス
InnoDB の主キー インデックスでは、データはすでにリーフ ノードに含まれています。つまり、インデックスとデータが一緒に格納されており、これがクラスター化インデックスです。 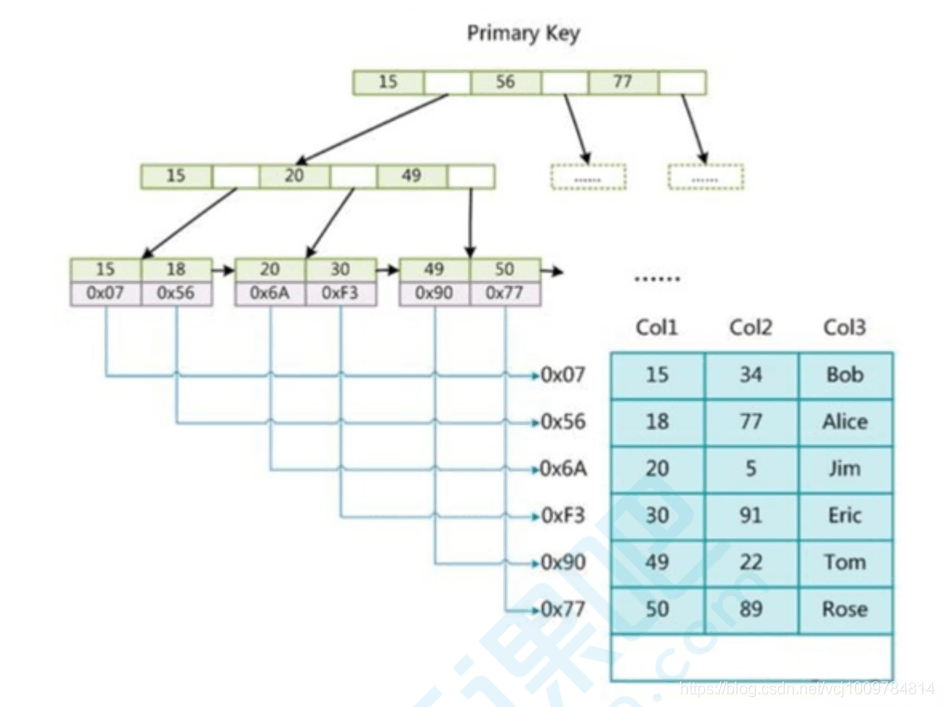
InnoDB の補助インデックスでは、主キーの値はアドレスではなくリーフ ノードに格納されます。補助インデックスを使用するには、2 つの検索が必要です。
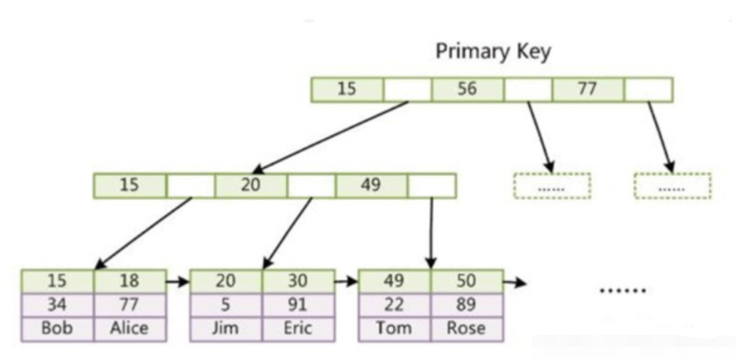
InnoDB はクラスター化インデックスを使用し、その主キー インデックスはデータを直接保存します。リーフ ノード。補助インデックス内のリーフ ノードには、主キーの値が格納されます。
- 質問 :
主キーが長すぎると、補助インデックスが多くのスペースを占有することになります
- InnoDB で自動インクリメント主キーの使用が推奨される理由
? 自動インクリメント主キーを使用する場合、新しいレコードが挿入されるたびに、新しいレコードは現在のインデックス ノードの後続の位置に順次追加されます。1 つのページがいっぱいになると、新しいページが開きますそのため、インデックス構造は非常にコンパクトであり、既存のデータを挿入するたびに移動する必要がなく、非常に効率的です。自動インクリメント主キーを使用しない場合、新しいレコードを挿入するたびに挿入位置を選択する必要があり、データの移動が必要になる場合があるため、効率が高くなく、インデックス構造もコンパクトになりません
- B ツリーではなく B ツリーを使用する理由
インデックスはどこに存在するのでしょうか? インデックス自体も比較的大きく、通常はディスクに保存されます。インデックスとデータは別々に保存される場合もあり (MyISAM の非クラスター化インデックス)、一緒に保存される場合もあります (InnoDB の場合)。クラスター化インデックス)
- #利点
- 並べ替えコストの削減 (インデックス付き列は自動的に並べ替えられ、order by を使用すると効率が大幅に向上します)
- 欠点
- #インデックスは追加の記憶領域を占有します
- インデックスはテーブル データの更新効率を低下させます。操作を追加、削除、または変更する場合は、データを保存するだけでなく、対応するインデックスも更新する必要があります
- ##主キー インデックス
#一意のインデックス
通常のインデックス
