

Redis 整数コレクションを使用するにはどのような方法がありますか?

1. コレクションの概要
コレクションについては、誰もが STL のセットに精通していると思いますが、その基礎となる実装は赤黒ツリーです。挿入、削除、検索に関係なく、時間計算量は O(log n) です。もちろん、ハッシュ テーブルを使用してコレクションを実装すると、挿入、削除、検索はすべて O(1) に達する可能性があります。では、なぜコレクションではハッシュ テーブルではなく赤黒ツリーを使用するのでしょうか?最も可能性が高いのは、集合自体の特性に基づいていると思います (集合には、交差、和集合、差分などの独自の演算があります)。ハッシュ テーブルの場合、3 つの操作はすべて O(n) です。順序付けされていないハッシュ テーブルと比較すると、順序付けされた赤黒ツリーを使用することが重要であるため、より適切です。
2. Redis 整数セット (intset)
今日説明する整数セット (intset とも呼ばれます) は、Redis の固有のデータ構造です。その実装は赤黒ツリーでもハッシュ テーブルでもありません。これは単純な配列とメモリのエンコーディングです。整数セットは、格納されている要素が少なく (要素数の上限は、server.h の OBJ_SET_MAX_INTSET_ENTRIES マクロ定義値で 512 に定義されています)、すべて整数である場合にのみ使用されます。検索は O(log n) で、挿入と削除は両方とも O(n) です。ただし、ストレージ要素が比較的少ない場合、O(log n) と O(n) の差はそれほど大きくありませんが、Redis の整数コレクションを使用すると、赤黒ツリーやハッシュ テーブルと比較してメモリを大幅に削減できます。 . .
したがって、Redis の整数セット intset の存在は主にメモリを節約するためです。
1. intset 構造体の定義
intset 構造体は intset.h で定義されます:
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
typedef struct intset {
uint32_t encoding; /* a */
uint32_t length; /* b */
int8_t contents[]; /* c */
} intset; a) エンコーディングはエンコード方式を指定します。INTSET_ENC_INT16、INTSET_ENC_INT32 の 3 種類があります。 、および INTSET_ENC_INT64 。マクロ定義からわかるように、これら 3 つの値はそれぞれ 2、4、8 です。文字通りの意味から、これら 3 つが表現できる範囲は 16 ビット整数、32 ビット整数、および 64 ビット整数であることがわかります。
b) length には、整数コレクションの要素の数が格納されます。
c) コンテンツは整数コレクションの柔軟な配列であり、要素の型は必ずしも int8_t 型である必要はありません。内容は構造体のサイズを占有せず、整数コレクション データの最初のポインターとしてのみ機能します。整数コレクション内の要素は、内容内で昇順に配置されます。
2. エンコード方式
まず、エンコード方式の意味を理解しましょう。明確にする必要があることの 1 つは、整数のセットの場合、すべての要素のエンコーディングが一貫している必要があり (そうでない場合、各数値は intset 構造体に格納するのではなく、コードを格納する必要がある)、その後、セット全体のエンコーディングが一貫している必要があるということです。整数の最大の「絶対値」を持つセット内の数値に依存します (絶対値である理由は、整数には正の数値と負の数値が含まれるためです)。
最大の絶対値を持つ整数を介してエンコーディングを取得します。実装は次のとおりです:
static uint8_t _intsetValueEncoding(int64_t v) {
if (v < INT32_MIN || v > INT32_MAX)
return INTSET_ENC_INT64;
else if (v < INT16_MIN || v > INT16_MAX)
return INTSET_ENC_INT32;
else
return INTSET_ENC_INT16;
