

Redis にパフォーマンスの問題があるかどうかを判断する方法とその解決方法


Redis は通常、キャッシュ、アカウントのログイン情報、ランキングなど、ビジネス システムの重要なコンポーネントです。
Redis リクエストの遅延が増加すると、ビジネス システムの「雪崩」が発生する可能性があります。
私は独身仲人型のインターネット会社に勤めているのですが、ダブルイレブンの期間中に、注文すると彼女にプレゼントを贈るというキャンペーンを始めました。
午前 12 時を過ぎるとユーザー数が急増し、技術的な不具合が発生してユーザーが注文できなくなるなど、その時、古い火災が発生するとは誰が想像したでしょうか。
検索した結果、Redis が プールからリソースを取得できませんでした と報告していることがわかりました。
接続リソースを取得できません。クラスター内の 1 つの Redis への接続数が非常に多くなっています。
大量のトラフィックが Redis のキャッシュされた応答を失い、MySQL を直接攻撃し、最終的にはデータベースもダウンしました...
そこで、最大数にさまざまな変更が加えられました。接続数と接続待機数 (エラー メッセージが報告されました) 頻度は軽減されましたが、エラーはまだ続いています。
その後、オフライン テストを行った結果、Redis に保存されている文字データが非常に大きく、データを返すのに平均 1 秒かかったことが判明しました。
Redis の遅延が大きくなりすぎると、さまざまな問題が発生することがわかります。
今日は、Redis にパフォーマンスの問題があるかどうかを判断する方法とその解決策を分析しましょう。
Redis のパフォーマンスに問題はありますか?
最大遅延は、クライアントがコマンドを発行してから、クライアントがコマンドに対する応答を受信するまでの時間であり、通常の状況では、Redis の処理時間はマイクロ秒レベルで非常に短いです。
Redis のパフォーマンスの変動が、たとえば数秒から 10 秒以上に達した場合、Redis のパフォーマンスが低下していると判断できるのは明らかです。
一部のハードウェア構成は比較的高く、遅延が 0.6ms の場合は遅いと考えられる場合があります。ハードウェアの性能が低い場合、問題があると判断されるまでに 3 ミリ秒かかることがあります。
では、Redis が本当に遅いかどうかをどのように判断すればよいでしょうか?
したがって、現在の環境の Redis ベースライン パフォーマンスを測定する必要があります。これは、低圧で干渉がない状態でのシステムの基本パフォーマンスです。
Redis ランタイムのレイテンシがベースライン パフォーマンスの 2 倍を超えていることが判明した場合は、Redis のパフォーマンスが低下していると判断できます。
レイテンシーのベースライン測定
redis-cli コマンドには、テスト期間中の最大レイテンシー (ミリ秒単位) を監視およびカウントするための –intrinsic-latency オプションが用意されています。遅延は、Redis のベースライン パフォーマンスとして使用できます。
redis-cli --latency -h `host` -p `port`
たとえば、次のコマンドを実行します。
redis-cli --intrinsic-latency 100 Max latency so far: 4 microseconds. Max latency so far: 18 microseconds. Max latency so far: 41 microseconds. Max latency so far: 57 microseconds. Max latency so far: 78 microseconds. Max latency so far: 170 microseconds. Max latency so far: 342 microseconds. Max latency so far: 3079 microseconds. 45026981 total runs (avg latency: 2.2209 microseconds / 2220.89 nanoseconds per run). Worst run took 1386x longer than the average latency.
注: パラメータ 100 は、テストが実行される秒数です。テストを長く実行するほど、遅延のスパイクが見つかる可能性が高くなります。
通常は 100 秒間実行するのが適切ですが、これで遅延の問題を検出するには十分です。もちろん、エラーを避けるために、異なる時間に数回実行することもできます。
実行時の最大遅延は 3079 マイクロ秒であるため、ベースライン パフォーマンスは 3079 (3 ミリ秒) マイクロ秒になります。
クライアントではなく、Redis サーバー上で実行する必要があることに注意してください。このようにして、ベースライン パフォーマンスに対するネットワークの影響を回避できます。
You can connect to the server through -h host -p port . Redis パフォーマンスに対するネットワークの影響を監視する場合は、Iperf を使用してネットワーク遅延を測定できます。クライアントからサーバーへ。
ネットワーク遅延が数百ミリ秒に達する場合は、他の高トラフィック プログラムが実行されてネットワークの輻輳が発生していることを示している可能性があります。ネットワーク トラフィックの分散を調整するには、運用および保守担当者に連絡する必要があります。
遅い命令の監視
それが遅い命令であるかどうかを判断するにはどうすればよいですか?