- 複合インデックス
インデックスは
CREATE INDEX index_name ON table_name(col_name); -- 或者 ALTER TABLE table_name ADD INDEX index_name(col_name)
ログイン後にコピーインデックスの削除DROP INDEX index_name ON table_name;
ログイン後にコピー#インデックス作成が必要なシナリオ#頻繁にクエリ条件として使用される列にはインデックスを付ける必要があります
- クエリの並べ替えフィールドにはインデックスを作成する必要がありますインデックスの構築
- インデックス作成が適さないシナリオ
- 書き込みが多く読み取りが少ないテーブルはインデックス作成には適していません
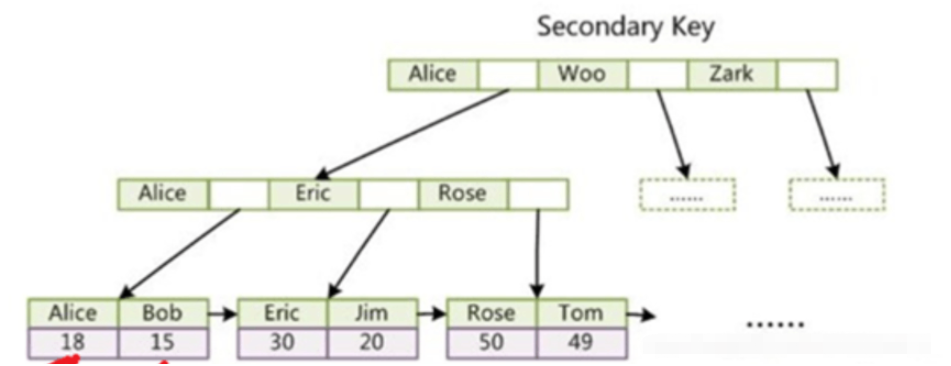
- #実行計画の説明
- ##既存のユーザー テーブルがあり、そのインデックスは次のとおりです。
MySQL 5.6.x 以降では、チェック条件をストレージ エンジン層にプッシュできる ICP 機能 (インデックス条件プッシュダウン) がサポートされています。条件を満たさないレコードは、 SQL レイヤーのレイヤー フィルタリングにより、ストレージ エンジン レイヤーによってスキャンされる行数が削減されます。
インデックス条件の使用filesort を使用する
は並べ替えできません 使用されるインデックス##type
- #次は、満たされる左端のプレフィックス ルールです。つまり、idx_name_age_add の場合、左端のプレフィックスは満たされ、最初のインデックスは name
- range: インデックス範囲スキャン、>、<、between、in、like およびその他のクエリで共通
- ##このような場合、ワイルドカード文字 % を先頭に置くことはできないことに注意してください。そうしないとテーブル全体のスキャンが発生します。
#単一列インデックス
を使用してインデックスを作成します
- #複数テーブルの関連付けでは、関連付けられたフィールドにインデックスを付ける必要があります
- 頻繁に更新されるフィールドはインデックスの構築には適していません
Explain を使用して、特定の SQL ステートメントのパフォーマンス分析を実行できます
explain select * from user where name = 'am';

