

Python 機械学習でカテゴリ特徴を処理する方法は何ですか?

カテゴリ特徴とは、職業や血液型など、有限のカテゴリのセット内に収まる値を持つ特徴を指します。元の入力は通常文字列の形式です。ほとんどのアルゴリズム モデルは数値特徴の入力を受け入れません。数値カテゴリ特徴は数値特徴として扱われるため、トレーニングされたモデルでエラーが発生します。
ラベル エンコーディング
ラベル エンコーディングは、辞書を使用して各カテゴリ ラベルを増加する整数に関連付けます。つまり、クラス Index という名前のファイルをインスタンスに生成します。 _ の配列。
Scikit-learn の LabelEncoder は、カテゴリ特徴量のエンコード、つまり不連続な値またはテキストのエンコードに使用されます。これには、次の一般的なメソッドが含まれています。
fit(y): fit は空の辞書と見なすことができ、y は辞書に挿入される単語と見なすことができます。
fit_transform(y): これは、最初に fit を実行してから変換を実行することと同じです。つまり、y を辞書に詰め込んでから、インデックス値を取得するために変換します。
inverse_transform(y): インデックス値 y に基づいて元のデータを取得します。
transform(y): y をインデックス値に変換します。
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() city_list = ["paris", "paris", "tokyo", "amsterdam"] le.fit(city_list) print(le.classes_) # 输出为:['amsterdam' 'paris' 'tokyo'] city_list_le = le.transform(city_list) # 进行Encode print(city_list_le) # 输出为:[1 1 2 0] city_list_new = le.inverse_transform(city_list_le) # 进行decode print(city_list_new) # 输出为:['paris' 'paris' 'tokyo' 'amsterdam']
複数列データ エンコーディング メソッド:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
df = pd.DataFrame({
'pets': ['cat', 'dog', 'cat', 'monkey', 'dog', 'dog'],
'owner': ['Champ', 'Ron', 'Brick', 'Champ', 'Veronica', 'Ron'],
'location': ['San_Diego', 'New_York', 'New_York', 'San_Diego', 'San_Diego',
'New_York']
})
d = {}
le = LabelEncoder()
cols_to_encode = ['pets', 'owner', 'location']
for col in cols_to_encode:
df_train[col] = le.fit_transform(df_train[col])
d[col] = le.classes_Pandas のactorize() は、系列内の名目データ マッピングを一連の数値として呼び出すことができます。タイプは同じ番号にマップされます。関数actorizeは、2つの要素を含むタプルを返します。最初の要素は配列であり、その要素は公称要素がマップされる番号です。2 番目の要素はインデックス タイプで、要素はすべて重複のない公称要素です。
import numpy as np import pandas as pd df = pd.DataFrame(['green','bule','red','bule','green'],columns=['color']) pd.factorize(df['color']) #(array([0, 1, 2, 1, 0], dtype=int64),Index(['green', 'bule', 'red'], dtype='object')) pd.factorize(df['color'])[0] #array([0, 1, 2, 1, 0], dtype=int64) pd.factorize(df['color'])[1] #Index(['green', 'bule', 'red'], dtype='object')
ラベル エンコーディングはテキストを数値に変換するだけで、テキストの特徴の問題は解決しません。すべてのラベルは数値になり、アルゴリズム モデルはラベルに関係なく、距離に基づいて同様の数値を直接考慮します。 . 具体的な意味。この方法で処理されたデータは、LightGBM などのカテゴリ属性をサポートするアルゴリズム モデルに適用できます。
シーケンス エンコーディング (順序エンコーディング)
