

反事実的因果推論に基づく Duxiaoman クォータ モデル


1. 因果推論の研究パラダイム
研究パラダイムには現在 2 つの主要な研究方向があります:
- Judea Pearl 構造モデル
- 潜在的な出力フレームワーク
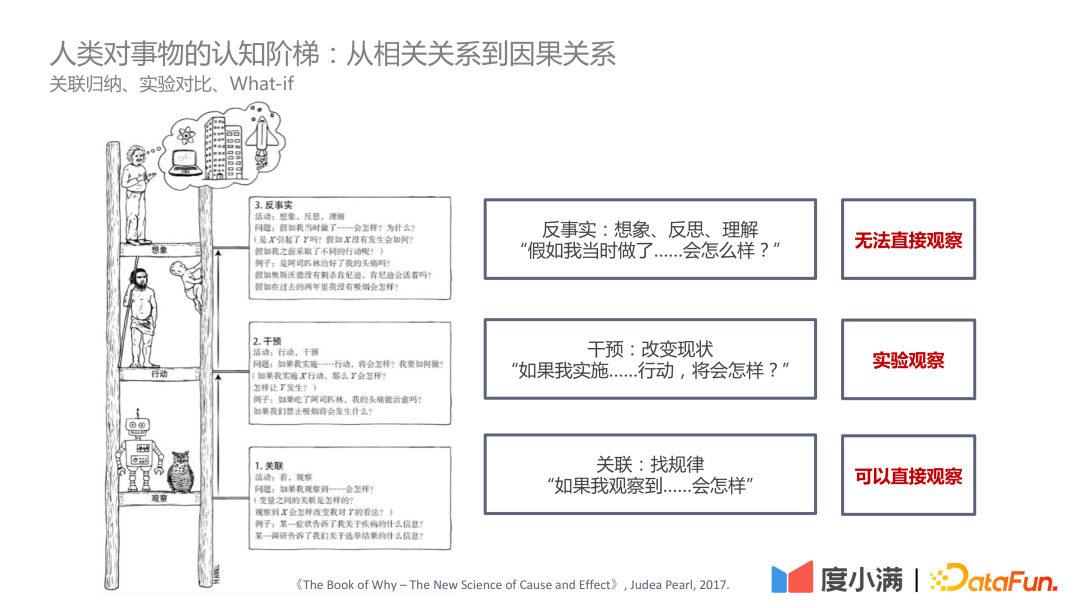
ジューデア・パール著『The Book of Why – The New Science of Cause and Effect』では、この本では次のように述べています。認知ラダーは 3 つのレベルとして配置されています:
- 最初のレベル - 相関関係: 相関関係を通じてルールを見つけます。直接観察できます。
- 第 2 レベル - 介入: 現状が変更された場合、どのようなアクションを実行する必要があり、どのような結論を導き出す必要があるかは、実験を通じて観察できます。
- #第 3 レベル - 反事実: 法律や規制などの問題により、実験的に直接観察することはできません。それをどう評価するか ATE と CATE はさらに難しい問題です。
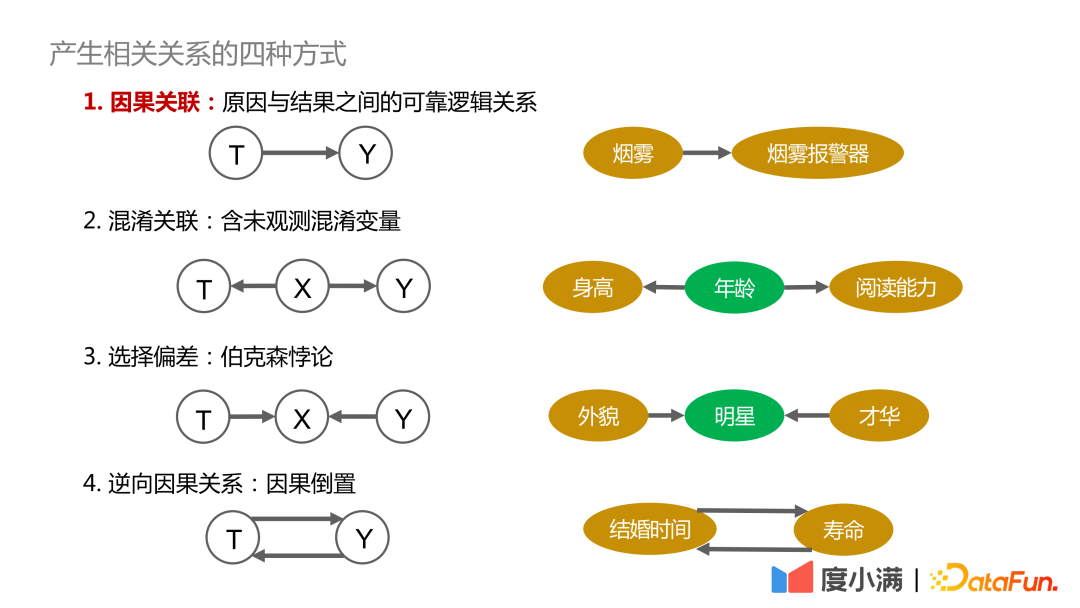
1. 原因と結果関連#: 原因と結果の間には、信頼性があり、追跡可能で、確実に依存する関係があります。たとえば、煙と煙警報器には因果関係があります。
2. 混同された相関関係 #: 身長と読解力に関連性があるかどうかなど、直接観察できない交絡変数が含まれています。変数の年齢は類似しているため、有効な結論が導き出されます;
3. 選択バイアス: 本質的にバークソンのパラドックスは、たとえば、外見と才能の関係を調査する場合、有名人の間でのみ観察すると、外見と才能が両方を持つことはできないという結論に達する可能性があります。全人類で観察した場合、容姿と才能の間には因果関係はありません。
4. 逆因果関係 #: つまり、原因と結果の逆転です。たとえば、統計は次のようになります。人間は結婚生活が長くなればなるほど、平均余命は長くなります。しかし逆に、「長生きしたければ早く結婚しなければならない」とは言えません。
#交絡因子が観察結果にどのような影響を与えるかを、ここで 2 つのケースで説明します。
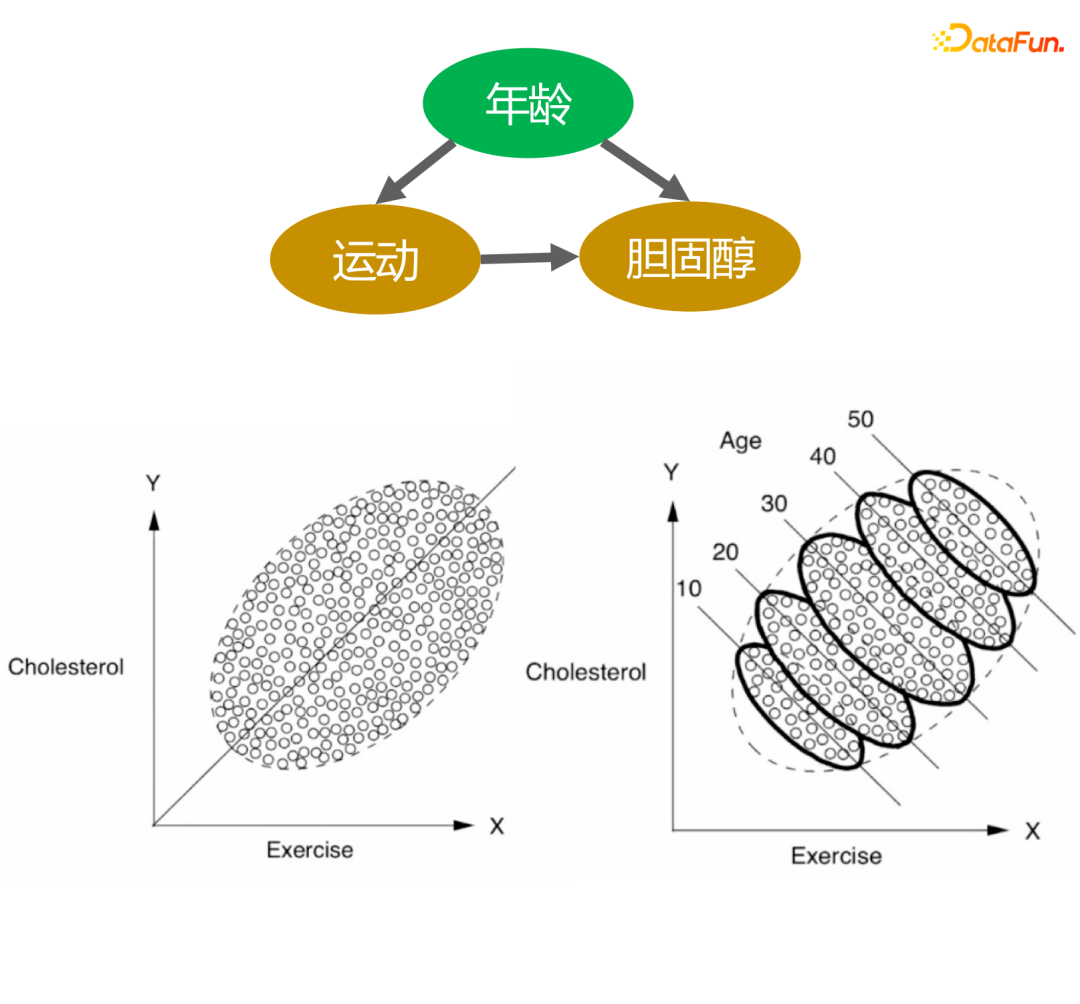
上の図は、運動量とコレステロール値の関係を示しています。左の図から、運動量が多いほどコレステロール値が高いと結論付けることができます。しかし、年齢層別を加えると、同じ年齢層別では運動量が多いほどコレステロール値は低下する。さらに、加齢とともにコレステロール値は徐々に上昇するため、この結論は私たちの知識と一致しています。
