

SQL ステートメントにインデックスを作成する場合、インデックスのエラーが発生し、ステートメントの実現可能性とパフォーマンス効率に重大な影響を及ぼします。この記事ではそれを分析しますインデックスを作成する理由失敗、どのような状況が インデックス失敗につながるか、およびインデックス失敗時の 最適化ソリューション (左端のプレフィックス マッチング原則に焦点を当てます), MySQL の論理アーキテクチャとオプティマイザー 、インデックス障害のシナリオとその理由。
以前、MySQL へのインデックス追加の特徴と最適化の問題について記事を書きましたが、ここではインデックスの失敗に関する内容を紹介します。
最初に、後続のインデックス失敗の理由で使用される原則を紹介します: 左端のプレフィックス マッチングの原則。
左端のプレフィックスの基本原則: MySQL が結合インデックスを構築するとき、左端のプレフィックス マッチング原則、つまり左端の優先順位に従います。データを取得するとき、マッチングは左端から開始されます。ジョイントインデックス。
左端のプレフィックス マッチングの原則は何ですか?結合インデックスの左端のマッチング原理を理解するために、まずインデックスの基礎となる原理を理解しましょう。インデックスの最下層は B ツリーであり、結合インデックスの最下層も B ツリーです。ただし、ジョイントインデックスのBツリーノードにはキー値が格納されます。 B ツリーは 1 つの値に基づいてのみインデックス関係を決定できるため、データベースは結合インデックスの左端のフィールドに基づいて構築する必要があります。
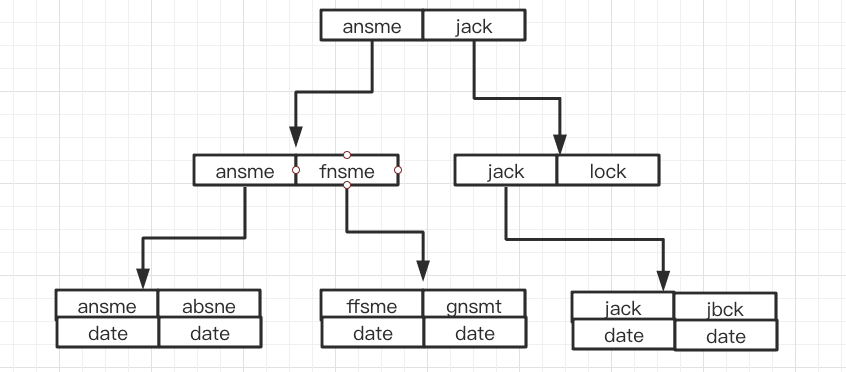
例: (a, b) の結合インデックスを作成すると、そのインデックス ツリーは次の図のようになります。
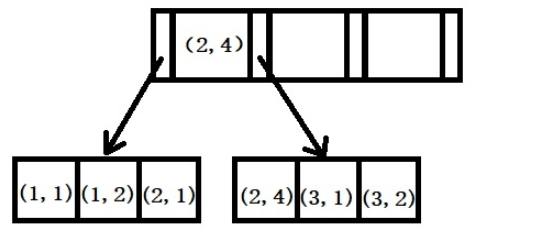
a の値は順番に並んでおり、出現順は 1、1、2、2、3、3 となります。 b の値には順序がなく、表示される数字は 1、2、1、4、1、2 です。 a の値が等しい場合、b の値が特定の順序で配置されていることがわかりますが、この順序は相対的なものであることに注意してください。これは、結合インデックスを作成するための MySQL のルールが、まず最初のフィールドの並べ替えに基づいて結合インデックスの左端のフィールドを並べ替え、次に 2 番目のフィールドを並べ替えることであるためです。したがって、b=2 などのクエリ条件にインデックスを使用する方法はありません。
プロセス全体は Explain 結果の分析に基づいているため、Explain の type フィールドと key_lef フィールドについて学びましょう。
1.type: 接続タイプ。
system: テーブルにはレコードが 1 行しかありません (システム テーブルと同じです)。これは const 型の特殊なケースです。通常は表示されないため、無視できます。
ref: 非一意インデックス スキャンなど) は、単一の値に一致するすべての行を返します。基本的には、単一の値に一致するすべての行を返すインデックス アクセスですが、複数の一致する行が見つかる場合があるため、検索とスキャンを組み合わせて行う必要があります。
range: インデックスを使用して行を選択し、指定された範囲内の行のみを取得します。キー列は、どのインデックスが使用されているかを示します。一般に、bettween、、in などのクエリは where ステートメントに現れます。インデックス列に対するこの範囲スキャンは、完全なインデックス スキャンよりも優れています。インデックス全体をスキャンする必要はなく、特定のポイントで開始し、別のポイントで終了するだけで済みます。
index: フル インデックス スキャン。インデックスと ALL の違いは、インデックス タイプがインデックス ツリーのみをスキャンすることです。インデックス ファイルは通常データ ファイルよりも小さいため、これは通常 ALL ブロックです。 (Index と ALL はどちらもテーブル全体を読み取りますが、index はインデックスから読み取られ、ALL はハードディスクから読み取られます)