順序エンコーディングは最も単純なアイデアであり、m 個のカテゴリを持つ特徴の場合、[0,m-1 ] が整数であることに対応してマッピングします。もちろん、順序エンコーディングは順序特徴により適しています。つまり、各特徴には固有の順序があります。たとえば、「教育」、「学士」、「修士」、「博士」などのカテゴリは、本質的にそのような論理順序が含まれているため、[0,2] として自然にエンコードできます。しかし、「色」のようなカテゴリーの場合、「青」、「緑」、「赤」をそれぞれ [0,2] にエンコードするのは不合理です。なぜなら、「青」と「緑」のギャップを考える理由がないからです。 「青」と「赤」の間では、機能に対する影響が異なります。
ord_map = {'Gen 1': 1, 'Gen 2': 2, 'Gen 3': 3, 'Gen 4': 4, 'Gen 5': 5, 'Gen 6': 6}
df['GenerationLabel'] = df['Generation'].map(gord_map)ワンホット エンコーディング
実際の機械学習アプリケーション タスクでは、特徴は必ずしも連続値であるとは限らず、性別が男性と女性に分けられるなどのカテゴリ値である場合があります。機械学習タスクでは、このような特徴については、通常、デジタル化する必要があります。たとえば、次の 3 つの特徴属性があります:
- ##性別: ["男性", "女性" ]
- 地域: ["ヨーロッパ"、"米国"、"アジア"]
- ブラウザ: ["Firefox"、"Chrome "," Safari","Internet Explorer"]
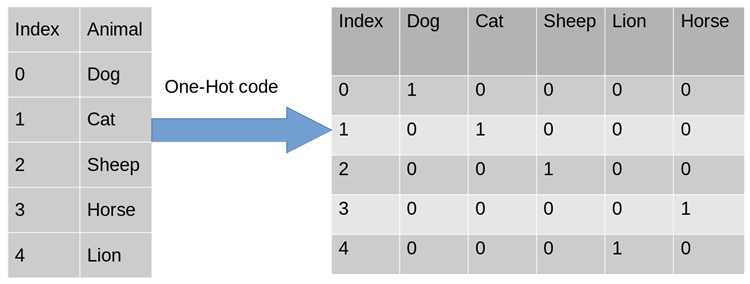
#One-Hot Encoding を使用できるのはなぜですか?
使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,也是基于的欧式空间。
使用One-Hot编码对离散型特征进行处理可以使得特征之间的距离计算更加准确。比如,有一个离散型特征,代表工作类型,该离散型特征,共有三个取值,不使用one-hot编码,计算出来的特征的距离是不合理。那如果使用one-hot编码,显得更合理。
独热编码优缺点
优点:独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
缺点:当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA(主成分分析)来减少维度。在实际应用中,One-Hot Encoding与PCA结合的方法也非常实用。
One-Hot Encoding的使用场景
独热编码用来解决类别型数据的离散值问题。将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码,比如,该离散特征共有1000个取值,我们分成两组,分别是400和600,两个小组之间的距离有合适的定义,组内的距离也有合适的定义,那就没必要用one-hot 编码。
树结构方法,如随机森林、Bagging和Boosting等,在特征处理方面不需要进行标准化操作。对于决策树来说,one-hot的本质是增加树的深度,决策树是没有特征大小的概念的,只有特征处于他分布的哪一部分的概念。
基于Scikit-learn 的one hot encoding
LabelBinarizer:将对应的数据转换为二进制型,类似于onehot编码,这里有几点不同:
可以处理数值型和类别型数据
输入必须为1D数组
可以自己设置正类和父类的表示方式
from sklearn.preprocessing import LabelBinarizer lb = LabelBinarizer() city_list = ["paris", "paris", "tokyo", "amsterdam"] lb.fit(city_list) print(lb.classes_) # 输出为:['amsterdam' 'paris' 'tokyo'] city_list_le = lb.transform(city_list) # 进行Encode print(city_list_le) # 输出为: # [[0 1 0] # [0 1 0] # [0 0 1] # [1 0 0]] city_list_new = lb.inverse_transform(city_list_le) # 进行decode print(city_list_new) # 输出为:['paris' 'paris' 'tokyo' 'amsterdam']
OneHotEncoder只能对数值型数据进行处理,需要先将文本转化为数值(Label encoding)后才能使用,只接受2D数组:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
def LabelOneHotEncoder(data, categorical_features):
d_num = np.array([])
for f in data.columns:
if f in categorical_features:
le, ohe = LabelEncoder(), OneHotEncoder()
