

Redis 関連の問題を解決する方法

Redis 永続化メカニズム
Redis は永続化をサポートするインメモリ データベースであり、永続化メカニズムを通じてメモリ内のデータをハードディスク ファイルに同期して、データの永続性を確保します。 Redis が再起動されると、ハードディスク ファイルをメモリに再ロードすることでデータを復元できます。
実装: fork() 子プロセスを別途作成し、現在の親プロセスのデータベースデータを子プロセスのメモリにコピーし、子プロセスで一時ファイルに書き込みます。 、この一時ファイルを使用すると、最後のスナップショット ファイルが置き換えられ、子プロセスが終了し、メモリが解放されます。
RDB は、Redis のデフォルトの永続化メソッドです。特定の期間戦略に従って、メモリ データはスナップショットの形式でハードディスク上のバイナリ ファイルに保存されます。つまり、スナップショット スナップショット ストレージ、対応する生成データ ファイルは dump.rdb であり、スナップショット サイクルは構成ファイルの save パラメーターを通じて定義されます。 (スナップショットは、それが表すデータのコピー、またはデータのコピーにすることができます。)
AOF: Redis は、受信した各書き込みコマンドをファイルの最後に追加します。 MySQL のバイナリログに似ています。 Redis が再起動すると、ファイルに保存された書き込みコマンドを再実行することにより、データベース全体の内容がメモリ内に再構築されます。
両方の方法を同時に有効にすると、データ回復 Redis は AOF 回復を優先します。
キャッシュなだれ、キャッシュペネトレーション、キャッシュの予熱、キャッシュの更新、キャッシュのダウングレードおよびその他の問題
キャッシュなだれこれは単純に次のように理解できます: 元のキャッシュの障害によるもの新しいキャッシュの有効期限が切れていない期間中は、
(例: キャッシュの設定時に同じ有効期限を使用し、同時にキャッシュの広い領域が期限切れになった場合)、キャッシュにアクセスする必要があり、データベースにクエリを実行する必要がありましたが、データベースがこれにより CPU とメモリに多大な負荷がかかり、ひどい場合にはデータベースのダウンタイムが発生する可能性があります。これにより一連の連鎖反応が起こり、システム全体が崩壊します。
解決策:
ほとんどのシステム設計者は、一度に多数のスレッドがデータベースを読み書きしないようにするために、ロック (最も一般的な解決策) またはキューの使用を検討します。これにより、障害時に基盤となるストレージ システムに大量の同時リクエストが発生するのを回避できます。もう 1 つの簡単な解決策は、キャッシュの有効期限を分散することです。
2. キャッシュ ペネトレーション
キャッシュ ペネトレーションとは、データベース内に見つからず、当然キャッシュ内にも見つからないユーザー クエリ データを指します。これにより、ユーザーはクエリ時にキャッシュ内でそのデータを見つけることができず、毎回データベースにアクセスして再度クエリを実行し、空のクエリを返す必要があります (2 つの無駄なクエリに相当)。このように、リクエストはキャッシュをバイパスしてデータベースを直接チェックしますが、これはキャッシュ ヒット率の問題でもよく指摘されます。
解決策;
最も一般的なのは、ブルーム フィルターを使用して、考えられるすべてのデータを十分な大きさのビットマップにハッシュすることです。存在しない特定のデータはインターセプトされます。このビットマップを使用することで、基盤となるストレージ システムに対するクエリのプレッシャーを回避できます。
もっと単純で粗雑な方法もあります クエリによって返されたデータが空の場合 (データが存在しないか、システムが失敗したかに関係なく)、空の結果をキャッシュしますが、有効期限は非常に短く、最大でも 5 分です。直接設定したデフォルト値をキャッシュに保存し、データベースへのアクセスを継続せずに2回目からキャッシュに値を取得する方法が最も単純で大雑把な方法です。 5TB ハードディスクにはデータがいっぱいです。データの重複を排除するアルゴリズムを作成してください。データが 32 ビット サイズの場合、この問題を解決するにはどうすればよいでしょうか? 64bitだとどうなるのでしょうか?
