

3D 点群、分類、検索、字幕、画像生成のオープンワールドの理解

ロッキングチェアと馬の 3 次元形状を入力すると、何が得られるでしょうか?


##木製カートと馬?馬車と電動馬、バナナと帆船を手に入れましょうか?バナナヨットを手に入れましょう。卵とデッキチェアはいかがですか?エッグチェアを手に入れましょう。
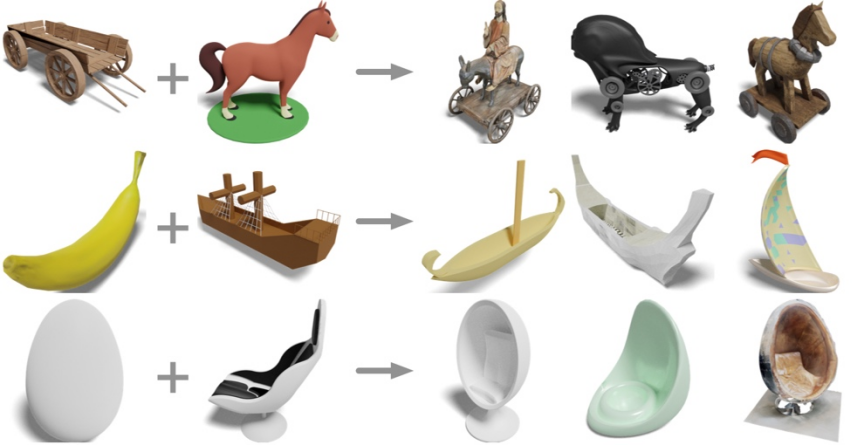
UCSD、上海交通大学、クアルコムのチームの研究者らは、最新の 3 次元表現モデル OpenShape を提案しました。 3次元形状のオープンワールド。
- #論文アドレス: https://arxiv.org/pdf/2305.10764.pdf
- プロジェクトのホームページ: https://colin97.github.io/OpenShape/
- インタラクティブ デモ: https://huggingface.co/spaces/OpenShape/openshape-demo
- コード アドレス: https://github.com/Colin97/OpenShape_code
#三次元形状ゼロショット分類
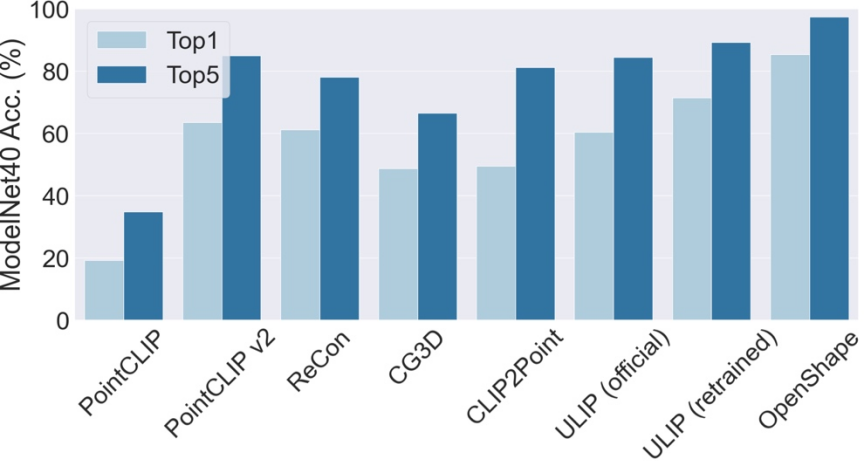
OpenShape の ModelNet40 でのトップ 3 とトップ 5 の精度は、それぞれ 96.5% と 98.0% に達しました。
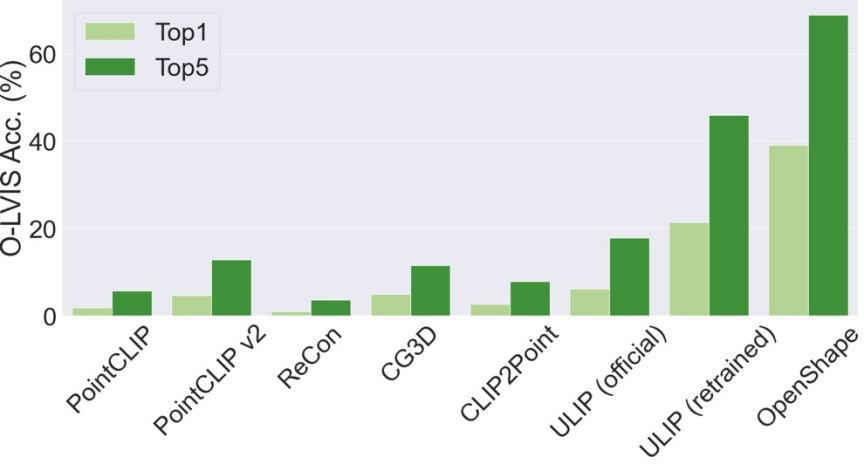
マルチモーダル 3D 形状検索
OpenShape のマルチモーダル表現を使用すると、ユーザーは画像、テキスト、または点群入力に対して 3D 形状検索を実行できます。入力表現と 3D 形状表現の間のコサイン類似度を計算し、kNN を見つけることにより、統合データセットからの 3D 形状の取得を研究します。

