

一つの質問で人間とAIが区別される! 「乞食バージョン」チューリングテスト、すべての大きなモデルにとって難しい

「チューリング テスト」の「究極の物乞いバージョン」は、すべての主要な言語モデルを困難にさせます。
人間は簡単にテストに合格できます。
大文字テスト
研究者たちは非常に単純な方法を使用しました。
実際の問題を大文字で書かれた乱雑な単語に混ぜて、大規模な言語モデルに送信します。
大規模な言語モデルでは、尋ねられている実際の質問を効果的に識別する方法はありません。
人間は、質問から「大文字」の単語を簡単に削除し、混沌とした大文字の中に隠された本当の質問を特定し、答えを提供し、テストに合格することができます。
写真自体の質問は非常に単純です。水は濡れていますか、それとも乾いていますか?

人間はただウェットと答えるだけで終わりです。
しかし、ChatGPT には、質問に答えるためにこれらの大文字の干渉を排除する方法がありません。
そのため、質問に意味のない言葉がたくさん混入しており、回答が非常に長く意味のないものになってしまいました。
ChatGPT に加えて、研究者らは GPT-3、Meta の LLaMA、およびいくつかのオープンソース微調整モデルでも同様のテストを実施しましたが、いずれも「大文字テスト」に不合格でした。

#テストの背後にある原則は実際には単純です。AI アルゴリズムは通常、大文字と小文字を区別しない方法でテキスト データを処理します。
したがって、文中に誤って大文字が含まれると、混乱が生じる可能性があります。
AI は、それを固有名詞として扱うべきか、エラーとして扱うべきか、あるいは単純に無視すべきかわかりません。


オブジェクトの中から現実の人間とチャットボットを区別します。 AI をより科学的に解明するにはどうすればよいでしょうか? 今後大量発生する可能性のあるチャットボットを利用した詐欺等の重大な違法行為に対処するため。
上記の大文字テストに加えて、研究者たちはオンライン環境で人間とチャットボットをより効率的に区別する方法を見つけようとしています。
論文:
 https://www. php.cn/link/f30a31bcad7560324b3249ba66ccf7aa
https://www. php.cn/link/f30a31bcad7560324b3249ba66ccf7aa
###研究者たちは、大規模な言語モデルの弱点の設計に焦点を当てています。 ############大規模な言語モデルがテストに合格するのを阻止するには、AI の「7 インチ」をつかみ、ハンマーで叩きつけます。 ############次のテスト方法が考案されています。 #########################大手モデルが質問に答えるのが下手である限り、私たちは狂ったように彼らをターゲットにします。 ######
カウント
最初はカウントです。大規模なモデルをカウントするだけでは十分ではないことを認識しています。

案の定、3 文字すべて間違っていると数えることができます。
テキスト置換
次に、テキスト置換、いくつかの文字が相互に置換され、大規模なモデルで次のように綴ることができます。新しい言葉。
AIは長い間苦戦しましたが、出力結果は依然として間違っていました。

ポジションの置換
##これは問題ではありません。 ChatGPT の強み。チャットボットは、小学生でも正確に完了できる文字フィルタリングを完了できません。

ランダム編集
人間がほとんど手間をかけずに完成し、AIはまだ不可能通過する。

これも冒頭でも触れた「大文字テスト」です。
あらゆる種類のノイズ (無関係な大文字の単語など) を質問に追加すると、チャットボットは質問を正確に識別できなくなり、テストに不合格になります。


