

Mysql ロックの内部実装メカニズムは何ですか?

概要
最新のリレーショナル データベースはますます似てきていますが、実装の背後にまったく異なるメカニズムが存在する場合があります。実際に使用する場合、SQL 構文の仕様が存在するため、複数のリレーショナル データベースに慣れることは難しくありませんが、ロックの実装方法はデータベースの数だけ存在する可能性があります。
Microsoft SQL Server は、2005 年以前はページ ロックのみを提供していました。オプティミスティック同時実行性とペシミスティック同時実行性のサポートが開始されたのは 2005 バージョンになってからです。オプティミスティック モードでは、行レベルのロックを実装できます。Sql の設計ではサーバーでは、ロックは希少なリソースです。ロックの数が大きいほどオーバーヘッドが大きくなります。ロックの数が急激に増加することによる崖のようなパフォーマンスの低下を避けるために、ロックのアップグレードと呼ばれる仕組みがサポートされています。行ロックがページ ロックにアップグレードされると、同時実行パフォーマンスは元の状態に戻ります。
実際、同じデータベース内の異なる実行エンジンによるロック機能の解釈については、依然として多くの論争があります。 MyISAM はテーブル レベルのロックのみをサポートしており、同時読み取りには問題ありませんが、同時変更には一定の制限があります。 Innodb は Oracle に非常に似ており、非ロックの一貫した読み取りと行ロックのサポートを提供します。SQL Server との明らかな違いは、ロックの総数が増加しても、Innodb が支払う必要があるのは少額のコストだけであることです。
行ロックの構造
Innodb は行ロックをサポートしており、ロックの記述に特に大きなオーバーヘッドはありません。したがって、多数のロックがパフォーマンス低下を引き起こした後の救済措置として、ロック アップグレード メカニズムは必要ありません。
lock0priv.h ファイルからの抜粋では、Innodb は行ロックを次のように定義しています。
/** Record lock for a page */
struct lock_rec_t {
/* space id */
ulint space;
/* page number */
ulint page_no;
/**
* number of bits in the lock bitmap;
* NOTE: the lock bitmap is placed immediately after the lock struct
*/
ulint n_bits;
};同時実行制御は行レベルで調整できますが、ロック管理メソッドはページ単位で構成されます。の。 Innodb の設計では、スペース ID とページ番号の 2 つの必要な条件によって唯一のデータ ページを決定できます。n_bits は、ページの行ロック情報を記述するために必要なビット数を示します。
同じデータ ページ内の各レコードには、一意の連続増加シーケンス番号 heap_no が割り当てられます。レコードの特定の行がロックされているかどうかを知りたい場合は、heap_no 位置の番号がロックされているかどうかを確認するだけで済みます。ビットマップの 1 つです。ロック ビットマップはデータ ページ内のレコード数に基づいてメモリ領域を割り当てるため、明示的に定義されておらず、ページ レコードは増加し続ける可能性があるため、LOCK_PAGE_BITMAP_MARGIN サイズの領域が予約されます。
/** * Safety margin when creating a new record lock: this many extra records * can be inserted to the page without need to create a lock with * a bigger bitmap */ #define LOCK_PAGE_BITMAP_MARGIN 64
スペース ID = 20、ページ番号 = 100 のデータ ページには現在 160 レコードがあり、heap_no が 2、3、および 4 のレコードがロックされていると仮定します。その後、対応する lock_rec_t 構造体とデータがロックされます。ページは次のようになります。 説明:
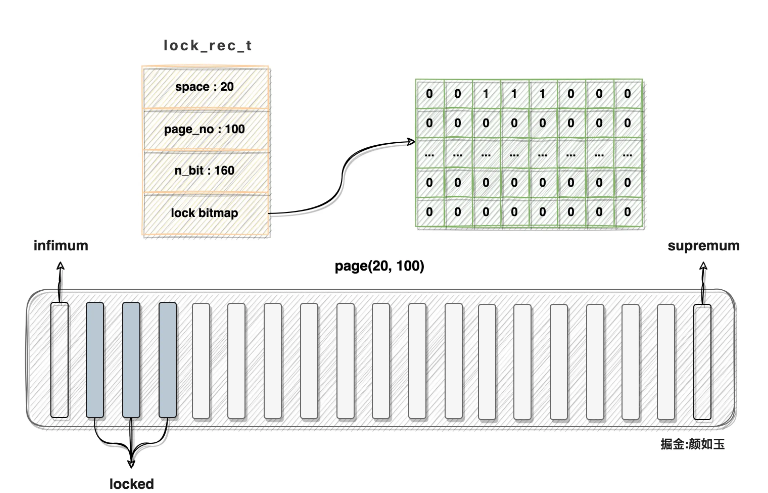
注:
メモリ内のロック ビットマップは線形に分散される必要があります。図に示した次元構造は説明を容易にするためです。
bitmap 構造体と lock_rec_t 構造体は連続したメモリであり、図中の参照関係も描画に必要です
対応するページが表示されます。ビットマップの 2 番目、3 番目、および 4 番目の位置はすべて 1 に設定されています。データ ページ行ロックの記述によって消費されるメモリは、知覚の観点からは非常に限られています。具体的にはどれくらいの割合を占めているのでしょうか?計算できます:
160 / 8 8 1 = 29バイト。
160 レコードは 160 ビットに対応します
8 は 64 ビットを予約する必要があるためです
1これは、ソース コードで 1 バイトが予約されているためです。
結果の値が小さい問題を回避するために、ここでさらに 1 が追加されます。これにより、整数の除算によって引き起こされるエラーを回避できます。 161 レコードがある場合、それが 1 でない場合、計算された 20 バイトでは、すべてのレコードのロック情報を記述するのに十分ではありません (予約ビットを使用しない場合)。
lock0priv.h ファイルからの抜粋:
/* lock_rec_create函数代码片段 */
n_bits = page_dir_get_n_heap(page) + LOCK_PAGE_BITMAP_MARGIN;
n_bytes = 1 + n_bits / 8;
/* 注意这里是分配的连续内存 */
lock = static_cast<lock_t*>(
mem_heap_alloc(trx->lock.lock_heap, sizeof(lock_t) + n_bytes)
);
/**
* Gets the number of records in the heap.
