

Redis が Spark を高速化する方法

Apache Spark は、次世代ビッグ データ処理ツールのモデルになりつつあります。オープンソース アルゴリズムを借用し、計算ノードのクラスター全体に処理タスクを分散することにより、Spark および Hadoop 生成フレームワークは、単一プラットフォーム上で実行できるデータ分析の種類と、これらのタスクを実行できる速度の両方において容易に優れています。伝統的なフレームワーク。 Spark はメモリを使用してデータを処理するため、ディスクベースの Hadoop よりも大幅に高速 (最大 100 倍) になります。
しかし、少しの助けを借りれば、Spark はさらに高速に実行できるようになります。 Spark と Redis (一般的なメモリ内データ構造ストレージ テクノロジ) を組み合わせると、分析タスクの処理パフォーマンスを再び大幅に向上させることができます。これは、Redis の最適化されたデータ構造と、操作実行時の複雑さとオーバーヘッドを最小限に抑える機能によるものです。コネクタを使用して Redis のデータ構造と API に接続すると、Spark をさらに高速化できます。
スピードアップはどれくらいですか? Redis を Spark と組み合わせて使用すると、(後述する時系列データを分析するための) データの処理は、単にインプロセス メモリを使用する Spark よりも高速であることがわかります。 45 倍 – 45% ではなく、完全に 45 倍高速です!
多くの企業がビジネスと同じ速さで分析を可能にする必要があるため、分析トランザクション速度の重要性が高まっています。取引。自動化される意思決定が増えるにつれ、それらの意思決定を推進するために必要な分析はリアルタイムで行われる必要があります。 Apache Spark は優れた汎用データ処理フレームワークであり、完全にリアルタイムではありませんが、データをよりタイムリーに活用できるようにするための大きな一歩となります。
Spark は、揮発性メモリまたは HDFS などの永続ストレージ システムに保存できる Resilient Distributed Datasets (RDD) を使用します。 Spark クラスターのノード全体に分散されたすべての RDD は変更されませんが、他の RDD は変換操作を通じて作成できます。
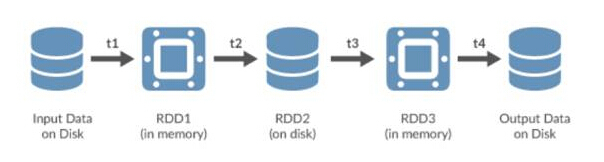
Spark RDD
RDD は、Spark の重要な抽象オブジェクトです。これらは、反復プロセスにデータを効率的に提示するフォールトトレラントな方法を表します。インメモリ処理を使用すると、HDFS や MapReduce を使用する場合と比較して、処理時間が桁違いに短縮されます。
Redis は、高パフォーマンスを実現するために特別に設計されています。ミリ秒未満の遅延は、データが保存されている場所の近くで操作を実行できるようにすることで効率を向上させる最適化されたデータ構造の結果です。このデータ構造はメモリを効率的に利用し、アプリケーションの複雑さを軽減するだけでなく、ネットワークのオーバーヘッド、帯域幅の消費、処理時間も削減します。 Redis は、文字列、セット、ソートされたセット、ハッシュ、ビットマップ、ハイパーログログ、地理空間インデックスなどの複数のデータ構造をサポートします。 Redis データ構造はレゴ ブロックのようなもので、開発者に複雑な機能を実装するためのシンプルなチャネルを提供します。
このデータ構造がアプリケーションの処理時間と複雑さをどのように簡素化できるかを視覚的に示すために、順序付きセット (ソート セット) データ構造を例として取り上げます。順序付きセットは、基本的にスコアによって順序付けされたメンバーのセットです。

Redis ソートコレクション
ここにはさまざまな種類のデータを保存でき、それらはスコアによって自動的にソートされます。順序付けされたコレクションに保存される一般的なデータ タイプには、品目 (価格別)、製品名 (数量別)、株価、タイムスタンプなどのセンサー読み取り値などの時系列データが含まれます。
順序付きコレクションの魅力は、範囲クエリ、複数の順序付きコレクションの交差、メンバー レベルとスコアによる取得、およびより多くのトランザクションを非常に高速に簡単に実行できる Redis の組み込み操作にあります。も大規模に実行されます。組み込み操作により、記述する必要のあるコードが節約されるだけでなく、メモリ内での実行によりネットワーク遅延が削減され、帯域幅が節約され、ミリ秒未満の遅延で高スループットが可能になります。ソート セットを使用して時系列データを分析すると、多くの場合、他のインメモリ キー/値ストレージ システムやディスク ベースのデータベースと比較して、数桁のパフォーマンス向上を達成できます。