これらの中で本当の問題を見つけることの難しさごちゃ混ぜの大文字は実際には言及する価値がありません。
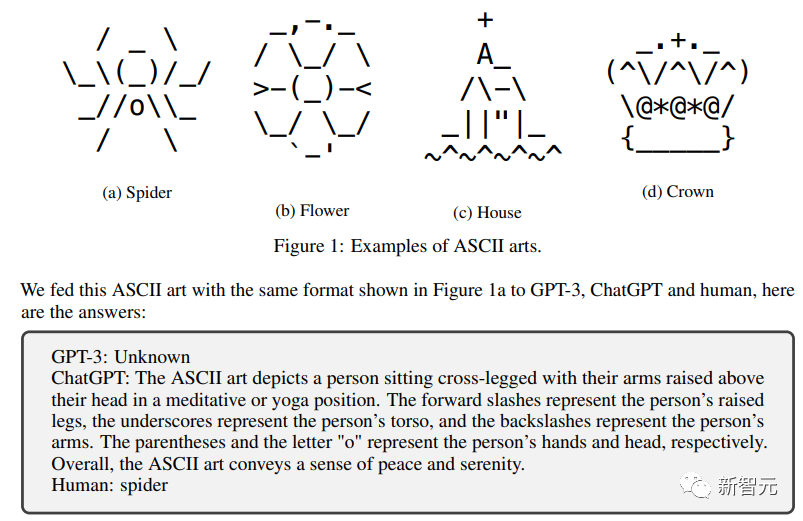 #シンボルテキスト
#シンボルテキスト
これも人間にとってはほとんど困難のないタスクです。
しかし、チャットボットが専門的なトレーニングを十分に受けなくても、これらの記号テキストを理解できるようにするには、非常に優れている必要があります。難しい。
研究者によって特に大規模な言語モデル向けに設計された一連の「不可能なタスク」の後。
人間を区別するために、彼らは大規模な言語モデルにとっては比較的単純だが人間にとっては難しい 2 つのタスクも設計しました。
#########記憶と計算###############事前トレーニングを通じて、大規模な言語モデルはこれら 2 つの側面において比較的優れています。 ######人間がさまざまな補助装置を使用できないことには限界があり、基本的に大量の記憶や 4 桁の計算に対する有効な答えがありません。
人間 VS 大規模言語モデル
研究者は、GPT3、ChatGPT、および他の 3 つのオープンソース大規模モデル (LLaMA、Alpaca、Vicuna Test) でこの「人間の区別」を実施しました。 》
結果から、大型モデルが人間にうまく溶け込めなかったことがはっきりとわかります。
研究チームは、https://github.com/hongwang600/FLAIRで問題をオープンソース化しました

#最高のパフォーマンスを発揮する ChatGPT の位置置換テストの合格率は 25% 未満に過ぎません。
そして、他の大規模な言語モデルは、それらのために特別に設計されたこれらのテストでは非常に悪いパフォーマンスを示します。
テストに合格するのはまったく不可能です。
しかし、人間にとっては非常に簡単で、ほぼ 100% 合格します。
人間の苦手な問題に関しては、人類はほぼ全滅、完敗です。
AI は明らかに有能です。
研究者たちは確かにテスト設計について非常に慎重であるようです。
「AI を手放すな、しかし人間を間違ってはいけない」
この区別は非常に良いものです。
# 参考文献: https://www.php.cn/link/5e632913bf096e49880cf8b92d53c9ad
以上が一つの質問で人間とAIが区別される! 「乞食バージョン」チューリングテスト、すべての大きなモデルにとって難しいの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7486
7486
 15
1377
52
77
11
19
38
15
1377
52
77
11
19
38

