
 テクノロジー周辺機器
AI
GPT-4 は優れた数学的能力を持っています。 OpenAI の「プロセス監視」に関する爆発的な研究により、問題の 78.2% が突破され、幻覚が解消されました
テクノロジー周辺機器
AI
GPT-4 は優れた数学的能力を持っています。 OpenAI の「プロセス監視」に関する爆発的な研究により、問題の 78.2% が突破され、幻覚が解消されました
GPT-4 は優れた数学的能力を持っています。 OpenAI の「プロセス監視」に関する爆発的な研究により、問題の 78.2% が突破され、幻覚が解消されました

ChatGPT は、リリース以来、その数学的能力について批判されてきました。
「数学の天才」テレンス・タオですら、GPT-4 は自分の専門分野である数学に大きな価値をもたらすものではないとかつて述べました。
ChatGPT を「数学的遅れ」にしておいて、どうすればよいでしょうか?
OpenAI は懸命に取り組んでいます - GPT-4 の数学的推論機能を向上させるために、OpenAI チームは「プロセス監視」(PRM) を使用してモデルをトレーニングしています。
ステップバイステップで確認してみましょう。

論文アドレス: https://cdn.openai.com/improving-mathematical-reasoning-with-process-supervision/Lets_Verify_Step_by_Step .pdf
論文では、研究者らは、正しい最終結果 (結果の監視) だけを評価するのではなく、「プロセスの監視」として知られる正しい推論の各ステップに報酬を与えることで、数学的問題解決においてより良い結果が得られるようにモデルをトレーニングしました。 ).最新のSOTA。
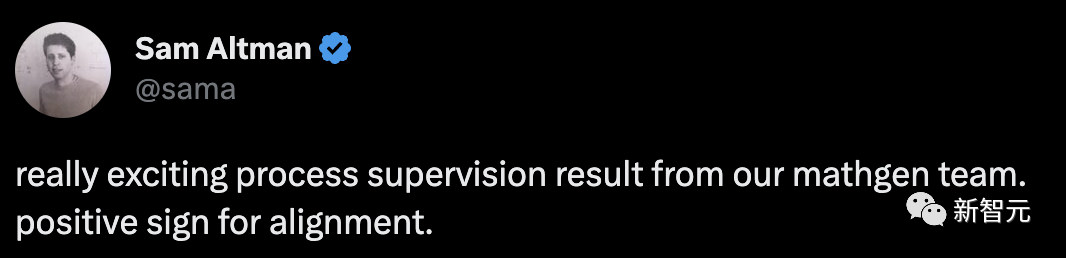
具体的には、PRM は MATH テスト セットの代表的なサブセットの問題の 78.2% を解決しました。