ビットマップ: 典型的なものはハッシュ テーブルです
欠点は、ビットマップは各要素に対して 1 ビットの情報しか記録できないことです。追加の機能を完成させたい場合は、残念ながら、さらに多くの機能を犠牲にすることによってのみ実現できると思います。空間と時間です。
ブルーム フィルター (推奨)
k(k>1)k(k>1) の独立したハッシュ関数を導入して、特定の空間内でエラーが発生することを保証します。要素重量判定が完了しました。
利点はスペース効率とクエリ時間が一般的なアルゴリズムよりもはるかに高いことですが、欠点は一定の誤認識率と削除の難しさです。
ブルーム フィルター アルゴリズムの中心となるアイデア は、複数の異なるハッシュ関数を使用して「競合」を解決することです。
ハッシュには競合 (衝突) の問題があり、同じハッシュを使用して取得された 2 つの URL の値が同じになる可能性があります。競合を減らすために、さらにいくつかのハッシュを導入することができます。ハッシュ値の 1 つによって要素がセットに含まれていないことが判明した場合、その要素は間違いなくセットに含まれていません。すべてのハッシュ関数が要素がセット内にあることを示す場合にのみ、要素がセット内に存在することを確認できます。これがブルームフィルターの基本的な考え方です。
ブルーム フィルターは通常、大規模なデータ セット内に要素が存在するかどうかを判断するために使用されます。
リマインダーにより追加: キャッシュの侵入とキャッシュのブレークダウンの違い
キャッシュのブレークダウン: 非常にホットなキーを指し、これへのアクセスに大規模な同時実行が集中します。キーの有効期限が切れると、大量の同時アクセスが継続してキャッシュを突破し、データベースに直接リクエストします。
解決策; キーにアクセスする前に、SETNX (存在しない場合は設定) を使用して別の短期キーを設定し、現在のキーへのアクセスをロックし、アクセス後に短期キーを削除します。
3. キャッシュの予熱
キャッシュの予熱は比較的一般的な概念です。多くの友人が簡単に理解できると思います。キャッシュの予熱は、システムがオンラインになるときです。最後に、関連するキャッシュ データはキャッシュ システムに直接ロードされます。このようにして、最初にデータベースにクエリを実行し、ユーザーが要求したときにデータをキャッシュするという問題を回避できます。ユーザーは、予熱されたキャッシュ データを直接クエリします。
解決策のアイデア:
1. キャッシュ更新ページを直接作成し、オンラインになるときに手動で実行します。
2. データの量は大きくないため、プロジェクトの開始時に自動的にロードできます。
3. タイミング更新キャッシュ;
4. キャッシュ更新
キャッシュ サーバーに付属するキャッシュ無効化戦略 (Redis にはデフォルトで 6 つの戦略から選択できます) に加えて、特定のビジネス ニーズに基づいてカスタマイズされたキャッシュ削除には 2 つの一般的な戦略があります:
(1) 期限切れのキャッシュを定期的にクリーンアップします;
(2) ユーザーがリクエストを行ったときに、次に使用するキャッシュを決定します。キャッシュの有効期限が切れているかどうか、期限が切れた場合は、基盤となるシステムにアクセスして新しいデータを取得し、キャッシュを更新します。
どちらにも独自の長所と短所があります。前者の短所は、キャッシュされた多数のキーを維持するのがより面倒であることです。後者の短所は、ユーザーが要求するたびにキャッシュが必要になることです。無効と判断されるため、ロジックが比較的複雑です。具体的にどのソリューションを使用するかは、独自のアプリケーション シナリオに基づいて検討できます。
5. キャッシュのダウングレード
アクセス数が急激に増加すると、サービスの問題 (応答時間が遅い、応答しないなど) が発生したり、非コア サービスがコア プロセスのパフォーマンスに影響を及ぼしたりすることがあります。サービスが損なわれた場合でも、サービスが引き続き利用可能であることを確認する必要があります。システムは、いくつかの重要なデータに基づいて自動的にダウングレードすることも、手動でダウングレードできるようにスイッチを構成することもできます。
ダウングレードの最終的な目標は、たとえ損失があったとしても、コア サービスを確実に利用できるようにすることです。また、一部のサービスはダウングレードできません (ショッピング カートへの追加、チェックアウトなど)。
参照ログ レベルに基づいて計画を設定します。
(1) 一般: たとえば、一部のサービスは、ネットワーク ジッターが原因でタイムアウトになる場合や、サービスがオンラインになり、自動的にダウングレードされる可能性があります。
( 2) 警告: 一部のサービスは一定期間内にタイムアウトする場合があります。成功率が変動する場合 (たとえば、95 ~ 100% の間)、自動的にダウングレードするか手動でダウングレードし、アラームを送信することができます。
(3)エラー: たとえば、可用性率が 90% 未満である、データベース接続プールが枯渇している、またはアクセス数がシステムが耐えられる最大しきい値まで突然急増した場合は、自動的にダウングレードすることも、手動でダウングレードすることもできます。状況に応じてダウングレード;
(4) 重大なエラー: たとえば、特別な理由によりデータが間違っており、現時点では緊急の手動ダウングレードが必要です。
サービスのダウングレードの目的は、データベース雪崩の問題を引き起こす Redis サービスの障害を回避することです。したがって、重要でないキャッシュ データについては、サービスのダウングレード戦略を採用できます。たとえば、一般的なアプローチは、Redis に問題がある場合、データベースにクエリを実行する代わりに、デフォルト値をユーザーに直接返すことです。
ホット データとコールド データとは何ですか?
