

LLaMAを粉砕する「Falcon」は完全にオープンソースです! 400億のパラメータ、数兆のトークントレーニング、Hugging Faceを支配

大型モデルの時代において、最も重要なことは何でしょうか?
LeCun がかつて与えた答えは、「オープンソース」です。
Meta の LLaMA のコードが GitHub に漏洩すると、世界中の開発者がそれにアクセスできるようになりました。 GPTレベルに達します。
次に、さまざまな LLM が AI モデルのオープンソースにさまざまな角度を与えます。
LLaMA は、スタンフォード大学の Alpac や Vicuna などのモデルへの道を切り開き、それらのモデルをオープンソースのリーダーにしました。
この瞬間、ファルコン「ファルコン」が再び包囲を突破した。
Falcon Falcon
「Falcon」は、アラブ首長国連邦、アブダビの Technology Innovation Institute (TII) によって開発されました。パフォーマンスの点では、Falcon の方が優れています。 LLaMAいいですね。
現在、「Falcon」には 1B、7B、40B の 3 つのバージョンがあります。
TII は、Falcon はこれまでで最も強力なオープンソース言語モデルであると述べました。その最大のバージョンである Falcon 40B には 400 億のパラメータがありますが、それでも 650 億のパラメータを持つ LLaMA よりも規模が若干小さいです。
規模は小さいですが、性能は高いです。
先進技術研究評議会 (ATRC) の事務局長であるファイサル・アル・バンナイ氏は、「ファルコン」のリリースにより LLM 取得の道が開かれ、研究者や起業家が提案できるようになると考えています。最良のソリューション、最も革新的な使用例。
FalconLM の 2 つのバージョン、Falcon 40B Instruct と Falcon 40B は、Hugging Face OpenLLM ランキングで上位 2 位にランクされ、Meta の LLaMA は 3 位にランクされています。
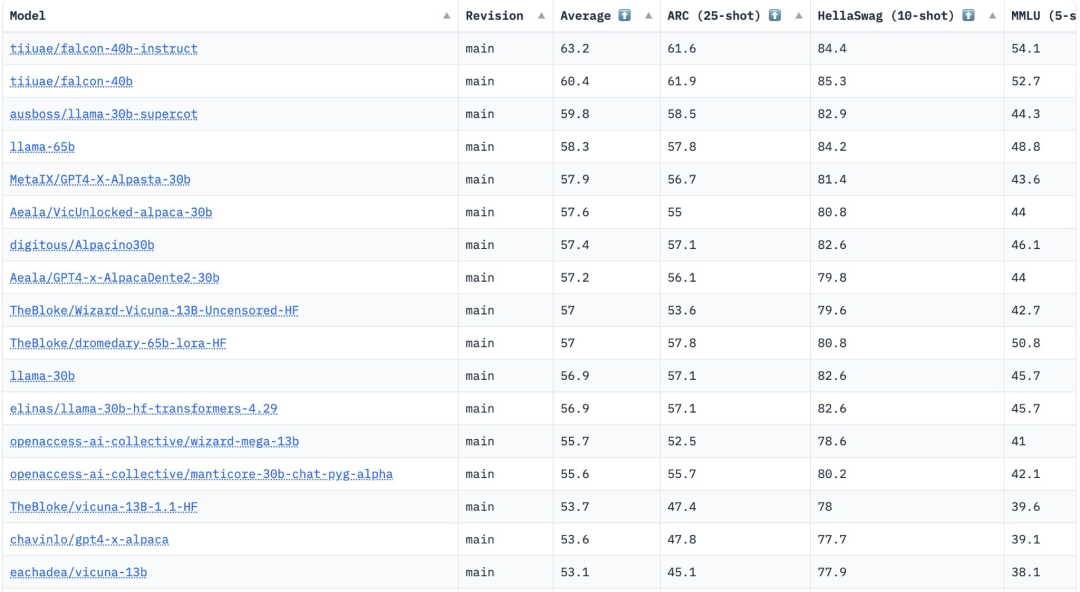
Hugging Face が、多様体を比較するための 4 つの現在のベンチマーク (AI2 Reasoning Challenge、HellaSwag、MMLU、およびTruthfulQA は、これらのモデルを評価するために使用されます。
「Falcon」論文はまだ公開されていませんが、Falcon 40B は慎重に選別された 1 兆のトークン ネットワーク データセットで広範囲にトレーニングされています。
研究者らは、「Falcon」がトレーニングプロセス中に大規模なデータで高いパフォーマンスを達成することの重要性を非常に重視していることを明らかにしました。
誰もが知っていることは、LLM はトレーニング データの品質に非常に敏感であるということです。そのため、研究者は、数万のデータに対して効率的な処理を実行できるデータの構築に多大な労力を費やしています。 CPU コアのデータ パイプライン。
目的は、フィルタリングと重複排除に基づいてインターネットから高品質のコンテンツを抽出することです。
現在、TII は、慎重にフィルタリングされ重複排除されたデータ セットである、洗練されたネットワーク データ セットをリリースしました。実践すると、それが非常に効果的であることが証明されました。
このデータセットのみを使用してトレーニングされたモデルは、パフォーマンスにおいて他の LLM と同等か、それを上回る可能性があります。これは「ファルコン」の優れた品質と影響力を示しています。

