

AI の実装に対する最大の障害を解決するために、OpenAI は方法を見つけたのでしょうか?

OpenAI は、生成人工知能の「重大なナンセンス」に対する解決策を見つけたようです。
5 月 31 日、OpenAI は公式 Web サイトで、生成 AI における一般的な「幻想」やその他の一般的な問題の排除に役立つモデルをトレーニングしたと発表しました。
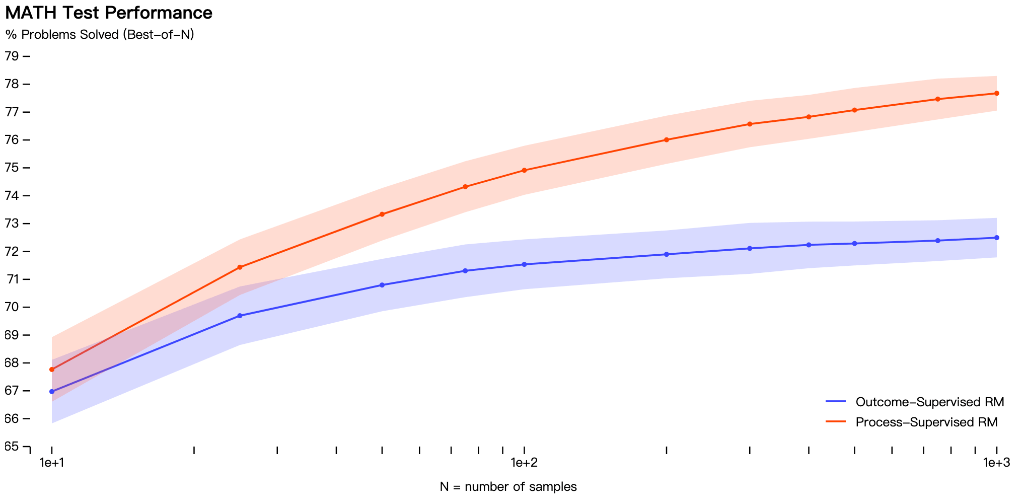
OpenAI は、報酬モデルは幻覚を検出するようにトレーニングできると述べ、報酬モデルは結果監視 (最終結果に基づいてフィードバックを提供) モデルとプロセス監視 (思考連鎖の各ステップにフィードバックを提供) モデルに分けられます。
つまり、プロセスの監視は推論の正しい各ステップに報酬を与えるのに対し、結果の監視は単純に正しい答えに報酬を与えます。
OpenAI は、対照的に、プロセス監視には重要な利点があると述べました - 人間が承認した思考連鎖を生成するようにモデルを直接トレーニングします:
OpenAI は数学的データセットで両方のモデルをテストし、プロセスの監視には、結果の監視に比べて一貫性に関する利点がいくつかあります。各ステップは正確に監視されるため、一貫した思考連鎖モデルに従った行動が評価されます。
プロセス監視は、人間が承認したプロセスにモデルが従うよう促すため、説明可能な推論を生成する可能性も高くなります。
結果のモニタリングは一貫性のないプロセスに報いる可能性がありますが、多くの場合、レビューはより困難です。
プロセス監視アプローチにより「パフォーマンスが大幅に向上」することがわかりました。
さらに、OpenAI は、この研究がまだ研究段階にある ChatGPT に適用されるまでにどれくらいの時間がかかるかについては示していません。
最初の結果は良好ですが、OpenAI は、より安全なアプローチによりアライメント税と呼ばれるパフォーマンスの低下が生じると言及しています。
現在の結果は、数学的問題を扱う場合、プロセスの監督によって調整税が発生しないことを示していますが、一般的な情報における状況は不明です。
生成AIの「幻想」
生成型 AI の登場以来、虚偽の情報の捏造や「幻覚を生成している」という告発が後を絶たず、これは現在の生成型 AI モデルの最大の問題の 1 つでもあります。
今年2月、GoogleはMicrosoftが資金提供したChatGPTに対抗してチャットボット「Bard」を急遽ローンチしたが、そのデモで常識的な誤りがあったことが判明し、Googleの株価は急落した。
AI の幻覚を引き起こす原因は数多くありますが、その 1 つは、AI プログラムをだまして誤分類させるためのデータ入力です。
たとえば、開発者はデータ (画像、テキスト、その他のタイプなど) を使用して人工知能システムをトレーニングします。データが変更されたり歪められたりすると、アプリケーションは入力を異なる方法で解釈し、誤った結果を生成します。
ChatGPT のような大規模な言語ベースのモデルでは、トランスフォーマーのデコードが間違っているため、錯覚が発生する可能性があり、言語モデルが非論理的または曖昧ではないストーリーや物語を生成する可能性があります。
以上がAI の実装に対する最大の障害を解決するために、OpenAI は方法を見つけたのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7749
7749
 15
1643
14
1397
52
1293
25
1234
29
15
1643
14
1397
52
1293
25
1234
29

 クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
この記事では、トップAIアートジェネレーターをレビューし、その機能、創造的なプロジェクトへの適合性、価値について説明します。 Midjourneyを専門家にとって最高の価値として強調し、高品質でカスタマイズ可能なアートにDall-E 2を推奨しています。
 Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
メタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
この記事では、ChatGpt、Gemini、ClaudeなどのトップAIチャットボットを比較し、自然言語の処理と信頼性における独自の機能、カスタマイズオプション、パフォーマンスに焦点を当てています。
 ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4は現在利用可能で広く使用されており、CHATGPT 3.5のような前任者と比較して、コンテキストを理解し、一貫した応答を生成することに大幅な改善を示しています。将来の開発には、よりパーソナライズされたインターが含まれる場合があります
 トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
この記事では、Grammarly、Jasper、Copy.ai、Writesonic、RytrなどのトップAIライティングアシスタントについて説明し、コンテンツ作成のためのユニークな機能に焦点を当てています。 JasperがSEOの最適化に優れているのに対し、AIツールはトーンの維持に役立つと主張します
 AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
2024年は、コンテンツ生成にLLMSを使用することから、内部の仕組みを理解することへの移行を目撃しました。 この調査は、AIエージェントの発見につながりました。これは、最小限の人間の介入でタスクと決定を処理する自律システムを処理しました。 buildin
 最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
この記事では、Google Cloud、Amazon Polly、Microsoft Azure、IBM Watson、DecriptなどのトップAI音声ジェネレーターをレビューし、機能、音声品質、さまざまなニーズへの適合性に焦点を当てています。
 AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
今週のAIの風景:進歩、倫理的考慮、規制の議論の旋風。 Openai、Google、Meta、Microsoftのような主要なプレーヤーは、画期的な新しいモデルからLEの重要な変化まで、アップデートの急流を解き放ちました