} このコードの意味は、整数 v が 32 ビット整数で表現できない場合、 INTSET_ENC_INT64 エンコーディングを使用する必要があります。そうでない場合は、16 ビット整数で表される場合は、INTSET_ENC_INT32 エンコーディングを使用する必要があります。それ以外の場合は、INTSET_ENC_INT16 エンコーディングを使用してください。重要なのは、2 バイトで表現できる場合は 4 バイトは必要なく、4 バイトで表現できる場合は 8 バイトは必要ないということです。
いくつかのマクロが stdint.h で次のように定義されています:
/* Minimum of signed integral types. */ # define INT16_MIN (-32767-1) # define INT32_MIN (-2147483647-1) /* Maximum of signed integral types. */ # define INT16_MAX (32767) # define INT32_MAX (2147483647)
3. エンコーディングのアップグレード
現在のエンコーディング方法では大きな桁の整数を格納できない場合、エンコーディングが必要になります。アップグレードされる予定です。たとえば、次の図に示されている 4 つの数値はすべて [-32768, 32767] の範囲内にあるため、INTSET_ENC_INT16 エンコードを使用できます。内容の配列の長さは、sizeof(int16_t) * 4 = 2 * 4 = 8 バイト (つまり、64 バイナリ ビット) です。
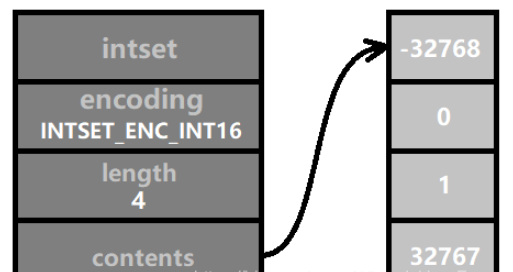
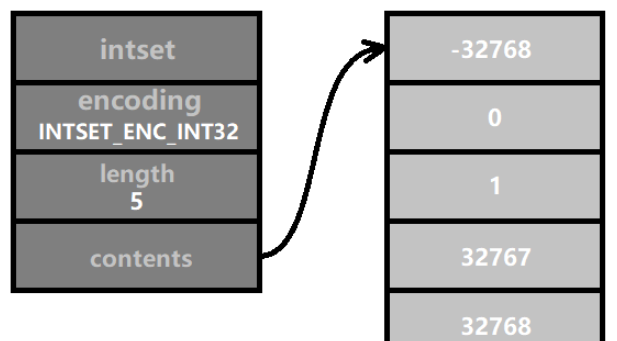
すべての整数セットを最初から INTSET_ENC_INT64 でエンコードして手間を省けば素晴らしいでしょう。その理由は、Redis が intset を設計する本来の目的はメモリを節約することであるためです。セットの要素が 16 ビット整数を超えることはないと想定されているため、64 ビット整数を使用することはメモリを 3 倍浪費することに相当します。
三、整数集合常用操作
1、创建集合
创建一个整数集合 intsetNew,实现在 intset.c 中:
intset *intsetNew(void) {
intset *is = zmalloc(sizeof(intset));
is->encoding = intrev32ifbe(INTSET_ENC_INT16);
is->length = 0;
return is;
} 初始创建的整数集合为空集合,用 zmalloc 进行内存分配后,定义编码为 INTSET_ENC_INT16,这样可以使内存尽量小。这里需要注意的是,intset 的存储直接涉及到内存编码,所以需要考虑主机的字节序问题(相关资料请参阅:字节序)。
intrev32ifbe 的意思是 int32 reversal if big endian。即 如果当前主机字节序为大端序,那么将它的内存存储进行翻转操作。简言之,intset 的所有成员存储方式都采用小端序。所以创建一个空的整数集合,内存分布如下:

了解了整数集合的内存编码以后,我们来看看它的 设置 (set)和 获取(get)。
2、元素设置
设置 的含义就是给定整数集合以及一个位置和值,将值设置到这个整数集合的对应位置上。_intsetSet 实现如下:
static void _intsetSet(intset *is, int pos, int64_t value) {
uint32_t encoding = intrev32ifbe(is->encoding); /* a */
if (encoding == INTSET_ENC_INT64) {
((int64_t*)is->contents)[pos] = value; /* b */
memrev64ifbe(((int64_t*)is->contents)+pos); /* c */
} else if (encoding == INTSET_ENC_INT32) {
((int32_t*)is->contents)[pos] = value;
memrev32ifbe(((int32_t*)is->contents)+pos);
} else {
((int16_t*)is->contents)[pos] = value;
memrev16ifbe(((int16_t*)is->contents)+pos);
}