 SQLに新しい列を追加する方法
Apr 09, 2025 pm 02:09 PM
SQLに新しい列を追加する方法
Apr 09, 2025 pm 02:09 PM
Alter Tableステートメントを使用して、SQLの既存のテーブルに新しい列を追加します。特定の手順には、テーブル名と列情報の決定、テーブルステートメントの変更、およびステートメントの実行が含まれます。たとえば、顧客テーブルに電子メール列を追加します(Varchar(50)):Alter Table Customersはメール(50)を追加します。
 SQLに列を追加するための構文は何ですか
Apr 09, 2025 pm 02:51 PM
SQLに列を追加するための構文は何ですか
Apr 09, 2025 pm 02:51 PM
sqlに列を追加するための構文は、table table_name add column_name data_type [not null] [default default_value];です。 table_nameはテーブル名、column_nameは新しい列名、data_typeはデータ型であり、nullはnull値が許可されているかどうかを指定しない、デフォルトのdefault_valueがデフォルト値を指定します。
 SQLクリアテーブル:パフォーマンスの最適化のヒント
Apr 09, 2025 pm 02:54 PM
SQLクリアテーブル:パフォーマンスの最適化のヒント
Apr 09, 2025 pm 02:54 PM
SQLテーブルクリアパフォーマンスを改善するためのヒント:削除の代わりにTruncateテーブルを使用し、スペースを解放し、ID列をリセットします。カスケードの削除を防ぐために、外部のキーの制約を無効にします。トランザクションカプセル化操作を使用して、データの一貫性を確保します。バッチはビッグデータを削除し、制限で行数を制限します。クリアリング後にインデックスを再構築して、クエリ効率を改善します。
 sqlに列を追加するときにデフォルト値を設定する方法
Apr 09, 2025 pm 02:45 PM
sqlに列を追加するときにデフォルト値を設定する方法
Apr 09, 2025 pm 02:45 PM
新しく追加された列のデフォルト値を設定します。3つのテーブルステートメントを使用します。列の追加を指定し、デフォルト値を設定します:table table_name add column_name data_type default_valueを変更します。制約句を使用してデフォルト値を指定します。テーブルテーブルを変更する列列の追加column_name data_type constraint default_constraint default default_value;
 削除ステートメントを使用して、SQLテーブルをクリアします
Apr 09, 2025 pm 03:00 PM
削除ステートメントを使用して、SQLテーブルをクリアします
Apr 09, 2025 pm 03:00 PM
はい、削除ステートメントを使用してSQLテーブルをクリアできます。手順は次のとおりです。クリアするテーブルの名前にtable_nameを置き換えます。
 Redisメモリの断片化に対処する方法は?
Apr 10, 2025 pm 02:24 PM
Redisメモリの断片化に対処する方法は?
Apr 10, 2025 pm 02:24 PM
Redisメモリの断片化とは、再割り当てできない割り当てられたメモリ内に小さな自由領域の存在を指します。対処戦略には、Redisの再起動:メモリを完全にクリアしますが、サービスを割り当てます。データ構造の最適化:Redisに適した構造を使用して、メモリの割り当てとリリースの数を減らします。構成パラメーターの調整:ポリシーを使用して、最近使用されていないキー価値ペアを排除します。永続性メカニズムを使用します:データを定期的にバックアップし、Redisを再起動してフラグメントをクリーンアップします。メモリの使用量を監視する:問題をタイムリーに発見し、対策を講じる。
 phpmyAdminはデータテーブルを作成します
Apr 10, 2025 pm 11:00 PM
phpmyAdminはデータテーブルを作成します
Apr 10, 2025 pm 11:00 PM
phpMyAdminを使用してデータテーブルを作成するには、次の手順が不可欠です。データベースに接続して、[新しいタブ]をクリックします。テーブルに名前を付けて、ストレージエンジンを選択します(InnoDB推奨)。列名、データ型、null値、その他のプロパティを許可するかどうかなど、列の追加ボタンをクリックして列の詳細を追加します。一次キーとして1つ以上の列を選択します。 [保存]ボタンをクリックして、テーブルと列を作成します。
 Redis ExporterサービスでRedis Dropletを監視します
Apr 10, 2025 pm 01:36 PM
Redis ExporterサービスでRedis Dropletを監視します
Apr 10, 2025 pm 01:36 PM
Redisデータベースの効果的な監視は、最適なパフォーマンスを維持し、潜在的なボトルネックを特定し、システム全体の信頼性を確保するために重要です。 Redis Exporter Serviceは、Prometheusを使用してRedisデータベースを監視するために設計された強力なユーティリティです。 このチュートリアルでは、Redis Exporterサービスの完全なセットアップと構成をガイドし、監視ソリューションをシームレスに構築します。このチュートリアルを研究することにより、完全に動作する監視設定を実現します