操作の複雑さが O(N) かどうかを確認します。公式ドキュメントでは各コマンドの複雑さが紹介されているため、できるだけ O(1) および O(log N) コマンドを使用してください。
セット操作に関連する複雑さは、フルセット クエリ HGETALL、SMEMBERS、およびセット集計操作 (SORT、LREM、SUNION など) など、通常 O(N) です。
観察できる監視データはありますか?私がコードを書いたわけではないので、遅い命令を使った人がいるかどうかはわかりません。
チェックするには 2 つの方法があります:
Redis のスロー ログ機能を使用して、遅いコマンドを検出します。
遅延監視ツール。
また、自分自身 (top、htop、prstat など) を使用して、Redis メイン プロセスの CPU 消費量をすばやく確認することもできます。 CPU 使用率が高くてもトラフィックが少ない場合は、通常、遅いコマンドが使用されていることを示します。
スロー ログ機能
Redis の throwlog コマンドを使用すると、指定された実行時間を超える遅いコマンドをすぐに見つけることができます。デフォルトでは、コマンドの実行時間が 10 ミリ秒を超えている場合、ログに記録されます。
slowlog は、IO ラウンドトリップ操作やネットワーク遅延による応答の遅さなどを除いて、コマンドの実行時間のみを記録します。
ベースライン パフォーマンスに基づいて低速コマンド標準をカスタマイズし (ベースライン パフォーマンスの最大遅延の 2 倍に構成)、低速コマンドの記録をトリガーするしきい値を調整できます。
redis-cli に次のコマンドを入力して、6 ミリ秒を超えて記録するようにコマンドを構成できます:
redis-cli CONFIG SET slowlog-log-slower-than 6000
Redis.config 構成ファイルでマイクロ秒単位で設定することもできます。 。
想要查看所有执行时间比较慢的命令,可以通过使用 Redis-cli 工具,输入 slowlog get 命令查看,返回结果的第三个字段以微秒位单位显示命令的执行时间。
假如只需要查看最后 2 个慢命令,输入 slowlog get 2 即可。
示例:获取最近2个慢查询命令
127.0.0.1:6381> SLOWLOG get 2
1) 1) (integer) 6
2) (integer) 1458734263
3) (integer) 74372
4) 1) "hgetall"
2) "max.dsp.blacklist"
2) 1) (integer) 5
2) (integer) 1458734258
3) (integer) 5411075
4) 1) "keys"
2) "max.dsp.blacklist"以第一个 HGET 命令为例分析,每个 slowlog 实体共 4 个字段:
字段 1:1 个整数,表示这个 slowlog 出现的序号,server 启动后递增,当前为 6。
字段 2:表示查询执行时的 Unix 时间戳。
字段 3:表示查询执行微秒数,当前是 74372 微秒,约 74ms。
字段4表示查询命令及其参数,如果参数数量较多或较大,则只显示部分参数。hgetall max.dsp.blacklist是当前正在执行的命令。
Latency Monitoring
Redis 在 2.8.13 版本引入了 Latency Monitoring 功能,用于以秒为粒度监控各种事件的发生频率。
启用延迟监视器的第一步是设置延迟阈值(单位毫秒)。只有超过该阈值的时间才会被记录,比如我们根据基线性能(3ms)的 3 倍设置阈值为 9 ms。
可以用 redis-cli 设置也可以在 Redis.config 中设置;
CONFIG SET latency-monitor-threshold 9
工具记录的相关事件的详情可查看官方文档:https://redis.io/topics/latency-monitor
如获取最近的 latency
127.0.0.1:6379> debug sleep 2 OK (2.00s) 127.0.0.1:6379> latency latest 1) 1) "command" 2) (integer) 1645330616 3) (integer) 2003 4) (integer) 2003
事件的名称;
事件发生的最新延迟的 Unix 时间戳;
毫秒为单位的时间延迟;
该事件的最大延迟。
如何解决 Redis 变慢?
Redis 的数据读写由单线程执行,如果主线程执行的操作时间太长,就会导致主线程阻塞。
一起分析下都有哪些操作会阻塞主线程,我们又该如何解决?