# #
上の図は、入力イメージと取得された 2 つの 3D 形状を示しています。

#テキスト入力の 3 次元形状検索
上の画像は、入力テキストと取得された 3 次元形状を示しています。 OpenShape は、幅広い視覚的および意味論的な概念を学習し、きめ細かいサブカテゴリ (最初の 2 行) と属性制御 (色、形状、スタイル、およびそれらの組み合わせなどの最後の 2 行) を可能にします。

#3D 点群入力の 3D 形状取得
上の図は、入力 3D 点群と 2 つの取得された 3D 形状を示しています。

上の図は 2 つの 3D 形状を入力として受け取り、その OpenShape 表現を使用して両方の入力に最も近い 3D 形状を同時に取得します。取得された形状は、両方の入力形状からの意味要素と幾何学的要素を巧みに組み合わせています。
3 次元形状ベースのテキストおよび画像の生成
OpenShape の 3 次元形状表現は CLIP の画像およびテキスト表現空間に合わせて配置されているため、これらを使用することができます。 CLIP からの派生モデルに基づく多くは、さまざまなクロスモーダル アプリケーションをサポートするために結合されます。
#3 次元点群の字幕生成
既製の画像字幕モデル (ClipCap) と組み合わせることで、OpenShape は 3D 点群の字幕生成を実装します。
#3 次元点群に基づく画像生成
既製のテキストから画像への拡散モデル (Stable unCLIP) と組み合わせることで、OpenShape は 3D 点群に基づく画像生成を実装します (オプションのテキスト ヒントをサポート)。
3 次元点群に基づく画像生成のその他の例