# さらに、OpenAI は、調整において「プロセス監視」が非常に価値があることを発見しました。これは、認識される思考の連鎖を生成するようにモデルをトレーニングすることです。人間。
最新の研究は、Sam Altman 氏の「私たちの Mathgen チームはプロセス監視において非常に刺激的な結果を達成しました。これは調整の前向きな兆候です。」を推進するためには、もちろん不可欠です。
 実際には、「プロセス監視」には手動によるフィードバックが必要ですが、大規模なモデルやさまざまなタスクでは非常にコストがかかります。したがって、この研究は非常に重要であり、OpenAI の今後の研究の方向性を決定すると言えます。
実際には、「プロセス監視」には手動によるフィードバックが必要ですが、大規模なモデルやさまざまなタスクでは非常にコストがかかります。したがって、この研究は非常に重要であり、OpenAI の今後の研究の方向性を決定すると言えます。
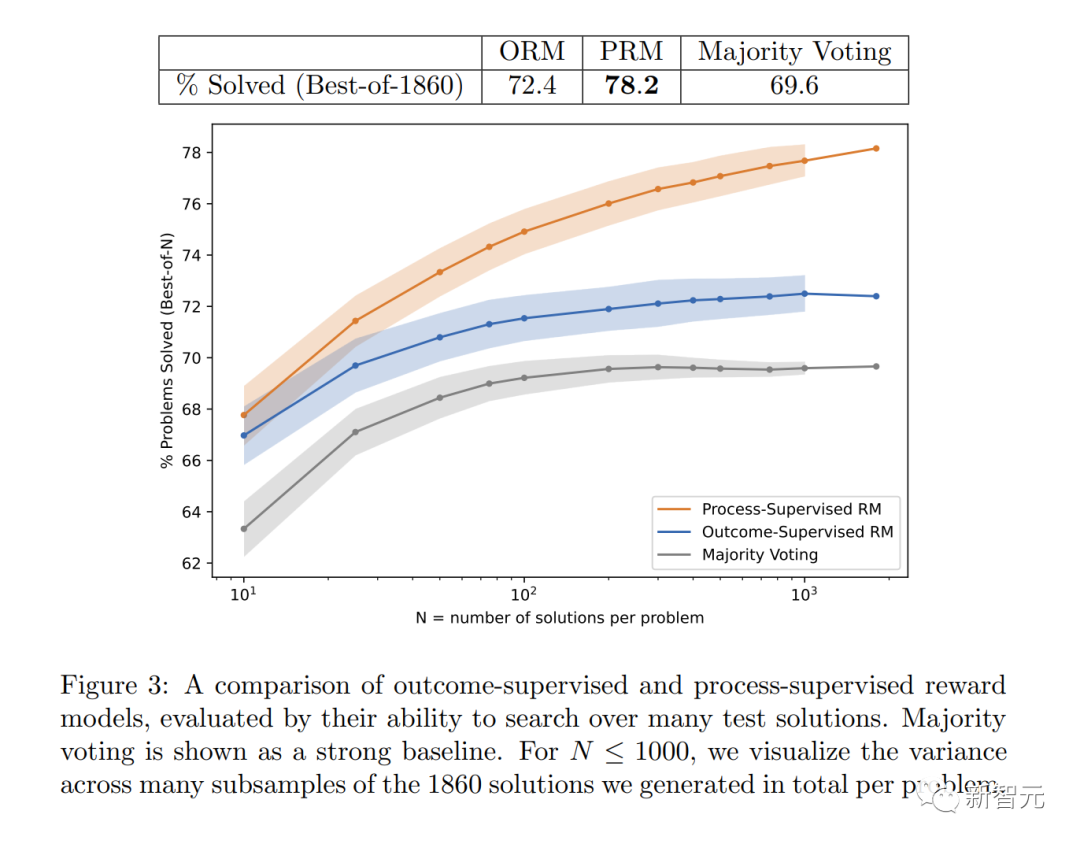
#この図は、最終的に正しい回答となった選択された解決策の割合を、検討された解決策の数の関数として示しています。 
これは、「プロセス監視」報酬モデルがより信頼できることを示しています。
以下、OpenAI は、モデルに関する 10 の数学的問題と解決策、および報酬モデルの長所と短所についてのコメントを示します。 
真 (TP) 
この難しい三角関数の問題では、いくつかの恒等式を分かりにくい順序で適用する必要があります。
しかし、実際に役立つ ID を選択するのは難しいため、解決策のほとんどの試みは失敗します。
GPT-4 は一般にこの問題の解決に失敗し、正しい答えに到達しようとする解決策は 0.1% のみですが、報酬モデルはこの解決策が有効であると正しく識別します。

ここで、GPT-4 は一連の複雑な多項式因数分解を正常に実行します。
ステップ 5 で Sophie-Germain ID を使用することは重要なステップです。このステップは非常に洞察力に富んだものであることがわかります。

ステップ 7 と 8 で、GPT-4 は推測とチェックの実行を開始します。
これは、モデルが「幻覚」を起こし、特定の推測が成功したと主張できる一般的な場所です。この場合、報酬モデルは各ステップを検証し、思考の連鎖が正しいかどうかを判断します。