网络通信导致的延迟
客户端使用 TCP/IP 连接或 Unix 域连接连接到 Redis。1 Gbit/s 网络的典型延迟约为 200 us。
redis 客户端执行一条命令分 4 个过程:
发送命令-〉 命令排队 -〉 命令执行-〉 返回结果
这个过程称为 Round trip time(简称 RTT, 往返时间),mget mset 有效节约了 RTT,但大部分命令(如 hgetall,并没有 mhgetall)不支持批量操作,需要消耗 N 次 RTT ,这个时候需要 pipeline 来解决这个问题。
Redis pipeline 将多个命令连接在一起来减少网络响应往返次数。
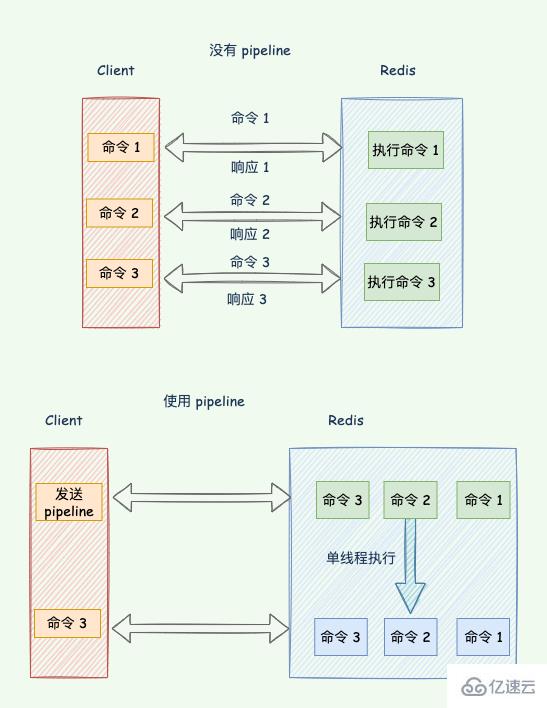
redis-pipeline
慢指令导致的延迟
根据上文的慢指令监控查询文档,查询到慢查询指令。可以通过以下两种方式解决:
在 Cluster 集群中,聚合运算等 O(N) 操作可以在 slave 节点上运行,也可以在客户端端完成。
使用高效的命令代替。采用增量迭代的方法查询数据,避免一次性查询大量数据,在此可参考SCAN、SSCAN、HSCAN和ZSCAN命令。
除此之外,生产中禁用KEYS 命令,它只适用于调试。因为它会遍历所有的键值对,所以操作延时高。
Fork 生成 RDB 导致的延迟
生成 RDB 快照,Redis 必须 fork 后台进程。fork 操作(在主线程中运行)本身会导致延迟。
Redis 使用操作系统的多进程写时复制技术 COW(Copy On Write) 来实现快照持久化,减少内存占用。

写时复制技术保证快照期间数据可修改
但 fork 会涉及到复制大量链接对象,一个 24 GB 的大型 Redis 实例需要 24 GB / 4 kB * 8 = 48 MB 的页表。
执行 bgsave 时,这将涉及分配和复制 48 MB 内存。
此外,从库加载 RDB 期间无法提供读写服务,所以主库的数据量大小控制在 2~4G 左右,让从库快速的加载完成。
内存大页(transparent huge pages)
常规的内存页是按照 4 KB 来分配,Linux 内核从 2.6.38 开始支持内存大页机制,该机制支持 2MB 大小的内存页分配。
Redis 使用了 fork 生成 RDB 做持久化提供了数据可靠性保证。
当生成 RDB 快照的过程中,Redis 采用**写时复制**技术使得主线程依然可以接收客户端的写请求。
也就是当数据被修改的时候,Redis 会复制一份这个数据,再进行修改。
采用了内存大页,生成 RDB 期间,即使客户端修改的数据只有 50B 的数据,Redis 需要复制 2MB 的大页。当写的指令比较多的时候就会导致大量的拷贝,导致性能变慢。
使用以下指令禁用 Linux 内存大页即可:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
swap:操作系统分页
当物理内存(内存条)不够用的时候,将部分内存上的数据交换到 swap 空间上,以便让系统不会因内存不够用而导致 oom 或者更致命的情况出现。
当某进程向 OS 请求内存发现不足时,OS 会把内存中暂时不用的数据交换出去,放在 SWAP 分区中,这个过程称为 SWAP OUT。
当某进程又需要这些数据且 OS 发现还有空闲物理内存时,又会把 SWAP 分区中的数据交换回物理内存中,这个过程称为 SWAP IN。
内存 swap 是操作系统里将内存数据在内存和磁盘间来回换入和换出的机制,涉及到磁盘的读写。
触发 swap 的情况有哪些呢?