ホット データ、キャッシュは貴重です
コールド データの場合、データの大部分は再度アクセスされる前にメモリから搾り出されている可能性がありますが、そうではありません。メモリを消費するだけで、あまり価値はありません。頻繁に変更されるデータについては、状況に応じてキャッシュの利用を検討してください。
上記 2 つの例では、寿命リストとナビゲーション情報は、どちらも情報の変更頻度が高くなく、読み込み速度が速いという特徴があります。通常は非常に高いです。
当社の IM 製品、誕生日挨拶モジュール、その日の誕生日リストなどのホット データの場合、キャッシュは何十万回も読み取られる可能性があります。別の例として、ナビゲーション製品では、ナビゲーション情報をキャッシュし、将来的にそれを何百万回も読み取る可能性があります。
**キャッシュは、更新前にデータが少なくとも 2 回読み取られる場合にのみ意味を持ちます。これは最も基本的な戦略ですが、キャッシュが有効になる前に失敗すると、あまり意味がありません。
キャッシュが存在せず、変更の頻度が非常に高いが、キャッシュを考慮する必要があるシナリオはどうでしょうか?持っている!たとえば、この読み取りインターフェイスはデータベースに多大な負荷をかけますが、同時にホット データでもあります。このとき、「いいね」の数、コレクションの数、アシスタント製品の 1 つの共有。これは非常に一般的なホット データですが、変化し続けます。現時点では、データベースへの負荷を軽減するために、データを Redis キャッシュに同期的に保存する必要があります。
Memcache と Redis の違いは何ですか?
1). 保存方法 Memecache はすべてのデータをメモリに保存します。停電後はハングアップします。データはメモリ サイズを超えることはできません。 Redis の一部はハードディスクに保存されており、redis はそのデータを永続化できます
2). データ サポート タイプ memcached のすべての値は単純な文字列です. その代わりに、redis はより豊富なデータ型をサポートし、 list 、 storage を提供しますset、zset、hash およびその他のデータ構造の
3). 使用される基礎となるモデル、基礎となる実装方法、およびクライアントと通信するためのアプリケーション プロトコルが異なります。一般的なシステムがシステム関数を呼び出すと、移動やリクエストに一定の時間が無駄になるため、Redis は独自の VM メカニズムを直接構築しました。
4). 値のサイズは異なります: Redis は最大 512M に達しますが、memcache はわずか 1MB です。
5) Redis の速度は memcached よりもはるかに高速です
6) Redis はデータ バックアップ、つまりマスター/スレーブ モードでのデータ バックアップをサポートしています。
なぜシングルスレッド Redis は非常に速いのですか?