} a) 大端序和小端序只是存储方式,encoding 在存储的时候进行了一次 intrev32ifbe 转换,取出来用的时候需要再进行一次 intrev32ifbe 转换(其实就是序列化和反序列化)。
b) 根据 encoding 的类型,将 contents 转换成指定类型的指针,然后用 pos 进行索引找到对应的内存位置,然后将 value 的值设置到对应的内存中。
c) memrev64ifbe 的实现参见 字节序 的 memrev64 函数,即将对应内存的值转换成小端序存储。
3、元素获取
获取 的含义就是给定整数集合以及一个位置,返回给定位置的元素的值。_intsetGet 实现如下:
static int64_t _intsetGetEncoded(intset *is, int pos, uint8_t enc) {
int64_t v64;
int32_t v32;
int16_t v16;
if (enc == INTSET_ENC_INT64) {
memcpy(&v64,((int64_t*)is->contents)+pos,sizeof(v64)); /* a */
memrev64ifbe(&v64); /* b */
return v64;
} else if (enc == INTSET_ENC_INT32) {
memcpy(&v32,((int32_t*)is->contents)+pos,sizeof(v32));
memrev32ifbe(&v32);
return v32;
} else {
memcpy(&v16,((int16_t*)is->contents)+pos,sizeof(v16));
memrev16ifbe(&v16);
return v16;
}
}
static int64_t _intsetGet(intset *is, int pos) {
return _intsetGetEncoded(is,pos,intrev32ifbe(is->encoding));
} a) 根据 encoding 的类型,将 contents 转换成指定类型的指针,然后用 pos 进行索引找到对应的内存位置,将内存位置上的值拷贝到临时变量中;
b) 由于是直接的内存拷贝,所以取出来的值还是小端序的,那么在大端序的主机上得到的值是不对的,所以需要再做一次 memrev64ifbe 转换将值还原。
4、元素查找
由于整数集合是有序集合,所以查找某个元素是否在整数集合中,Redis 采用的是二分查找。intsetSearch 实现如下:
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;
int64_t cur = -1;
if (intrev32ifbe(is->length) == 0) {
if (pos) *pos = 0; /* a */
return 0;
} else { /* b */
if (value > _intsetGet(is,intrev32ifbe(is->length)-1)) {
if (pos) *pos = intrev32ifbe(is->length);
return 0;
} else if (value < _intsetGet(is,0)) {
if (pos) *pos = 0;
return 0;
}
}
while(max >= min) {
mid = ((unsigned int)min + (unsigned int)max) >> 1; /* c */
cur = _intsetGet(is,mid);
if (value > cur) {
min = mid+1;
} else if (value < cur) {
max = mid-1;
} else {
break;
}
}
if (value == cur) { /* d */
if (pos) *pos = mid;
return 1;
} else {
if (pos) *pos = min;
return 0;
}
} a) 整数集合为空,返回0表示查找失败;
b) value 的值比整数集合中的最大值还大,或者比最小值还小,则返回0表示查找失败;
c) 执行二分查找,将找到的值存在 cur 中;
d) 如果找到则返回1,表示查找成功,并且将 pos 设置为 mid 并返回;如果没找到则返回一个需要插入的位置。
5、内存重分配
由于 contents 的内存是动态分配的,所以每次进行元素插入或者删除的时候,都需要重新分配内存,这个实现放在 intsetResize 中,实现如下:
static intset *intsetResize(intset *is, uint32_t len) {
uint32_t size = len*intrev32ifbe(is->encoding);
is = zrealloc(is,sizeof(intset)+size);
return is;
} encoding 本身表示字节个数,所以乘上集合个数 len 就是 contents 数组需要的总字节数了,调用 zrealloc 进行内存重分配,然后返回重新分配后的地址。
注意:zrealloc 的返回值必须返回出去,因为 intset 在进行内存重分配以后,地址可能就变了。即 is = zrealloc(is, ...) 中,此 is 非彼 is。所以,所有调用 intsetResize 的函数都需要连带的返回新的 intset 指针。
6、编码升级
编码升级一定发生在元素插入,并且插入的元素的绝对值比整数集合中的元素都大的时候,所以我们把升级后的元素插入和编码升级放在一个函数实现,名曰 intsetUpgradeAndAdd,实现如下:
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
uint8_t curenc = intrev32ifbe(is->encoding);
uint8_t newenc = _intsetValueEncoding(value);
int length = intrev32ifbe(is->length);
int prepend = value < 0 ? 1 : 0; /* a */
is->encoding = intrev32ifbe(newenc);
is = intsetResize(is,intrev32ifbe(is->length)+1); /* b */
while(length--)
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc)); /* c */
if (prepend)
_intsetSet(is,0,value);
else
_intsetSet(is,intrev32ifbe(is->length),value); /* d */
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
} a) curenc 记录升级前的编码,newenc 记录升级后的编码;
b) 将整数集合 is 的编码设置成新的编码后,进行内存重分配;
c) 获取原先内存中的数据,设置到新内存中(注意:由于两段内存空间是重叠的,而且新内存的长度一定大于原先内存,所以需要从后往前进行拷贝);
d) 当插入的值 value 为负数的时候,为了保证集合的有序性,需要插入到 contents 的头部;反之,插入到尾部;当 value 为负数时 prepend 为1,这样就可以保证在内存拷贝的时候将第 0 个位置留空。
如图展示了一个 (-32768, 0, 1, 32767) 的整数集合在插入数字 32768 后的升级的完整过程:
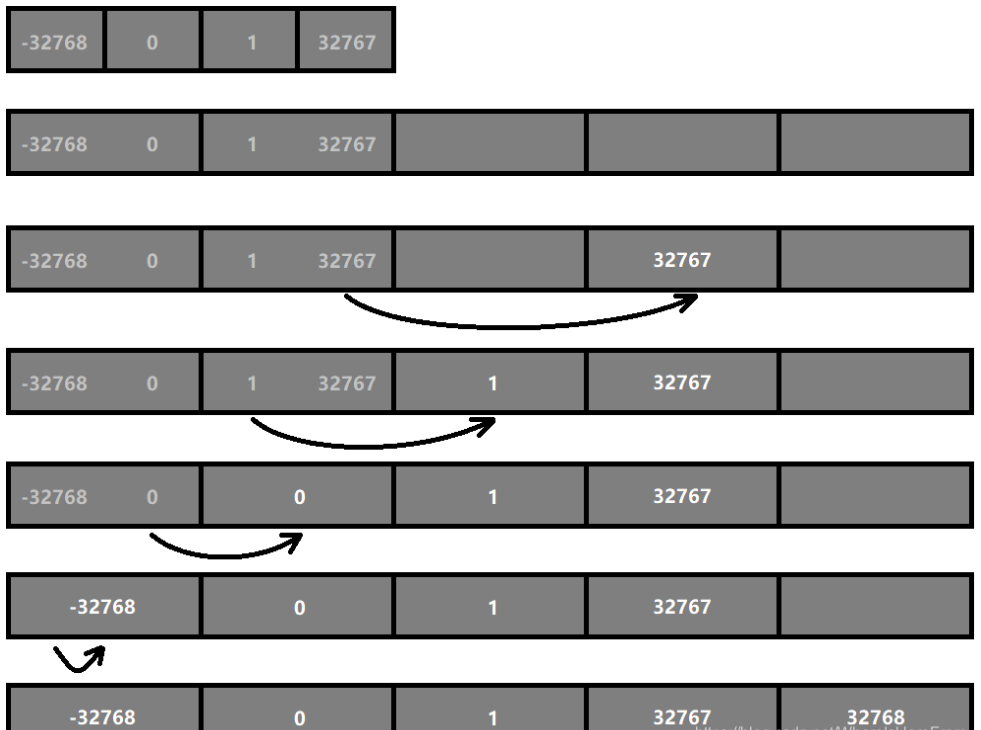
整数集合升级的时间复杂度是 O(n) 的,但是在整数集合的生命期内,升级最多发生两次(从 INTSET_ENC_INT16 到 INTSET_ENC_INT32 以及 从 INTSET_ENC_INT32 到 INTSET_ENC_INT64)。
7、内存迁移
绝大多数情况都是在执行 插入 、删除 、查找 操作。插入 和 删除 会涉及到连续内存的移动。为了实现内存移动,Redis内部实现包括intsetMoveTail函数。
static void intsetMoveTail(intset *is, uint32_t from, uint32_t to) {
void *src, *dst;
uint32_t bytes = intrev32ifbe(is->length)-from; /* a */
uint32_t encoding = intrev32ifbe(is->encoding);
if (encoding == INTSET_ENC_INT64) {
src = (int64_t*)is->contents+from;
dst = (int64_t*)is->contents+to;
bytes *= sizeof(int64_t); /* b */
} else if (encoding == INTSET_ENC_INT32) {
src = (int32_t*)is->contents+from;