: MySQL が実際に使用することを決定したインデックスの長さを表示します。インデックスが NULL の場合、長さは NULL になります。 NULL でない場合は、使用されるインデックスの長さ。したがって、このフィールドを使用して、どのインデックスが使用されているかを推測できます。
計算ルール:
MySQL 論理アーキテクチャ:
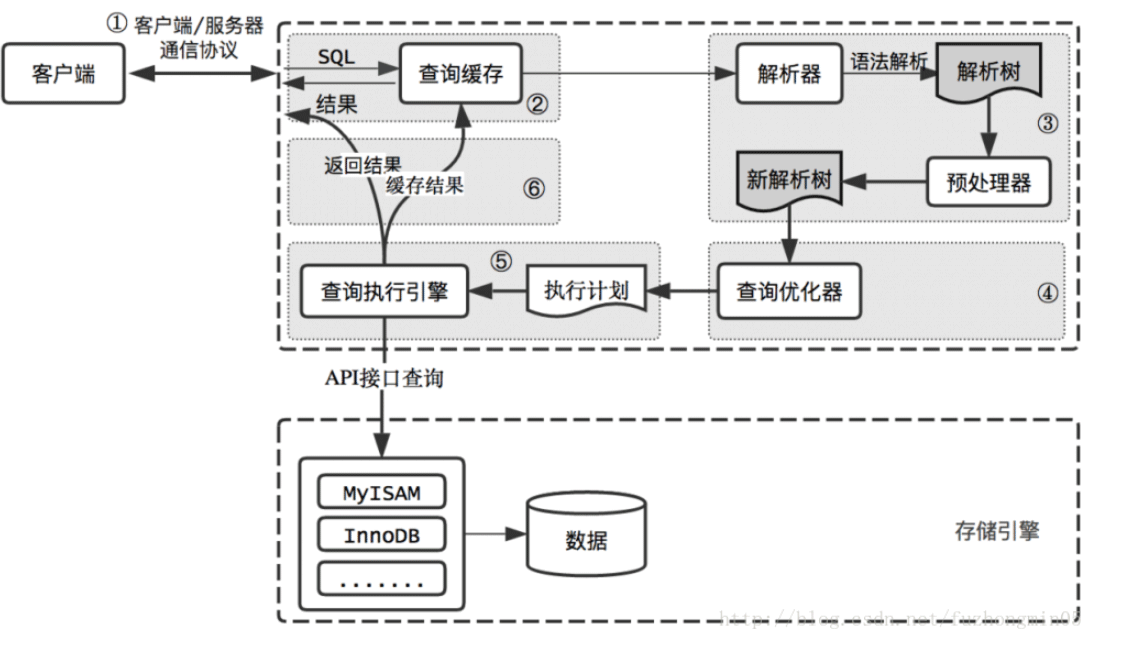
mysql アーキテクチャは次のように分割できます。大まかに 4 つのレイヤーがあります。
Client: さまざまな言語が、jdbc などの mysql データベースに接続するメソッドを提供します。 、 php 、 go など、選択したバックエンド開発言語
サーバー層## に応じて、mysql に接続するための対応するメソッドまたはフレームワークを選択できます。 #: コネクタ、クエリ キャッシュ、アナライザー、オプティマイザー、エグゼキューターなどを含み、MySQL のコア サービス関数のほとんどと、すべての組み込み関数 (日付、ファミリー、数学関数、暗号化関数など) をカバーします。ストアド プロシージャ、トリガー、ビューなど、すべてのクロスストレージ エンジン機能がこのレイヤーに実装されます。
: データの保存と取得を担当し、基礎となる物理ファイルを実際に処理するコンポーネントです。データの本質はディスクに保存され、特定のストレージ エンジンを通じて組織的に保存され、ビジネス ニーズに応じて抽出されます。ストレージ エンジンのアーキテクチャ モデルはプラグインであり、Innodb、MyIASM、Memory などの複数のストレージ エンジンをサポートします。現在最も一般的に使用されているストレージ エンジンは Innodb で、mysql5.5.5 以降、デフォルトのストレージ エンジンとなっています。
: データベースの実テーブルデータやログなどを格納します。物理ファイルには、redolog、undolog、binlog、errorlog、querylog、slowlog、data、index などが含まれます。
1. コネクタ
コネクタクライアント接続からの接続、ユーザー権限の取得、接続の維持および管理を担当します。
ユーザーが接続を正常に確立した後、管理者アカウントを使用してユーザーの権限を変更しても、既存の接続の権限には影響しません。変更が完了すると、新しい接続のみが新しい権限設定を使用するようになります。
2. クエリ キャッシュmysql はクエリ リクエストを取得すると、まずクエリ キャッシュに移動して、このステートメントが以前に実行されたかどうかを確認します。以前に実行されたステートメントとその出力は、キーと値のペアとしてキャッシュされてメモリに直接保存される場合があります。キーはクエリ ステートメントであり、値はクエリ結果です。 SQL クエリのキーワードがクエリ キャッシュ内で直接一致する場合、クエリ結果 (値) がクライアントに直接返されます。
実際、ほとんどの場合、クエリ キャッシュを使用しないことをお勧めします。クエリ キャッシュは多くの場合、良いことよりも害を及ぼすためです。テーブルの更新操作が含まれる限り、テーブルに関連するすべてのクエリ キャッシュは簡単に無効になり、クリアされる可能性があります。したがって、結果を苦労して保存した後、使用する前に新しい更新操作によって消去される可能性が非常に高くなります。更新操作が多いデータベースの場合、クエリ キャッシュのヒット率は非常に低くなります。ビジネスで静的なテーブルが必要な場合を除き、テーブルは長い期間に 1 回だけ更新されます。たとえば、システム構成テーブルの場合、このテーブルのクエリはクエリ キャッシュの使用に適しています。
3. アナライザー字句解析 (キーワード、演算、テーブル名、列名の特定)
構文解析 (文法に準拠しているかどうかの判断)オプティマイザーは、テーブルに複数のインデックスがある場合、または 1 つのステートメントで複数のテーブルの関連付け (結合) がある場合に、どのインデックスを使用するかを決定します。各テーブルの接続順序を決定します。オプティマイザ フェーズが完了すると、このステートメントの実行計画が決定され、エグゼキュータ フェーズに入ります。