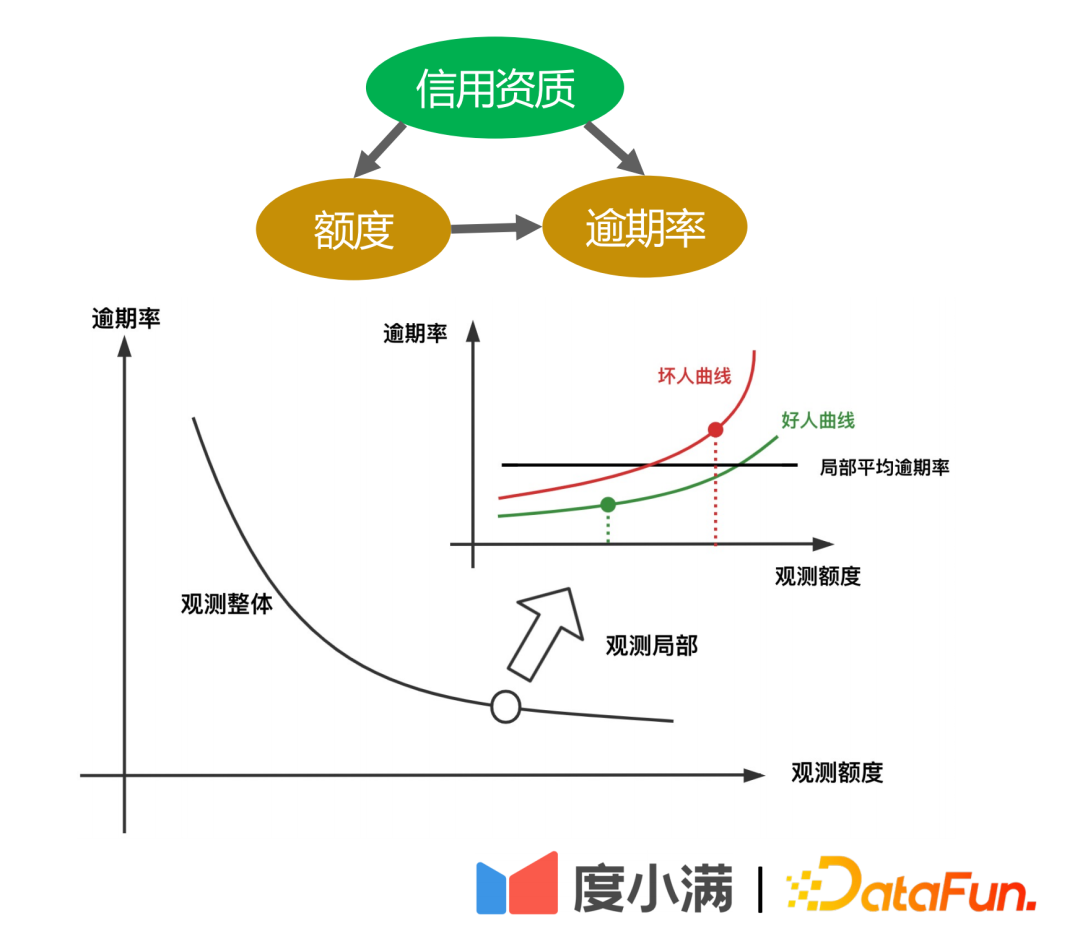
2 番目の例は、信用シナリオです。過去の統計から、所定の限度額(借入可能額)が高くなるほど延滞率が低くなることがわかります。ただし、金融分野では、まず借り手の信用度が A カードに基づいて判断され、信用度が高ければ、プラットフォームはより高い限度額を付与し、全体的な延滞率は非常に低くなります。しかし、ローカルでのランダム実験によると、同じ与信資格を持つ人々であっても、与信限度額移行曲線の変化が緩やかな人もいる一方、与信限度額移行リスクがより高い人もいる。増加すると、リスクの増加が大きくなります。
上記の 2 つのケースは、モデリングで交絡因子が無視された場合、誤った結論、さらには反対の結論が得られる可能性があることを示しています。
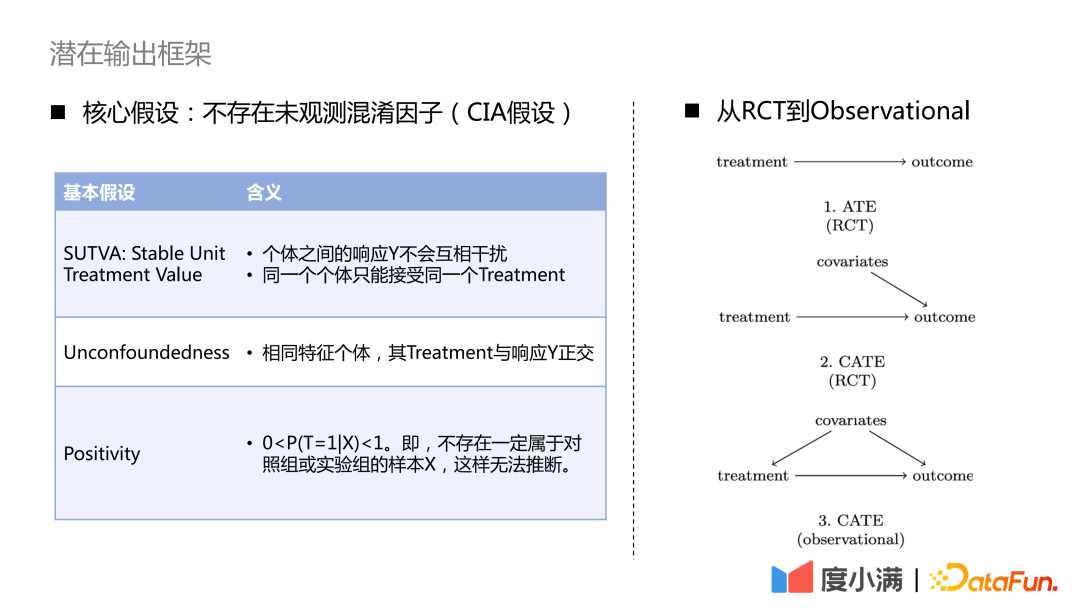
RCT ランダムサンプルから観察サンプル因果モデリングに移行するにはどうすればよいですか?
RCT サンプルの場合、ATE 指標を評価したい場合は、グループ減算または DID (差分の差) を使用できます。 CATE インジケーターを評価したい場合は、隆起モデリングを使用できます。一般的な手法には、メタ学習器、二重機械学習、コーサル フォレストなどが含まれます。ここで注意すべき 3 つの前提条件があります。SUTVA、混乱のなさ、積極性です。中心となる仮定は、観察されていない交絡因子は存在しないということです。
観察サンプルのみの場合、治療→結果の因果関係を直接求めることはできません。共変量から治療へのバックドアパス。一般的な方法は、操作変数法と反事実表現学習です。操作変数手法では、具体的なビジネスの詳細を剥ぎ取り、ビジネス変数の因果関係図を描く必要があります。反事実表現学習は、成熟した機械学習に依存して、因果関係の評価のために類似の共変量を持つサンプルを照合します。
#2. 因果推論のフレームワークの進化
1. ランダムデータから観察データへ
## 次に、因果推論のフレームワークの進化と、因果表現の学習に段階的に移行する方法を紹介します。
#一般的な Uplift モデルには、Slearner、Tlearner、Xlearner が含まれます。
#ここで、Slearner は介在する変数を 1 次元の特徴として扱います。一般的なツリー モデルでは、治療が容易に圧倒され、治療効果の推定値が小さくなることに注意してください。
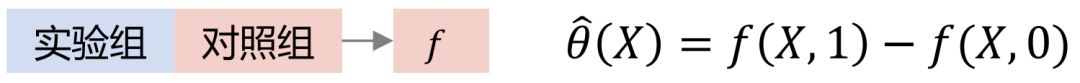
#Tlearner は治療を離散化し、グループ内の介在変数をモデル化し、各治療の予測モデルを構築して、違いがございます。サンプルサイズが小さいほど、推定される分散が大きくなることに注意することが重要です。