对于 Redis 而言,有两种常见的情况:
Redis 使用了比可用内存更多的内存;
与 Redis 在同一机器运行的其他进程在执行大量的文件读写 I/O 操作(包括生成大文件的 RDB 文件和 AOF 后台线程),文件读写占用内存,导致 Redis 获得的内存减少,触发了 swap。
我要如何排查是否因为 swap 导致的性能变慢呢?
Linux 提供了很好的工具来排查这个问题,所以当怀疑由于交换导致的延迟时,只需按照以下步骤排查。
获取 Redis 实例 pid
$ redis-cli info | grep process_id process_id:13160
进入此进程的 /proc 文件系统目录:
cd /proc/13160
在这里有一个 smaps 的文件,该文件描述了 Redis 进程的内存布局,运行以下指令,用 grep 查找所有文件中的 Swap 字段。
$ cat smaps | egrep '^(Swap|Size)' Size: 316 kB Swap: 0 kB Size: 4 kB Swap: 0 kB Size: 8 kB Swap: 0 kB Size: 40 kB Swap: 0 kB Size: 132 kB Swap: 0 kB Size: 720896 kB Swap: 12 kB
每行 Size 表示 Redis 实例所用的一块内存大小,和 Size 下方的 Swap 对应这块 Size 大小的内存区域有多少数据已经被换出到磁盘上了。
如果 Size == Swap 则说明数据被完全换出了。
可以看到有一个 720896 kB 的内存大小有 12 kb 被换出到了磁盘上(仅交换了 12 kB),这就没什么问题。
Redis 本身会使用很多大小不一的内存块,所以,你可以看到有很多 Size 行,有的很小,就是 4KB,而有的很大,例如 720896KB。不同内存块被换出到磁盘上的大小也不一样。
敲重点了
如果 Swap 一切都是 0 kb,或者零星的 4k ,那么一切正常。
当出现百 MB,甚至 GB 级别的 swap 大小时,就表明,此时,Redis 实例的内存压力很大,很有可能会变慢。
解决方案
增加机器内存;
将 Redis 放在单独的机器上运行,避免在同一机器上运行需要大量内存的进程,从而满足 Redis 的内存需求;
增加 Cluster 集群的数量分担数据量,减少每个实例所需的内存。
AOF 和磁盘 I/O 导致的延迟
为了保证数据可靠性,Redis 使用 AOF 和 RDB 快照实现快速恢复和持久化。
可以使用 appendfsync 配置将 AOF 配置为以三种不同的方式在磁盘上执行 write 或者 fsync (可以在运行时使用 CONFIG SET命令修改此设置,比如:redis-cli CONFIG SET appendfsync no)。
no:Redis 不执行 fsync,唯一的延迟来自于 write 调用,write 只需要把日志记录写到内核缓冲区就可以返回。
everysec:Redis 每秒执行一次 fsync。使用后台子线程异步完成 fsync 操作。最多丢失 1s 的数据。
always:每次写入操作都会执行 fsync,然后用 OK 代码回复客户端(实际上 Redis 会尝试将同时执行的许多命令聚集到单个 fsync 中),没有数据丢失。建议使用能够快速执行 fsync 并搭配快速的磁盘的文件系统实现,因为在这种模式下性能通常非常低。
我们通常将 Redis 用于缓存,数据丢失完全恶意从数据获取,并不需要很高的数据可靠性,建议设置成 no 或者 everysec。
除此之外,避免 AOF 文件过大, Redis 会进行 AOF 重写,生成缩小的 AOF 文件。
可以把配置项 no-appendfsync-on-rewrite设置为 yes,表示在 AOF 重写时,不进行 fsync 操作。
也就是说,Redis 实例把写命令写到内存后,不调用后台线程进行 fsync 操作,就直接返回了。
expires 淘汰过期数据
Redis 有两种方式淘汰过期数据:
惰性删除:当接收请求的时候发现 key 已经过期,才执行删除;
定时删除:每 100 毫秒删除一些过期的 key。
定时删除的算法如下:
随机采样 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP个数的 key,删除所有过期的 key;
如果发现还有超过 25% 的 key 已过期,则执行步骤一。
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP默认设置为 20,每秒执行 10 次,删除 200 个 key 问题不大。
2 番目の項目がトリガーされると、Redis はメモリを解放するために期限切れのデータを一貫して削除します。そして削除はブロックです。
発動条件は何ですか?