5. エグゼキューターが実行を開始するとき、最初にユーザーがこのテーブル T に対してクエリを実行する権限を持っているかどうかを判断する必要があります。そうでない場合は、権限なしエラーが返されます。クエリ キャッシュがヒットした場合、クエリ キャッシュが結果を返すときに権限の検証が行われます。また、クエリはオプティマイザーの前に事前チェックを呼び出して権限を検証します。権限がある場合は、テーブルを開いて実行を続行します。テーブルが開かれると、エグゼキューターはテーブルのエンジン定義に基づいてエンジンによって提供されるインターフェイスを呼び出します。一部のシナリオでは、エグゼキューターが 1 回呼び出され、エンジン内で複数の行がスキャンされるため、エンジンによってスキャンされた行の数と rows_examined
はまったく同じではありません。MySQL オプティマイザー
MySQL オプティマイザーは、コストベースの最適化 (コストベースの最適化) を使用し、SQL ステートメントを入力として受け取り、組み込みのコスト モデルを使用します。データ ディクショナリ情報とストレージ エンジンの統計情報によって、クエリ ステートメント、つまりクエリ プランを実装するためにどのステップが使用されるかが決まります。
大まかに言えば、MySQL サーバーはサーバー層とストレージ エンジン層の 2 つのコンポーネントに分かれています。このうち、オプティマイザーはストレージ エンジン API の上に位置するサーバー層で動作します。 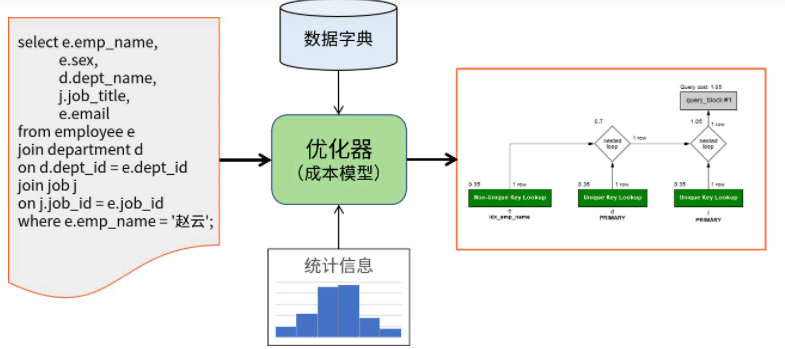
オプティマイザの作業プロセスは、意味的に次の 4 つの段階に分けることができます。
1.論理変換 (否定の削除、等しい値の転送と定数の転送、定数式の評価、外部結合から内部結合への変換、サブクエリ変換、ビューのマージなど);
2 .最適化の準備、インデックス参照やレンジアクセス方式の分析、クエリ条件のファンアウト値(ファンアウト、フィルタリング後のレコード数)分析、定数テーブルの検出など;
3.コストに基づく最適化 (アクセス方法と接続シーケンスの選択を含む);
4.実行計画の改善 (テーブル条件のプッシュダウン、アクセス方法の調整、ソート回避、インデックスなど)状態プッシュダウン。
1.ワイルドカード文字 % で始まるインデックスと同様に、失敗します。 上記は、左端のプレフィックス マッチングの基本原理を紹介しています。一般的に使用されるインデックス データ構造は B ツリーであり、インデックスは順序付けされていることがわかります。インデックス キーの型が Int 型 の場合、 インデックスは次の順序でソートされます。
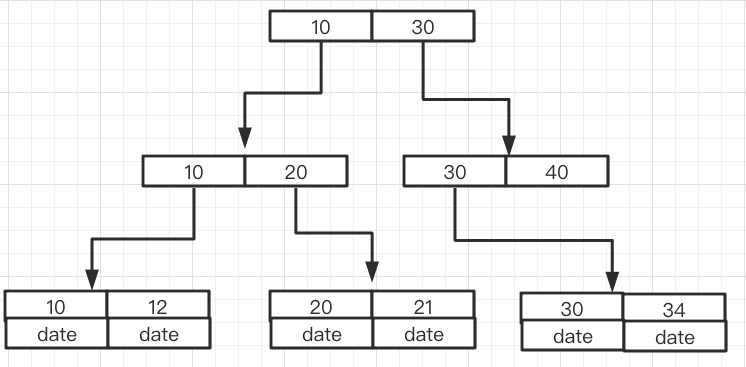
データは次のとおりです。 リーフ ノード にのみ保存され、 順序付けられた に配置されます。
インデックス キーワードの型が String 型 の場合、ソート順は次のようになります:
最初の文字 に基づいています。 ファジー クエリを実行するとき、前に % を付けると、左端の n 文字があいまいで不確実になります。インデックスの順序に基づいて特定のインデックスを正確に見つけることはできません。完全なクエリのみを実行できます。テーブル スキャン条件に合うデータを探します。
(左端のプレフィックスの基本原則)
joint インデックス を使用する場合も同様です。インデックスの順序付けの規則に違反すると、インデックスも次のようになります。無効です。完全なテーブルスキャン。 例: テーブルの例には結合インデックスがあります: (A, B, C)
SELECT * FROM example WHERE A=1 and B =1 and C=1;
次のことができます。インデックスを使用します ; SELECT A FROM example WHERE C =1 and B=1 ORDER BY A; インデックスを使用できます (カバーインデックスが使用されます)