(1) 純粋なメモリ操作
(2) シングルスレッド操作、頻繁なコンテキスト切り替えを回避
(3) 非スレッドの使用- ブロッキング I/O 多重化の仕組み
redis のデータ型と各データ型の利用シナリオ
答え: 5 種類あります
(1)String
This最も一般的な set/get 操作では、value は文字列または数値のいずれかになります。一般に、一部の複雑なカウント関数はキャッシュされます。
(2)hash
ここの値には構造化オブジェクトが格納されており、その中の特定のフィールドを操作する方が便利です。ブロガーがシングル サインオンを行う場合、このデータ構造を使用してユーザー情報を保存し、cookieId をキーとして使用し、キャッシュの有効期限を 30 分に設定します。これにより、セッションのような効果を非常によくシミュレートできます。
(3) list
List のデータ構造を利用して、簡単なメッセージキュー機能を実行できます。もう 1 つは、lrange コマンドを使用して Redis ベースのページング機能を実装できることです。これは優れたパフォーマンスと優れたユーザー エクスペリエンスを備えています。また、私は市場情報を取得するという非常に適したシナリオを使用します。それは生産者と消費者の現場でもあります。 LIST は、キューイングと先入れ先出しの原則を非常にうまく実装できます。
(4)set
set は一意の値のコレクションであるためです。したがって、グローバル重複排除機能を実現することができる。重複排除のために JVM に付属するセットを使用してみてはいかがでしょうか?システムは通常クラスタでデプロイされるため、JVM に付属の Set を使用するのは面倒ですが、グローバル重複排除を行うためだけにパブリック サービスをセットアップするのは面倒ですか?
さらに、交差、和集合、差分などの演算を使用して、共通の設定、すべての設定、独自の独自の設定、その他の関数を計算することができます。
(5) ソートセット
ソートセットには追加の重みパラメータスコアがあり、セット内の要素をスコアに従って配置できます。ランキングアプリを作成してTOPNを取ることができます。
Redis の内部構造
dict は本質的にアルゴリズム (検索) で検索問題を解決するために使用されるデータ構造であり、キーとキー間のマッピング関係を維持するために使用されます。多くの言語の地図や辞書は似ています。本質的には、アルゴリズム
sds で検索問題 (検索) を解決することです。sds は char * と同等です。任意のバイナリ データを格納できますが、文字 '\ で表すことはできません。 C 言語の文字列と同様に、0' は文字列の終わりを識別するため、長さフィールドが必要です。
skiplist (スキップ リスト) スキップ リストは、実装が非常に簡単な単層マルチポインタ リンク リストで、最適化されたバイナリ バランス ツリーに匹敵する高い検索効率を備えています。バランスツリーの実装と比較すると、
quicklist
ziplist 圧縮テーブルの ziplist は、一連のコードで構成されるエンコードされたリストです。特殊なエンコーディング 連続したメモリ ブロックで構成されるシーケンシャル データ構造、
redis の有効期限戦略とメモリ削除メカニズム
redis は 定期削除戦略と遅延削除戦略を採用しています。
スケジュールされた削除戦略を使用してみてはいかがでしょうか?
スケジュールされた削除では、タイマーを使用してキーを監視し、期限が切れると自動的に削除されます。メモリは時間内に解放されますが、大量の CPU リソースを消費します。大規模な同時リクエストでは、CPU はキーを削除する代わりにリクエストの処理に時間を費やす必要があるため、この戦略は採用されません。遅延削除は機能しますか? 削除では、redis はデフォルトで 100 ミリ秒ごとに期限切れのキーがあるかどうかを確認し、期限切れのキーがある場合は削除します。 redis は 100 ミリ秒ごとにすべてのキーをチェックするのではなく、ランダムにそれらを選択して検査することに注意してください (すべてのキーが 100 ミリ秒ごとにチェックされる場合、redis はスタックしないでしょうか)。したがって、通常の削除戦略のみを採用した場合、多くのキーはそれまでに削除されません。
したがって、遅延削除が便利です。つまり、有効期限が設定されている場合、キーを取得すると、Redis はキーの有効期限が切れているかどうかを確認します。有効期限が切れた場合は、この時点で削除されます。 通常の削除と遅延削除には他に問題はありませんか? いいえ、通常の削除でキーが削除されない場合は問題ありません。この場合、キーをすぐに要求しませんでした。つまり、遅延削除は有効になりませんでした。このようにして、redis のメモリはどんどん増えていきます。その場合は、メモリ削除メカニズムを採用する必要があります。
redis.conf に設定の行があります
maxmemory-policy volatile-lru
この設定はメモリ削除戦略で設定されています (何、設定していないのですか?よく考えてください)
volatile-lru
: 削除する有効期限が設定されたデータ セット (server.db[i].expires) から、最も最近使用されていないデータを選択します。