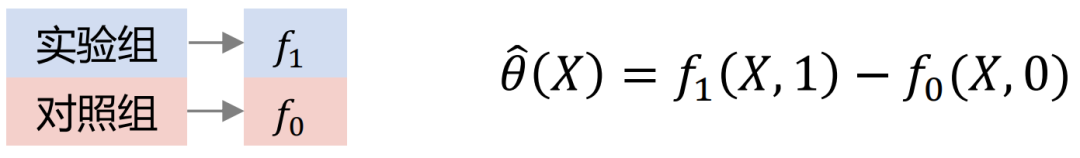
X学習者グループのクロスモデリングでは、実験グループと対照グループが個別に相互計算され、トレーニングされます。この方法は S/T-learner の利点を組み合わせていますが、欠点は、高次モデルの構造エラーが発生し、パラメーター調整の難易度が高くなるということです。
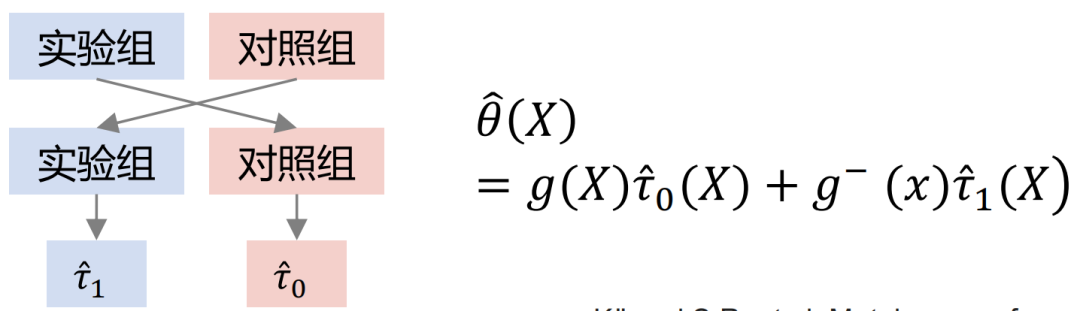
3 つのモデルの比較:
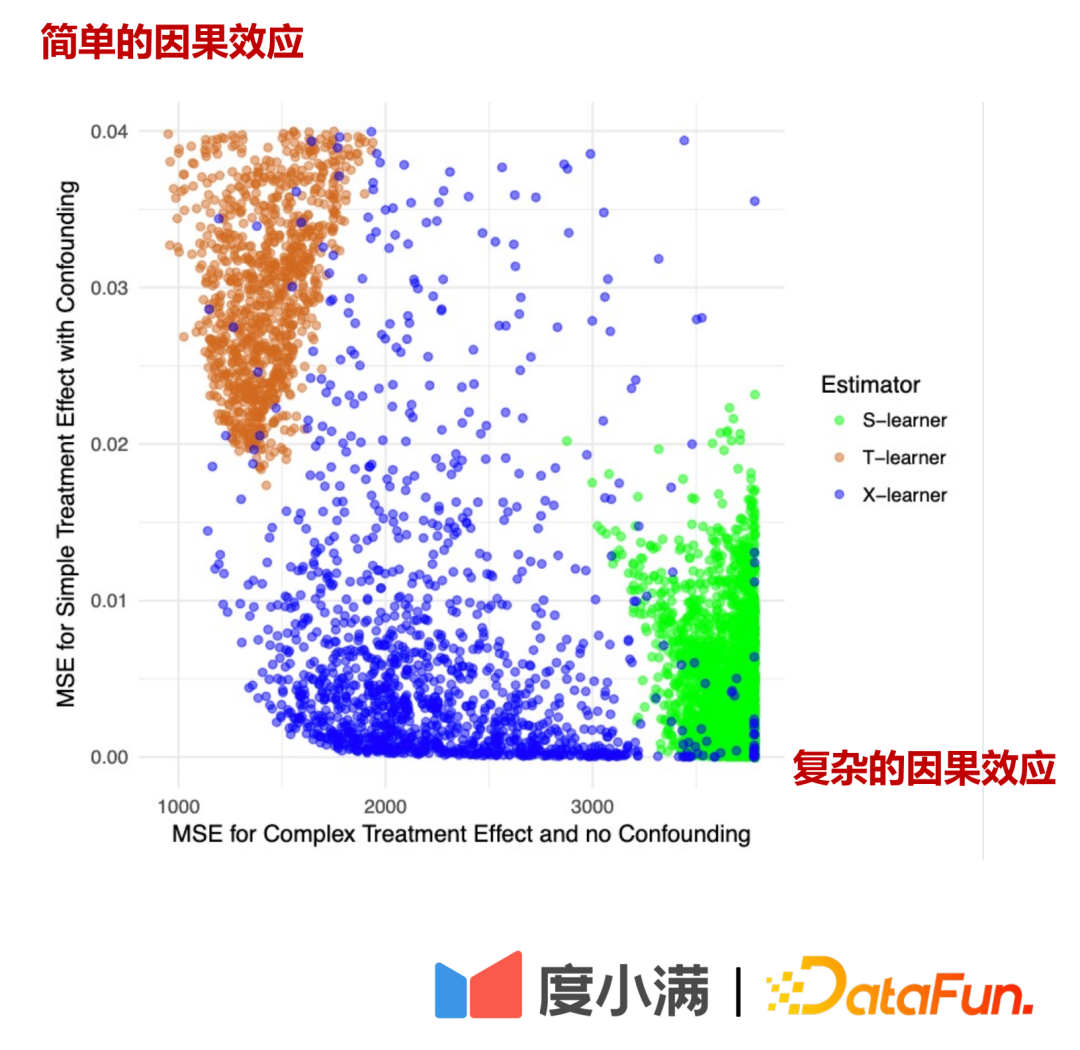
上図の横軸は複合因果効果とMSEの推定誤差、縦軸は単純因果効果、横軸と縦軸はMSEの推定誤差です。軸はそれぞれ 2 つの部分のデータを表します。緑色は Slearner の誤差分布、茶色は Tlearner の誤差分布、青色は Xlearner の誤差分布を表します。 ランダムなサンプル条件下では、Xlearner は複雑な因果効果の推定と単純な因果効果の推定の両方に優れています。Slearner は複雑な因果効果の推定では比較的パフォーマンスが悪く、単純な因果効果の推定には優れています。トレーナーはスラーナーの反対です。 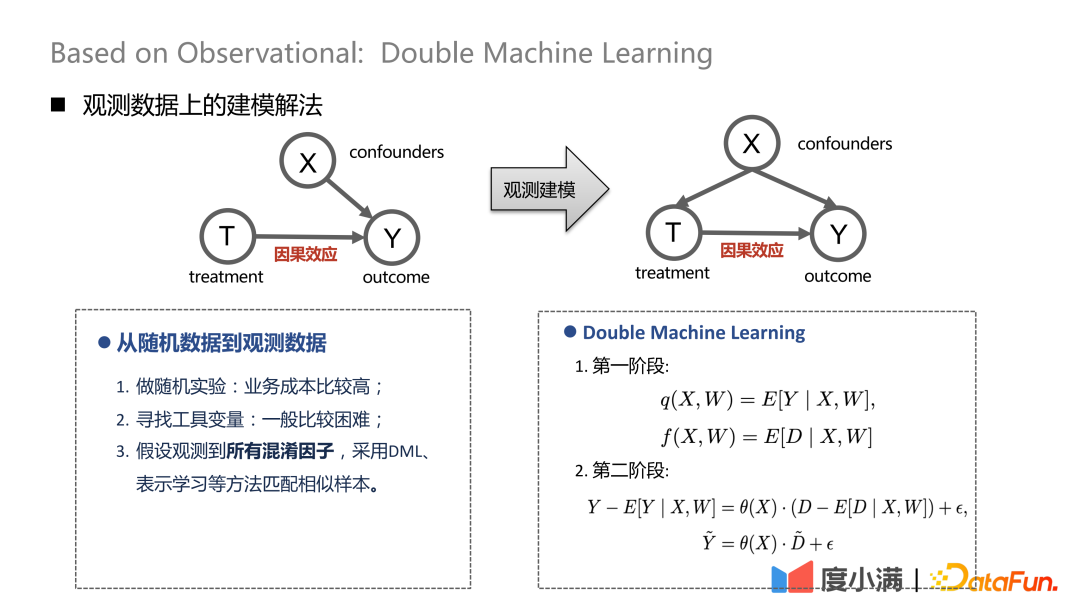
# ランダムなサンプルがある場合は、X から T までの矢印を削除できます。観察モデリングに移行した後は、X から T への矢印を取り除くことはできず、治療と転帰は同時に交絡因子の影響を受けることになりますが、このとき、何らかの脱分極処理を行うことができます。例えば、DML (Double Machine Learning) 手法は 2 段階のモデリングを実行します。最初の段階では、X はユーザー自身の表現特性 (年齢、性別など) です。交絡変数には、たとえば、特定のグループの人々を選別するためのこれまでの取り組みが含まれる可能性があります。第 2 段階では、前段階の計算結果の誤差がモデル化されます。これが CATE の推定値です。
ランダム データから観測データまで 3 つの処理方法があります。
(1 ) ランダム化実験を実施するが、ビジネスコストが高い;
(2) 操作変数を見つけるのは一般に困難;
(3) すべての交絡因子が観察されたと仮定して、DML、表現学習、およびその他の方法を使用して、類似したサンプルを照合します。
2. 因果表現の学習
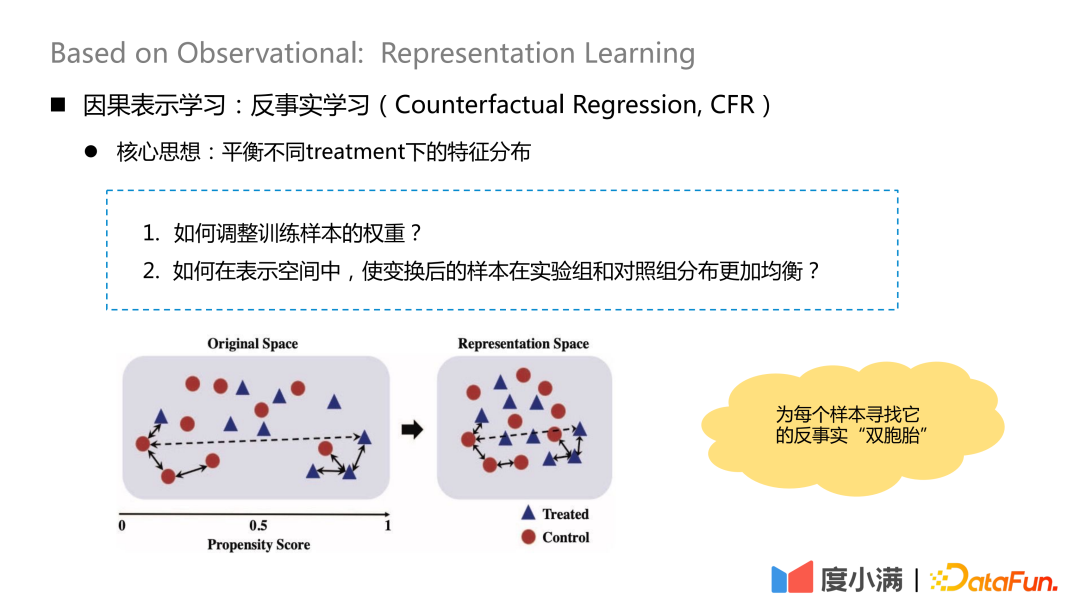
中心となるアイデア反事実学習 さまざまな処理の下で特徴分布のバランスをとることです。
核心的な質問は 2 つあります:1. トレーニング サンプルの重みを調整するにはどうすればよいですか?