Spark-Redis コネクタは、Spark の分析機能を向上させるために Redis チームによって開発されました。このパッケージにより、Spark はデータ ソースの 1 つとして Redis を使用できるようになります。このコネクタを通じて、Spark は Redis のデータ構造に直接アクセスできるため、さまざまな種類の分析のパフォーマンスが大幅に向上します。

Spark Redis コネクタ
Spark にもたらされるメリットを実証するために、Redis チームはいくつかの異なるシナリオを使用することにしました。 Spark での時系列分析を水平方向に比較するためのタイム スライス (範囲) クエリ。これらのシナリオには、Spark がすべてのデータをヒープ内メモリに保存する、Spark がオフヒープ キャッシュとして Tachyon を使用する、Spark が HDFS を使用する、および Spark と Redis の組み合わせが含まれます。
Redis チームは、Cloudera の Spark 時系列パッケージを使用して、Redis の順序付きコレクションを使用して時系列分析を高速化する Spark-Redis 時系列パッケージを構築しました。 Spark が Redis にアクセスできるようにするすべてのデータ構造を提供することに加えて、このパッケージは 2 つの追加タスクも実行します
Redis ノードが Spark クラスターと一致していることを自動的に確認します。これにより、各 Spark ノードがローカル Redis データを使用するようになり、レイテンシーが最適化されます。
Spark データフレームおよびデータ ソース API と統合して、Spark SQL クエリを Redis のデータの最も効率的な取得メカニズムに自動的に変換します。
簡単に言えば、これは、ユーザーが Spark と Redis 間の運用の一貫性を心配する必要がなく、クエリのパフォーマンスを大幅に向上させながら、分析に Spark SQL を使い続けることができることを意味します。
この水平比較で使用される時系列データには、ランダムに生成された財務データと、32 年間にわたる 1 日あたり 1024 株の銘柄が含まれます。各株式は独自の順序セットで表され、スコアは日付であり、データ メンバーには始値、最終価格、最終価格、終値、取引高、および調整終値が含まれます。次の図は、Spark 分析に使用される Redis ソート セットのデータ表現を示しています。
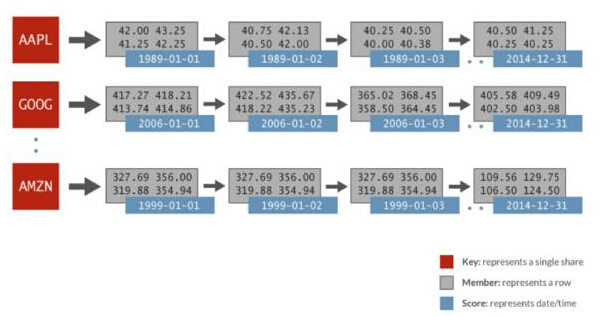
Spark Redis 時系列
上記の例では、順序セット AAPL の場合、毎日 (1989-01-01) で表されるスコアと、関連する行として表される 1 日全体の複数の値があります。これを行うには、Redis で単純な ZRANGEBYSCORE コマンドを使用するだけです。特定のタイム スライスのすべての値を取得し、したがって指定された日付範囲のすべての株価を取得します。 Redis は、この種のクエリを他のキー/値ストレージ システムよりも最大 100 倍高速に実行できます。
この水平比較により、パフォーマンスの向上が確認されます。 Redis を使用した Spark は、HDFS を使用した Spark よりも 135 倍高速にタイム スライス クエリを実行でき、オンヒープ (プロセス) メモリを使用した Spark またはオフヒープ キャッシュとして Tachyon を使用した Spark よりも 45 倍高速にタイム スライス クエリを実行できることがわかりました。以下の図は、さまざまなシナリオで比較した平均実行時間を示しています。
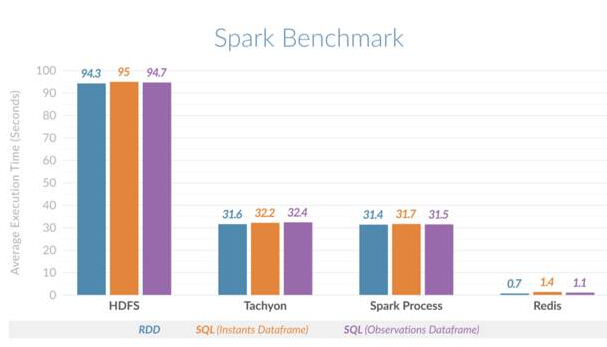
Spark Redis の水平比較
このガイドでは、ステップごとに説明します。ステップ 標準の Spark クラスターと Spark-Redis パッケージをインストールする手順を案内します。簡単な単語カウントの例を通じて、Spark と Redis の使用を統合する方法を示します。 Spark と Spark-Redis パッケージを試した後、他の Redis データ構造を利用するシナリオをさらに検討できます。
