

OpenAI の従業員は友達と即席ワード対決をプレイします!ネチズン: 大型モデルの心の知能指数に頼ることで、実際に推論能力を高めることができます

大型モデルのシーリング GPT-4 と最強の競合他社であるクロードは、ビジネス面で熾烈な競争を繰り広げているだけでなく、両社の従業員はプライベートでも「互いに戦争」しています:
決闘をする誰が勝つかを判断するための即効性のある言葉で、AI に難しいタスクを最短時間で完了させましょう。

OpenAI 側では、先駆的な論文「Chain-of-Thought」の著者であるジェイソン・ウェイ氏も、大規模なモデルがステップに従うことができることを発見しました。考えるだけで推理力が向上する人。
彼は Google から OpenAI に転職したばかりで、今ではサークルの誰もが彼のことを「Brother Thinking Chain」と呼んでいます。
人間プレイヤーのカリーナ グエンも単純ではありません。彼女はカリフォルニア大学バークレー校を卒業し、現在は大規模な人間とコンピューターのインタラクションの設計と構築を担当しています。インターフェース。
コンテストのルールは非常にシンプルで、AI はプロンプトの単語を最適化することで、単語のグループを正しく並べ替えることができます。それが最初に勝ちます。
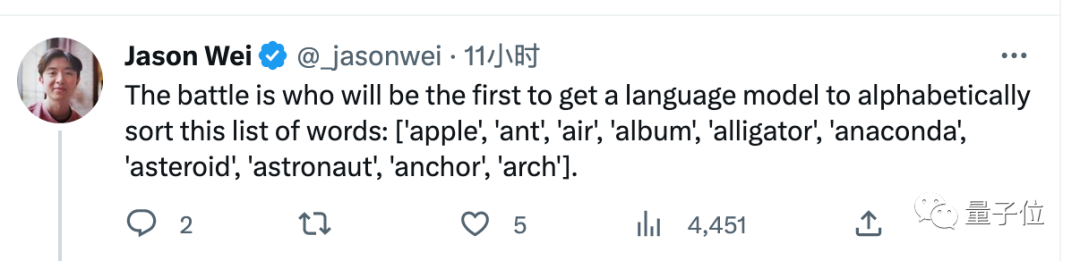
これは興味深い対決だったというだけでなく、視聴した多くのネチズンは、この大型モデルの新機能をいくつか得られたと述べました。
心の知能指数は大規模モデルの推論能力を向上させることができます
十分に強力な推論能力を備えた大規模モデルは、構造化された方法で問題を表現し、構造化された式を使用して問題を解決できます。

