

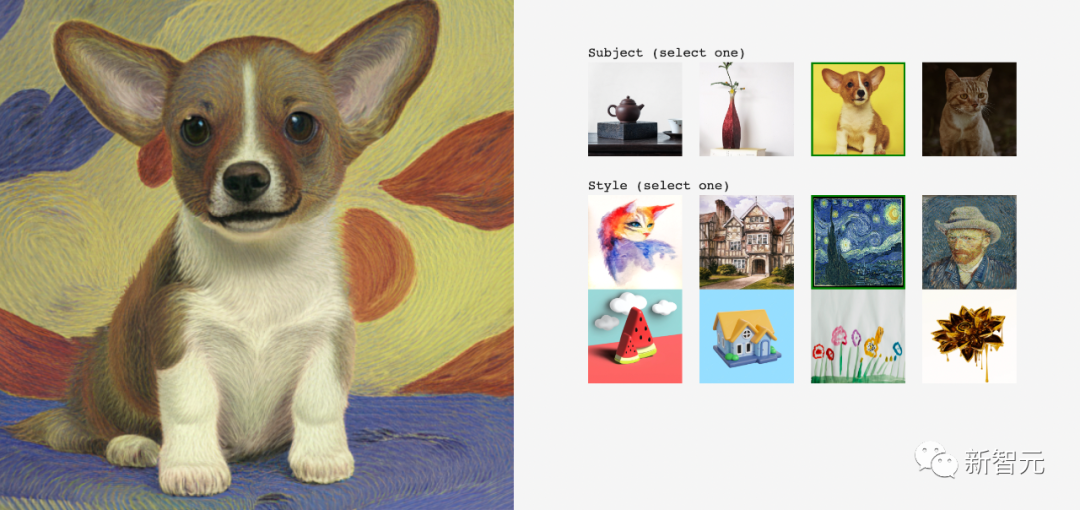
ミッドジャーニーのライバル登場! GoogleのStyleDropエース「カスタマイズマスター」がAIアート界に爆発をもたらす

Google StyleDrop は登場するとすぐにインターネットに登場しました。
ゴッホの星月夜を考えると、AI はゴッホ巨匠に変身し、この抽象的なスタイルをトップレベルで理解した後、無数の同様の絵画を作成しました。

#別の漫画スタイルでは、私が描きたいオブジェクトはもっとかわいいです。


ネチズンは、これもデザイナーを排除する AI ツールであると表明しました。
StyleDrop ホットリサーチは、Google 研究チームによる最新の製品です。

##現在、StyleDrop のようなツールを使用すると、より制御して描画できるだけでなく、ロゴの描画など、以前は想像できなかった細かい作業を完了することもできます。
NVIDIA の科学者でさえ、これを「驚異的な」結果と呼んでいました。
「カスタマイズ」マスター

同様に、StyleDrop は、誰もが 1 つまたは少数の参照画像からすばやく簡単にスタイルを「選択」し、そのスタイルの画像を生成できることを望んでいます。
ナマケモノには 18 のスタイルがあります:

パンダには 24 のスタイルがあります:

子供が描いた水彩画、紙も含めて StyleDrop が完璧に制御します。復元されました。

さまざまなスタイルの英語文字のデザインを参照する StyleDrop もあります:

