

MySQL で join ステートメントを最適化する方法

単純なネストループ結合
結合操作を実行するときに mysql がどのように動作するかを見てみましょう。一般的な結合方法は何ですか?
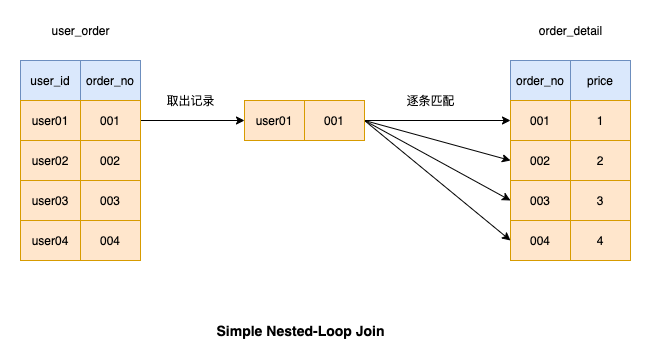
図に示すように、接続操作を実行すると、左側のテーブルは ドライバー テーブル、右側のテーブルは駆動テーブル
単純なネストループ結合 この結合操作は、駆動テーブルからレコードを取得し、駆動テーブルのレコードを 1 つずつ照合することです。条件が一致する場合、結果が返されます。次に、ドライバー テーブル内のすべてのデータが一致するまで、ドライバー テーブル内の次のレコードの照合を続けます。
毎回ドライバー テーブルからデータをフェッチするのは時間がかかるため、MySQL はこのアルゴリズムは使用しないでください。 結合操作を実行するには
Block Nested-Loop Join
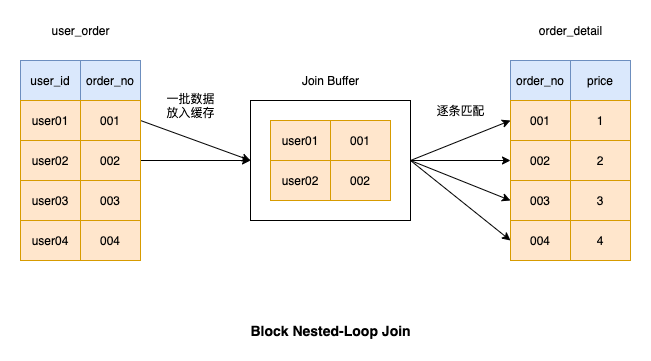
時間のかかるデータの取得を避けるため、ドライバー テーブルのバッチを追加するたびに、データがドライバー テーブルから一度に取得され、メモリ内で照合されます。このデータのバッチが一致すると、ドライバー テーブル内のすべてのデータが一致するまで、データのバッチがドライバー テーブルからフェッチされ、メモリに配置されます。
バッチ データの取得により、多くの IO 操作が削減されます。 , そのため、実行効率が比較的高いです. この種の接続操作は MySQL でも使用されます
ちなみに、このメモリには MySQ では結合バッファと呼ばれる正式な名前があります. 次のステートメントを実行して表示できます結合バッファのサイズ
show variables like '%join_buffer%'

前に使用したsingle_tableテーブルを移動し、single_tableテーブルに基づいて2つのテーブルを作成し、各テーブルに1wのランダムなレコードを挿入します
CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
create table t1 like single_table;
create table t2 like single_table;join ステートメントを直接使用する場合、MySQL の最適化サーバーは駆動テーブルとしてテーブル t1 または t2 を選択する可能性があり、これは SQL ステートメントの分析プロセスに影響を与えるため、mysql に固定接続方法を使用させるために、straight_join を使用します。クエリを実行するには
select * from t1 straight_join t2 on (t1.common_field = t2.common_field)
実行時間は0.035秒です