dst = (int32_t*)is->contents+to;
bytes *= sizeof(int32_t);
} else {
src = (int16_t*)is->contents+from;
dst = (int16_t*)is->contents+to;
bytes *= sizeof(int16_t);
}
memmove(dst,src,bytes); /* c */
} a) 统计从 from 到结尾,有多少个元素;
b) 根据不同的编码,计算出需要拷贝的内存字节数 bytes,以及拷贝源位置 src,拷贝目标位置 dst;
c) memmove 是 string.h 中的函数:src指向的内存区域拷贝 bytes 个字节到 dst 所指向的内存区域,这个函数是支持内存重叠的;
8、元素插入
最后,讲整数集合的插入和删除,插入调用的是 intsetAdd,在 intset.c 中实现:
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
if (valenc > intrev32ifbe(is->encoding)) { /* a */
return intsetUpgradeAndAdd(is,value);
} else {
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0; /* b */
return is;
}
is = intsetResize(is,intrev32ifbe(is->length)+1); /* c */
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1); /* d */
}
_intsetSet(is,pos,value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1); /* e */
return is;
} a) 插入的数值 value 的内存编码大于现有集合的编码,直接调用 intsetUpgradeAndAdd 进行编码升级;
b) 集合元素是不重复的,如果 intsetSearch 能够找到,则将 success 置为0,表示此次插入失败;
c) 如果 intsetSearch 找不到,将 intset 进行内存重分配,即 长度 加 1。
d) pos 为 intsetSearch 过程中找到的 value 将要插入的位置,我们将 pos 以后的内存向后移动1个单位 (这里的1个单位可能是2个字节、4个字节或者8个字节,取决于当前整数集合的内存编码)。
e) 调用 _intsetSet 将 value 的值设置到 pos 的位置上,然后给成员变量 length 加 1。最后返回 intset 指针首地址,因为其间进行了 intsetResize,传入的 intset 指针和返回的有可能不是同一个了。
9、元素删除
删除元素调用的是 intsetRemove ,实现如下:
intset *intsetRemove(intset *is, int64_t value, int *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 0;
if (valenc <= intrev32ifbe(is->encoding) && intsetSearch(is,value,&pos)) { /* a */
uint32_t len = intrev32ifbe(is->length);
if (success) *success = 1;
if (pos < (len-1)) intsetMoveTail(is,pos+1,pos); /* b */
is = intsetResize(is,len-1); /* c */
is->length = intrev32ifbe(len-1);
}
return is;
} a) 当整数集合中存在 value 这个元素时才能执行删除操作;
b) 如果能通过 intsetSearch 找到元素,那么它的位置就在 pos 上,这是通过 intsetMoveTail 将内存往前挪;
c) intsetResize 重新分配内存,并且将集合长度减1;
以上がRedis 整数コレクションを使用するにはどのような方法がありますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7456
7456
 15
1375
52
77
11
14
9
15