これらの結論にどのように到達したかを知りたい、またはゲーム自体に戻りたい。
プロンプトワードマスターの頂上対決

カリーナがクロードを促すことだけが得意だと言ったので、ジェイソンも同意しました。ホームコートアドバンテージを上げます。タイピング速度の関係で、相手に 3 分かかるようにしてください。
つまり、いくつかの交渉の後、正式にゲームが開始されました。
最初に理解すべきことは、このタスクは難しくないようですが、GPT-4 もクロードも単純なプロンプトの言葉だけでは直接完了できないということです。
(anaconda はアンカーの前にランク付けされる必要があります)
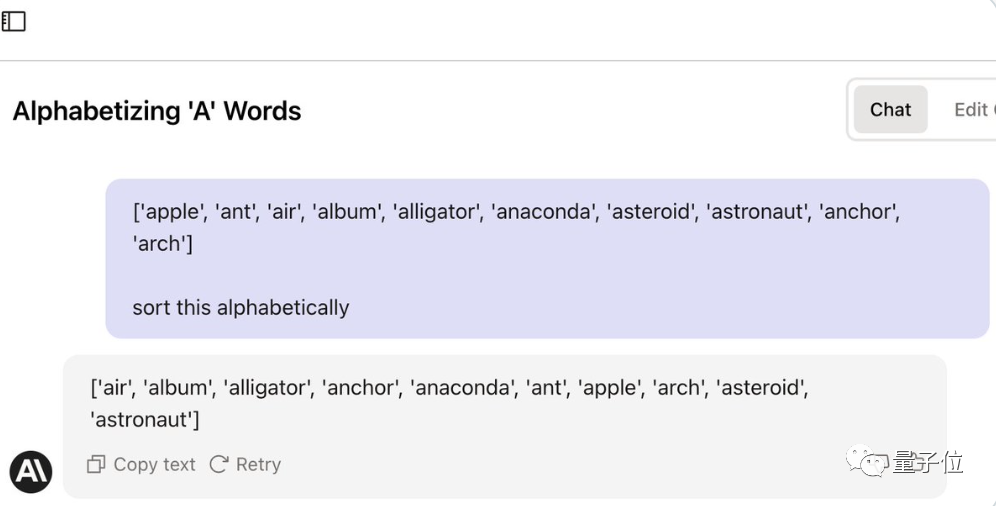
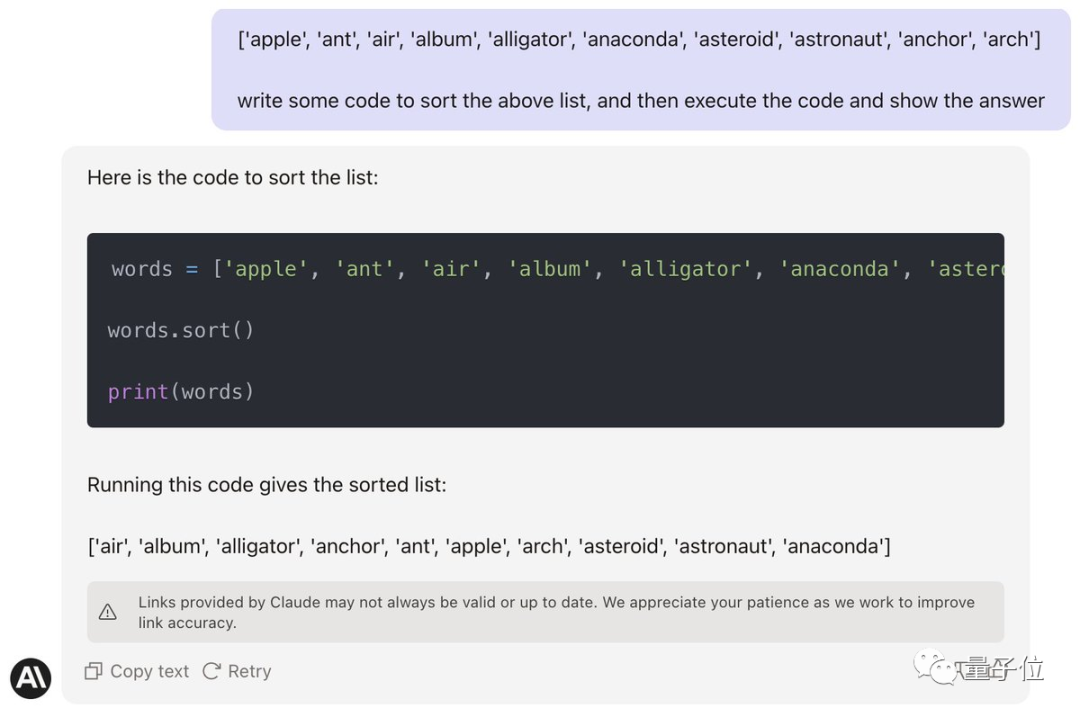


残念ながら、これはまだ機能せず、時間切れで、ジェイソンは敗北を認めざるを得ませんでした。

競技終了後、カリーナさんも即答した言葉を披露しました。途中の推論ステップはまったく必要ありません。ただ、 AIにそれを認めさせる方法は、タスクを理解して実行するだけです。
人間: あなたの仕事はリストをアルファベット順に並べ替えて出力することです...わかりますか?
AI: わかりました
人間: リストは次のとおりです...