data[f] = le.fit_transform(data[f])
if len(d_num) == 0:
d_num = np.array(ohe.fit_transform(data[[f]]))
else:
d_num = np.hstack((d_num, ohe.fit_transform(data[[f]]).A))
else:
if len(d_num) == 0:
d_num = np.array(data[[f]])
else:
d_num = np.hstack((d_num, data[[f]]))
return d_num
df = pd.DataFrame([
['green', 'Chevrolet', 2017],
['blue', 'BMW', 2015],
['yellow', 'Lexus', 2018],
])
df.columns = ['color', 'make', 'year']
df_new = LabelOneHotEncoder(df, ['color', 'make', 'year'])基于Pandas的one hot encoding
其实如果我们跳出 scikit-learn, 在 pandas 中可以很好地解决这个问题,用 pandas 自带的get_dummies函数即可
import pandas as pd
df = pd.DataFrame([
['green', 'Chevrolet', 2017],
['blue', 'BMW', 2015],
['yellow', 'Lexus', 2018],
])
df.columns = ['color', 'make', 'year']
df_processed = pd.get_dummies(df, prefix_sep="_", columns=df.columns[:-1])
print(df_processed)get_dummies的优势在于:
本身就是 pandas 的模块,所以对 DataFrame 类型兼容很好
不管你列是数值型还是字符串型,都可以进行二值化编码
能够根据指令,自动生成二值化编码后的变量名
get_dummies虽然有这么多优点,但毕竟不是 sklearn 里的transformer类型,所以得到的结果得手动输入到 sklearn 里的相应模块,也无法像 sklearn 的transformer一样可以输入到pipeline中进行流程化地机器学习过程。
频数编码(Frequency Encoding/Count Encoding)
将类别特征替换为训练集中的计数(一般是根据训练集来进行计数,属于统计编码的一种,统计编码,就是用类别的统计特征来代替原始类别,比如类别A在训练集中出现了100次则编码为100)。这个方法对离群值很敏感,所以结果可以归一化或者转换一下(例如使用对数变换)。未知类别可以替换为1。
频数编码使用频次替换类别。有些变量的频次可能是一样的,这将导致碰撞。尽管可能性不是非常大,没法说这是否会导致模型退化,不过原则上我们不希望出现这种情况。
import pandas as pd
data_count = data.groupby('城市')['城市'].agg({'频数':'size'}).reset_index()
data = pd.merge(data, data_count, on = '城市', how = 'left')目标编码(Target Encoding/Mean Encoding)
目标编码(target encoding),亦称均值编码(mean encoding)、似然编码(likelihood encoding)、效应编码(impact encoding),是一种能够对高基数(high cardinality)自变量进行编码的方法 (Micci-Barreca 2001) 。
如果某一个特征是定性的(categorical),而这个特征的可能值非常多(高基数),那么目标编码(Target encoding)是一种高效的编码方式。在实际应用中,这类特征工程能极大提升模型的性能。
一般情况下,针对定性特征,我们只需要使用sklearn的OneHotEncoder或LabelEncoder进行编码。
LabelEncoder は不規則な特徴列を受け取り、0 から n-1 までの整数値に変換できます (合計 n 個の異なるカテゴリがあると仮定します); OneHotEncoder はダミー エンコーディングを通じて m*n を生成できます スパース行列 (存在すると仮定します)合計 m 行のデータである場合、特定の出力行列形式がスパースであるかどうかは、sparse パラメーターによって制御できます。
定性的特性の「カーディナリティ」とは、その特性が取り得る個別の可能な値の総数を指します。カーディナリティの高い定性的特性に直面して、これらのデータ前処理方法では満足のいく結果が得られないことがよくあります。
高基数の定性的特徴の例: IP アドレス、電子メール ドメイン名、都市名、自宅の住所、番地、製品番号。
主な理由:
LabelEncoder はカーディナリティの高い定性的特徴をエンコードします。必要な列は 1 つだけですが、各自然数は異なる意味を持ちます。 y に関して切り離せない。単純なモデルを使用するとアンダーフィッティングになる傾向があり、異なるカテゴリ間の差異を完全に捉えることができません。複雑なモデルを使用すると、他の場所でオーバーフィッティングになる傾向があります。
OneHotEncoder はカーディナリティの高い定性的特徴をエンコードするため、必然的に数万列の疎行列が生成され、アルゴリズム自体を使用しない限り、大量のメモリとトレーニング時間を容易に消費します。関連する最適化が行われています (例: SVM)。
特定のカテゴリ特徴量のカーディナリティが比較的低い場合 (低カーディナリティ特徴量)、つまり、次の特徴量のすべての値で構成されるセット内の要素の数が低い場合重複排除は比較的小規模で、通常は One-Hot Encoding メソッドを使用して特徴を数値型に変換します。ワンホット エンコーディングは、データの前処理中またはモデルのトレーニング中に完了できます。トレーニング時間の観点からは、後者の方法がより効率的です。CatBoost は、カーディナリティの低いカテゴリ特徴量にも後者の方法を使用します。
明らかに、ユーザー ID などのカーディナリティの高い機能の中で、このエンコード方法は多数の新しい機能を生成し、次元の惨事を引き起こします。妥協の方法は、カテゴリを限られた数のグループにグループ化し、ワンホット エンコーディングを実行することです。一般的に使用される方法は、カテゴリごとに目的変数の期待値を推定するために使用される目的変数統計量 (Target Statistics、以下 TS と呼びます) に従ってグループ化することです。元のカテゴリ変数を置き換える新しい数値変数として TS を直接使用する人もいます。重要なのは、対数損失、ジニ係数、または平均二乗誤差に基づいて TS 数値特徴のしきい値を設定することにより、トレーニング セットのカテゴリを 2 つに分割するすべての可能な分割の中から最適な分割を取得できることです。 LightGBM では、カテゴリ特徴は、勾配ブースティングの各ステップで勾配統計 (GS) によって表されます。ツリー構築に重要な情報が得られますが、この方法には次の 2 つの欠点があります:
反復の各ステップで各カテゴリ特徴が必要になるため、計算時間が増加します。計算済み
ストレージ要件が増加します。カテゴリ変数の場合、各ノードのカテゴリを毎回分離して格納する必要があります
これらの欠点を克服するために、LightGBM は一部の情報を失うという代償を払って、すべてのロングテール カテゴリを 1 つのカテゴリに分類しますが、この方法はカーディナリティの高いカテゴリの特徴を処理する場合にワンホット エンコーディングよりもはるかに優れていると著者は主張しています。 TS 機能を使用すると、カテゴリごとに 1 つの数値のみが計算され、保存されます。したがって、カテゴリ特徴を処理するための新しい数値特徴として TS を使用することが最も効果的であり、情報損失を最小限に抑えることができます。 TS はクリック予測タスクでも広く使用されており、このシナリオのカテゴリ機能には、ユーザー、地域、広告、広告発行者などが含まれます。次の説明では、TS に焦点を当て、ワンホット エンコーディングと GS については今のところ脇に置きます。
以下は計算式です。
ここで、n は特定の特徴の値の数を表し、
は特定の特徴の値を表します。特定の特徴 低い数値は、正のラベルの数です。mdl は、最小しきい値です。この値より小さいサンプル番号を持つ特徴カテゴリは無視されます。Prior は、ラベルの平均値です。回帰問題を扱っている場合は、対応する特徴のラベル値の平均/最大値に処理できることに注意してください。 k 個の分類問題の場合、対応する k-1 個の特徴が生成されます。
この方法も過学習を引き起こしやすいので、過学習を防ぐために次の方法が使用されます。正規項 a
- トレーニング セットのこの列にノイズを追加します ##交差検証を使用します
- ##ターゲットのエンコーディングは監視されています コーディング方法は、適切に使用されれば、予測モデルの精度を効果的に向上させることができます (Pargent、Bischl、および Thomas 2019); そして、その鍵となるのは、コーディング プロセスに正則化を導入して過剰な処理を避けることです。 -フィッティングの問題。
- たとえば、カテゴリ A は、200 個のタグ 1、300 個のタグ 2、および 500 個のタグ 3 に対応します。これは、2/10、3/10、3/6 のようにコード化できます。中間で最も重要なことは、過学習を回避する方法です (元のターゲット エンコーディングはすべてのトレーニング セット データとラベルを直接エンコードするため、得られるエンコード結果がトレーニング セットに大きく依存することになります)。一般的な解決策は 2 を使用することです。相互検証のレベルによってターゲット平均が見つかります。アイデアは次のとおりです:
把train data划分为20-folds (举例:infold: fold #2-20, out of fold: fold #1)