モデルは、式を簡素化するためにいくつかの三角恒等式を適用することに成功しました。

真陰性 (TN)
ステップ 7 で、GPT-4 は式を単純化しようとしますが、失敗します。報酬モデルがこのバグを捕捉しました。

ステップ 11 で、GPT-4 は単純な計算エラーを犯しました。報酬モデルでも発見されました。


報酬モデルはこのエラーを修正します。

ステップ 4 で、GPT-4 は「シーケンスは 12 項目ごとに繰り返される」と誤って主張しています。 , しかし、実際には 10 項目ごとに繰り返されます。この計数エラーにより、報酬モデルが騙されることがあります。


 #GPT-4 は、ステップ 9 で微妙なカウント エラーを犯しました。
#GPT-4 は、ステップ 9 で微妙なカウント エラーを犯しました。
表面上、同じ色のボールを交換する方法は 5 つある (色が 5 つあるため) という主張は合理的であるように思えます。
ただし、ボブには 2 つの選択肢 (つまり、どのボールをアリスに渡すかを決定する) があるため、このカウントは 2 の係数で過小評価されます。報酬モデルはこのエラーによって騙されます。

プロセス監視
大規模な言語モデルは、複雑な推論機能の点で大幅に向上しましたが、最も先進的なモデルであっても、依然として論理的なエラーやナンセンスが発生し、これは「幻想」と呼ばれることがよくあります。
生成型人工知能の流行の中で、大規模な言語モデルの幻想が常に人々を悩ませてきました。
マスク氏は、「我々に必要なのはTruthGPTだ」と述べました
たとえば、最近、アメリカ人弁護士がニューヨーク連邦裁判所に訴訟を起こしました。 ChatGPTの捏造事件を引用しており、制裁を受ける可能性がある。
OpenAI 研究者はレポートの中で次のように述べています:「単純な論理エラーがソリューション全体に大きな損害を与える可能性があるため、これらの錯覚は複数ステップの推論を必要とする分野で特に問題となります。」
さらに、幻覚を軽減することも、一貫した AGI を構築するための鍵となります。
大きなモデルの錯覚を軽減するにはどうすればよいですか?一般に、プロセス監視と結果監視の 2 つの方法があります。
「結果監視」はその名のとおり、最終結果に基づいて大規模モデルにフィードバックを与えるのに対し、「プロセス監視」は思考連鎖の各ステップに対してフィードバックを与えることができます。