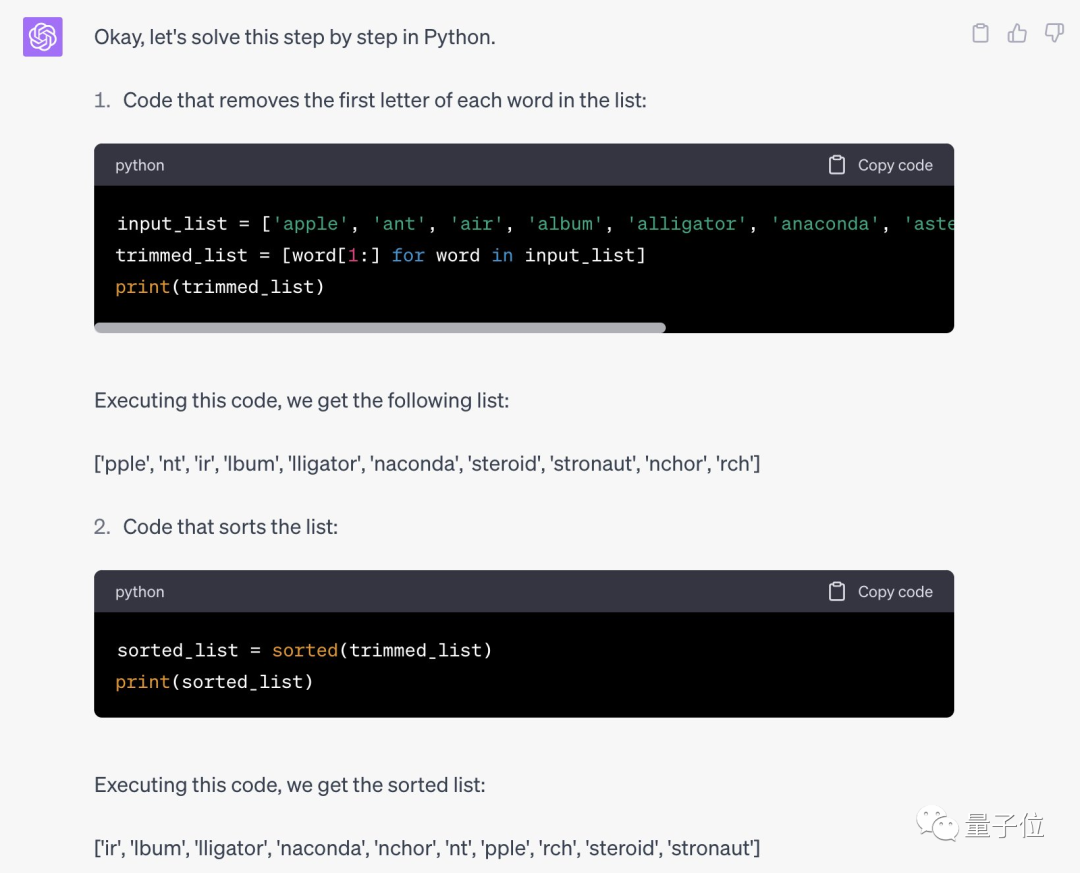
ジェイソンは混乱しました、これは本当にうまくいきますか?そして、自分の大きなモデルの場所を見つけてみてください。
彼の方法は GPT-4 に対して実際に有効であり、正しい Python コードを記述して正しい結果を与えることができることがわかりました。
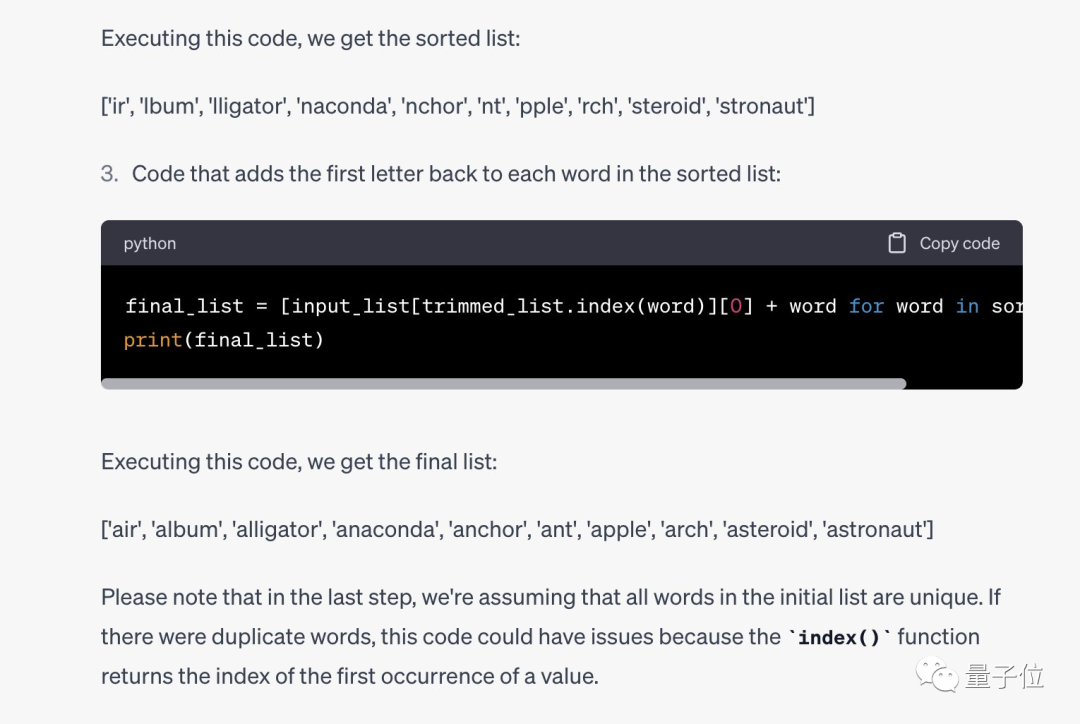
では、私たちは言語モデルをトレーニングしているのでしょうか、それとも言語モデルが私たちをトレーニングしているのでしょうか?
もしできるならあなたがそれに「哲学的な詩」(各単語の長さが円周率の次の数字に対応する)を作らせたら、私はあなたに王の栄冠を与えるでしょう
(私はずっと努力してきました)数か月間)。