順序付きセットは時系列データに適していますが、Redis の他のデータ構造 (セット、リスト、地理空間インデックスなど) を使用すると、Spark 分析をさらに強化できます。これを想像してみてください。Spark プロセスは、新製品の発売効果を最適化するために、群衆の好みや市内中心部からの距離などの要素を考慮して、どのエリアが新製品の発売に適しているかを判断しようとしています。地理空間インデックスや分析機能が組み込まれたコレクションなどのデータ構造が、このプロセスをどのように大幅にスピードアップできるかを想像してみてください。 Spark と Redis の組み合わせには、優れたアプリケーションの可能性があります。
Spark は、SQL、機械学習、グラフ コンピューティング、Spark ストリーミングなどの幅広い分析機能を提供します。 Spark のメモリ内処理機能を使用しても、一定の規模までしか達成できません。ただし、Redis を使用すると、さらに一歩先に進むことができます。Redis のデータ構造を使用してパフォーマンスを向上させるだけでなく、Spark が提供する共有分散メモリ データ ストレージ メカニズムを最大限に活用して、Spark をより簡単に拡張することもできます。 Redis は数十万のレコード、さらには数十億のレコードを処理します。
この時系列の例はほんの始まりにすぎません。機械学習とグラフ分析に Redis データ構造を使用すると、これらのワークロードに実行時間の大幅な利点がもたらされることが期待されます。
以上がRedis が Spark を高速化する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1673
1673
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 Centos RedisでLUAスクリプト実行時間を構成する方法
Apr 14, 2025 pm 02:12 PM
Centos RedisでLUAスクリプト実行時間を構成する方法
Apr 14, 2025 pm 02:12 PM
Centosシステムでは、Redis構成ファイルを変更するか、Redisコマンドを使用して悪意のあるスクリプトがあまりにも多くのリソースを消費しないようにすることにより、LUAスクリプトの実行時間を制限できます。方法1:Redis構成ファイルを変更し、Redis構成ファイルを見つけます:Redis構成ファイルは通常/etc/redis/redis.confにあります。構成ファイルの編集:テキストエディター(VIやNANOなど)を使用して構成ファイルを開きます:sudovi/etc/redis/redis.conf luaスクリプト実行時間制限を設定します。
 Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインツール(Redis-Cli)を使用して、次の手順を使用してRedisを管理および操作します。サーバーに接続し、アドレスとポートを指定します。コマンド名とパラメーターを使用して、コマンドをサーバーに送信します。ヘルプコマンドを使用して、特定のコマンドのヘルプ情報を表示します。 QUITコマンドを使用して、コマンドラインツールを終了します。
 Redisカウンターを実装する方法
Apr 10, 2025 pm 10:21 PM
Redisカウンターを実装する方法
Apr 10, 2025 pm 10:21 PM
Redisカウンターは、Redisキー価値ペアストレージを使用して、カウンターキーの作成、カウントの増加、カウントの減少、カウントのリセット、およびカウントの取得など、カウント操作を実装するメカニズムです。 Redisカウンターの利点には、高速速度、高い並行性、耐久性、シンプルさと使いやすさが含まれます。ユーザーアクセスカウント、リアルタイムメトリック追跡、ゲームのスコアとランキング、注文処理などのシナリオで使用できます。
 Redisの有効期限ポリシーを設定する方法
Apr 10, 2025 pm 10:03 PM
Redisの有効期限ポリシーを設定する方法
Apr 10, 2025 pm 10:03 PM
Redisデータの有効期間戦略には2つのタイプがあります。周期削除:期限切れのキーを削除する定期的なスキャン。これは、期限切れの時間帯-remove-countおよび期限切れの時間帯-remove-delayパラメーターを介して設定できます。怠zyな削除:キーが読み取られたり書かれたりした場合にのみ、削除の有効期限が切れたキーを確認してください。それらは、レイジーフリーレイジーエビクション、レイジーフリーレイジーエクスピア、レイジーフリーラジーユーザーのパラメーターを介して設定できます。
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