## もゴッホ風の文字です。

#線画もあります。線画は抽象度が高く、画面構成に非常に合理性が要求されるため、これまでの手法では成功することが困難でした。

元の画像のチーズの影のストロークが、各画像のオブジェクトに復元されます。


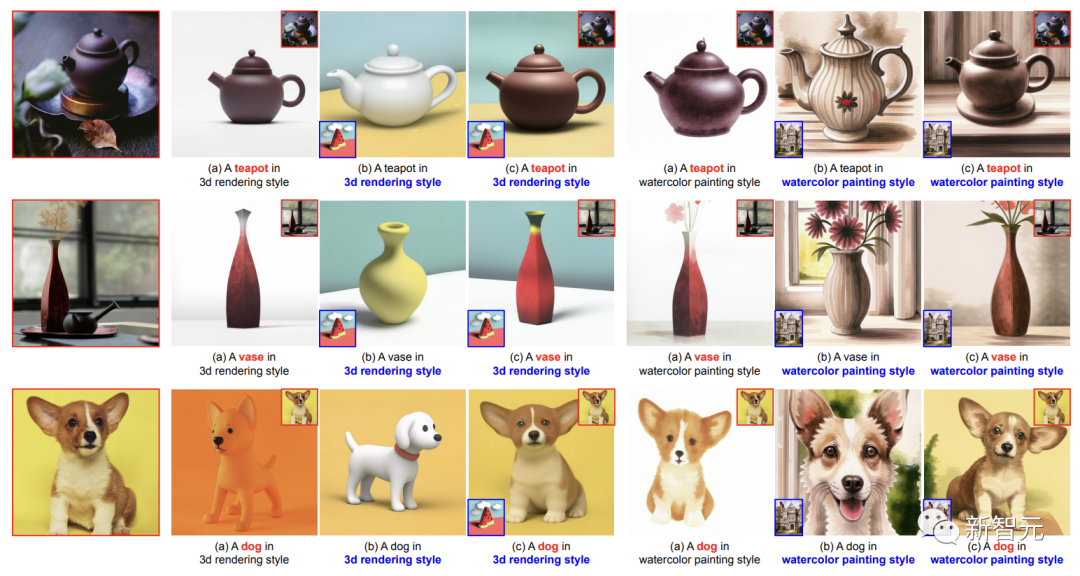
たとえば、ゴッホ スタイルのまま、小さなコーギー用に同様のスタイルの絵画を生成します。
StyleDrop は Muse 上に構築されており、2 つの重要な部分で構成されています。
 1 つは、視覚的な Transformer を生成するパラメータの効果的な微調整です。もう 1 つはフィードバック トレインによる反復です。
1 つは、視覚的な Transformer を生成するパラメータの効果的な微調整です。もう 1 つはフィードバック トレインによる反復です。
Muse は、マスク生成画像 Transformer に基づいた最新のテキストから画像への合成モデルです。基本画像生成 (256 × 256) と超解像度 (512 × 512 または 1024 × 1024) のための 2 つの合成モジュールが含まれています。
#各モジュールは、テキスト エンコーダー T、トランスフォーマー G、サンプラー S、イメージ エンコーダーで構成されます。デコーダ E とデコーダ D の
T は、テキスト プロンプト t∈T を連続埋め込み空間 E にマップします。 G はテキスト埋め込み e ∈ E を処理して、ビジュアル トークン シーケンス l ∈ L の対数を生成します。 S は、テキスト埋め込み e と前のステップからデコードされたビジュアル トークンに条件付けされたトランスフォーマー推論のいくつかのステップを実行する反復デコードを通じて、対数からビジュアル トークン シーケンス v ∈ V を抽出します。

図 2 は、簡略化された Muse トランスフォーマ層アーキテクチャです。 Parameter Efficient Fine-tuning (PEFT) とアダプターをサポートするために部分的に変更されました。
L層のトランスフォーマーを使用して、テキスト埋め込みeの条件で緑色に表示されたビジュアルトークン列を処理します。学習されたパラメータ θ は、アダプター調整の重みを構築するために使用されます。
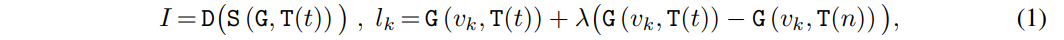
θ をトレーニングするために、多くの場合、研究者はスタイルの参考として画像を与えるだけかもしれません。
研究者はテキスト プロンプトを手動で添付する必要があります。彼らは、コンテンツの説明とそれに続く説明スタイルのフレーズで構成されるテキスト プロンプトを構築するための、シンプルなテンプレート化されたアプローチを提案しました。
たとえば、研究者は表 1 のオブジェクトを説明するために「猫」を使用し、スタイルの説明として「水彩画」を追加します。