対比学習に基づくマルチモーダル表現の調整: OpenShape は、3D 点群は次のような 3D ネイティブ エンコーダーをトレーニングします。 3D 形状の表現を抽出するための入力として使用されます。以前の研究に続いて、マルチモーダル対比学習を活用して、CLIP の画像およびテキスト表現空間と整合させます。以前の研究とは異なり、OpenShape は、より一般的でスケーラブルなジョイント表現空間を学習することを目的としています。研究の焦点は主に、オープンワールドでの 3D 形状理解を真に実現するために、3D 表現学習の規模を拡大し、対応する課題に対処することです。
複数の 3D 形状データセットの統合: 大規模な 3D 形状表現の学習にはトレーニング データの規模と多様性が重要な役割を果たすため、この研究では、現在公開されている最大のデータセットに関する 4 つのトレーニングを統合しました。 3D データセット。以下の図に示すように、調査されたトレーニング データには 876,000 のトレーニング シェイプが含まれています。 4 つのデータセットのうち、ShapeNetCore、3D-FUTURE、および ABO には人間が検証した高品質の 3D 形状が含まれていますが、限られた数の形状と数十のカテゴリのみをカバーしています。 Objaverse データセットは、最近リリースされた 3D データセットで、より多くの 3D 形状が含まれ、より多様なオブジェクト クラスをカバーしています。しかし、Objaverse の形状は主にインターネット ユーザーによってアップロードされており、手動による検証が行われていないため、品質が不均一であり、配布が非常に不均一であり、さらなる処理が必要です。 
テキスト フィルタリングとエンリッチメント: 3D 形状と 2D 画像の間でのみ検出された研究 対照学習の適用大規模なデータセットでトレーニングした場合でも、3D 形状とテキスト空間の位置合わせを推進するには不十分です。研究によると、これは CLIP の言語空間と画像表現空間に固有のドメイン ギャップが原因であると推測されています。したがって、研究では 3D 形状をテキストと明示的に位置合わせする必要があります。ただし、元の 3D データ セットからのテキスト アノテーションは、コンテンツが欠落している、間違っている、粗い、単一のコンテンツであるなどの問題に直面することがよくあります。この目的を達成するために、この文書では、テキストをフィルタリングおよび強化してテキスト注釈の品質を向上させるための 3 つの戦略を提案します。GPT-4 を使用したテキスト フィルタリング、字幕生成、および 3D モデルの 2D レンダリングの画像取得です。
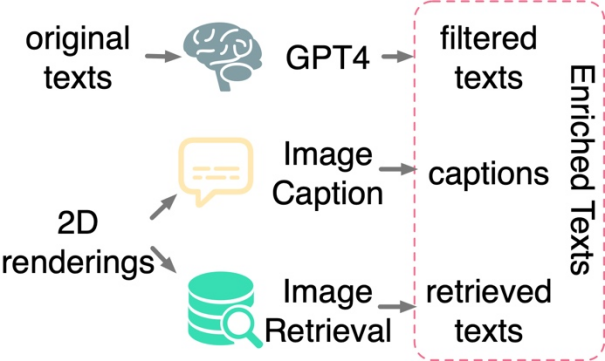
#調査では、自動的にフィルタリングして強化するための 3 つの戦略が提案されました。生のデータセット内のノイズの多いテキスト。
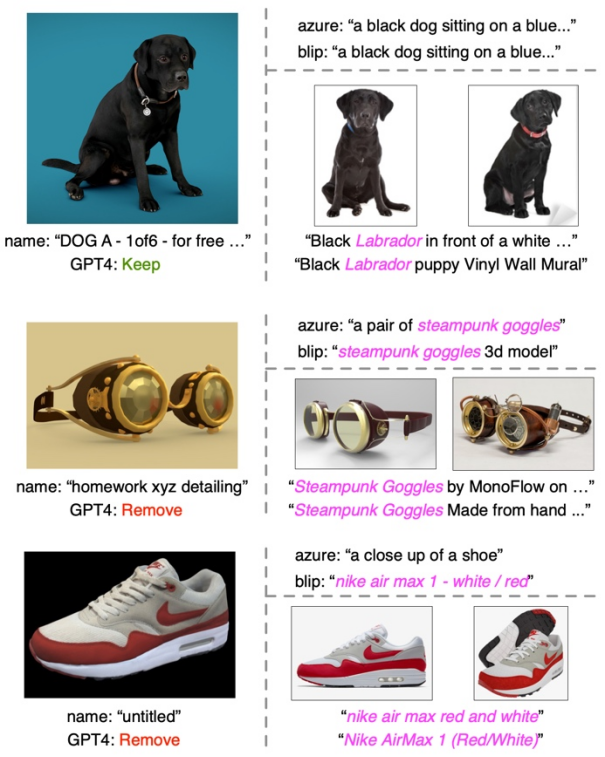
テキスト フィルタリングとエンリッチメントの例
各例の左側のセクションには、サムネイル、元の形状名、GPT-4 フィルター処理された結果が表示されます。右上部分には 2 つのキャプション モデルからの画像キャプションが表示され、右下部分には取得された画像とそれに対応するテキストが表示されます。
三次元基幹ネットワークを拡充します。 3D 点群学習に関する以前の研究は主に ShapeNet のような小規模な 3D データ セットを対象としていたため、これらのバックボーン ネットワークは大規模な 3D トレーニングに直接適用できない可能性があり、それに応じてバックボーン ネットワークの規模を拡張する必要があります。 。この研究では、異なる 3D バックボーン ネットワークは、異なるサイズのデータセットでトレーニングされた場合に異なる動作とスケーラビリティを示すことがわかりました。その中でも、Transformer ベースの PointBERT と 3 次元畳み込みベースの SparseConv がより強力なパフォーマンスとスケーラビリティを示すため、3 次元バックボーン ネットワークとして選択されました。
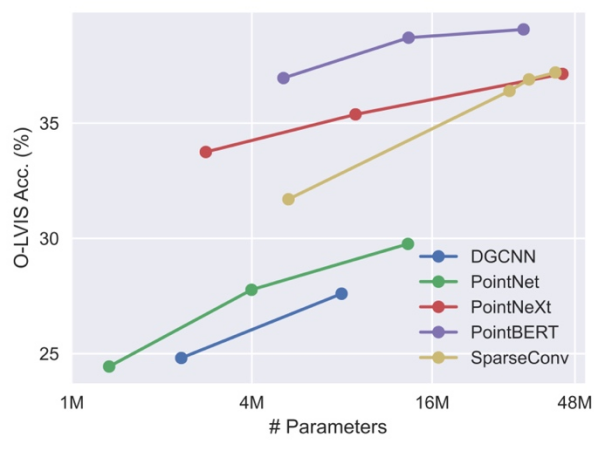
#統合データセット上の 3D バックボーン モデルのサイズをスケールアップすると、パフォーマンスが低下します。スケーラビリティの比較。
困難な負の例マイニング:この研究のアンサンブル データセットは、高度なクラスの不均衡を示しています。建築などの一部の一般的なカテゴリは数万の形状を占める場合がありますが、セイウチや財布などの他の多くのカテゴリは数十、またはさらに少ない形状しか含まれておらず、過小評価されています。したがって、対照学習用にバッチがランダムに構築される場合、混同されやすい 2 つのカテゴリ (リンゴとサクランボなど) の形状が同じバッチ内に出現して対比される可能性は低くなります。この目的を達成するために、この論文では、トレーニングの効率とパフォーマンスを向上させるための、オフラインでの困難なネガティブ サンプル マイニング戦略を提案します。 HuggingFace のインタラクティブなデモへようこそ。
以上が3D 点群、分類、検索、字幕、画像生成のオープンワールドの理解の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7503
7503
 15
1377
52
78
11
19
54
15
1377
52
78
11
19
54