#2. 変換されたサンプルを表現空間内の実験グループと対照グループにさらに均等に分散させるにはどうすればよいでしょうか?
#本質的なアイデアは、変換マッピング後に各サンプルの反事実的な「双子」を見つけることです。マッピング後、治療グループと対照グループの X の分布は比較的類似しています。
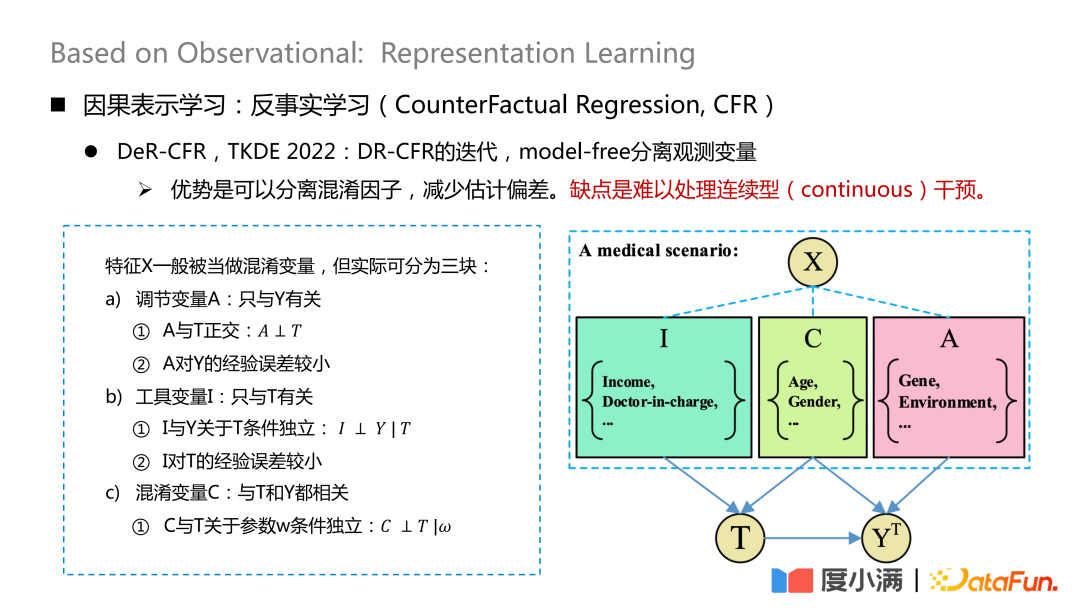
より代表的な研究は、TKDE 2022 に掲載された論文で、DeR-CFR の一部の研究を紹介しています。この部分はこれは実際には DR-CRF モデルの反復であり、モデルフリーの方法を使用して観測変数を分離します。
# X 変数を調整変数 A、操作変数 I、交絡変数 C の 3 つの部分に分割します。次に、I、C、A を使用してさまざまな処理の下で X の重みを調整し、観察されたデータの因果モデリングの目的を達成します。
#この方法の利点は、交絡因子を分離し、推定のバイアスを軽減できることです。欠点は、継続的な介入に対処するのが難しいことです。
#このネットワークの核心は、3 種類の変数 A/I/C をどのように分離するかです。調整変数 A は Y のみに関連しており、A と T が直交し、A から Y までの経験的誤差が小さいことを保証する必要があります。操作変数 I は T のみに関連しており、次の条件を満たす必要があります。 T に関する I と Y の条件付き独立性、および T に関する I の経験 誤差は小さい; 混同変数 C は T と Y の両方に関連しており、w はネットワークの重みです。重みを考慮するには、C と T が w に関して条件付きで独立していることを確認する必要があります。ここでの直交性は、対数損失や mse ユークリッド距離などの一般的な距離公式やその他の制約によって実現できます。
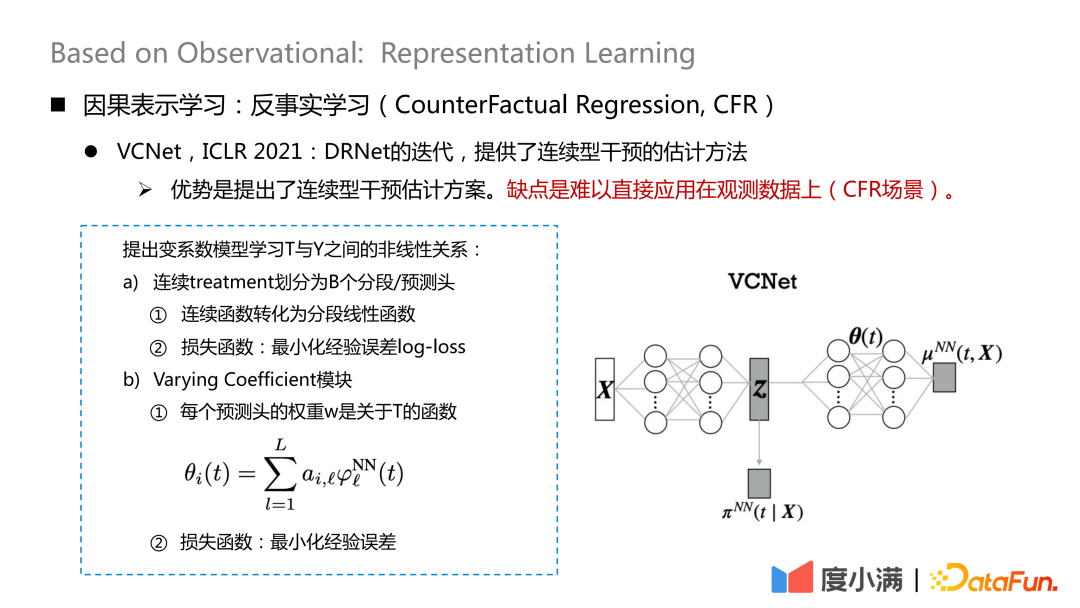
また、継続的介入に対処する方法に関する新しい論文研究もいくつかあり、ICLR2021 で公開された VCNet では、継続的介入の推定方法が提供されています。欠点は、観測データ(CFRシナリオ)に直接適用することが難しいことです。
マップ 寄与する変数は X から抽出されます。ここでは、連続処理を B 分割/予測ヘッドに分割し、各連続関数を分割線形関数に変換し、経験的誤差対数損失を最小化して
# # を学習します。 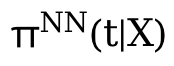
# 次に、学習した Z と θ(t) を使用します。 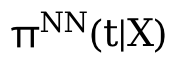 それが結果です。ここでの θ(t) が連続処理の鍵となるのですが、可変係数モデルではありますが、このモデルは連続処理のみを扱っているため、観測データの場合、各 B セグメントのデータが均一であることは保証できません。
それが結果です。ここでの θ(t) が連続処理の鍵となるのですが、可変係数モデルではありますが、このモデルは連続処理のみを扱っているため、観測データの場合、各 B セグメントのデータが均一であることは保証できません。
3. 反事実的なクォータ モデル Mono-CFR
最後に、Du Xiaoman の反事実を紹介しましょう。信用モデルは主に、観察データに対する継続的治療の反事実推定の問題を解決します。