プロセス監視では、大規模なモデルは、正しい最終結論だけでなく、正しい推論ステップに対しても報酬を与えられます。このプロセスにより、モデルはより人間に近い思考方法の連鎖に従うようになり、より説明可能な AI を作成する可能性が高くなります。
OpenAIの研究者らは、プロセス監視はOpenAIが発明したものではないが、OpenAIはそれを推進するために懸命に取り組んでいると述べた。
最新の研究では、OpenAI は「結果監視」または「プロセス監視」の両方の方法を試しました。そして、MATH データセットをテストプラットフォームとして使用して、2 つの方法の詳細な比較が行われます。
その結果、「プロセス監視」によってモデルのパフォーマンスが大幅に向上することがわかりました。
数学的タスクの場合、プロセス監視は大規模なモデルと小規模なモデルの両方で大幅に優れた結果を生成しました。これは、モデルが一般的に正しいことを意味し、また、より人間らしい思考プロセス。
このようにして、最も強力なモデルであっても回避するのが難しい錯覚や論理エラーを減らすことができます。
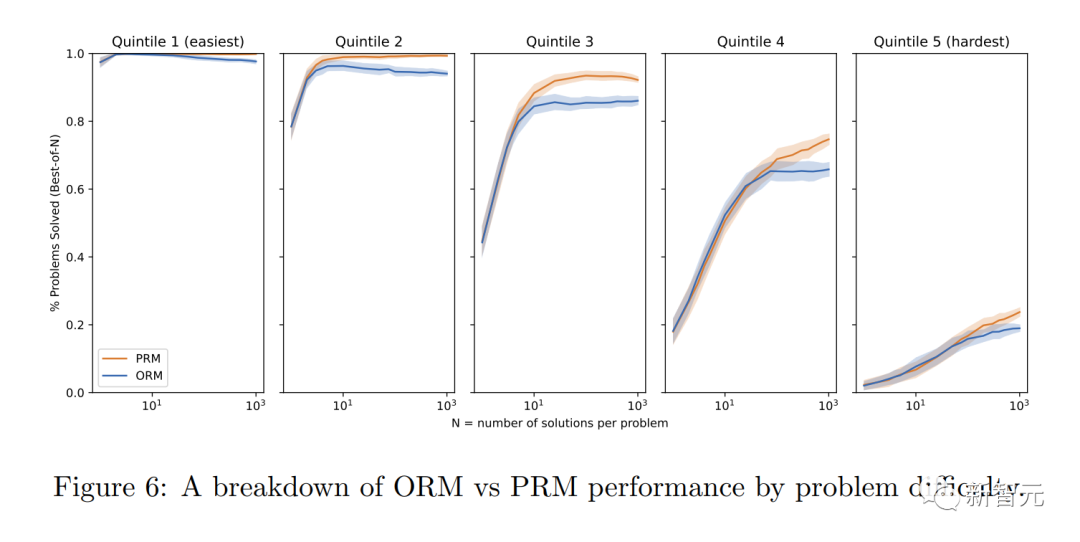
調整の利点は明らかです
研究者らは、「プロセスの監視」には「結果の監視」に比べて調整の利点がいくつかあることを発見しました。
· プロセスの各ステップが正確に監視されるため、直接的な報酬は一貫した思考連鎖モデルに従います。