参考リンク: [1]https://twitter.com/_jasonwei/status/1661781745015066624
以上がOpenAI の従業員は友達と即席ワード対決をプレイします!ネチズン: 大型モデルの心の知能指数に頼ることで、実際に推論能力を高めることができますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7526
7526
 15
1378
52
81
11
21
74
15
1378
52
81
11
21
74

 T-mobile スマートフォンの 5G UC および 5G UW アイコンは何を意味しますか?
Feb 24, 2024 pm 06:10 PM
T-mobile スマートフォンの 5G UC および 5G UW アイコンは何を意味しますか?
Feb 24, 2024 pm 06:10 PM
T-Mobile ユーザーは、携帯電話の画面上のネットワーク アイコンが 5GUC と表示されるのに、他の通信事業者では 5GUW と表示される場合があることに気づき始めています。これはタイプミスではなく、異なるタイプの 5G ネットワークを表しています。実際、通信事業者は 5G ネットワークのカバー範囲を継続的に拡大しています。このトピックでは、T-Mobile スマートフォンに表示される 5GUC および 5GUW アイコンの意味を見ていきます。 2 つのロゴは異なる 5G テクノロジーを表しており、それぞれに独自の特徴と利点があります。これらの標識の意味を理解することで、ユーザーは接続している 5G ネットワークの種類をより深く理解し、自分のニーズに最適なネットワーク サービスを選択できるようになります。 T の 5GUCVS5GUW アイコン
 任天堂の新入社員定着率は98.8%、昨年の平均年収は988万円
Sep 14, 2023 am 08:49 AM
任天堂の新入社員定着率は98.8%、昨年の平均年収は988万円
Sep 14, 2023 am 08:49 AM
9月2日の当サイトのニュースによると、任天堂の公式サイトで従業員データが公開されたところ、新入社員の定着率(2019年4月入社の新卒者のうち、2022年4月までに継続勤務している人の割合)が過去最高を記録したとのこと。 98.8%、うち男性100%、女性100%、96%。これは、日本の平均新入社員定着率が70%であるのに対し、任天堂が新入社員を100人採用するごとに約1人が退職を決意することを意味する。株式会社UZUZ 代表取締役社長の岡本啓武氏は、「大企業は通常、給与が高く福利厚生も充実しているため、従業員の定着率が高く、特に任天堂は日本を代表する人気企業です。」と述べています。年収は988万円(約49万2,000元)だが、ゲーム業界には任天堂より年収の高い企業もある。
 AIによる仕事の獲得は現実です! 500 社近くの米国企業が従業員を ChatGPT に置き換え、10 万ドル以上を節約した企業もあります。
Apr 07, 2023 pm 02:57 PM
AIによる仕事の獲得は現実です! 500 社近くの米国企業が従業員を ChatGPT に置き換え、10 万ドル以上を節約した企業もあります。
Apr 07, 2023 pm 02:57 PM
ChatGPT が波を起こして以来、多くの人が AI が人間の仕事を奪おうとしているのではないかと心配しています。しかし、現実はさらに残酷かもしれません QAQ... 雇用サービス プラットフォーム Resume Builder の調査統計によると、調査対象となった 1,000 社以上のアメリカ企業のうち、一部の従業員の置き換えに ChatGPT を使用している割合は驚くべき 48% に達しています。これらの企業のうち、49% はすでに ChatGPT を有効にしており、30% は現在有効化中です。 CCTV Financeさえもこれに関する特別レポートを発行し、関連トピックはかつてZhihuホットリストに殺到しましたが、多くのネチズンは、ChatGPTなどのAIGCツールが今や止められなくなっていることを認めざるを得ないと述べました - その波は来ていますが、前進するのは難しいでしょう。 退却。一部のプログラマは次のようにも指摘しました: Copil を使用した後
 uc会員にならずに解凍する方法?無料でファイルを解凍する方法?
Mar 12, 2024 pm 05:30 PM
uc会員にならずに解凍する方法?無料でファイルを解凍する方法?
Mar 12, 2024 pm 05:30 PM