実行計画は次のとおりです

「結合バッファーの使用」が「追加」列に表示されます。これは、接続操作が Block Nested -Loop Join アルゴリズム
Index Nested-Loop Join
に基づいていることを示しています。 Block Nested-Loop Join アルゴリズムを理解すると、ドライバー テーブルの各レコードがドリブン テーブルのすべてのレコードと一致するのに非常に時間がかかることがわかります。改善されるでしょうか?
あなたもこのアルゴリズムを考えたことがあると思います。このアルゴリズムは、図に示すように、駆動テーブルによって接続された列にインデックスを追加することで、一致プロセスが非常に高速になります。
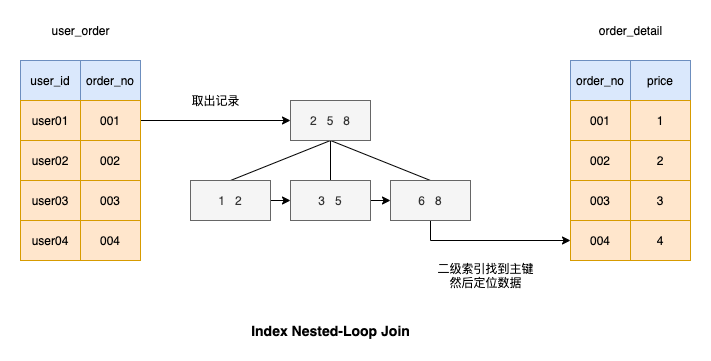 インデックス列に基づく結合に基づくクエリの実行速度を見てみましょう。
インデックス列に基づく結合に基づくクエリの実行速度を見てみましょう。
select * from t1 straight_join t2 on (t1.id = t2.id)
実行時間は0.001秒で、通常の列ベースで接続するよりも1段以上速いことがわかります。
 実行時間は0.001秒です。計画は次のとおりです
実行時間は0.001秒です。計画は次のとおりです

ドライバーテーブルはどのように選択すればよいですか?
結合の具体的な実装がわかったところで、よくある質問、つまりドライバー テーブルをどのように選択するかについて話しましょう。
ブロック ネスト ループ結合アルゴリズムの場合:
- 結合バッファーが十分に大きい場合、誰が駆動するかは問題ではありません。 table
- 結合バッファーが十分に大きくない場合は、小さなテーブルを駆動テーブルとして選択する必要があります (小さなテーブルにはデータが少なく、結合に入れられる回数も少なくなります)バッファが小さいため、テーブルのスキャン数が減少します)
次のように仮定します。ドライバー テーブルの行数は M なので、ドライバー テーブルの M 行をスキャンする必要があります。
毎回、駆動テーブルからデータの行を取得するときは、最初にインデックス a を検索する必要があります。そして主キーインデックスを検索します。駆動テーブルの行数は N です。毎回ツリーを検索するおおよその複雑さは底 2 N の対数であるため、駆動テーブル上の行を検索する時間計算量は 2\l o g 2 N 2*log2^N 2\log2N
Each となります。ドライバー テーブル内のデータ行は、駆動テーブルで 1 回検索する必要があります。実行プロセス全体のおおよその複雑さは、M M∗ 2∗ l o g 2 N M M*2*log2^N M M∗2∗log2N
## です。#明らかに M はスキャンされる行数に大きな影響を与えるため、小さなテーブルを駆動テーブルとして使用する必要があります。もちろん、この結論の前提は、駆動テーブルのインデックスが使用できることです。
つまり、小さなテーブルを駆動テーブルにするだけで済みます。
結合ステートメントの実行が遅い場合は、次の方法で最適化できます
- #接続操作を実行する場合、駆動テーブルのインデックスを使用できます ##小さなテーブルは駆動テーブルとして使用されます
- 結合バッファのサイズを増やします
- * をクエリ リストとして使用せず、必要な列のみを返します
以上がMySQL で join ステートメントを最適化する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7504
7504
 15
1378
52
78
11
19
54
15
1378
52
78
11
19
54

 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
 NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する手順:データベースに接続します。 SQLエディターウィンドウを作成します。 SQLクエリまたはスクリプトを書きます。 [実行]ボタンをクリックして、クエリまたはスクリプトを実行します。結果を表示します(クエリが実行された場合)。
 Navicatは、データベースエラーコードとソリューションに接続します
Apr 08, 2025 pm 11:06 PM
Navicatは、データベースエラーコードとソリューションに接続します
Apr 08, 2025 pm 11:06 PM
データベースに接続するときの一般的なエラーとソリューション:ユーザー名またはパスワード(エラー1045)ファイアウォールブロック接続(エラー2003)接続タイムアウト(エラー10060)ソケット接続を使用できません(エラー1042)SSL接続エラー(エラー10055)接続の試みが多すぎると、ホストがブロックされます(エラー1129)データベースは存在しません(エラー1049)