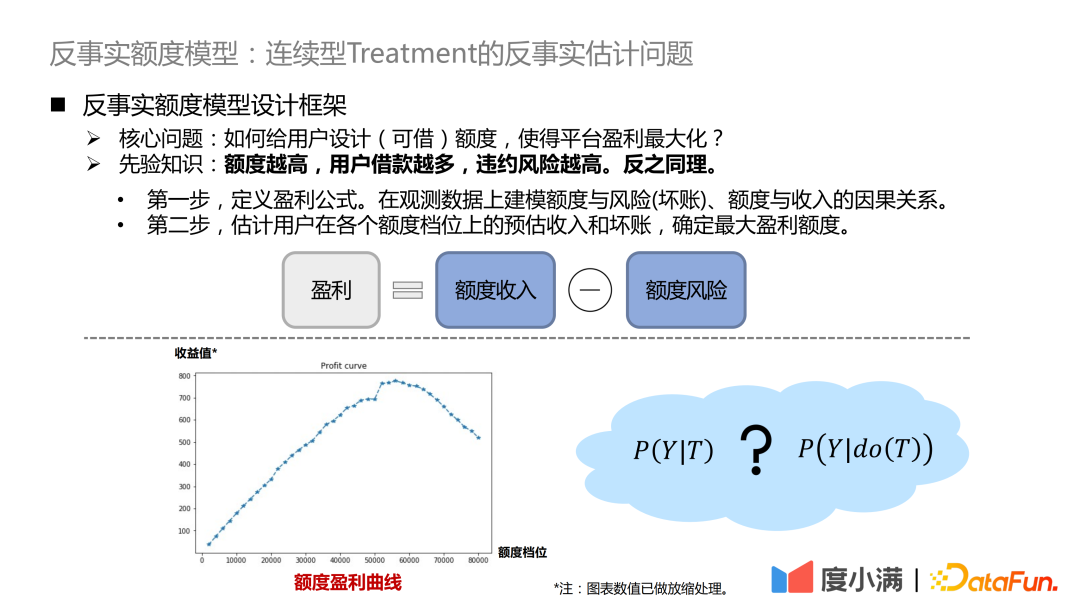
#核心的な問題は、プラットフォームの利益を最大化するためにユーザーの (借入可能な) クォータをどのように設計するかということです。ここでの先験的な知識は、限度額が高いほど、より多くのユーザーが借りることになり、デフォルトのリスクが高まるということです。逆に。
- #最初のステップは、利益計算式を定義することです。利益 = 割り当て収入 - 割り当てリスク。計算式は単純そうに見えますが、実際には調整すべき点がたくさんあります。このようにして、問題は、観察データに基づいて、割り当てとリスク(不良債権)、割り当てと収入の間の因果関係をモデル化することに変換されます。
- #2 番目のステップは、各割り当てレベルでのユーザーの推定収入と不良債権を推定し、最大利益額を決定することです。
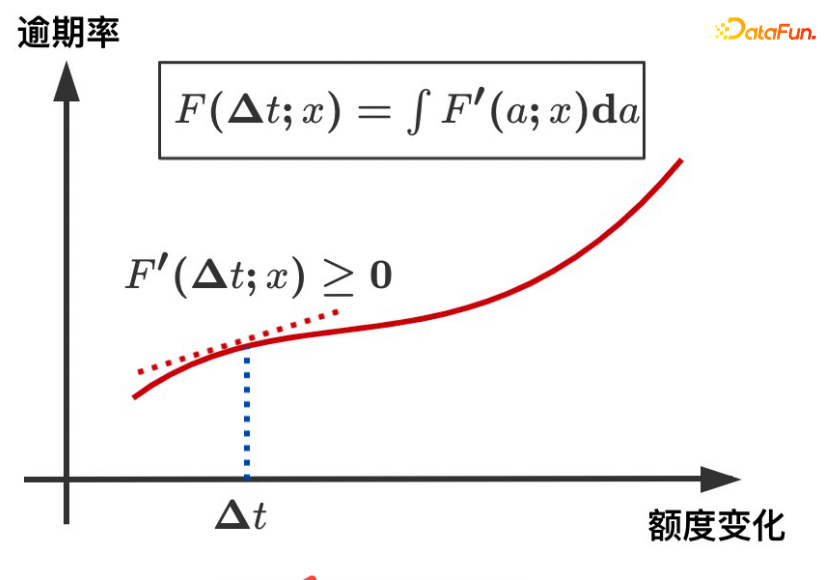
各ユーザーは、上の図に示すような利益曲線を持つことが期待されます。さまざまな割り当てレベルでは、収入の値は事実の推定に反比例します。
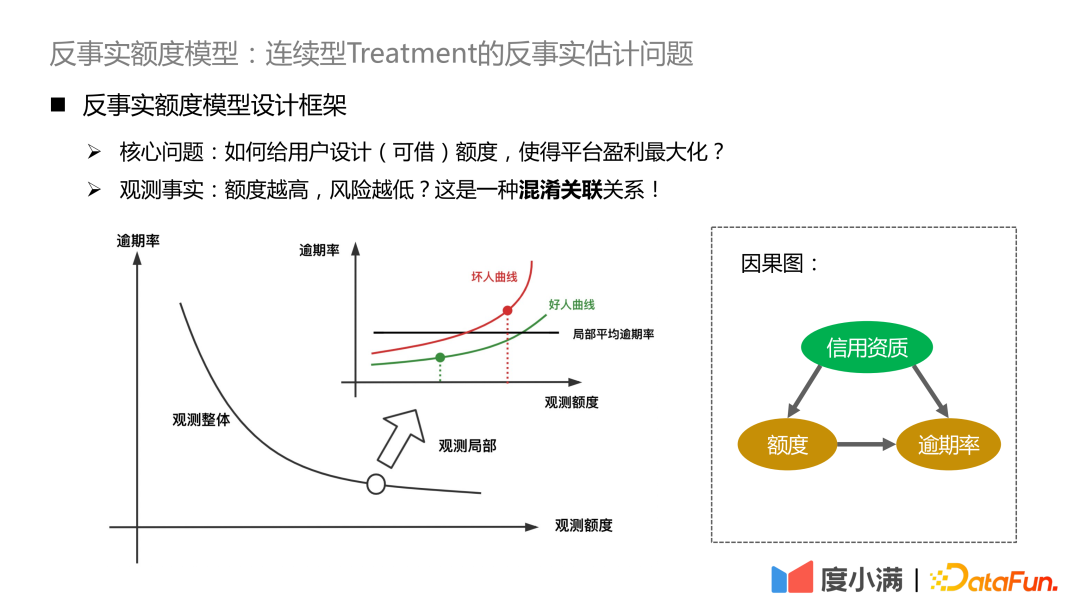
#観測データで、量が多ければ多いほどリスクが低いことがわかります。これは本質的に次のような理由によるものです。交絡因子の存在。私たちのシナリオで混乱を招く要因は、信用資格です。良好な信用資格を持つ人に対しては、プラットフォームはより高い限度額を付与し、その逆の場合は、プラットフォームはより低い限度額を付与します。優れた信用資格を持つ人々の絶対リスクは、低い信用資格を持つ人々の絶対リスクよりも依然として大幅に低いです。信用資格を向上させると、限度額の引き上げがリスクの増加をもたらし、限度額の上限がユーザー自身の支払い能力を超えることがわかります。
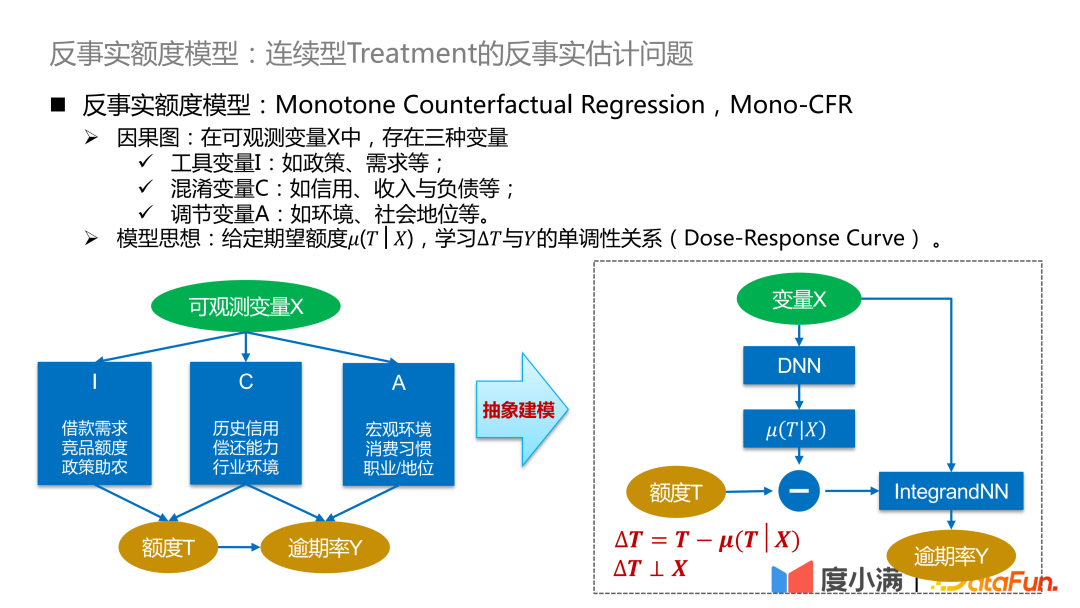
モデルのアイデア: 期待量 μ(T|X) が与えられた場合、ΔT と Y の間の単調関係 (用量反応曲線) を学習します。期待量はモデルに学習された連続的な傾向量として理解できるため、交絡変数Cと量Tの関係を切り離してΔTとYの因果関係学習に変換し、分布を比較することができます。 ΔT の下での Y の良好な特性評価。
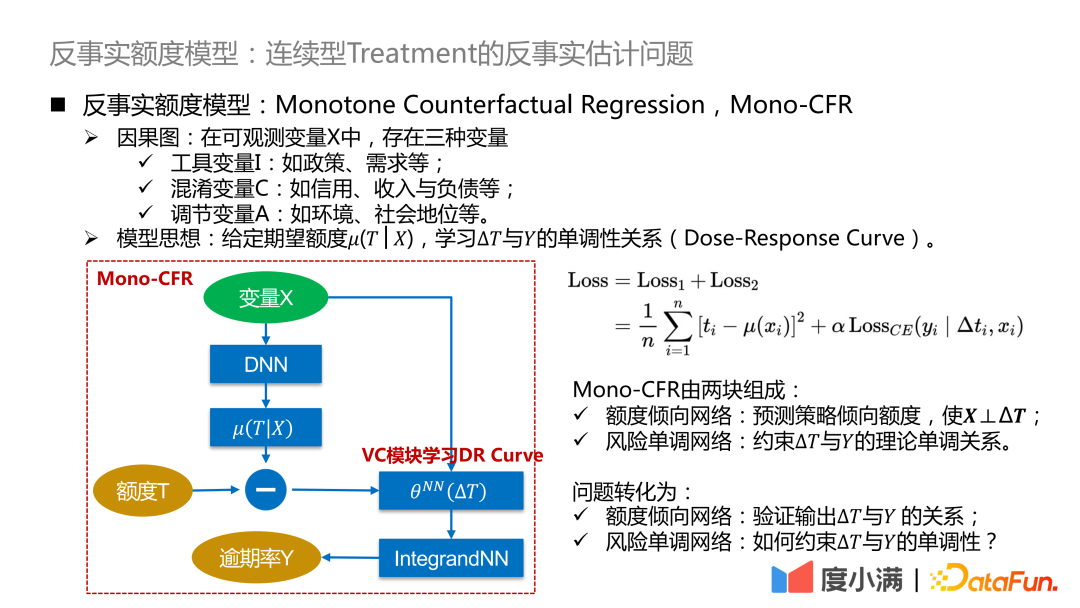
#ここでは、上記の抽象フレームワークをさらに洗練させます。 ΔT を可変係数モデルに変換し、IntegrandNN ネットワークに接続します。トレーニング エラーは 2 つの部分に分割されます:
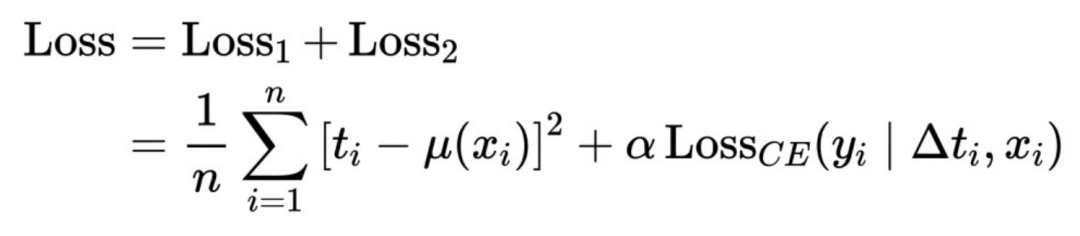
#ここでの α は、リスクの重要性を測定するハイパーパラメータです。
Mono-CFR は 2 つの部分で構成されます:
- クォータ傾向ネットワーク:X⊥ΔTとなるように戦略傾向量を予測します。
関数 1: T に最も関連する X 内の変数を抽出し、経験的誤差を最小限に抑えます。
# 機能 2: 過去の戦略に近似サンプルを固定します。
- リスク単調ネットワーク: 制約 ΔT と Y の間の理論的な単調関係。
#機能 2: 推定バイアスを軽減します。
問題は次のように変換されます:
- 割り当て傾向ネットワーク: 検証出力 Δ T と Y の関係。
- リスク単調ネットワーク: ΔT と Y の単調性を制限するにはどうすればよいですか?