 Debian Apacheログ形式の構成方法
Apr 12, 2025 pm 11:30 PM
Debian Apacheログ形式の構成方法
Apr 12, 2025 pm 11:30 PM
この記事では、Debian SystemsでApacheのログ形式をカスタマイズする方法について説明します。次の手順では、構成プロセスをガイドします。ステップ1:Apache構成ファイルにアクセスするDebianシステムのメインApache構成ファイルは、/etc/apache2/apache2.confまたは/etc/apache2/httpd.confにあります。次のコマンドを使用してルートアクセス許可を使用して構成ファイルを開きます。sudonano/etc/apache2/apache2.confまたはsudonano/etc/apache2/httpd.confステップ2:検索または検索または
 Tomcatログがメモリの漏れのトラブルシューティングに役立つ方法
Apr 12, 2025 pm 11:42 PM
Tomcatログがメモリの漏れのトラブルシューティングに役立つ方法
Apr 12, 2025 pm 11:42 PM
Tomcatログは、メモリリークの問題を診断するための鍵です。 Tomcatログを分析することにより、メモリの使用状況とガベージコレクション(GC)の動作に関する洞察を得ることができ、メモリリークを効果的に見つけて解決できます。 Tomcatログを使用してメモリリークをトラブルシューティングする方法は次のとおりです。1。GCログ分析最初に、詳細なGCロギングを有効にします。 Tomcatの起動パラメーターに次のJVMオプションを追加します:-xx:printgcdetails-xx:printgcdateStamps-xloggc:gc.logこれらのパラメーターは、GCタイプ、リサイクルオブジェクトサイズ、時間などの情報を含む詳細なGCログ(GC.log)を生成します。分析GC.LOG
 Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Systemsでは、Readdir関数はディレクトリコンテンツを読み取るために使用されますが、それが戻る順序は事前に定義されていません。ディレクトリ内のファイルを並べ替えるには、最初にすべてのファイルを読み取り、QSORT関数を使用してソートする必要があります。次のコードは、debianシステムにreaddirとqsortを使用してディレクトリファイルを並べ替える方法を示しています。
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Debian Syslogのファイアウォールルールを構成する方法
Apr 13, 2025 am 06:51 AM
Debian Syslogのファイアウォールルールを構成する方法
Apr 13, 2025 am 06:51 AM
この記事では、Debian SystemsでiPtablesまたはUFWを使用してファイアウォールルールを構成し、Syslogを使用してファイアウォールアクティビティを記録する方法について説明します。方法1:Iptablesiptablesの使用は、Debian Systemの強力なコマンドラインファイアウォールツールです。既存のルールを表示する:次のコマンドを使用して現在のiPtablesルールを表示します。Sudoiptables-L-N-vでは特定のIPアクセスを許可します。たとえば、IPアドレス192.168.1.100がポート80にアクセスできるようにします:sudoiptables-input-ptcp - dport80-s192.166
 Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
このガイドでは、Debian SystemsでSyslogの使用方法を学ぶように導きます。 Syslogは、ロギングシステムとアプリケーションログメッセージのLinuxシステムの重要なサービスです。管理者がシステムアクティビティを監視および分析して、問題を迅速に特定および解決するのに役立ちます。 1. syslogの基本的な知識Syslogのコア関数には以下が含まれます。複数のログ出力形式とターゲットの場所(ファイルやネットワークなど)をサポートします。リアルタイムのログ表示およびフィルタリング機能を提供します。 2。syslog(rsyslogを使用)をインストールして構成するDebianシステムは、デフォルトでrsyslogを使用します。次のコマンドでインストールできます:sudoaptupdatesud
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
 Debian Nginxログパスはどこですか
Apr 12, 2025 pm 11:33 PM
Debian Nginxログパスはどこですか
Apr 12, 2025 pm 11:33 PM
Debianシステムでは、nginxのアクセスログとエラーログのデフォルトのストレージ場所は次のとおりです。アクセスログ(アクセスログ):/var/log/nginx/access.logエラーログ(errorlog):/var/log/nginx/error.log上記のパスは、標準のdebiannginxインストールのデフォルト構成です。インストールプロセス中にログファイルストレージの場所を変更した場合は、nginx構成ファイル(通常は/etc/nginx/nginx.confまたは/etc/etc/nginx/sites-abailable/directoryにあります)を確認してください。構成ファイル
