

ニューロシンボリックプログラミングの力を示す
過去数年間、私たちはTransformer ベースのモデルが登場し、自然言語処理やコンピューター ビジョンなどの多くの分野で成功裏に適用されています。この記事では、ディープ ラーニング モデル、特に Transformer をハイブリッド アーキテクチャとして表現する、つまりディープ ラーニングとシンボリック人工知能を組み合わせて表現する、簡潔で解釈可能かつスケーラブルな方法を検討します。したがって、PyNeuraLogic と呼ばれる Python 神経記号フレームワークでモデルを実装します。
シンボリック表現と深層学習を組み合わせることで、すぐに使える解釈可能性や不足している推論技術など、現在の深層学習モデルのギャップを埋めます。おそらく、カメラのメガピクセル数を増やしても必ずしもより良い写真が得られるわけではないのと同様、パラメーターの数を増やすことは、これらの望ましい結果を達成するための最も合理的な方法ではありません。
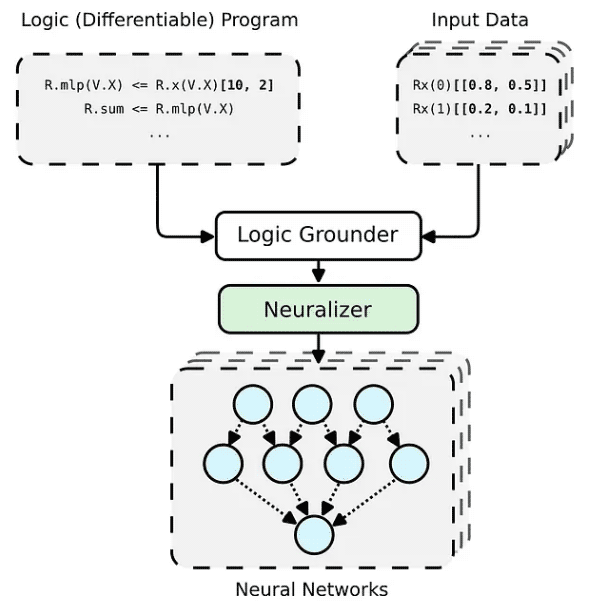
PyNeuraLogic フレームワークはロジック プログラミングに基づいており、ロジック プログラムには微分可能なパラメーターが含まれています。このフレームワークは、より小規模な構造化データ (分子など) や複雑なモデル (トランスフォーマーやグラフ ニューラル ネットワークなど) に適しています。 PyNeuraLogic は、非リレーショナル データや大規模なテンソル データには最適な選択ではありません。
フレームワークの主要なコンポーネントは、テンプレートと呼ばれる微分可能なロジック プログラムです。テンプレートは、ニューラル ネットワークの構造を抽象的な方法で定義する論理ルールで構成されます。テンプレートはモデルのアーキテクチャの青写真と考えることができます。次に、テンプレートが各入力データ インスタンスに適用され、入力サンプルに固有のニューラル ネットワークが (ベースとニューラル化を通じて) 生成されます。他の事前定義されたアーキテクチャとは完全に異なり、このプロセスはさまざまな入力サンプルに合わせて調整することができません。
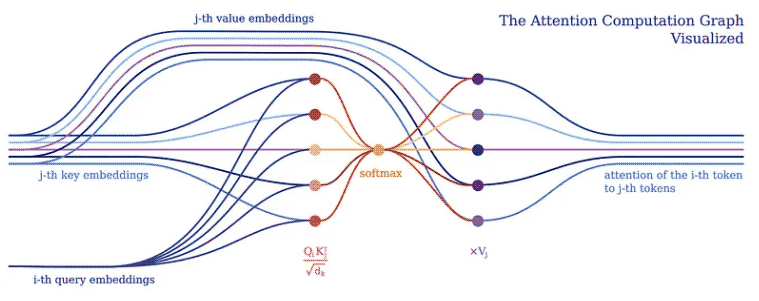
#通常、入力トークンのバッチをテンソル処理して大規模なテンソル演算として深層学習モデルを実装します。深層学習フレームワークとハードウェア (GPU など) は一般に、形状やサイズが異なる複数のテンソルではなく、より大きなテンソルを処理するように最適化されているため、これは理にかなっています。トランスフォーマーも例外ではなく、通常、単一のトークン ベクトル表現を大きな行列にバッチ処理し、そのような行列に対する演算としてモデルを表します。ただし、このような実装では、Transformer のアテンション メカニズムで明らかなように、個々の入力トークンが互いにどのように関連しているかが隠蔽されます。