- #実際の金額傾向ネットワークの入力は次のとおりです:
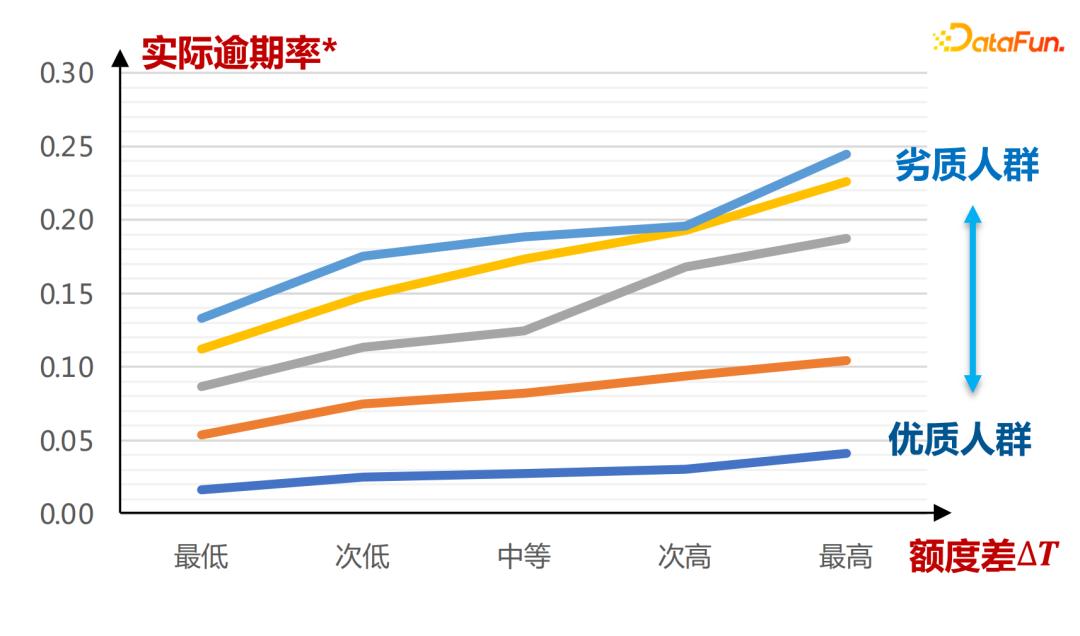 #横軸はAカードスコアで定義されるグループであり、異なる傾向のノルマμ(T|X)の下で、ノルマの差ΔTと延滞率が変化していることがわかります。 Yは単調増加の関係を示しており、グループの質が低いほど信用差ΔTの変化曲線が急峻になり、実際の延滞率の変化曲線も急峻になり、全体の傾きが大きくなる。ここでの結論は、すべて履歴データの学習を通じて導き出されます。
#横軸はAカードスコアで定義されるグループであり、異なる傾向のノルマμ(T|X)の下で、ノルマの差ΔTと延滞率が変化していることがわかります。 Yは単調増加の関係を示しており、グループの質が低いほど信用差ΔTの変化曲線が急峻になり、実際の延滞率の変化曲線も急峻になり、全体の傾きが大きくなる。ここでの結論は、すべて履歴データの学習を通じて導き出されます。
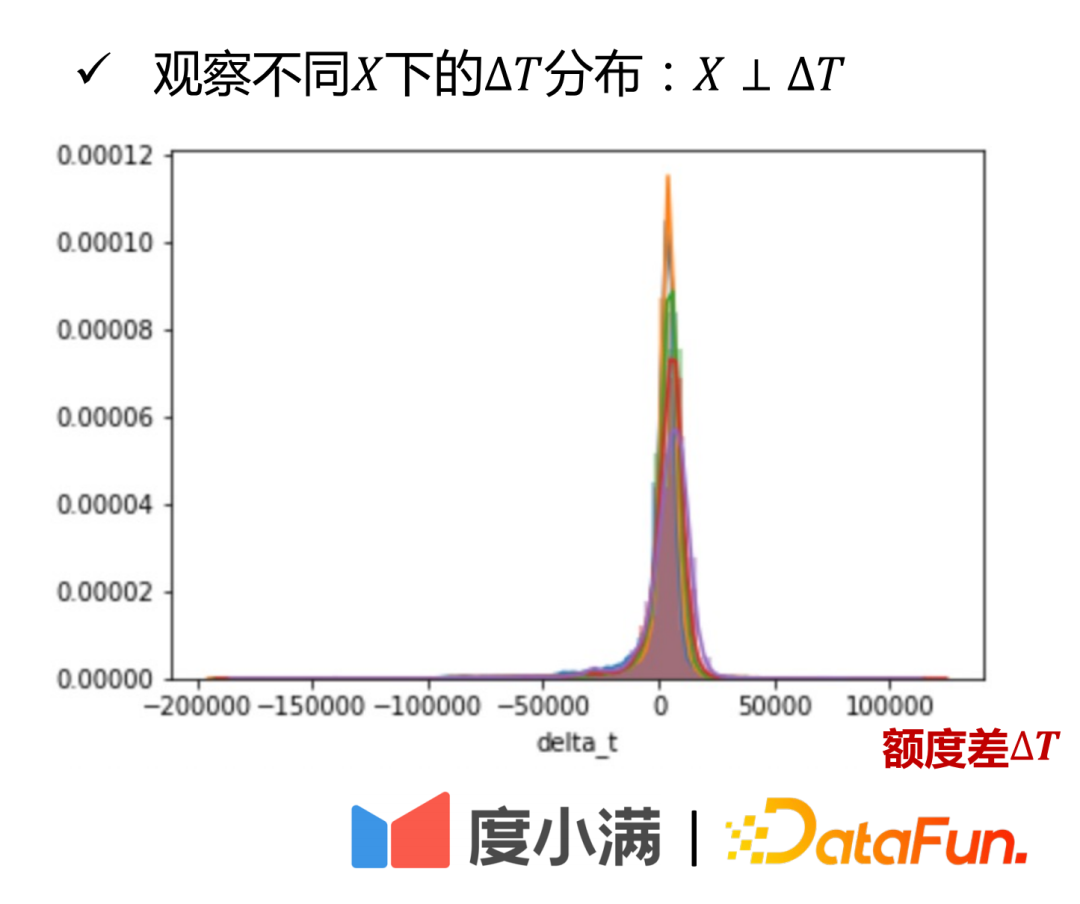 X 分布図と ΔT 分布図からわかります: さまざまな条件人々の集団間の差ΔT(図では色で区別)が同じ間隔で均等に分布していることを、実践的な観点から説明します。
X 分布図と ΔT 分布図からわかります: さまざまな条件人々の集団間の差ΔT(図では色で区別)が同じ間隔で均等に分布していることを、実践的な観点から説明します。
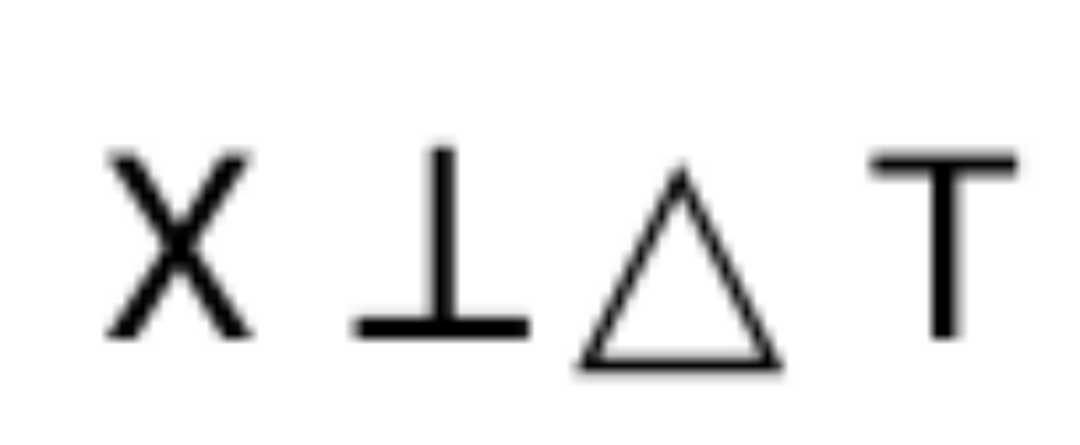
#理論的な観点からは、厳密に証明することもできます。
2 番目の部分は、リスク単調ネットワークの実装です:

ここでの ELU 1 関数の数式は次のとおりです:
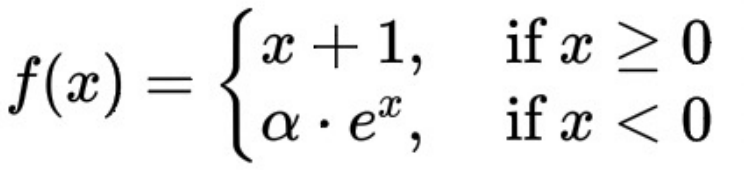
##ΔT と延滞率は単調増加傾向を示し、これは ELU 1 関数の導関数が常に または より大きいことで保証されます。 0に等しい。
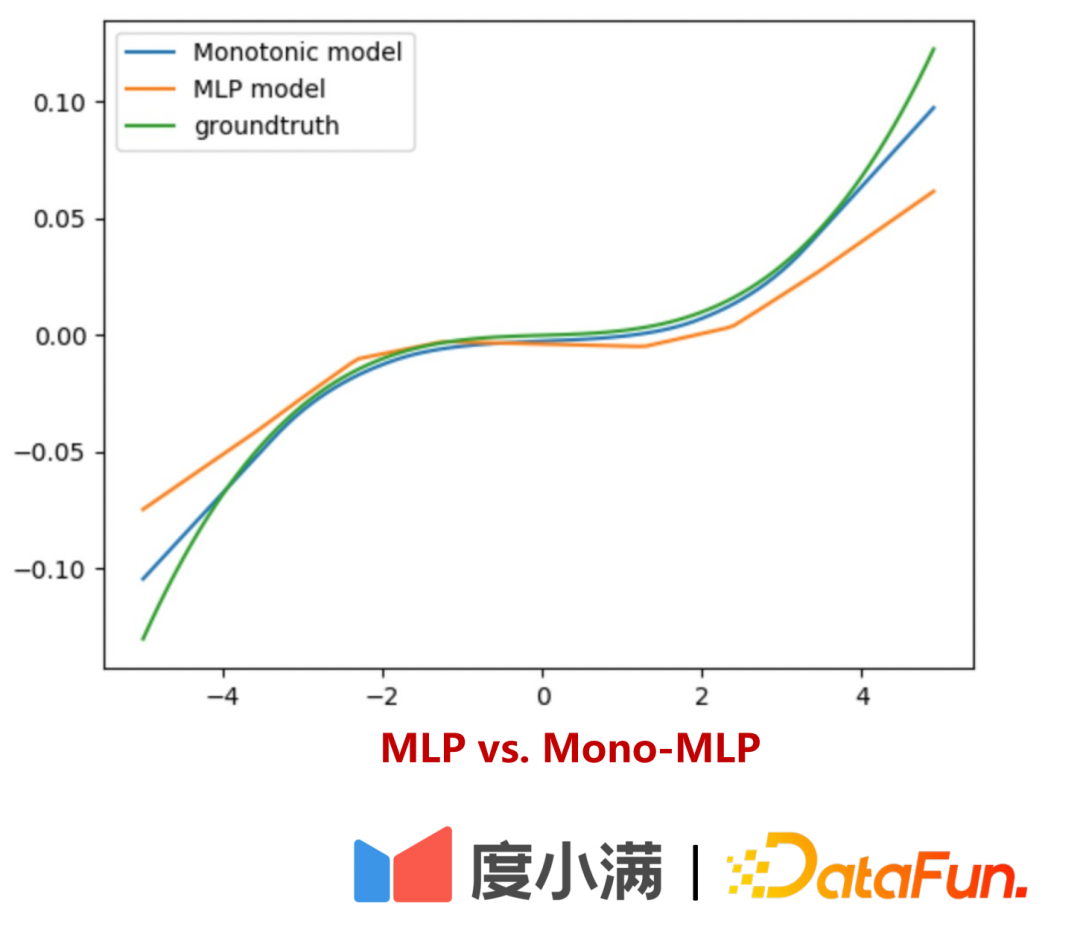
以下では、リスク単調ネットワークが弱い係数変数をより正確に学習する方法を説明します:
次のような数式があるとします。
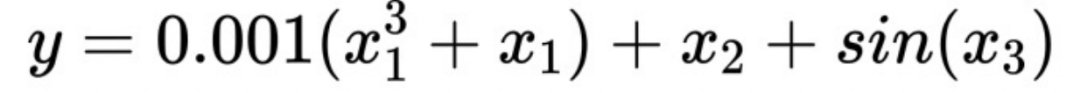
が表示されます。ここで ##xx1 は弱い係数変数です。x1## に単調性を適用する場合# 性的拘束の後、応答 Y の推定はより正確になります。このような個別の制約がないと、#1 の重要性が #2 に圧倒され、その結果、モデルのバイアスが増加します。
 #オフラインで金額のリスク推定曲線を評価するにはどうすればよいですか?
#オフラインで金額のリスク推定曲線を評価するにはどうすればよいですか?
は 2 つの部分に分かれています:
パート 1: 解釈可能な検証
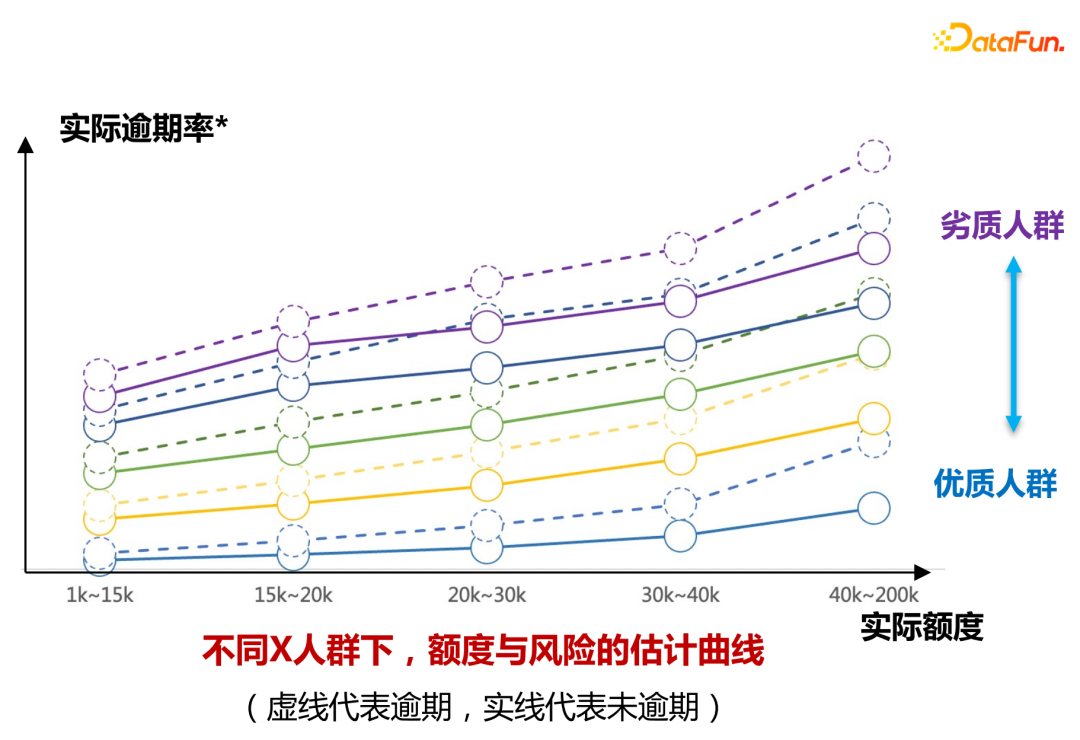
#パート 2: 小規模なトラフィック実験を使用して、さまざまな増加範囲でのリスク偏差が上昇値ビニングを通じて取得できることを検証します。
- ##オンライン実験の結論:
条件は、ノルマが30%増加、利用者の延滞額が20%以上減少、借入が30%増加、収益性が30%以上増加すること。
将来のモデルの期待:
モデルフリー形式で操作変数と調整を組み合わせる変数がより明確に分離されるため、劣等集団に対するリスク移転においてモデルのパフォーマンスが向上します。
実際のビジネス シナリオでは、Du Xiaoman のモデル進化の反復プロセスは次のとおりです:
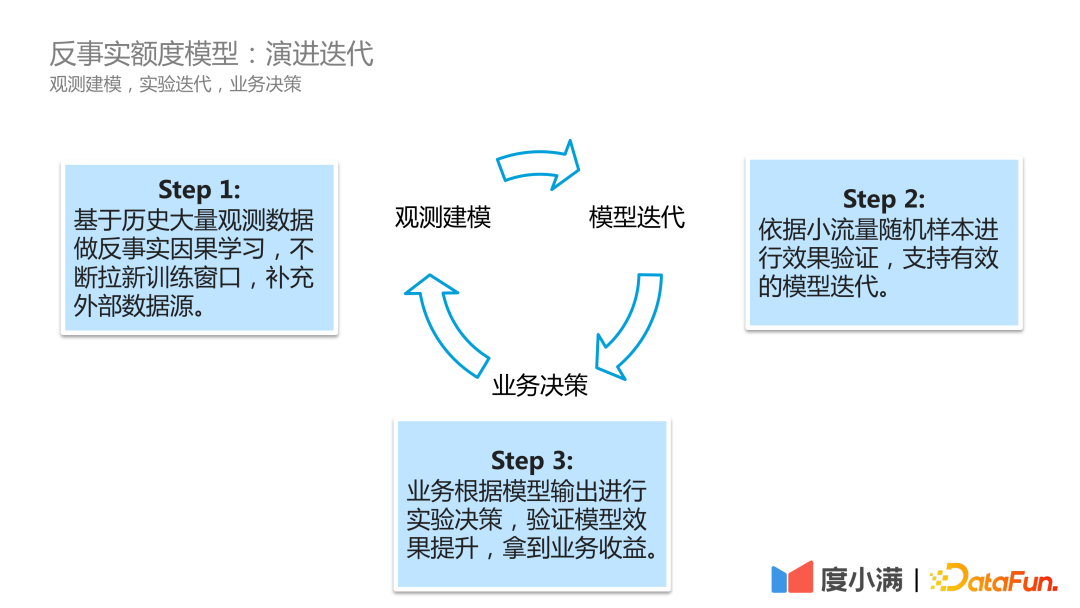
#最初のステップは観察モデリングであり、過去の観察データを継続的にスクロールし、反事実的因果学習を実行し、新しいトレーニング ウィンドウを常に開きます。外部データソースによって補完されます。
#2 番目のステップはモデルの反復です。効果は、効果的なモデルの反復をサポートするために、少量のトラフィックのランダム サンプルに基づいて検証されます。
#3 番目のステップはビジネス上の意思決定であり、ビジネスはモデルの出力に基づいて実験的な意思決定を行い、モデル効果の向上を検証し、ビジネス上の利益を獲得します。
以上が反事実的因果推論に基づく Duxiaoman クォータ モデルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107

 主な技術思想と因果推論手法の概要
Apr 12, 2023 am 08:10 AM
主な技術思想と因果推論手法の概要