SELECT * FROM example WHERE C =1 and B=1 ORDER BY A; CannotGo through the Index
インデックスには、クエリのニーズを満たすすべてのデータが含まれています。カバー インデックス (Covering Index) と呼ばれます):方法は 2 つあります
最適化
1 つは カバー インデックスを使用する 、2 つ目は
の後ろに % を入れます。 2.フィールド タイプは文字列であり、where は引用符で囲まれていません。
例: テーブルの例には、pid が varchar 型であるフィールドがあります。 <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>//此时执行语句type为ALL全表查询
explain SELECT * FROM example WHERE pid = 1</pre><div class="contentsignin">ログイン後にコピー</div></div><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>//此时执行语句type为ref索引查询
explain SELECT * FROM example WHERE pid = &#39;1&#39;</pre><div class="contentsignin">ログイン後にコピー</div></div>最初のステートメントが一重引用符を追加しないとインデックス付けされないのはなぜですか?これは、一重引用符が追加されていない場合、比較は文字列と数値の間で行われ、型が一致しないためです。MySQL は
暗黙的
3.OR の前後にインデックス以外の列がある限り、インデックスは失敗します。
例: テーブルの例には、pid が int 型で、score が int 型であるフィールドがあります。 <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>//此时执行语句type为ref索引查询
explain SELECT * FROM example WHERE pid = 1</pre><div class="contentsignin">ログイン後にコピー</div></div><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>//把or条件加没有索引的score,并不会走索引,为ALL全表查询
explain SELECT * FROM example WHERE pid = 1 OR score = 10</pre><div class="contentsignin">ログイン後にコピー</div></div>OR の後にインデックスなしのスコアが続く場合は、p_id インデックスを使用すると想定されますが、スコアのクエリ条件に関しては、テーブル全体をスキャンする必要があります。これには 3 段階のプロセスが必要です。 :
フル テーブル スキャン インデックス スキャン マージ。
Mysql にはオプティマイザがあり、効率とコストの観点から、OR 条件に遭遇したときにインデックスが失敗する可能性があるのは当然です。
注
4.結合インデックス(結合インデックス)の場合、クエリ時の条件列が結合インデックスの最初の列ではない場合、インデックスは無効になります。
(k1,k2,k3) などの結合インデックスを作成すると、3 つのインデックス (k1)、(k1,k2)、(k1,k2,k3) を作成するのと同じになります。これは左端の一致です。原理。 例: 結合インデックス idx_pid_score があり、最初に pid、2 番目にスコアが付いています。
//此时执行语句type为ref索引查询,idx_pid_score索引 explain SELECT * FROM example WHERE pid = 1 OR score = 10
//此时执行语句type为ref索引查询,idx_pid_score索引 explain SELECT * FROM example WHERE pid = 1
