

OpenAI 創設者 Sam Altman への最新インタビュー: GPT-3 またはオープンソース、スケーリング ルールが AGI の構築を加速する

ビッグ データ ダイジェストの生成
「GPU が非常に不足しています」
最近のインタビューで、OpenAI の責任者である Sam Altman 氏は、「不満はAPI「信頼性とスピード」。
このインタビューは、人工知能スタートアップ Humanloop の CEO、Raza Habib によるもので、彼はインタビューのハイライトを Twitter にまとめました。
Twitter アドレス:
https://twitter.com/dr_cintas/status/1664281914948337664


2019 年、OpenAI は投資家の資金を吸収するために、営利目的の人工知能研究研究所に変わりました。
研究所の研究を支援する資金が不足してきたとき、マイクロソフトは研究所にさらに 10 億米ドルを投資すると発表しました。
OpenAI によって発売された GPT シリーズのすべてのバージョンは、業界でカーニバルを引き起こす可能性があります。Microsoft Build 2023 開発者カンファレンスで、OpenAI 創設者の Andrej Karpthy 氏は講演「State of GPT (GPT の現状)」で次のように述べています。彼らは大型モデルを「人間の頭脳」として訓練してきた。
Andrej 氏は、現在の LLM 大規模言語モデルは人間の思考モードのシステム 1 (高速システム) と比較でき、システム 1 (高速システム) は、応答は遅いが長期的な推論を行うシステム 2 (低速システム) と比較できると述べました。 。
「システム 1 は、LLM に相当する高速の自動プロセスで、トークンをサンプリングするだけだと思います。
システム 2 は、ゆっくりとした、よく考えられた計画を立てる脳の部分です。
プロンプト プロジェクトは基本的に、私たちの脳の機能の一部を LLM に復元することを望んでいます。」
Andrej Karpthy 氏も、GPT-4 は驚くべき成果物であると述べ、彼はそのことに非常に感謝しています。それが存在します。多くの分野で豊富な知識があり、数学やコードなどをすべて指先で実行できます。
CEO の Altman 氏は、初期の GPT-4 は非常に遅く、バグがあり、多くの機能が不十分だったと述べました。しかし、初期のコンピューターも同様で、たとえ開発に数十年かかったとしても、私たちの生活にとって非常に重要になる何かへの道を示していました。
OpenAIは夢を主張し、極限までやりたいと考えている組織のようです。
Microsoft Research Asia の元副社長で Lanzhou Technology の創設者である Zhou Ming 氏は、インタビューで次のように述べています。
OpenAI の最大の成果は、あらゆる面で完璧を達成したことであり、統合されたイノベーションのモデルです。
世界にはさまざまなタイプの人々がいますが、根底にあるイノベーションを研究したいだけの人もいます。基礎となるイノベーションに基づいたアプリケーションもあれば、一般的なアプリケーションは単一のタスクを解決するものです。これは次のように書き換えることができます。 もう 1 つのアプローチは、統合イノベーションを達成し、すべての作業、アプリケーション、アルゴリズムを大規模なプラットフォームに集中させてマイルストーンを作成することです。 OpenAI は、イノベーションの統合において非常に優れた仕事をしています。
参照:
https://mp.weixin.qq.com/s/p42pBVyjZws8XsstDoR2Jw https://mp.weixin.qq.com/s/zmEGzm1cdXupNoqZ65h7yg https://weibo.com/1727858283/4907695679472174?wm=3333_2001&from=10D5293010&sourcetype=weixin&s_trans=6289897940_490769 5679472174&s_channel=4 https://humanloop.com/blog/openai - 計画?cnotallow=bd9e76a5f41a6d847de52fa275480e22
以上がOpenAI 創設者 Sam Altman への最新インタビュー: GPT-3 またはオープンソース、スケーリング ルールが AGI の構築を加速するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7554
7554
 15
1382
52
83
11
22
96
15
1382
52
83
11
22
96