计算 10-folds的 inner out of folds值 (举例:使用inner_infold #2-10 的target的均值,来作为inner_oof #1的预测值)
对10个inner out of folds 值取平均,得到 inner_oof_mean
将每一个 infold (fold #2-20) 再次划分为10-folds (举例:inner_infold: fold #2-10, Inner_oof: fold #1)
计算oof_mean (举例:使用 infold #2-20的inner_oof_mean 来预测 out of fold #1的oof_mean
将train data 的 oof_mean 映射到test data完成编码
比如划分为10折,每次对9折进行标签编码然后用得到的标签编码模型预测第10折的特征得到结果,其实就是常说的均值编码。
目标编码尝试对分类特征中每个级别的目标总体平均值进行测量。当数据量较少时,每个级别的数据量减少意味着估计的均值与真实均值之间的差距增加,方差也会更大。
from category_encoders import TargetEncoder import pandas as pd from sklearn.datasets import load_boston # prepare some data bunch = load_boston() y_train = bunch.target[0:250] y_test = bunch.target[250:506] X_train = pd.DataFrame(bunch.data[0:250], columns=bunch.feature_names) X_test = pd.DataFrame(bunch.data[250:506], columns=bunch.feature_names) # use target encoding to encode two categorical features enc = TargetEncoder(cols=['CHAS', 'RAD']) # transform the datasets training_numeric_dataset = enc.fit_transform(X_train, y_train) testing_numeric_dataset = enc.transform(X_test)
ログイン後にコピーBeta Target Encoding
Kaggle竞赛Avito Demand Prediction Challenge 第14名的solution分享:14th Place Solution: The Almost Golden Defenders。和target encoding 一样,beta target encoding 也采用 target mean value (among each category) 来给categorical feature做编码。不同之处在于,为了进一步减少target variable leak,beta target encoding发生在在5-fold CV内部,而不是在5-fold CV之前:
把train data划分为5-folds (5-fold cross validation)
target encoding based on infold data
train model
get out of fold prediction
同时beta target encoding 加入了smoothing term,用 bayesian mean 来代替mean。Bayesian mean (Bayesian average) 的思路:某一个category如果数据量较少(
另外,对于target encoding和beta target encoding,不一定要用target mean (or bayesian mean),也可以用其他的统计值包括 medium, frqequency, mode, variance, skewness, and kurtosis — 或任何与target有correlation的统计值。
# train -> training dataframe # test -> test dataframe # N_min -> smoothing term, minimum sample size, if sample size is less than N_min, add up to N_min # target_col -> target column # cat_cols -> categorical colums # Step 1: fill NA in train and test dataframe # Step 2: 5-fold CV (beta target encoding within each fold) kf = KFold(n_splits=5, shuffle=True, random_state=0) for i, (dev_index, val_index) in