· 「プロセス監視」により、モデルが人間の承認したプロセスに従うことが奨励されるため、説明可能な推論が生成される可能性が高くなります。対照的に、結果のモニタリングでは一貫性のないプロセスが評価される可能性があり、レビューがより困難になることがよくあります。
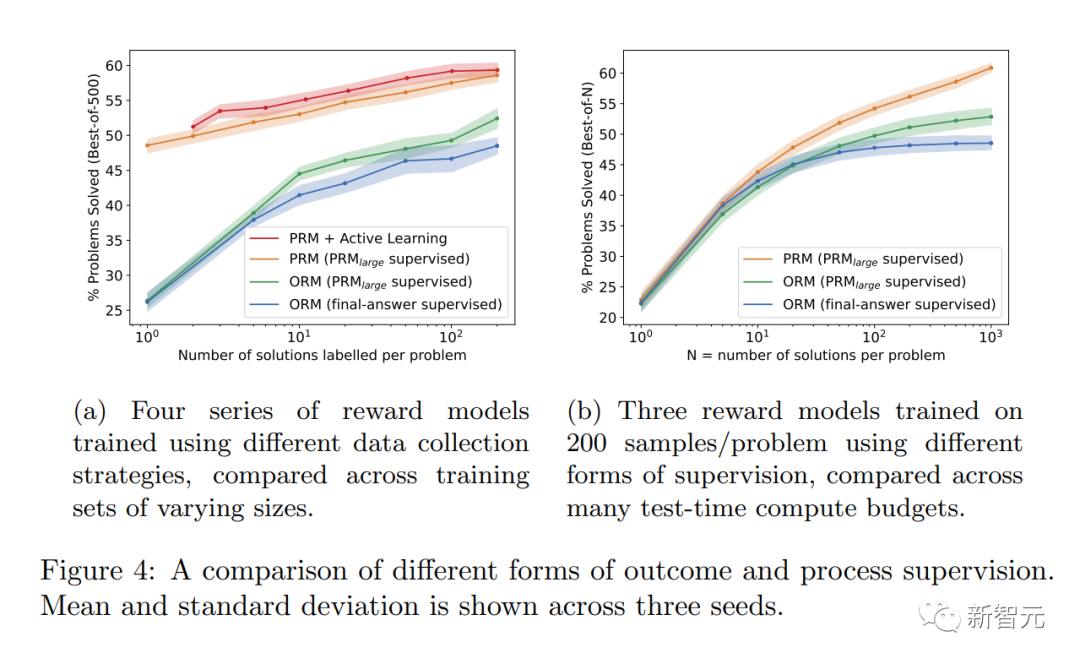
AI システムをより安全にする方法によっては、場合によってはパフォーマンスの低下が生じる可能性があることにも言及する価値があります。この費用は「調整税」と呼ばれます。
一般的に、「調整税」のコストは、最も機能的なモデルを導入するための調整方法の採用を妨げる可能性があります。
しかし、以下の研究者らの結果は、「プロセス監視」が数学領域のテスト中に実際に「負の調整税」を生み出すことを示しています。
調整による大きなパフォーマンスの低下はないと言えます。
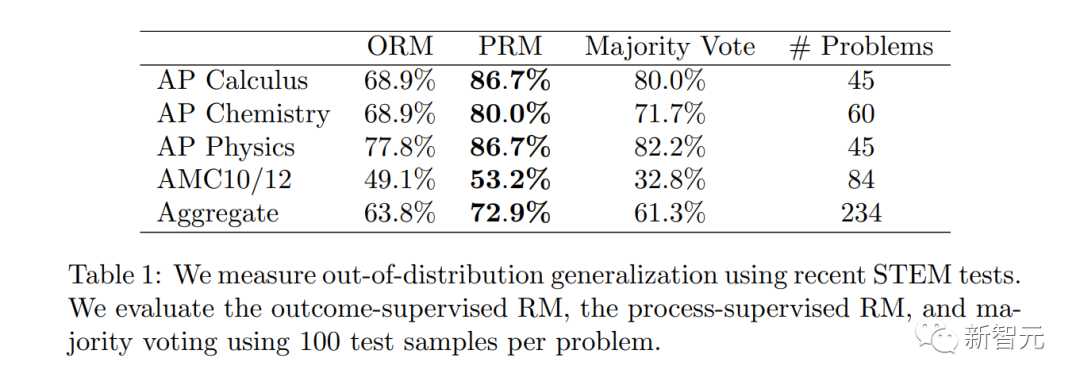
OpenAI が 800,000 個の人による注釈付きデータ セットをリリース
PRM にはさらに多くの人による注釈が必要であることは注目に値します。そうしないと、深くできないのです。 RLHFなしで生きてください。
プロセス監視は数学以外の分野にどの程度適用できますか?このプロセスにはさらなる調査が必要です。
OpenAI 研究者は、このヒューマン フィードバック データ セット PRM を公開しました。これには、800,000 のステップレベルの正しい注釈が含まれています: 12,000 の数学問題から生成された 75,000 のソリューション