volatile-ttl: 選択します。有効期限が設定されたデータ セットから最も最近使用されていないデータ データ セット (server.db[i].expires) から有効期限が切れるデータを選択して、
volatile-random: From有効期限を設定したデータセット (server.db[i].expires) データ削除をランダムに選択
allkeys-lru: データセット (server.db) から最も最近使用されていないデータを選択します[i].dict) を削除します
allkeys-random: データセット (server.db[i].dict) から任意のデータを選択して
no-enviction# を削除します## (エビクション): データのエビクションを禁止します。新しい書き込み操作ではエラーが報告されます。 ps : 有効期限キーが設定されておらず、前提条件が満たされていない場合、volatile-lru、volatile-random、およびvolatile-ttl 戦略は基本的に noeviction (削除なし) と同じです。
Redis がシングルスレッドである理由公式 FAQ には、Redis はメモリベースの操作であるため、CPU が Redis のボトルネックではないと記載されています。Redis のボトルネックはおそらくサイズです。マシンのメモリまたはネットワーク帯域幅。シングルスレッドは実装が簡単で、CPU がボトルネックにならないため、シングルスレッド ソリューションを採用するのが合理的です (結局のところ、マルチスレッドを使用すると多くのトラブルが発生します!) Redis はキュー テクノロジを使用して、同時アクセスからシリアル アクセスへの変換
1) ほとんどのリクエストは純粋なメモリ操作 (非常に高速) 2) シングルスレッドで、不必要なコンテキスト スイッチや競合状態を回避します
1. 高速データはメモリ内に存在するため、HashMap と同様に、HashMap の利点は、検索と操作の時間計算量が O(1)
2 であることです。豊富なデータ型をサポートし、文字列、リスト、セット、ソートされたセット、ハッシュをサポートします。 3 .サポート トランザクションと操作はすべてアトミックです。いわゆるアトミックとは、データに対するすべての変更が実行されるか、まったく実行されないかのどちらかであることを意味します。
4. 豊富な機能: キャッシュ、メッセージング、設定に使用可能キーごとの有効期限、有効期限が切れると自動的に削除されます redis での同時キー競合の問題を解決する方法
複数のサブシステムが同時にキーを設定しています。このとき私たちは何に注意すべきでしょうか? Redis トランザクション メカニズムを使用することはお勧めできません。本番環境は基本的に Redis クラスター環境であるため、データのシャーディング操作が実行されます。トランザクションに複数のキー操作が含まれる場合、これらの複数のキーは必ずしも同じ redis サーバーに保存されるとは限りません。したがって、redis のトランザクション機構は非常に役に立ちません。
(1) このキーを操作する場合、順序は必要ありません。分散ロックを準備し、全員がロックを取得し、ロックを取得した後に set 操作を実行するだけです。
(2) これを操作する場合キー、順序は必須です: 分散ロックのタイムスタンプ。システム B が最初にロックを取得し、key1 を {valueB 3:05} に設定すると仮定します。次に、システム A がロックを取得し、その valueA のタイムスタンプがキャッシュ内のタイムスタンプよりも古いことが判明したため、セット操作は実行されません。等々。
(3) キューを使用して set メソッドをシリアル アクセスに変えると、redis が高い同時実行性を実現できるようになります。キーの読み取りと書き込みの一貫性が確保されている場合、
Redis クラスター ソリューションでは何をすべきですか?計画は何ですか?
1.twemproxy の一般的な概念は、プロキシ メソッドに似ています。使用すると、redis を接続する必要がある場所が twemproxy に接続するように変更されます。リクエストをプロキシとして受信し、一貫したハッシュ アルゴリズムを使用し、リクエストを特定の redis に転送し、結果を twemproxy に返します。
欠点: twemproxy 独自のシングルポート インスタンスの圧力により、コンシステント ハッシュを使用した後、redis ノードの数が変わると計算値が変わり、データを新しいノードに自動的に移動できなくなります。現在最も一般的に使用されているクラスター ソリューションである
2.codis は、基本的には twemproxy と同じ効果がありますが、ノード数が変わった場合に古いノード データを新しいハッシュ ノードに復元する機能をサポートしています
3. rediscluster3.0に付属するクラスタは、分散アルゴリズムがコンシステンシーハッシュではなくハッシュスロットの概念を採用しているのが特徴で、ノード設定のスレーブノードをサポートしています。詳細については公式ドキュメントを参照してください。
マルチマシン Redis をデプロイしてみましたか?データの一貫性を確保するにはどうすればよいでしょうか?