アテンション メカニズムは、すべての Transformer モデルの中核を形成します。具体的には、そのクラシック バージョンでは、いわゆるマルチヘッド スケーリング ドット積アテンションを使用します。 (わかりやすくするために) ヘッダーを使用して、スケーリングされたドット積アテンションを単純なロジック プログラムに分解してみましょう。
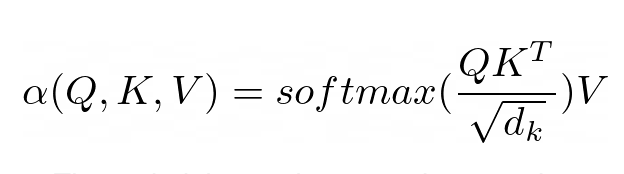
注目の目的は、ネットワークが入力のどの部分に注目すべきかを決定することです。実装の際は、重み付けされた計算値 V に注意する必要があります。重みは、入力キー K とクエリ Q の適合性を表します。この特定のバージョンでは、重みは、クエリ Q とクエリ キー K の内積を入力特徴ベクトル次元 d_k の平方根で割ったソフトマックス関数によって計算されます。
(R.weights(V.I, V.J) <= (R.d_k, R.k(V.J).T, R.q(V.I))) | [F.product, F.softmax_agg(agg_terms=[V.J])], (R.attention(V.I) <= (R.weights(V.I, V.J), R.v(V.J)) | [F.product]
PyNeuraLogic では、上記の論理ルールを通じてアテンション メカニズムを完全に捉えることができます。最初のルールは重みの計算を表し、次元の逆平方根と転置された j 番目のキー ベクトルと i 番目のクエリ ベクトルの積を計算します。次に、softmax 関数を使用して、考えられるすべての j を含む i の結果を集計します。
2 番目のルールは、この重みベクトルと対応する j 番目の値ベクトルの積を計算し、i 番目のトークンごとに異なる j の結果を合計します。
トレーニングと評価中に、入力トークンが参加できる内容を制限することがよくあります。たとえば、マーカーを制限して先を読み、今後の単語に焦点を当てたいと考えています。 PyTorch などの一般的なフレームワークは、マスキングによってこれを実現します。つまり、スケーリングされたドット積の結果の要素のサブセットを非常に小さい負の数に設定します。これらの数値は、softmax 関数が対応するタグ ペアの重みを強制的にゼロに設定することを指定します。
(R.weights(V.I, V.J) <= (
R.d_k, R.k(V.J).T, R.q(V.I), R.special.leq(V.J, V.I)
)) | [F.product, F.softmax_agg(agg_terms=[V.J])],これは、シンボルにボディ関係の制約を追加することで簡単に実現できます。重みを計算するために、i 番目のインジケーターが j 番目のインジケーター以上になるように制約します。マスクとは対照的に、必要なスケーリングされたドット積のみを計算します。
