

前回の記事では、LangChain の基礎知識をご紹介しました。まだ見ていない方は、ここをクリックしてご覧ください。今日は、LangChain の最初の非常に重要なコンポーネント モデルである Model を紹介します。
ここで言及されているモデルは、OpenAI のような言語モデルではなく、LangChain のモデル コンポーネントを指していることに注意してください。LangChain にモデル コンポーネントがある理由は、業界には言語モデルが多すぎるためです。 OpenAI 社 言語モデルに加えて、他にも多くのモデルがあります。
LangChain には、LLM ラージ言語モデル、Chat Model チャット モデル、およびテキスト埋め込みモデル Text Embedding Models の 3 種類のモデル コンポーネントがあります。
最も基本的なモデル コンポーネントとして、LLM は文字列の入出力のみをサポートしており、ほとんどのシナリオでニーズを満たすことができます。 Colab([https://colab.research.google.com)] で Python コードを直接記述することができます。
次のようなケースです。最初に依存関係をインストールしてから実行します。次のコード。
pip install openaipip install langchain
import os# 配置OpenAI 的 API KEYos.environ["OPENAI_API_KEY"] ="sk-xxx"# 从 LangChain 中导入 OpenAI 的模型from langchain.llms import OpenAI# 三个参数分别代表OpenAI 的模型名称,执行的次数和随机性,数值越大越发散llm = OpenAI(model_name="text-davinci-003", n=2, temperature=0.3)llm.generate(["给我讲一个故事", "给我讲一个笑话"])
実行結果は次のとおりです
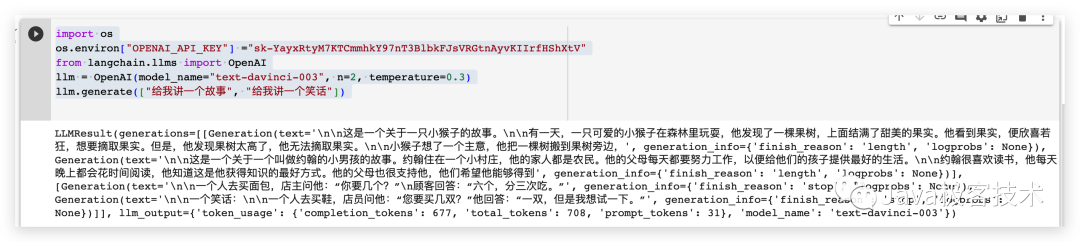
チャット モデルは、 LLM モデル。チャット モデル コンポーネント間の入出力が LLM モデルよりも構造化されているだけです。入出力パラメータのタイプは単純な文字列ではなく、チャット モデルです。一般的に使用されるチャット モデル タイプには、次の
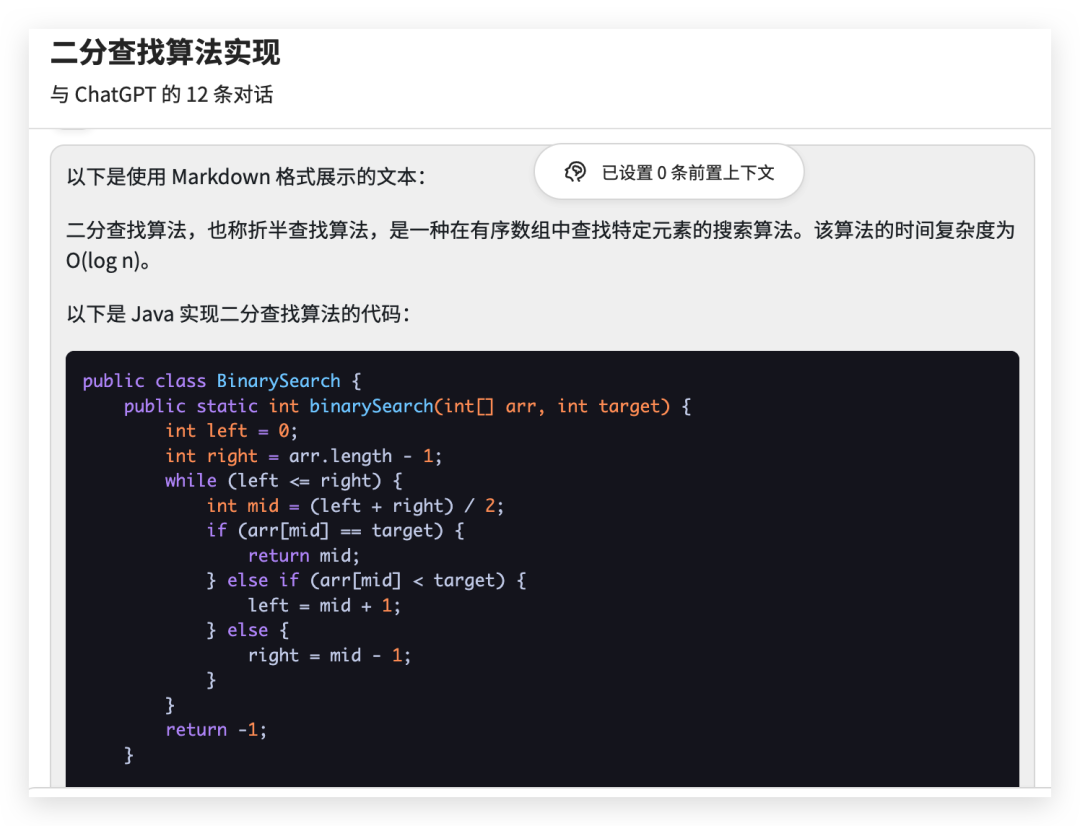
from langchain.chat_models import ChatOpenAIfrom langchain.schema import (AIMessage,HumanMessage,SystemMessage)chat = ChatOpenAI(temperature=0)messages = [SystemMessage(cnotallow="返回的数据markdown 语法进行展示,代码使用代码块包裹"),HumanMessage(cnotallow="用 Java 实现一个二分查找算法")]print(chat(messages))
生成されるコンテンツ文字列形式は次のとおりです
半検索アルゴリズムは、順序付けされた配列内の特定の要素を見つけるために使用される検索です。 、二分探索アルゴリズムとも呼ばれます。このアルゴリズムの時間計算量は O(log n) です。 \n\n次は、バイナリ検索アルゴリズムを実装する Java のコードです。\n\njava\npublic class BinarySearch {\n public static int binarySearch(int[] arr, int target) {\n int left = 0;\ n int right = arr.length - 1;\n while (left
コンテンツ内のコンテンツを抽出し、次のようなマークダウン構文を使用して表示します