マスター/スレーブ レプリケーション、読み取りと書き込みの分離
1 つはマスター データベース (マスター)、もう 1 つはスレーブ データベース (スレーブ) であり、マスター データベースは読み取りおよび書き込み操作を実行できます。操作が発生すると、データは自動的にスレーブ データベースに同期されます。スレーブ データベースは通常読み取り専用で、マスター データベースから同期されたデータを受け取ります。マスター データベースは複数のスレーブ データベースを持つことができますが、スレーブ データベースはマスターを 1 つだけ持つことができますデータベース。
大量のリクエストに対処する方法
redis はシングルスレッド プログラムです。つまり、同時に 1 つのクライアント リクエストのみを処理できます。
redis は多重化されています。 IO を使用して (select、epoll、kqueue、さまざまなプラットフォームに基づくさまざまな実装) を使用して
Redis の一般的なパフォーマンスの問題と解決策を処理しますか?
(1) マスターは、RDB メモリ スナップショットや AOF ログ ファイルなどの永続化作業を行わないことが最善です
(2) データが重要な場合、スレーブは AOF バックアップ データとポリシーを有効にします。毎秒 1 回同期するように設定されています
(3) マスター/スレーブ レプリケーションの速度と接続の安定性を考慮すると、マスターとスレーブが同じ LAN 内にあることが最適です
(4) 次のことを試してください。大きなプレッシャーにさらされているマスター ライブラリにスレーブ ライブラリを追加することは避けてください
(5) マスター/スレーブ レプリケーションにグラフ構造を使用しないでください。一方向リンク リスト構造、つまりマスター < を使用する方が安定しています。 ;- Slave1 Slave3…
Redis スレッド モデルにおける
ファイル イベント ハンドラーには、 ソケット、I/O マルチプレクサー、ファイル イベント ディスパッチャーが含まれます(ディスパッチャ)、およびイベント ハンドラ 。 I/O マルチプレクサを使用して、複数のソケットを同時にリッスンし、現在実行しているタスクに基づいて、異なるイベント ハンドラをソケットに関連付けます。監視対象のソケットが接続応答(accept)、読み取り(read)、書き込み(write)、クローズ(close)などの操作を実行できる状態になると、その操作に対応したファイルイベントが生成されます。ファイル イベント ハンドラーは、ソケットに以前に関連付けられていたイベント ハンドラーを呼び出して、これらのイベントを処理します。
I/O マルチプレクサは、複数のソケットをリッスンし、イベントを生成したソケットをファイル イベント ディスパッチャに配信する役割を果たします。
動作原理:
1) I/O マルチプレクサは、複数のソケットをリッスンし、イベントを生成したソケットをファイル イベント ディスパッチャに送信する役割を果たします。
複数のファイル イベントが同時に発生する可能性がありますが、I/O マルチプレクサは常にイベントを生成するすべてのソケットをキューに入れ、このキューを通過して、一度に 1 ソケットずつ (順次) 同期的に (同期的に) 順序付けします。ファイル イベント ディスパッチャに送信されます。前のソケットによって生成されたイベントが処理された後 (ソケットがイベントに関連付けられ、イベント ハンドラが実行されました)、I/O マルチプレクサは次のソケットをファイル イベント ディスパッチャに渡し続けます。 。ソケットが読み取り可能と書き込み可能の場合、サーバーは最初にソケットを読み取り、次にソケットを書き込みます。 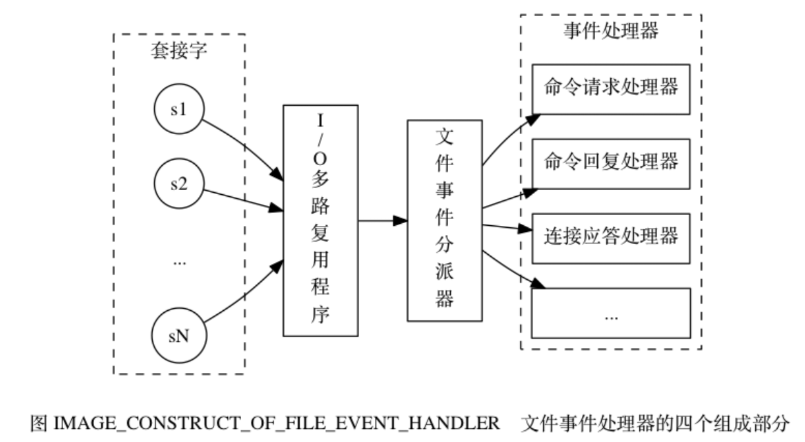 Redis の場合、コマンドのアトミック性は、操作を細分化することができず、操作が実行されるか実行されないかを意味します。
Redis の場合、コマンドのアトミック性は、操作を細分化することができず、操作が実行されるか実行されないかを意味します。