つまり、多数のキーが同じ時間パラメータを設定します。期限切れのキーの数を 25% 未満に減らすには、複数の重複排除が必要です。これらのキーは同じ 1 秒以内に大量に期限切れになります。
要するに: 多数のキーが同時に期限切れになると、パフォーマンスが変動する可能性があります。
解決策
キーのバッチが同時に期限切れになる場合は、特定のサイズ範囲内の乱数を EXPIREAT と の有効期限パラメータに追加できます。 EXPIRE. 、このようにして、キーが近い時間範囲内で確実に削除されるだけでなく、同時の有効期限切れによるプレッシャーも回避されます。
bigkey
通常、大規模なデータ、または多数のメンバーやリストを含むキーをビッグ キーと呼びます。以下では、いくつかの実際の例を使用します。大きなキーの特性を説明します:
A STRING タイプのキー、その値は 5MB (データが大きすぎます)
A A LIST 型のキー、そのリストの数は 10,000 (リストの数が多すぎます)です。
ZSET 型のキー、そのメンバーの数は 10,000 (リストの数が多すぎます)メンバーが多すぎます)
- #HASH 形式のキーには 1000 メンバーしかありませんが、これらのメンバーの値の合計サイズは 10MB です (メンバー サイズが大きすぎます)
- Redis メモリが増大し続けて OOM が発生するか、maxmemory 設定値に達して書き込みがブロックされたり、重要なキーが削除されたりします。
- Redis クラスター内の特定のノードのメモリが他のノードのメモリをはるかに上回っていますが、Redis クラスター内のデータ移行の最小粒度がキーであるため、ノード上のメモリのバランスをとることができません;
- bigkey の読み取りリクエストは帯域幅を占有しすぎ、速度が低下し、サーバー上の他のサービスに影響を与えます;
- bigkey を削除するとメイン ライブラリが発生します長時間ブロックされ、同期をトリガーする 割り込みまたはマスター/スレーブの切り替え;
bigkey を見つける
redis-rdb-tools を使用するカスタマイズされた方法で大きなキーを見つけるためのツール。解決策
大きなキーを分割するたとえば、数万のメンバーを含む HASH キーを複数の HASH キーに分割し、 Redis クラスター構造では、大きなキーの分割がノード間のメモリ バランスに重要な役割を果たす可能性があります。 大きなキーの非同期クリーンアップRedis は 4.0 以降、非ブロック的な方法で受信キーをゆっくりと段階的にクリーンアップできる UNLINK コマンドを提供しています。UNLINK を通じて、安全に削除できます。ラージ キーまたはエクストラ ラージ キーです。以上がRedis にパフォーマンスの問題があるかどうかを判断する方法とその解決方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7675
7675
 15
1393
52
1207
24
91
11
15
1393
52
1207
24
91
11

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisを使用して操作をロックするには、setnxコマンドを介してロックを取得し、有効期限を設定するために有効期限コマンドを使用する必要があります。特定の手順は次のとおりです。(1)SETNXコマンドを使用して、キー価値ペアを設定しようとします。 (2)expireコマンドを使用して、ロックの有効期限を設定します。 (3)Delコマンドを使用して、ロックが不要になったときにロックを削除します。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインツール(Redis-Cli)を使用して、次の手順を使用してRedisを管理および操作します。サーバーに接続し、アドレスとポートを指定します。コマンド名とパラメーターを使用して、コマンドをサーバーに送信します。ヘルプコマンドを使用して、特定のコマンドのヘルプ情報を表示します。 QUITコマンドを使用して、コマンドラインツールを終了します。
 Centos RedisでLUAスクリプト実行時間を構成する方法
Apr 14, 2025 pm 02:12 PM
Centos RedisでLUAスクリプト実行時間を構成する方法
Apr 14, 2025 pm 02:12 PM
Centosシステムでは、Redis構成ファイルを変更するか、Redisコマンドを使用して悪意のあるスクリプトがあまりにも多くのリソースを消費しないようにすることにより、LUAスクリプトの実行時間を制限できます。方法1:Redis構成ファイルを変更し、Redis構成ファイルを見つけます:Redis構成ファイルは通常/etc/redis/redis.confにあります。構成ファイルの編集:テキストエディター(VIやNANOなど)を使用して構成ファイルを開きます:sudovi/etc/redis/redis.conf luaスクリプト実行時間制限を設定します。