1375
52
77
11
14
9

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
Redisはハッシュテーブルを使用してデータを保存し、文字列、リスト、ハッシュテーブル、コレクション、注文コレクションなどのデータ構造をサポートします。 Redisは、スナップショット(RDB)を介してデータを維持し、書き込み専用(AOF)メカニズムを追加します。 Redisは、マスタースレーブレプリケーションを使用して、データの可用性を向上させます。 Redisは、シングルスレッドイベントループを使用して接続とコマンドを処理して、データの原子性と一貫性を確保します。 Redisは、キーの有効期限を設定し、怠zyな削除メカニズムを使用して有効期限キーを削除します。
 鍵はRedisクエリにとってどのようにユニークですか
Apr 10, 2025 pm 07:03 PM
鍵はRedisクエリにとってどのようにユニークですか
Apr 10, 2025 pm 07:03 PM
Redisは、キーの一意性を確保するために5つの戦略を使用します。1。名前空間分離。 2。ハッシュデータ構造。 3.データ構造を設定します。 4。文字列キーの特殊文字。 5。LUAスクリプト検証。特定の戦略の選択は、データ組織、パフォーマンス、およびスケーラビリティ要件に依存します。
 Redisクラスターはどのように実装されていますか
Apr 10, 2025 pm 05:27 PM
Redisクラスターはどのように実装されていますか
Apr 10, 2025 pm 05:27 PM
Redis Clusterは、Redisインスタンスの水平拡張を可能にする分散展開モデルであり、ノード間通信、ハッシュスロット部門キースペース、ノード選挙、マスター奴隷レプリケーション、コマンドリダイレクトを通じて実装されます。ハッシュスロット:キースペースをハッシュスロットに分割して、キーの責任ノードを決定します。ノード選挙:少なくとも3つのマスターノードが必要であり、選挙メカニズムを通じて1つのアクティブマスターノードのみが保証されます。マスタースレーブレプリケーション:マスターノードはリクエストの書き込みを担当し、スレーブノードはリクエストとデータレプリケーションを読む責任があります。コマンドリダイレクト:クライアントはキーを担当するノードに接続し、ノードは誤ったリクエストをリダイレクトします。トラブルシューティング:障害検出、オフラインのマーク、および再
 Redisのバージョン番号を表示する方法
Apr 10, 2025 pm 05:57 PM
Redisのバージョン番号を表示する方法
Apr 10, 2025 pm 05:57 PM
Redisバージョン番号を表示するには、次の3つの方法を使用できます。(1)情報コマンドを入力し、(2) - versionオプションでサーバーを起動し、(3)構成ファイルを表示します。
 Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示するには、3つの方法があります。キーコマンドを使用して、指定されたパターンに一致するすべてのキーを返します。スキャンコマンドを使用してキーを繰り返し、キーのセットを返します。情報コマンドを使用して、キーの総数を取得します。
 Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインツール(Redis-Cli)を使用して、次の手順を使用してRedisを管理および操作します。サーバーに接続し、アドレスとポートを指定します。コマンド名とパラメーターを使用して、コマンドをサーバーに送信します。ヘルプコマンドを使用して、特定のコマンドのヘルプ情報を表示します。 QUITコマンドを使用して、コマンドラインツールを終了します。
 Redis Zsetの使用方法
Apr 10, 2025 pm 07:27 PM
Redis Zsetの使用方法
Apr 10, 2025 pm 07:27 PM
Redis Orderedセット(ZSET)は、並べ替えられた要素を保存し、関連するスコアでソートするために使用されます。 zsetを使用する手順には次のものがあります。1。zsetを作成します。 2。メンバーを追加します。 3.メンバースコアを取得します。 4。ランキングを取得します。 5.ランキング範囲のメンバーを取得します。 6.メンバーを削除します。 7.要素の数を取得します。 8。スコア範囲のメンバーの数を取得します。