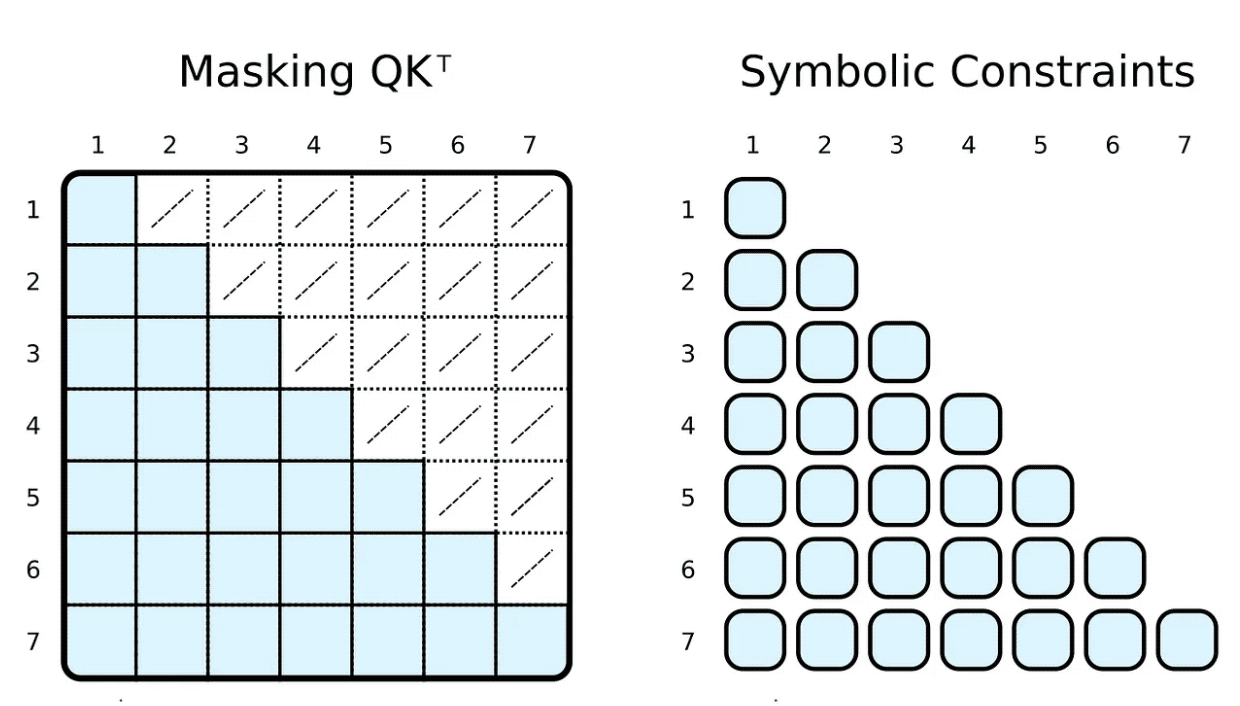
もちろん、シンボリックな「マスキング」は完全に任意のものにすることができます。ほとんどの人は、スパース トランスフォーマー ベースの GPT-3⁴ や、ChatGPT などのそのアプリケーションについて聞いたことがあるでしょう。 ⁵ スパーストランスフォーマーのアテンション (ストライドバージョン) には 2 種類のアテンションヘッドがあります:
一个只关注前 n 个标记 (0 ≤ i − j ≤ n)
一个只关注每第 n 个前一个标记 ((i − j) % n = 0)
两种类型的头的实现都只需要微小的改变(例如,对于 n = 5)。
(R.weights(V.I, V.J) <= (
R.d_k, R.k(V.J).T, R.q(V.I),
R.special.leq(V.D, 5), R.special.sub(V.I, V.J, V.D),
)) | [F.product, F.softmax_agg(agg_terms=[V.J])],(R.weights(V.I, V.J) <= (
R.d_k, R.k(V.J).T, R.q(V.I),
R.special.mod(V.D, 5, 0), R.special.sub(V.I, V.J, V.D),
)) | [F.product, F.softmax_agg(agg_terms=[V.J])],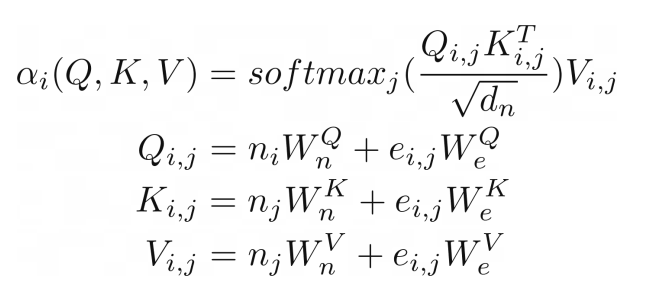
我们可以进一步推进,将类似图形输入的注意力概括到关系注意力的程度。⁶ 这种类型的注意力在图形上运行,其中节点只关注它们的邻居(由边连接的节点)。结果是节点向量嵌入和边嵌入的键 K、查询 Q 和值 V 相加。
(R.weights(V.I, V.J) <= (R.d_k, R.k(V.I, V.J).T, R.q(V.I, V.J))) | [F.product, F.softmax_agg(agg_terms=[V.J])], (R.attention(V.I) <= (R.weights(V.I, V.J), R.v(V.I, V.J)) | [F.product], R.q(V.I, V.J) <= (R.n(V.I)[W_qn], R.e(V.I, V.J)[W_qe]), R.k(V.I, V.J) <= (R.n(V.J)[W_kn], R.e(V.I, V.J)[W_ke]), R.v(V.I, V.J) <= (R.n(V.J)[W_vn], R.e(V.I, V.J)[W_ve]),
在我们的示例中,这种类型的注意力与之前展示的点积缩放注意力几乎相同。唯一的区别是添加了额外的术语来捕获边缘。将图作为注意力机制的输入似乎很自然,这并不奇怪,因为 Transformer 是一种图神经网络,作用于完全连接的图(未应用掩码时)。在传统的张量表示中,这并不是那么明显。