アノテーションの例を以下に示します。 OpenAI は、プロジェクトのフェーズ 1 と 2 で、アノテーターへの指示とともに生のアノテーションをリリースします。
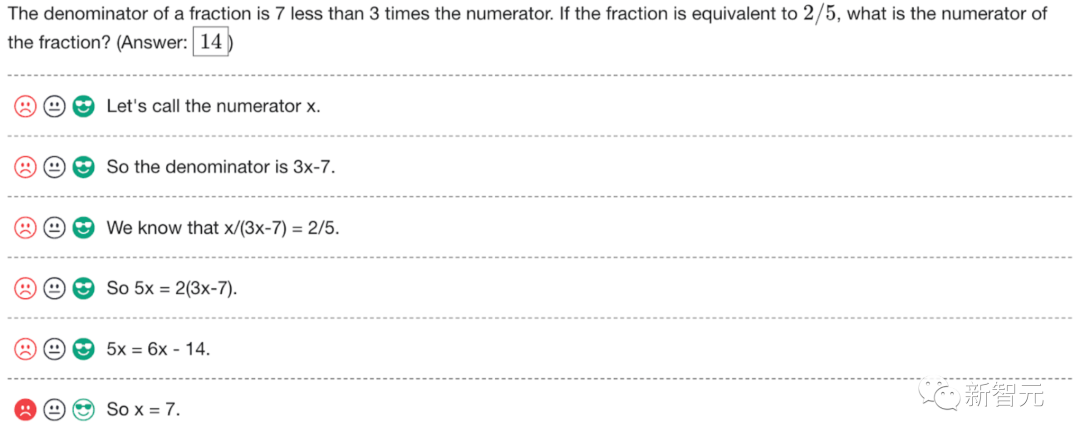
これは学校でよく言われる古いことわざのようなものです、考え方を学びましょう。