* @return number of user records
*/
UNIV_INLINE ulint page_dir_get_n_heap(const page_t* page)
{
return(page_header_get_field(page, PAGE_N_HEAP) & 0x7fff);
}テーブル ロックの構造
Innodb はテーブル ロックもサポートしています。テーブル ロックは、意図的なロックと自動ロックの 2 つのカテゴリに分類できます。インクリメント ロック データ構造は次のように定義されます:
lock0priv.h ファイルからの抜粋
struct lock_table_t {
/* database table in dictionary cache */
dict_table_t* table;
/* list of locks on the same table */
UT_LIST_NODE_T(lock_t) locks;
};ut0lst.h ファイルからの抜粋
struct ut_list_node {
/* pointer to the previous node, NULL if start of list */
TYPE* prev;
/* pointer to next node, NULL if end of list */
TYPE* next;
};
#define UT_LIST_NODE_T(TYPE) ut_list_node<TYPE>トランザクションにおけるロックの説明
上記のlock_rec_t、lock_table_t 構造は別定義です トランザクション内でロックが生成されるため、各トランザクションに対応する行ロックとテーブルロックは対応するロック構造を持つことになります その定義は以下の通りです
lock0priv.h ファイルからの抜粋
/** Lock struct; protected by lock_sys->mutex */
struct lock_t {
/* transaction owning the lock */
trx_t* trx;
/* list of the locks of the transaction */
UT_LIST_NODE_T(lock_t) trx_locks;
/**
* lock type, mode, LOCK_GAP or LOCK_REC_NOT_GAP,
* LOCK_INSERT_INTENTION, wait flag, ORed
*/
ulint type_mode;
/* hash chain node for a record lock */
hash_node_t hash;
/*!< index for a record lock */
dict_index_t* index;
/* lock details */
union {
/* table lock */
lock_table_t tab_lock;
/* record lock */
lock_rec_t rec_lock;
} un_member;
};lock_t は各トランザクションの各ページ (またはテーブル) に基づいて定義されますが、トランザクションには複数のページが含まれることが多いため、リンク リスト trx_locksトランザクションに関連するすべてのロック情報を連結するために必要です。実際のシナリオでは、トランザクションに基づいてすべてのロック情報をクエリすることに加えて、行レコードがロックされているかどうかをシステムが迅速かつ効率的に検出できる必要もあります。したがって、行レコードのロック情報のクエリをサポートするには、グローバル変数が必要です。 Innodb は、次のように定義されたハッシュ テーブルを選択しました。
lock0lock.h ファイルから抽出
/** The lock system struct */
struct lock_sys_t {
/* Mutex protecting the locks */
ib_mutex_t mutex;
/* 就是这里: hash table of the record locks */
hash_table_t* rec_hash;
/* Mutex protecting the next two fields */
ib_mutex_t wait_mutex;
/**
* Array of user threads suspended while waiting forlocks within InnoDB,
* protected by the lock_sys->wait_mutex
*/
srv_slot_t* waiting_threads;
/*
* highest slot ever used in the waiting_threads array,
* protected by lock_sys->wait_mutex
*/
srv_slot_t* last_slot;
/**
* TRUE if rollback of all recovered transactions is complete.
* Protected by lock_sys->mutex
*/
ibool rollback_complete;
/* Max wait time */
ulint n_lock_max_wait_time;
/**
* Set to the event that is created in the lock wait monitor thread.