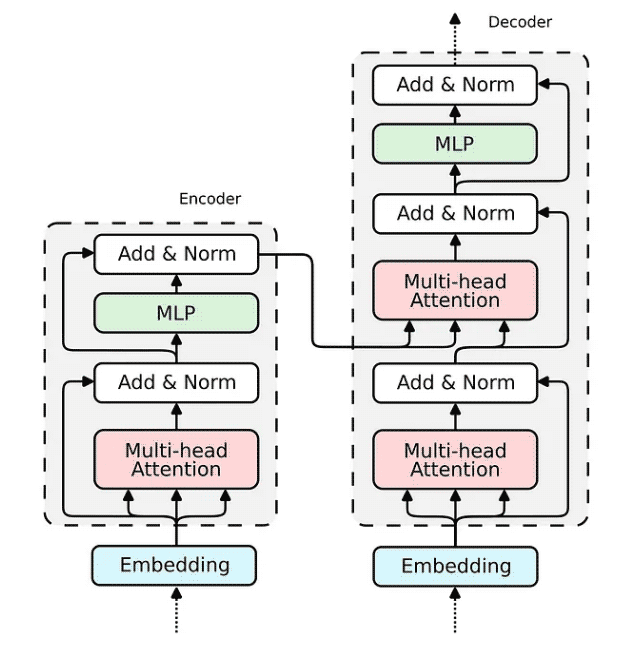
现在,当我们展示 Attention 机制的实现时,构建整个 transformer 编码器块的缺失部分相对简单。
如何在 Relational Attention 中实现嵌入已经为我们所展现。对于传统的 Transformer,嵌入将非常相似。我们将输入向量投影到三个嵌入向量中——键、查询和值。
R.q(V.I) <= R.input(V.I)[W_q], R.k(V.I) <= R.input(V.I)[W_k], R.v(V.I) <= R.input(V.I)[W_v],
查询嵌入通过跳过连接与注意力的输出相加。然后将生成的向量归一化并传递到多层感知器 (MLP)。
(R.norm1(V.I) <= (R.attention(V.I), R.q(V.I))) | [F.norm],
对于 MLP,我们将实现一个具有两个隐藏层的全连接神经网络,它可以优雅地表达为一个逻辑规则。
(R.mlp(V.I)[W_2] <= (R.norm(V.I)[W_1])) | [F.relu],
最后一个带有规范化的跳过连接与前一个相同。
(R.norm2(V.I) <= (R.mlp(V.I), R.norm1(V.I))) | [F.norm],
所有构建 Transformer 编码器所需的组件都已经被构建完成。解码器使用相同的组件;因此,其实施将是类似的。让我们将所有块组合成一个可微分逻辑程序,该程序可以嵌入到 Python 脚本中并使用 PyNeuraLogic 编译到神经网络中。
R.q(V.I) <= R.input(V.I)[W_q], R.k(V.I) <= R.input(V.I)[W_k], R.v(V.I) <= R.input(V.I)[W_v], R.d_k[1 / math.sqrt(embed_dim)], (R.weights(V.I, V.J) <= (R.d_k, R.k(V.J).T, R.q(V.I))) | [F.product, F.softmax_agg(agg_terms=[V.J])], (R.attention(V.I) <= (R.weights(V.I, V.J), R.v(V.J)) | [F.product], (R.norm1(V.I) <= (R.attention(V.I), R.q(V.I))) | [F.norm], (R.mlp(V.I)[W_2] <= (R.norm(V.I)[W_1])) | [F.relu], (R.norm2(V.I) <= (R.mlp(V.I), R.norm1(V.I))) | [F.norm],
以上がPython アーキテクチャ PyNeuraLogic ソース コード分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