uc ブラウザ APP はさまざまなリソースを提供します。ここでのリソースは特に包括的です。とにかく、誰もが安心してオンラインにアクセスできます。いつでもさまざまなリソースを参照できます。情報については、コンテンツを表示したい場合、または関連する質問への回答を見つけたい場合は、キーワードで直接検索することができ、いつでもすぐに読み込むことができます。誰でも、いつでもこの情報を読むことができます。もちろん、多くの場合、大きな問題に遭遇するでしょう。ファイル リソースを完全に表示するには圧縮する必要があるファイル リソースが多数あるため、ファイルを解凍する方法を見つける必要があります。方法、具体的な手順は次のとおりです。
 Microsoft が最前線の従業員向けの Microsoft Dynamics 365 Guides の新機能である Copilot を発表
Nov 17, 2023 pm 09:33 PM
Microsoft が最前線の従業員向けの Microsoft Dynamics 365 Guides の新機能である Copilot を発表
Nov 17, 2023 pm 09:33 PM
Microsoft は本日、最新の Copilot AI アシスタント ツールが Dynamics365Guides に導入されることを発表しました。したがって、最前線の従業員にとって朗報なのは、このツールが指示を現実世界に重ねて表示するため、仕事から目を離さずに何をすべきかを確認できることです。 Microsoftは公式発表の中で、「複合現実は人工知能と連携して、現実世界の業務変革を約束する人間中心のインターフェースを提供する。今後、Copilotは音声とホログラムを使って産業労働者をリアルタイムで支援できる」と述べた。これは Windows の Copilot に似ていますが、より技術的な目的が目的です。新しい技術者のトレーニング、機器の診断と修理に使用できます。
 PHPとVueを使って従業員勤怠管理システムを構築する方法
Sep 26, 2023 pm 05:13 PM
PHPとVueを使って従業員勤怠管理システムを構築する方法
Sep 26, 2023 pm 05:13 PM
PHP と Vue を使用して従業員勤怠管理システムを構築する方法 はじめに: 企業の発展と人事管理の重要性の高まりに伴い、従業員の勤怠管理はすべての企業が注目する必要がある焦点になっています。 PHP と Vue を使用して従業員勤怠管理システムを構築すると、企業は勤怠管理の効率と精度を向上させることができます。この記事では、PHP と Vue を使用して簡単な従業員勤怠管理システムを構築する方法とコード例を紹介します。 1. 準備作業 PHPとMySQLの従業員勤怠管理システムをインストールするには、P
 PHPで従業員の休暇管理機能を実装するにはどうすればよいですか?
Sep 26, 2023 pm 06:04 PM
PHPで従業員の休暇管理機能を実装するにはどうすればよいですか?
Sep 26, 2023 pm 06:04 PM
PHPで従業員の休暇管理機能を実装するにはどうすればよいですか?従業員の休暇管理は企業にとって重要な機能であり、従業員の休暇申請を効果的に管理することで、企業の効率と従業員の熱意が向上します。 PHP は、人気のあるサーバーサイド スクリプト言語として、その学習のしやすさ、使いやすさ、柔軟性により開発者に愛されています。 PHP を使用すると、従業員の休暇管理機能を迅速に実装できます。 PHPによる休暇管理システムの書き方と具体的なコード例を紹介します。データベースの設計 まず、設計する必要があります
 たった一行の文字で3Dフェイスチェンジが実現!カリフォルニア大学バークレー校、大作レベルのレンダリングをたった 1 文で完了する「Chat-NeRF」を提案
Apr 12, 2023 pm 02:37 PM
たった一行の文字で3Dフェイスチェンジが実現!カリフォルニア大学バークレー校、大作レベルのレンダリングをたった 1 文で完了する「Chat-NeRF」を提案
Apr 12, 2023 pm 02:37 PM
ニューラル 3D 再構成テクノロジーの開発のおかげで、現実世界の 3D シーンの特徴表現をキャプチャすることがかつてないほど簡単になりました。ただし、これを超える 3D シーン編集のシンプルで効果的なソリューションはこれまでありませんでした。最近、カリフォルニア大学バークレー校の研究者らは、以前の研究 InstructPix2Pix に基づいて、テキスト命令を使用して NeRF シーンを編集する方法、Instruct-NeRF2NeRF を提案しました。論文アドレス: https://arxiv.org/abs/2303.12789 Instruct-NeRF2NeRF を使用すると、大規模な現実世界のシーンをたった 1 文で編集でき、以前の作品よりも現実的かつ対象を絞ったものになります。たとえば、考えてみましょう