* A value of 0 means the thread is not active
*/
os_event_t timeout_event;
/* True if the timeout thread is running */
bool timeout_thread_active;
};関数 lock_sys_create は、データベースの起動時に lock_sys_t 構造を初期化する役割を果たします。 srv_lock_table_size 変数は、rec_hash 内のハッシュ スロットの数のサイズを決定します。 rec_hash ハッシュ テーブルのキー値は、スペース ID とページのページ番号を使用して計算されます。
lock0lock.ic、ut0rnd.ic ファイルからの抜粋
/**
* Calculates the fold value of a page file address: used in inserting or
* searching for a lock in the hash table.
*
* @return folded value
*/
UNIV_INLINE ulint lock_rec_fold(ulint space, ulint page_no)
{
return(ut_fold_ulint_pair(space, page_no));
}
/**
* Folds a pair of ulints.
*
* @return folded value
*/
UNIV_INLINE ulint ut_fold_ulint_pair(ulint n1, ulint n2)
{
return (
(
(((n1 ^ n2 ^ UT_HASH_RANDOM_MASK2) << 8) + n1)
^ UT_HASH_RANDOM_MASK
)
+ n2
);
}これは、特定の行がロックされているかどうかを直接知る方法を提供する方法がないことを意味します。代わりに、まずスペースが配置されているページからスペース ID とページ番号を取得し、lock_rec_fold 関数を通じてキー値を取得し、次にハッシュ クエリを通じて lock_rec_t を取得し、次に heap_no に従ってビット マップをスキャンして、最終的にロック情報。 lock_rec_get_first 関数は上記のロジックを実装します。
这里返回的其实是lock_t对象,摘自lock0lock.cc文件
/**
* Gets the first explicit lock request on a record.
*
* @param block : block containing the record
* @param heap_no : heap number of the record
*
* @return first lock, NULL if none exists
*/
UNIV_INLINE lock_t* lock_rec_get_first(const buf_block_t* block, ulint heap_no)
{
lock_t* lock;
ut_ad(lock_mutex_own());
for (lock = lock_rec_get_first_on_page(block); lock;
lock = lock_rec_get_next_on_page(lock)
) {
if (lock_rec_get_nth_bit(lock, heap_no)) {
break;
}
}
return(lock);
}以页面为粒度进行锁维护并非最直接有效的方式,它明显是时间换空间,不过这种设计使得锁开销很小。某一事务对任一行上锁的开销都是一样的,锁数量的上升也不会带来额外的内存消耗。
对应每个事务的内存对象trx_t中,包含了该事务的锁信息链表和等待的锁信息。因此存在如下两种途径对锁进行查询:
根据事务: 通过trx_t对象的trx_locks链表,再通过lock_t对象中的trx_locks遍历可得某事务持有、等待的所有锁信息。
根据记录: 根据记录所在的页,通过space id、page number在lock_sys_t结构中定位到lock_t对象,扫描bitmap找到heap_no对应的bit位。
上述各种数据结构,对其整理关系如下图所示:
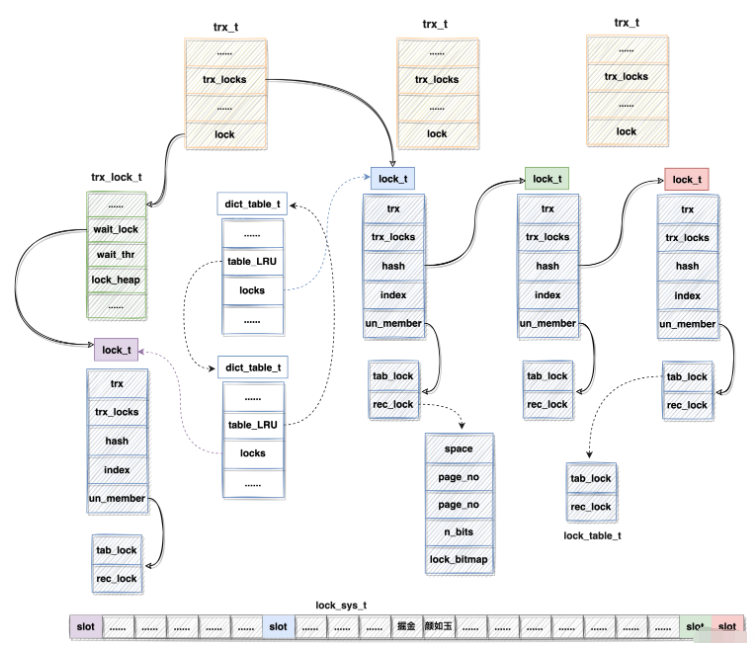
注:
lock_sys_t中的slot颜色与lock_t颜色相同则表明lock_sys_t slot持有lock_t 指针信息,实在是没法连线,不然图很混乱
以上がMysql ロックの内部実装メカニズムは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7651
7651
 15
1392
52
91
11
36
110
15
1392
52
91
11
36
110

 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerでMySQLを起動するプロセスは、次の手順で構成されています。MySQLイメージをプルしてコンテナを作成および起動し、ルートユーザーパスワードを設定し、ポート検証接続をマップしてデータベースを作成し、ユーザーはすべての権限をデータベースに付与します。