 numpyのバージョンを簡単に確認する方法
Jan 19, 2024 am 08:23 AM
numpyのバージョンを簡単に確認する方法
Jan 19, 2024 am 08:23 AM
Numpy は Python の重要な数学ライブラリであり、効率的な配列演算と科学技術計算機能を提供し、データ分析、機械学習、深層学習などの分野で広く使用されています。 numpy を使用する場合、多くの場合、現在の環境でサポートされている機能を確認するために numpy のバージョン番号を確認する必要があります。この記事では、numpyのバージョンを簡単に確認する方法と具体的なコード例を紹介します。方法 1: numpy に付属の __version__ 属性を使用する numpy モジュールには __ が付属しています
 Mavenのバージョンを確認する方法
Jan 17, 2024 pm 05:06 PM
Mavenのバージョンを確認する方法
Jan 17, 2024 pm 05:06 PM
Maven バージョンを確認する方法: 1. コマンド ラインを使用する; 2. 環境変数を確認する; 3. IDE を使用する; 4. pom.xml ファイルを確認する。詳細な紹介: 1. コマンド ラインを使用して、コマンド ラインに「mvn -v」または「mvn --version」と入力し、Enter キーを押します。これにより、Maven バージョン情報と Java バージョン情報が表示されます。 2. 環境を表示します。変数 、一部のシステムでは、環境変数をチェックして Maven のバージョン情報を確認し、コマンド ラインにコマンドを入力して Enter キーなどを押すことができます。
 Linux での CURL バージョンの更新に関するチュートリアル!
Mar 07, 2024 am 08:30 AM
Linux での CURL バージョンの更新に関するチュートリアル!
Mar 07, 2024 am 08:30 AM
Linux でカールのバージョンを更新するには、以下の手順に従います。 現在のカールのバージョンを確認します。 まず、現在のシステムにインストールされているカールのバージョンを確認する必要があります。ターミナルを開き、次のコマンドを実行します。curl --version このコマンドは、現在のcurlバージョン情報を表示します。利用可能なcurlのバージョンを確認する:curlを更新する前に、利用可能な最新バージョンを確認する必要があります。 Curl の公式 Web サイト (curl.haxx.se) または関連ソフトウェア ソースにアクセスして、curl の最新バージョンを見つけることができます。 Curl ソース コードをダウンロードする:curl またはブラウザを使用して、選択した CURL バージョンのソース コード ファイル (通常は .tar.gz または .tar.bz2) をダウンロードします。
 インストールされている Oracle のバージョンを簡単に確認する方法
Mar 07, 2024 am 11:27 AM
インストールされている Oracle のバージョンを簡単に確認する方法
Mar 07, 2024 am 11:27 AM
インストールされている Oracle のバージョンを簡単に確認するには、具体的なコード例が必要です。Oracle データベースは、エンタープライズ レベルのデータベース管理システムで広く使用されているソフトウェアとして、多くのバージョンとさまざまなインストール方法があります。私たちは日々の業務で、対応する運用やメンテナンスのために、インストールされている Oracle データベースのバージョンを確認する必要があることがよくあります。この記事では、インストールされているOracleのバージョンを簡単に確認する方法と具体的なコード例を紹介します。方法 1: Oracle データベースの SQL クエリを通じて、次のことができます。
 Kirin オペレーティング システムのバージョンとカーネルのバージョンを確認する
Feb 21, 2024 pm 07:04 PM
Kirin オペレーティング システムのバージョンとカーネルのバージョンを確認する
Feb 21, 2024 pm 07:04 PM
Kylin オペレーティング システムのバージョンとカーネル バージョンの確認 Kirin オペレーティング システムでは、システム バージョンとカーネル バージョンを確認する方法を知ることが、システム管理とメンテナンスの基礎となります。 Kylin オペレーティング システムのバージョンを確認する方法 1: /etc/.kyinfo ファイルを使用する Kylin オペレーティング システムのバージョンを確認するには、/etc/.kyinfo ファイルを確認します。このファイルには、オペレーティング システムのバージョン情報が含まれています。次のコマンドを実行します: cat/etc/.kyinfo このコマンドは、オペレーティング システムの詳細なバージョン情報を表示します。方法 2: /etc/issue ファイルを使用する オペレーティング システムのバージョンを確認するもう 1 つの方法は、/etc/issue ファイルを参照することです。このファイルにはバージョン情報も含まれていますが、.kyinfo ファイルほど優れていない可能性があります。
 pip バージョンを更新する簡単な手順: 1 分で完了します
Jan 27, 2024 am 09:45 AM
pip バージョンを更新する簡単な手順: 1 分で完了します
Jan 27, 2024 am 09:45 AM
1 分で完了: pip バージョンを更新する方法、具体的なコード例が必要です Python の急速な発展に伴い、pip は Python パッケージ管理の標準ツールになりました。ただし、時間の経過とともに、pip バージョンは常に更新されるため、最新の機能を使用し、潜在的なセキュリティ脆弱性を修正できるようにするには、pip バージョンを更新することが非常に重要です。この記事では、pip を 1 分で素早く更新する方法と具体的なコード例を説明します。まず、コマンド ライン ウィンドウを開く必要があります。 Windows システムでは、次のように使用できます。
 大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
Llama3 に関しては、新しいテスト結果が発表されました。大規模モデル評価コミュニティ LMSYS は、Llama3 が 5 位にランクされ、英語カテゴリでは GPT-4 と同率 1 位にランクされました。このリストは他のベンチマークとは異なり、モデル間の 1 対 1 の戦いに基づいており、ネットワーク全体の評価者が独自の提案とスコアを作成します。最終的に、Llama3 がリストの 5 位にランクされ、GPT-4 と Claude3 Super Cup Opus の 3 つの異なるバージョンが続きました。英国のシングルリストでは、Llama3 がクロードを追い抜き、GPT-4 と並びました。この結果について、Meta の主任科学者 LeCun 氏は非常に喜び、リツイートし、
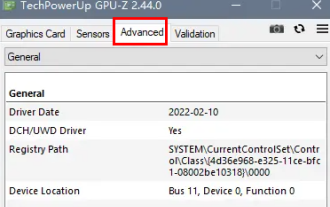 dp インターフェイスが 1.2 か 1.4 かを確認するにはどうすればよいですか?
Feb 06, 2024 am 10:27 AM
dp インターフェイスが 1.2 か 1.4 かを確認するにはどうすればよいですか?
Feb 06, 2024 am 10:27 AM
DP インターフェースはコンピューターの重要なインターフェース ケーブルです。コンピューターを使用するときに、多くのユーザーは DP インターフェースが 1.2 か 1.4 かを確認する方法を知りたいと考えています。実際には、GPU-Z で確認するだけで済みます。 dp インターフェイスが 1.2 か 1.4 かを判断する方法: 1. まず、GPU-Z で「アドバンス」を選択します。 2. 「詳細」の「全般」の「Monitor1」を見ると、「LinkRate (current)」と「Lane (current)」の 2 つの項目が表示されます。 3. 最後に 8.1Gbps×4 と表示されていれば DP1.3 以降のバージョン、通常は DP1.4 を意味し、5.4Gbps×4 であれば、