さらに、Falcon モデルには多言語機能もあります。
英語、ドイツ語、スペイン語、フランス語、そしてオランダ語、イタリア語、ルーマニア語、ポルトガル語、チェコ語、ポーランド語、スウェーデン語などのいくつかのヨーロッパの小さな言語も理解できます。それ。
Falcon 40B は、H2O.ai モデルのリリースに続く 2 番目の真のオープンソース モデルです。ただし、H2O.ai はこのランキングの他のモデルに対してベンチマークされていないため、これら 2 つのモデルはまだリングに上がっていません。
LLaMA を振り返ると、そのコードは GitHub で入手できますが、その重みはオープンソース化されていませんでした。
これは、このモデルの商用利用には一定の制限があることを意味します。
さらに、LLaMA のすべてのバージョンは元の LLaMA ライセンスに依存しているため、LLaMA は小規模な商用アプリケーションには適していません。
この時点で、「Falcon」が再びトップに浮上します。
唯一の無料商用モデル!
Falcon は現在、商用で無料で使用できる唯一のオープンソース モデルです。
TII は当初、Falcon が商業目的で使用され、帰属所得が 100 万ドルを超える場合、10% の「使用税」を課すことを要求していました。
しかし、中東の裕福な実業家たちがこの制限を解除するのに時間はかかりませんでした。
少なくとも今のところ、Falcon の商用利用と微調整はすべて無料です。
富裕層は、当面このモデルでお金を稼ぐ必要はないと言っています。
また、TIIでは世界各国から事業化プランを募集しております。
潜在的な科学研究および商業化ソリューションについては、さらに多くの「トレーニング コンピューティング能力サポート」を提供したり、さらなる商業化の機会を提供したりする予定です。