enumerate(kf.split(train.index.values)): # split data into dev set and validation set dev = train.loc[dev_index].reset_index(drop=True) val = train.loc[val_index].reset_index(drop=True) feature_cols = [] for var_name in cat_cols: feature_name = f'{var_name}_mean' feature_cols.append(feature_name) prior_mean = np.mean(dev[target_col]) stats = dev[[target_col, var_name]].groupby(var_name).agg(['sum', 'count'])[target_col].reset_index() ### beta target encoding by Bayesian average for dev set df_stats = pd.merge(dev[[var_name]], stats, how='left') df_stats['sum'].fillna(value = prior_mean, inplace = True) df_stats['count'].fillna(value = 1.0, inplace = True) N_prior = np.maximum(N_min - df_stats['count'].values, 0) # prior parameters dev[feature_name] = (prior_mean * N_prior + df_stats['sum']) / (N_prior + df_stats['count']) # Bayesian mean ### beta target encoding by Bayesian average for val set df_stats = pd.merge(val[[var_name]], stats, how='left') df_stats['sum'].fillna(value = prior_mean, inplace = True) df_stats['count'].fillna(value = 1.0, inplace = True) N_prior = np.maximum(N_min - df_stats['count'].values, 0) # prior parameters val[feature_name] = (prior_mean * N_prior + df_stats['sum']) / (N_prior + df_stats['count']) # Bayesian mean ### beta target encoding by Bayesian average for test set df_stats = pd.merge(test[[var_name]], stats, how='left') df_stats['sum'].fillna(value = prior_mean, inplace = True) df_stats['count'].fillna(value = 1.0, inplace = True) N_prior = np.maximum(N_min - df_stats['count'].values, 0) # prior parameters test[feature_name] = (prior_mean * N_prior + df_stats['sum']) / (N_prior + df_stats['count']) # Bayesian mean # Bayesian mean is equivalent to adding N_prior data points of value prior_mean to the data set. del df_stats, stats # Step 3: train model (K-fold CV), get oof predictioログイン後にコピーM-Estimate Encoding
M-Estimate Encoding 相当于 一个简化版的Target Encoding:
其中????+代表所有正Label的个数,m是一个调参的参数,m越大过拟合的程度就会越小,同样的在处理连续值时????+可以换成label的求和,????+换成所有label的求和。
James-Stein Encoding
一种基于目标的算法是 James-Stein 编码。算法的思想很简单,对于特征的每个取值 k 可以根据下面的公式获得:
其中B由以下公式估计:
但是它有一个要求是target必须符合正态分布,这对于分类问题是不可能的,因此可以把y先转化成概率的形式。在实际操作中,可以使用网格搜索方法来选择一个较优的B值。
Weight of Evidence Encoder
Weight Of Evidence 同样是基于target的方法。
使用WOE作为变量,第i类的WOE等于:
WOE特别合适逻辑回归,因为Logit=log(odds)。WOE编码的变量被编码为统一的维度(是一个被标准化过的值),变量之间直接比较系数即可。
Leave-one-out Encoder (LOO or LOOE)
这个方法类似于SUM的方法,只是在计算训练集每个样本的特征值转换时都要把该样本排除(消除特征某取值下样本太少导致的严重过拟合),在计算测试集每个样本特征值转换时与SUM相同。可见以下公式:
Binary Encoding
使用二进制编码对每一类进行编号,使用具有log2N维的向量对N类进行编码。以 (0,0) 为例,它表示第一类,而 (0,1) 表示第二类,(1,0) 表示第三类,(1,1) 则表示第四类
Hashing Encoding
类似于One-hot encoding,但是通过hash函数映射到一个低维空间,并且使得两个类对应向量的空间距离基本保持一致。使用低维空间来降低了表示向量的维度。
特征哈希可能会导致要素之间发生冲突。一个哈希编码的好处是不需要指定或维护原变量与新变量之间的映射关系。因此,哈希编码器的大小及复杂程度不随数据类别的增多而增多。
Probability Ratio Encoding
和WOE相似,只是去掉了log,即:
Sum Encoder (Deviation Encoder、Effect Encoder)
特徴値の下のラベル (またはその他の関連変数) の平均値を全体の平均値と比較することにより、特定の特徴に対して合計エンコードを実行します。それらの間の違いにラベルを付けて特徴をエンコードします。詳細が適切に行われていない場合、この方法は過剰適合する傾向が非常に高いため、特徴をエンコードするには、leave-one-out 方法または 5 分割交差検証と組み合わせる必要があります。過剰適合を防ぐために、分散に基づいてペナルティ項を追加する方法もあります。
Helmert エンコーディング
Helmert エンコーディングは計量経済学でよく使用されます。 Helmert エンコード後 (カテゴリ特徴量の各値は Helmert 行列の行に対応します)、線形モデルのエンコードされた変数係数は、カテゴリ変数の特定のカテゴリ値が与えられた場合の従属変数の平均値を反映できます。そのカテゴリ内の他のカテゴリの値を与えられた従属変数の平均。
ヘルメット エンコーディングは、One-Hot エンコーディングと Sum Encoder に次いで最も広く使用されているエンコーディング方法です。Sum Encoder とは異なり、特定の特徴値の下で対応するラベル (またはその他の関連変数) を比較します。) は、と比較されます。すべての特徴の平均ではなく、以前の特徴の平均。この特徴は過剰適合する傾向もあります。
CatBoost エンコーディング
可能な値の数がワンホット最大値より大きいカテゴリカル変数の場合、CatBoost は平均エンコーディングに似た非常に効果的なエンコーディング方法を使用します。過学習を減らすことができます。その具体的な実装方法は次のとおりです。
入力サンプル セットをランダムに並べ替え、ランダムな配置の複数のグループを生成します。
浮動小数点タグまたは属性値タグを整数に変換します。
すべての分類特徴量結果を次の式に従って数値化します。
このうち、CountInClass は、現在の分類特徴値でマーク値 1 を持つサンプルがいくつあるかを示し、Prior は、初期パラメーターに従って決定される分子の初期値です。 TotalCount は、現在のサンプル自体を含む、現在のサンプルと同じ分類特徴値を持つすべてのサンプルの数を表します。
CatBoost 処理の概要 カテゴリ特徴量:
まず、いくつかのデータの統計を計算します。カテゴリの出現頻度を計算し、ハイパーパラメータを追加して、新しい数値特徴を生成します。この戦略では、同じラベルを持つデータを一緒に配置することができず (つまり、最初にすべて 0、次にすべて 1)、トレーニング前にデータ セットをスクランブルする必要があります。
2 番目に、データの異なる順列 (実際には 4 つ) を使用します。各ラウンドでツリーを構築する前に、サイコロのラウンドを投げて、ツリーを構築するためにどの配置を使用するかを決定します。
3 番目のポイントは、カテゴリ特徴量のさまざまな組み合わせを試してみることです。たとえば、色とタイプを組み合わせて、青い犬に似た特徴を形成できます。組み合わせる必要があるカテゴリ特徴量の数が増えると、catboost は一部の組み合わせのみを考慮します。最初のノードを選択するときは、A などの 1 つのフィーチャのみが考慮されます。 2 番目のノードを生成するときは、A とカテゴリ特徴の組み合わせを考慮して、最適なものを選択します。このように、貪欲なアルゴリズムを使用して組み合わせが生成されます。
第 4 に、性別のように次元が非常に小さい場合を除き、ワンホット ベクトルを自分で生成することはお勧めできません。アルゴリズムに任せるのが最善です。
以上がPython 機械学習でカテゴリ特徴を処理する方法は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7642