//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE score = 10
計算、関数、型変換 (自動または手動) によりインデックスが失敗します。インデックス フィールドに (!= または < >, not in) を使用すると、インデックスが失敗する可能性があります。 。
Birthtime にはインデックスが付けられていますが、mysql の組み込み関数 Date_ADD() を使用しているため、インデックスはありません。 例: テーブルの例では、idx_birth_time インデックスは datetime 型の Birthtime フィールドです。
//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE Date_ADD(birthtime,INTERVAL 1 DAY) = 6
//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE score-1=5
还有不等于(!= 或者<>)导致索引失效。
例子:在表example中有int类型的score字段索引idx_score
//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE score != 2
//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE score <> 3
虽然score 加了索引,但是使用了!= 或者 < >,not in这些时,索引如同虚设。
6. is null可以使用索引,is not null无法使用索引。
例子:在表example中有varchar类型的name字段索引idx_name,varchar类型的card字段索引idx_card。
//此时执行语句type为range索引查询 explain SELECT * FROM example WHERE name is not null
//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE name is not null OR card is not null
7.左连接查询或者右连接查询查询关联的字段编码格式不一样。两张表相同字段外连接查询时字段编码格式不同则会不走索引查询。
例子:在表example中有varchar类型的name字段编码是utf8mb4,索引为idx_name
在表example_two中有varchar类型的name字段编码为utf8,索引为idx_name。

//此时执行语句example表会走type为index类型索引,example_two则为ALL全表搜索不走索引 explain SELECT e.name,et.name FROM example e LEFT JOIN example_two et on e.name = et.name
当把两表的字段类型改为一致时:
//此时执行语句example表会走type为index类型索引,example_two会走type为ref类型索引 explain SELECT e.name,et.name FROM example e LEFT JOIN example_two et on e.name = et.name
所以字段类型也会导致索引失效
8.mysql估计使用全表扫描要比使用索引快,则不使用索引。当表的索引被查询,会使用最好的索引,除非优化器使用全表扫描更有效。优化器优化成全表扫描取决与使用最好索引查出来的数据是否超过表的30%的数据。建议:不要给’性别’等增加索引。如果某个数据列里包含了均是"0/1"或“Y/N”等值,即包含着许多重复的值,就算为它建立了索引,索引效果不会太好,还可能导致全表扫描。
Mysql出于效率与成本考虑,估算全表扫描与使用索引,哪个执行快,这跟它的优化器有关。
以上がMySQL インデックスの障害を解決する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