使用される可能性のあるインデックスkey
 実際に使用されるインデックス
実際に使用されるインデックス
key_lenクエリに使用されるインデックスの長さ
ref 同等のクエリの場合、const
rowsスキャンされる推定行数 (正確な値ではありません)
extra
using where
などの追加情報は、ストレージ エンジンから返された結果が SQL 層レイヤーでもフィルタリングされる必要があることを示します
usingindex
は、テーブルにクエリを戻す必要がないことを示します。通常、この値はカバー インデックスを使用する場合に当てはまります。インデックスをカバーするとは、選択内の列がすべてインデックス列であることを意味します。テーブルに返す必要のないクエリは、補助インデックスを経由してインデックス列の値を直接取得できることを意味し、レコードをフェッチするために主キー インデックスに移動する必要はありません
- const: 一意のインデックスまたは主キー インデックスを使用し、where およびその他の値を使用してクエリを実行します返されるレコードは 1 行であり、一意のインデックス スキャンとも呼ばれます
##ref: 一意でないインデックスの場合、同等の where 条件または左端のプレフィックス ルールを使用したクエリ。




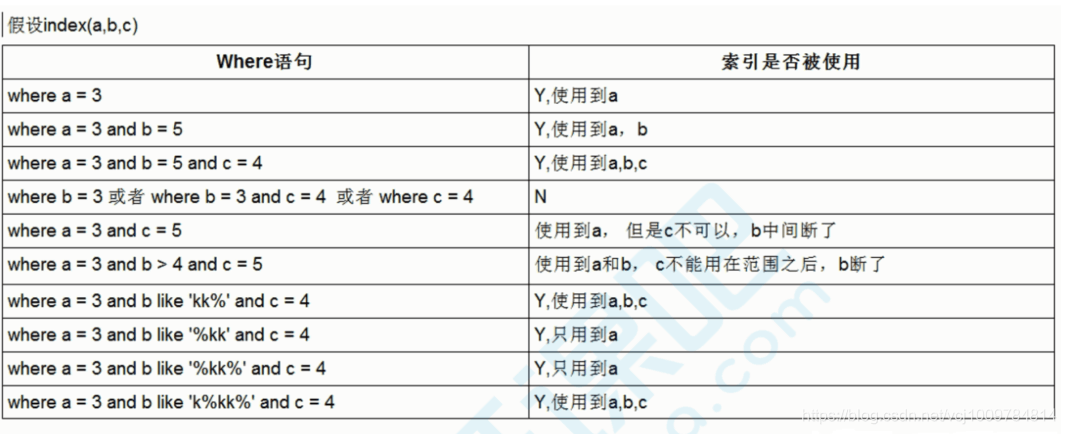
索引使用规范(索引失效分析)
全值匹配
在索引列上使用等值查询
explain select * from user where name = 'y' and age = 15;

2. 最左前缀
组合索引中,查询条件要从组合索引的最左列开始,如上述example中组合索引idx_name_age_add,是建立在三个列name,age,address的,若跳过name,直接用age查询,则会变为全表扫描
explain select * from user where age = 15;

3. 不要在索引列上做计算
4. 范围条件右侧的索引列会失效
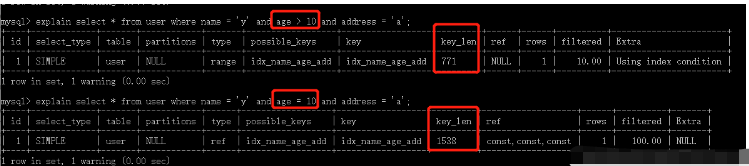
看到第一个SQL语句,没有用上addresss索引
5. 尽量使用覆盖索引
explain select name,age from user where name = 'y' and age = 1;
可以避免回表查询
6. 索引字段不要使用不等(!= 或 ),不要判断null(is null/ is not null)
会导致索引失效,转为全表扫描


7. 索引字段上使用like时,不要以%开头

8. 索引字段如果是字符串,记得加单引号
9. 索引字段不要用or

例子总结:
以上がMySQL のインデックス作成と最適化に関する知識ポイントは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7666
7666
 15
1393
52
1205
24
91
11
15
1393
52
1205
24
91
11

 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。
 DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerでMySQLを起動するプロセスは、次の手順で構成されています。MySQLイメージをプルしてコンテナを作成および起動し、ルートユーザーパスワードを設定し、ポート検証接続をマップしてデータベースを作成し、ユーザーはすべての権限をデータベースに付与します。
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