7642
 15
1392
52
91
11
33
150
15
1392
52
91
11
33
150

 PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPは主に手順プログラミングですが、オブジェクト指向プログラミング(OOP)もサポートしています。 Pythonは、OOP、機能、手続き上のプログラミングなど、さまざまなパラダイムをサポートしています。 PHPはWeb開発に適しており、Pythonはデータ分析や機械学習などのさまざまなアプリケーションに適しています。
 PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPはWeb開発と迅速なプロトタイピングに適しており、Pythonはデータサイエンスと機械学習に適しています。 1.PHPは、単純な構文と迅速な開発に適した動的なWeb開発に使用されます。 2。Pythonには簡潔な構文があり、複数のフィールドに適しており、強力なライブラリエコシステムがあります。
 Windows 8でコードを実行できます
Apr 15, 2025 pm 07:24 PM
Windows 8でコードを実行できます
Apr 15, 2025 pm 07:24 PM
VSコードはWindows 8で実行できますが、エクスペリエンスは大きくない場合があります。まず、システムが最新のパッチに更新されていることを確認してから、システムアーキテクチャに一致するVSコードインストールパッケージをダウンロードして、プロンプトとしてインストールします。インストール後、一部の拡張機能はWindows 8と互換性があり、代替拡張機能を探すか、仮想マシンで新しいWindowsシステムを使用する必要があることに注意してください。必要な拡張機能をインストールして、適切に動作するかどうかを確認します。 Windows 8ではVSコードは実行可能ですが、開発エクスペリエンスとセキュリティを向上させるために、新しいWindowsシステムにアップグレードすることをお勧めします。
 VSCODE拡張機能は悪意がありますか?
Apr 15, 2025 pm 07:57 PM
VSCODE拡張機能は悪意がありますか?
Apr 15, 2025 pm 07:57 PM
VSコード拡張機能は、悪意のあるコードの隠れ、脆弱性の活用、合法的な拡張機能としての自慰行為など、悪意のあるリスクを引き起こします。悪意のある拡張機能を識別する方法には、パブリッシャーのチェック、コメントの読み取り、コードのチェック、およびインストールに注意してください。セキュリティ対策には、セキュリティ認識、良好な習慣、定期的な更新、ウイルス対策ソフトウェアも含まれます。
 Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
VSコードはPythonの書き込みに使用でき、Pythonアプリケーションを開発するための理想的なツールになる多くの機能を提供できます。ユーザーは以下を可能にします。Python拡張機能をインストールして、コードの完了、構文の強調表示、デバッグなどの関数を取得できます。デバッガーを使用して、コードを段階的に追跡し、エラーを見つけて修正します。バージョンコントロールのためにGitを統合します。コードフォーマットツールを使用して、コードの一貫性を維持します。糸くずツールを使用して、事前に潜在的な問題を発見します。
 ターミナルVSCODEでプログラムを実行する方法
Apr 15, 2025 pm 06:42 PM
ターミナルVSCODEでプログラムを実行する方法
Apr 15, 2025 pm 06:42 PM
VSコードでは、次の手順を通じて端末でプログラムを実行できます。コードを準備し、統合端子を開き、コードディレクトリが端末作業ディレクトリと一致していることを確認します。プログラミング言語(pythonのpython your_file_name.pyなど)に従って実行コマンドを選択して、それが正常に実行されるかどうかを確認し、エラーを解決します。デバッガーを使用して、デバッグ効率を向上させます。
 Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Pythonは、スムーズな学習曲線と簡潔な構文を備えた初心者により適しています。 JavaScriptは、急な学習曲線と柔軟な構文を備えたフロントエンド開発に適しています。 1。Python構文は直感的で、データサイエンスやバックエンド開発に適しています。 2。JavaScriptは柔軟で、フロントエンドおよびサーバー側のプログラミングで広く使用されています。
 vscodeはMacに使用できますか
Apr 15, 2025 pm 07:36 PM
vscodeはMacに使用できますか
Apr 15, 2025 pm 07:36 PM
VSコードはMacで利用できます。強力な拡張機能、GIT統合、ターミナル、デバッガーがあり、豊富なセットアップオプションも提供しています。ただし、特に大規模なプロジェクトまたは非常に専門的な開発の場合、コードと機能的な制限がある場合があります。