Redis 自体が提供するすべての API はアトミック操作であり、Redis のトランザクションは実際にバッチ操作のアトミック性を保証します。
複数のコマンドは同時実行でアトミックですか? 必ずしも必要ではありませんが、get と set を単一のコマンド操作に変更します。 Redis トランザクションを使用するか、Redis Lua== を使用して実装します。
Redis トランザクション
Redis トランザクション関数は、MULTI、EXEC、DISCARD、WATCH の 4 つのプリミティブによって実装されます。
Redis は、トランザクション内のすべてのコマンドをシリアル化し、順番に実行します。
1.redis はロールバックをサポートしていません 「Redis はトランザクションが失敗したときにロールバックしませんが、残りのコマンドを実行し続けます」ため、Redis の内部はシンプルかつ高速なままになります。
2. トランザクション内の コマンド でエラーが発生した場合、 すべてのコマンド は実行されません;
3. トランザクション ## でエラーが発生した場合# 実行エラー の場合、正しいコマンドが実行されます。 注: Redis の破棄はこのトランザクションを終了するだけであり、正しいコマンドの影響はまだ存在します。
2) EXEC: すべてのトランザクション ブロックでコマンドを実行します。トランザクションブロック内のすべてのコマンドの戻り値をコマンド実行順に並べて返します。操作が中断されると、空の値 nil が返されます。
3) DISCARD を呼び出すことにより、クライアントはトランザクション キューをクリアしてトランザクションの実行を放棄することができ、クライアントはトランザクション状態から抜け出します。
4) WATCH コマンドは、Redis トランザクションにチェックアンドセット (CAS) 動作を提供できます。 1 つ以上のキーを監視できます。キーの 1 つが変更 (または削除) されると、それ以降のトランザクションは実行されず、EXEC コマンドが実行されるまで監視が継続されます。
キーが存在しない場合にのみ、キーの値を value に設定します。指定されたキーがすでに存在する場合、SETNX は何もアクションを実行しません
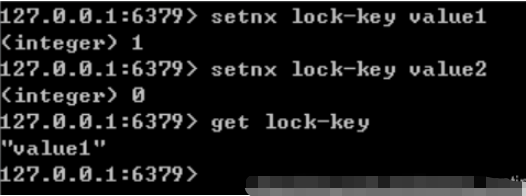
デッドロックの解決:
1) Redis 経由expire() で、ロックの最大保持時間を設定します。それを超えた場合、Redis がロックの解放を支援します。
2) これは、setnx キー「現在のシステム時刻ロック時刻」と getset キー「現在のシステム時刻ロック時刻」のコマンドの組み合わせを使用して実現できます。
以上がRedis 関連の問題を解決する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7518
7518
 15
1378
52
81
11
21
67
15
1378
52
81
11
21
67

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示するには、3つの方法があります。キーコマンドを使用して、指定されたパターンに一致するすべてのキーを返します。スキャンコマンドを使用してキーを繰り返し、キーのセットを返します。情報コマンドを使用して、キーの総数を取得します。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisサーバーを起動する手順には、以下が含まれます。オペレーティングシステムに従ってRedisをインストールします。 Redis-Server(Linux/Macos)またはRedis-Server.exe(Windows)を介してRedisサービスを開始します。 Redis-Cli ping(Linux/macos)またはRedis-Cli.exePing(Windows)コマンドを使用して、サービスステータスを確認します。 Redis-Cli、Python、node.jsなどのRedisクライアントを使用して、サーバーにアクセスします。