Apr 12, 2023 am 08:10 AM
はじめに: 因果推論はデータ サイエンスの重要な分野です。インターネットや業界における製品の反復、アルゴリズム、インセンティブ戦略の評価において重要な役割を果たしています。データ、実験、または統計計量経済モデルを組み合わせて、新しい変化の影響を計算します。利益は意思決定の基礎となります。しかし、因果関係の推論は単純なものではありません。まず、日常生活において、人々は相関関係と因果関係を混同することがよくあります。相関関係は、多くの場合、2 つの変数が同時に増加または減少する傾向があることを意味しますが、因果関係は、変数を変更したときに何が起こるかを知りたいこと、または、実際にそれを行った場合に反事実的な結果が得られることを期待することを意味します。過去 違う行動をとったら、未来は変わりますか?ただし、問題は、事実に反するデータがしばしば存在することです。
 反事実的因果推論に基づく Duxiaoman クォータ モデル
Jun 03, 2023 pm 10:16 PM
反事実的因果推論に基づく Duxiaoman クォータ モデル
Jun 03, 2023 pm 10:16 PM
1. 因果推論の研究パラダイム 研究パラダイムには現在 2 つの主要な研究方向があります: ユダヤ・パール構造モデルの潜在的な出力フレームワーク ユダヤ・パールの著書「The Book of Why-The New Science of Cause and Effect」では、認知ラダーが第 1 レベル - アソシエーション : 直接観察できる相関関係を通じてルールを見つけ出す、第 2 レベル - 介入 : 現状が変更された場合、どのようなアクションを実行し、どのような結論を導き出すか、実験的に観察される; 第 3 レベル - 反事実: 法律や規制などの問題のため、実験的に直接観察することはできず、その行動が実行されたらどうなるかについて反事実的な仮定が立てられます。
 因果推論に基づく推奨システム: レビューと展望
Apr 12, 2024 am 09:01 AM
因果推論に基づく推奨システム: レビューと展望
Apr 12, 2024 am 09:01 AM
この共有のテーマは、因果推論に基づく推奨システムであり、これまでの関連研究をレビューし、この方向の将来の展望を提案します。レコメンダー システムで因果推論技術を使用する必要があるのはなぜですか?既存の研究成果では、因果推論を使用して 3 種類の問題を解決しています (Gaoe et al. の TOIS2023 論文「レコメンダー システムにおける因果推論: ASurvey と Future Directions」を参照): まず、レコメンデーション システムにはさまざまなバイアス (BIAS) があり、因果推論はこれらのバイアスツールを削除する効果的な方法です。レコメンダー システムは、データ不足や因果関係を正確に推定できないことに対処する際に課題に直面する可能性があります。解決するために
 そこに集中してください! !因果推論のための 2 つの主要なアルゴリズム フレームワークの分析
Jun 04, 2024 pm 04:45 PM
そこに集中してください! !因果推論のための 2 つの主要なアルゴリズム フレームワークの分析
Jun 04, 2024 pm 04:45 PM
1. フレームワーク全体の主なタスクは 3 つのカテゴリに分類できます。 1 つ目は因果構造の発見、つまりデータから変数間の因果関係を特定することです。 2 つ目は因果効果の推定です。つまり、ある変数が別の変数に及ぼす影響の程度をデータから推測します。この影響は相対的な性質を指すのではなく、1 つの変数が介入したときに別の変数の値または分布がどのように変化するかを指すことに注意してください。最後のステップはバイアスを修正することです。多くのタスクでは、さまざまな要因によって開発サンプルとアプリケーション サンプルの配布が異なる可能性があるためです。この場合、因果推論はバイアスを修正するのに役立つ可能性があります。これらの関数はさまざまなシナリオに適していますが、最も典型的なのは意思決定のシナリオです。因果推論を通じて、さまざまなユーザーが私たちの意思決定行動にどのように反応するかを理解できます。第二に、産業界においては、
 因果的推奨技術のマーケティングと説明可能性への応用
May 18, 2023 pm 01:58 PM
因果的推奨技術のマーケティングと説明可能性への応用
May 18, 2023 pm 01:58 PM