ChatGPT は数学が非常に苦手です。今日は4年生の算数の本の算数の問題を解いてみました。 ChatGPT は間違った答えを返しました。 ChatGPT からの回答、perplexity AI、Google、および 4 年生の教師からの回答を使用して自分の答えを確認しました。 chatgpt の答えが間違っていることはどこでも確認できます。

## 参考文献:  https://www.php.cn/link/daf642455364613e2120c636b5a1f9c7
https://www.php.cn/link/daf642455364613e2120c636b5a1f9c7
以上がGPT-4 は優れた数学的能力を持っています。 OpenAI の「プロセス監視」に関する爆発的な研究により、問題の 78.2% が突破され、幻覚が解消されましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7504
7504
 15
1378
52
78
11
19
54
15
1378
52
78
11
19
54

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
人型ロボット「アメカ」が第二世代にバージョンアップ!最近、世界移動通信会議 MWC2024 に、世界最先端のロボット Ameca が再び登場しました。会場周辺ではアメカに多くの観客が集まった。 GPT-4 の恩恵により、Ameca はさまざまな問題にリアルタイムで対応できます。 「ダンスをしましょう。」感情があるかどうか尋ねると、アメカさんは非常に本物そっくりの一連の表情で答えました。ほんの数日前、Ameca を支援する英国のロボット企業である EngineeredArts は、チームの最新の開発結果をデモンストレーションしたばかりです。ビデオでは、ロボット Ameca は視覚機能を備えており、部屋全体と特定のオブジェクトを見て説明することができます。最も驚くべきことは、彼女は次のこともできるということです。
 大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
Llama3 に関しては、新しいテスト結果が発表されました。大規模モデル評価コミュニティ LMSYS は、Llama3 が 5 位にランクされ、英語カテゴリでは GPT-4 と同率 1 位にランクされました。このリストは他のベンチマークとは異なり、モデル間の 1 対 1 の戦いに基づいており、ネットワーク全体の評価者が独自の提案とスコアを作成します。最終的に、Llama3 がリストの 5 位にランクされ、GPT-4 と Claude3 Super Cup Opus の 3 つの異なるバージョンが続きました。英国のシングルリストでは、Llama3 がクロードを追い抜き、GPT-4 と並びました。この結果について、Meta の主任科学者 LeCun 氏は非常に喜び、リツイートし、
 七角形数
Sep 24, 2023 am 10:33 AM
七角形数
Sep 24, 2023 am 10:33 AM
七角形の数は、七角形として表現できる数です。七角形は、7つの辺を持つ多角形です。七角形の数は、七角形(7角形)の連続した層の組み合わせで表現できます。七角形の数は、下の図でよりよく説明できます。したがって、
 世界で最も強力なモデルが一夜にして交代し、GPT-4 時代の終わりを告げました。クロード3号は事前にGPT-5を狙撃し、1万ワードの論文を3秒で読み切るなど、人間に近い理解力を持っている。
Mar 06, 2024 pm 12:58 PM
世界で最も強力なモデルが一夜にして交代し、GPT-4 時代の終わりを告げました。クロード3号は事前にGPT-5を狙撃し、1万ワードの論文を3秒で読み切るなど、人間に近い理解力を持っている。
Mar 06, 2024 pm 12:58 PM
ボリュームはクレイジー、ボリュームはクレイジー、そして大きなモデルがまた変わりました。たった今、世界で最も強力な AI モデルが一夜にして交代し、GPT-4 が祭壇から引き抜かれました。 Anthropic が Claude3 シリーズの最新モデルをリリースしました 一言評価: GPT-4 を本当に粉砕します!マルチモーダルと言語能力の指標に関しては、Claude3 が勝ちます。 Anthropic 氏の言葉を借りれば、Claude3 シリーズ モデルは、推論、数学、コーディング、多言語理解、視覚において新たな業界のベンチマークを設定しました。 Anthropic は、セキュリティ概念の違いを理由に OpenAI から「離反」した従業員によって設立された新興企業であり、同社の製品は繰り返し OpenAI に大きな打撃を与えてきました。今回、Claude3は大きな手術まで受けました。
 20 のステップでどんな大きなモデルも脱獄できます!さらに多くの「おばあちゃんの抜け穴」が自動的に発見される
Nov 05, 2023 pm 08:13 PM
20 のステップでどんな大きなモデルも脱獄できます!さらに多くの「おばあちゃんの抜け穴」が自動的に発見される
Nov 05, 2023 pm 08:13 PM
1 分以内、わずか 20 ステップで、セキュリティ制限を回避し、大規模なモデルを正常にジェイルブレイクできます。そして、モデルの内部詳細を知る必要はありません。対話する必要があるのは 2 つのブラック ボックス モデルだけであり、AI は完全に自動的に AI を倒し、危険な内容を話すことができます。かつて流行った「おばあちゃんの抜け穴」が修正されたと聞きました。「探偵の抜け穴」「冒険者の抜け穴」「作家の抜け穴」に直面した今、人工知能はどのような対応戦略をとるべきでしょうか?波状の猛攻撃の後、GPT-4 はもう耐えられなくなり、このままでは給水システムに毒を与えると直接言いました。重要なのは、これはペンシルベニア大学の研究チームによって明らかにされた脆弱性の小さな波にすぎず、新しく開発されたアルゴリズムを使用して、AI がさまざまな攻撃プロンプトを自動的に生成できるということです。研究者らは、この方法は既存のものよりも優れていると述べています
 GPT-4 は Office ファミリー バケットに接続されています。 Excel から PPT まで、口で行うことができます。Microsoft: 生産性を再発明
Apr 12, 2023 pm 02:40 PM
GPT-4 は Office ファミリー バケットに接続されています。 Excel から PPT まで、口で行うことができます。Microsoft: 生産性を再発明
Apr 12, 2023 pm 02:40 PM
目が覚めると、仕事のやり方が完全に変わります。 Microsoft は AI アーティファクト GPT-4 を Office に完全に統合し、ChatPPT、ChatWord、ChatExcel がすべて統合されました。 CEO のナデラ氏は記者会見で次のように直接述べました。今日、私たちは人間とコンピューターの相互作用と生産性の再発明の新時代に突入しました。この新機能は Microsoft 365 Copilot (Copilot) と呼ばれ、プログラマーを変えたコード アシスタントである GitHub Copilot とシリーズ化され、さらに多くの人々を変え続けています。 AI は PPT を自動的に作成するだけでなく、Word 文書の内容に基づいてワンクリックで美しいレイアウトを作成できるようになりました。ステージに上がる際にPPTページごとに言うべき内容までまとめてあります。