このモデル コンポーネントを使用します。事前に設定できます。いくつかの役割を選択してから、パーソナライズされた質問と回答をカスタマイズします。
from langchain.chat_models import ChatOpenAIfrom langchain.prompts import (ChatPromptTemplate,PromptTemplate,SystemMessagePromptTemplate,AIMessagePromptTemplate,HumanMessagePromptTemplate,)from langchain.schema import (AIMessage,HumanMessage,SystemMessage)system_template="你是一个把{input_language}翻译成{output_language}的助手"system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)human_template="{text}"human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])messages = chat_prompt.format_prompt(input_language="英语", output_language="汉语", text="I love programming.")print(messages)chat = ChatOpenAI(temperature=0)print(chat(messages.to_messages()))output
messages=[SystemMessage(cnotallow='あなたは英語を中国語に翻訳するアシスタントです',Additional_kwargs= { }), HumanMessage(cnotallow='プログラミングが大好きです。',Additional_kwargs={}, example=False)] cnotallow='プログラミングが大好きです。' example=False、追加_kwargs={}
文本嵌入模型组件相对比较难理解,这个组件接收的是一个字符串,返回的是一个浮点数的列表。在 NLP 领域中 Embedding 是一个很常用的技术,Embedding 是将高维特征压缩成低维特征的一种方法,常用于自然语言处理任务中,如文本分类、机器翻译、推荐系统等。它将文本中的离散数据如单词、短语、句子等,映射为实数向量,以更好地进行神经网络处理和学习。通过 Embedding,文本数据可以被更好地表示和理解,提高了模型的表现力和泛化能力。
from langchain.embeddings import OpenAIEmbeddingsembeddings = OpenAIEmbeddings()text = "hello world"query_result = embeddings.embed_query(text)doc_result = embeddings.embed_documents([text])print(query_result)print(doc_result)
output
[-0.01491016335785389, 0.0013780705630779266, -0.018519161269068718, -0.031111136078834534, -0.02430146001279354, 0.007488010451197624,0.011340680532157421, 此处省略 .......
今天给大家介绍了一下 LangChain 的模型组件,有了模型组件我们就可以更加方便的跟各种 LLMs 进行交互了。
官方文档:https://python.langchain.com/en/latest/modules/models.html
以上がJava プログラマーは LangChain をゼロから学びます - モデルコンポーネントの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