1. Uplift ゲイン感度予測 Uplift ゲインに関して、一般的なビジネス上の問題は次のように要約できます。マーケティング担当者は、定義された人々のグループの中で、新しいマーケティング アクション T=1 が元のマーケティング アクション T= と比較してどれだけの効果をもたらすかを知りたいと考えます。 0. 平均利益はどれくらいですか (リフト、ATE、AverageTreatmentEffect)。新しいマーケティング活動が元のマーケティング活動よりも効果的であるかどうかに誰もが注目するでしょう。保険シナリオでは、マーケティング活動は主に、推奨モジュールで明らかにされるコピーライティングや商品などの保険の推奨事項を指します。目標は、さまざまなマーケティング活動や制約の下で、マーケティング活動によって最も利益を得たグループを見つけて、実行することです。ターゲットを絞った配信 (AudienceTargeting)。まずは比較してみましょう
 Kuaishou での因果推論演習ショートビデオの推奨
Feb 05, 2024 pm 06:20 PM
Kuaishou での因果推論演習ショートビデオの推奨
Feb 05, 2024 pm 06:20 PM
1. Kuaishou シングルカラムショートビデオ推奨シナリオ 1. Kuaishou について* データは 2023 年の第 2 四半期から取得. Kuaishou は人気のショートビデオおよびライブブロードキャストコミュニティアプリケーションであり、驚異的な MAU と New DAU 記録を達成しています。 Kuaishou の中心的なコンセプトは、一般の人々の生活を観察し共有することで、誰もがコンテンツの作成者および普及者になれるようにすることです。 Kuaishou アプリケーションでは、短いビデオ シーンは主に 1 列と 2 列の 2 つの形式に分けられます。現時点では 1 カラムのトラフィックが比較的多く、ユーザーは上下にスライドすることでビデオ コンテンツを没入的に閲覧できます。 2カラムのプレゼンテーションは情報の流れに似ており、ユーザーは画面に表示されるいくつかのコンテンツから興味のあるものを選択し、クリックして視聴する必要があります。レコメンデーション アルゴリズムは Kuaishou のビジネス エコシステムの中核であり、トラフィック分散にとって重要です。
 因果推論でデータをより有効に活用するにはどうすればよいでしょうか?
Apr 11, 2023 pm 07:43 PM
因果推論でデータをより有効に活用するにはどうすればよいでしょうか?
Apr 11, 2023 pm 07:43 PM
はじめに: この共有のタイトルは「因果推論でデータをより効果的に使用するには?」です。 」では、因果関係に関する出版論文に関連したチームの最近の研究を主に紹介します。本レポートでは、より多くのデータを活用して因果推論を行う方法を、履歴管理データを活用して明示的に混乱バイアスを軽減する方法と、複数ソースデータの融合による因果推論の2つの側面から紹介します。全文目次: 因果推論、背景補正、因果ツリー、アリのビジネスアプリケーションにおける GBCT 因果データ融合 1. 因果推論の背景. 共通の機械学習予測問題は、通常、同じシステム内に設定されます。喫煙者の予測など、肺がんになる確率や画像分類などの予測問題が想定されます。原因と結果の問題は、データの背後にあるメカニズムに関係します。
 AI詐欺の成功率は100%なのでしょうか?ドゥ・シャオマン氏のアンチディープフェイクモデルは「魔法で魔法を倒す」
May 30, 2023 pm 09:46 PM
AI詐欺の成功率は100%なのでしょうか?ドゥ・シャオマン氏のアンチディープフェイクモデルは「魔法で魔法を倒す」
May 30, 2023 pm 09:46 PM
2023-05-2610:22:19 著者: Song Junyi 最近、#AIFraud 成功率は 100% に近い# というトピックが Weibo でホット検索になりました。 AI の顔を変えるビデオにより、福建省のテクノロジー企業の法定代理人が 10 分間で 430 万元をだまし取られました。海外でもAI関連の詐欺が発生し、Google CEOの動画が添付されたメールをきっかけに多くのYouTubeブロガーが危険なウイルスを含むファイルをダウンロードさせた。どちらの詐欺事件にもディープフェイク技術が関与していた。これは6年前から存在する顔を変える手法で、現在ではAIGC技術の爆発的な発展により、識別が難しいディープフェイク動画の作成がますます簡単になってきています。顔認証が広く使われている金融業界では、