プロジェクト提出メール: Submissions.falconllm@tii.ae
これは単に、プロジェクトが優れている限り、モデルは無料だと言っているだけです。十分な計算能力!お金が足りない場合でも、私たちがお金を集めることができます!
スタートアップ企業にとって、これは中東の大物企業による「AI 大規模モデル起業家精神のためのワンストップ ソリューション」にすぎません。
高品質のトレーニング データ開発チームによると、FalconLM の競争上の優位性の重要な側面はトレーニング データの選択です。
研究チームは、クロールされた公開データセットから高品質のデータを抽出し、重複データを削除するプロセスを開発しました。
冗長で重複したコンテンツを徹底的に除去した結果、強力な言語モデルをトレーニングするのに十分な 5 兆個のトークンが保持されました。
40B Falcon LM はトレーニングに 1 兆トークンを使用し、モデルの 7B バージョンはトレーニングに 1.5 兆トークンを使用します。
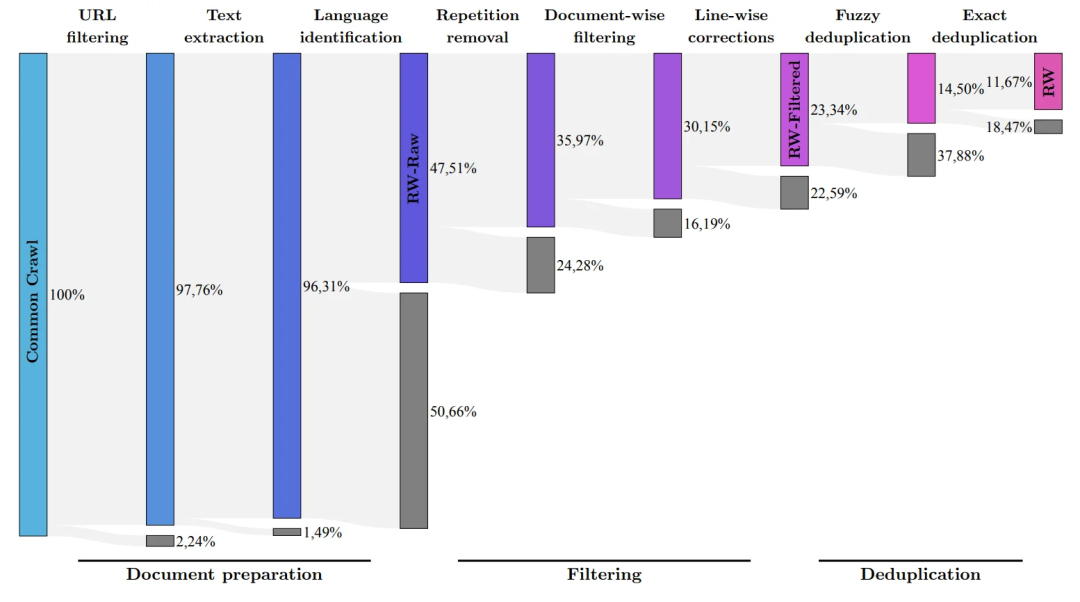
(研究チームは、RefinedWeb データセットを使用して、共通クロールから最高品質の生データのみをフィルタリングすることを目指しています)
より制御可能なトレーニング コストTII は、GPT-3 と比較して、Falcon は大幅なパフォーマンス向上を達成したと述べました。
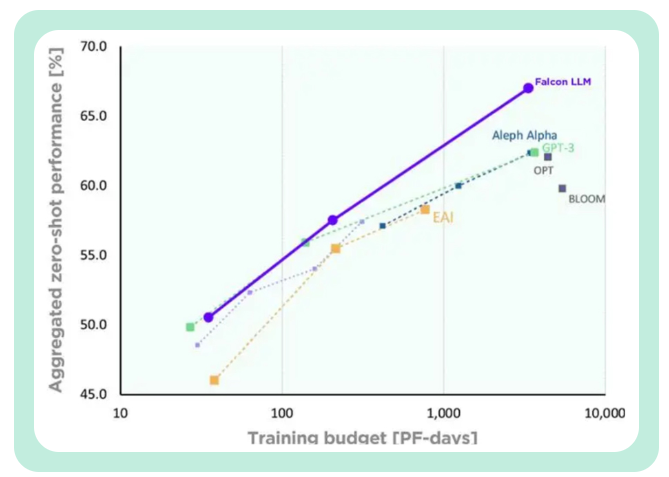
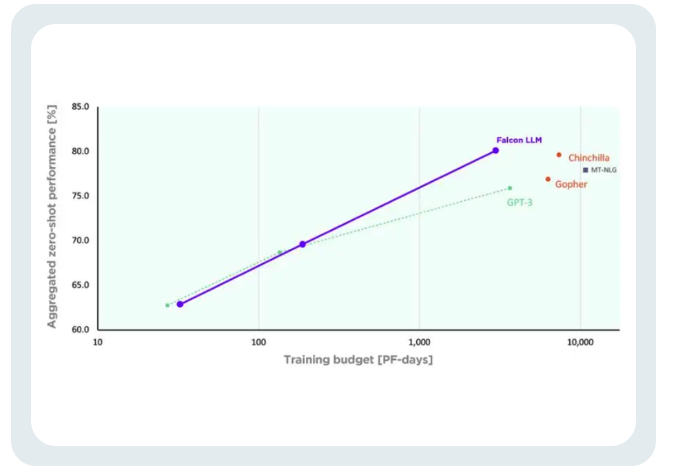
ファルコンの訓練コストは、チンチラの 40%、PaLM-62B の 80% にすぎません。 コンピューティング リソースの効率的な利用を実現しました。
以上がLLaMAを粉砕する「Falcon」は完全にオープンソースです! 400億のパラメータ、数兆のトークントレーニング、Hugging Faceを支配の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7563
7563
 15
1385
52
84
11
28
99
15
1385
52
84
11
28
99

 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 Centosでgitlabログを表示する方法
Apr 14, 2025 pm 06:18 PM
Centosでgitlabログを表示する方法
Apr 14, 2025 pm 06:18 PM
CENTOSシステムでGitLabログを表示するための完全なガイドこの記事では、メインログ、例外ログ、その他の関連ログなど、CentosシステムでさまざまなGitLabログを表示する方法をガイドします。ログファイルパスは、gitlabバージョンとインストール方法によって異なる場合があることに注意してください。次のパスが存在しない場合は、gitlabインストールディレクトリと構成ファイルを確認してください。 1.メインGitLabログの表示
 CentosでPytorchバージョンを選択する方法
Apr 14, 2025 pm 06:51 PM
CentosでPytorchバージョンを選択する方法
Apr 14, 2025 pm 06:51 PM
PytorchをCentosシステムにインストールする場合、適切なバージョンを慎重に選択し、次の重要な要因を検討する必要があります。1。システム環境互換性:オペレーティングシステム:Centos7以上を使用することをお勧めします。 Cuda and Cudnn:PytorchバージョンとCudaバージョンは密接に関連しています。たとえば、pytorch1.9.0にはcuda11.1が必要ですが、pytorch2.0.1にはcuda11.3が必要です。 CUDNNバージョンは、CUDAバージョンとも一致する必要があります。 Pytorchバージョンを選択する前に、互換性のあるCUDAおよびCUDNNバージョンがインストールされていることを確認してください。 Pythonバージョン:Pytorch公式支店