テキスト プロンプトにコンテンツとスタイルの説明を含めることは、コンテンツとスタイルを分離するのに役立つため重要です。これが調査の主な目的です。職員。
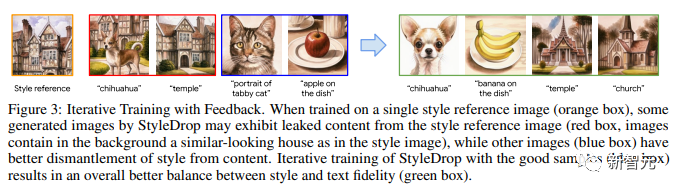
図 3 は、フィードバックを伴う反復トレーニングを示しています。
単一のスタイル参照画像 (オレンジ色のボックス) でトレーニングする場合、StyleDrop によって生成された一部の画像には、スタイル参照画像から抽出されたコンテンツが表示される場合があります (赤いボックス、画像の背景には類似した家が含まれています)スタイルイメージに)。
他の画像 (青いボックス) では、スタイルとコンテンツをより適切に分離できます。良好なサンプル (青色のボックス) で StyleDrop を反復トレーニングすると、スタイルとテキストの忠実性 (緑色のボックス) のバランスが向上します。
研究者らはここでも 2 つの方法を使用しました:
- CLIP スコア
##この方法は、画像とテキストの配置を測定するために使用されます。したがって、CLIP スコア (つまり、視覚的およびテキストの CLIP 埋め込みのコサイン類似性) を測定することで、生成された画像の品質を評価できます。研究者は、最高スコアの CLIP 画像を選択できます。彼らはこの方法を CLIP フィードバック反復トレーニング (CF) と呼んでいます。
実験の結果、研究者らは、CLIP スコアを使用して合成画像の品質を評価することが、スタイルの忠実度を過度に損なうことなく再現率 (つまり、テキストの忠実度) を向上させる効果的な方法であることを発見しました。
しかし、一方で、CLIP スコアは人間の意図と完全に一致しない場合や、微妙なスタイルの属性を捕捉できない場合があります。
-HF
ヒューマン フィードバック (HF) は、ユーザーの意図を合成画質評価に直接注入する方法です。より直接的な方法で。強化学習のための LLM 微調整において、HF はその威力と有効性を証明しています。
HF は、CLIP スコアが微妙なスタイル属性をキャプチャできないことを補うために使用できます。
現在、大量の研究が、複数の個人的なスタイルを含む画像を合成するためのテキストから画像への拡散モデルの個人化問題に焦点を当てています。
研究者たちは、DreamBooth と StyleDrop を簡単な方法で組み合わせて、スタイルとコンテンツの両方をパーソナライズする方法を示しています。
これは、スタイルとコンテンツの参照画像にそれぞれ独立して、スタイルの θs とコンテンツの θc に基づいて、2 つの修正された生成分布からサンプリングすることによって実現されます。
既存の製品とは異なり、このチームのアプローチでは、複数の概念に関する学習可能なパラメーターを共同トレーニングする必要がなく、組み合わせ機能の向上につながります。事前トレーニングされたアダプターは個別のトピックとスタイルに基づいてトレーニングされるため、別々に。
研究者らの全体的なサンプリング プロセスは、式 (1) の反復デコードに従い、各デコード ステップで異なる方法で対数がサンプリングされます。
t がテキスト プロンプト、c がスタイル記述子のないテキスト プロンプトで、対数がステップ k で次のように計算されるとします。 ここで: γ は StyleDrop と DreamBooth のバランスをとるために使用されます。γ が 0 の場合は StyleDrop を取得し、1 の場合は DreamBooth を取得します。 γを適切に設定することで、適切な画像を得ることができます。 #実験設定 これまでのところ、テキスト画像生成モデルのスタイル調整は広く研究されています。 したがって、研究者らは新しい実験計画を提案しました: -データ収集 研究者たちは、水彩画や油絵、平面イラスト、3D レンダリングからさまざまな素材の彫刻に至るまで、さまざまなスタイルの数十枚の写真を収集しました。 -モデル構成 研究者はアダプターを使用して Muse ベースの StyleDrop を調整します。すべての実験では、Adam オプティマイザーを使用して、学習率 0.00003 で 1000 ステップのアダプターの重みを更新しました。特に明記されていない限り、研究者らは StyleDrop を使用してモデルの第 2 ラウンドを表現します。このモデルは、人間のフィードバックを使用して 10 を超える合成画像でトレーニングされました。 - 評価 CLIP に基づく研究レポートの定量的評価。スタイルの一貫性とテキストの整合性を測定します。さらに、研究者らはスタイルの一貫性とテキストの配置を評価するためにユーザーの好みの調査を実施しました。 写真に示すように、研究者が収集したさまざまなスタイルの 18 枚の写真を StyleDrop 処理した結果です。 ご覧のとおり、StyleDrop はさまざまなスタイルのテクスチャ、シェーディング、構造のニュアンスをキャプチャできるため、以前よりもスタイルをより適切に制御できるようになります。 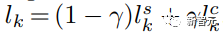
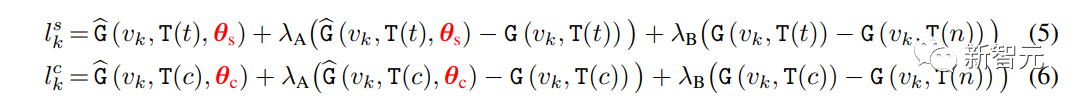

比較のために、研究者らは、Imagen に関する DreamBooth、安定拡散および LoRA 実現に関する DreamBooth の結果とテキストも紹介しました。反転結果。

#具体的な結果を表に示します。人間の画像とテキストの配置 (Text) およびビジュアル スタイルの配置 (スタイル) スコア (上) と CLIP スコア (下) の評価指標。
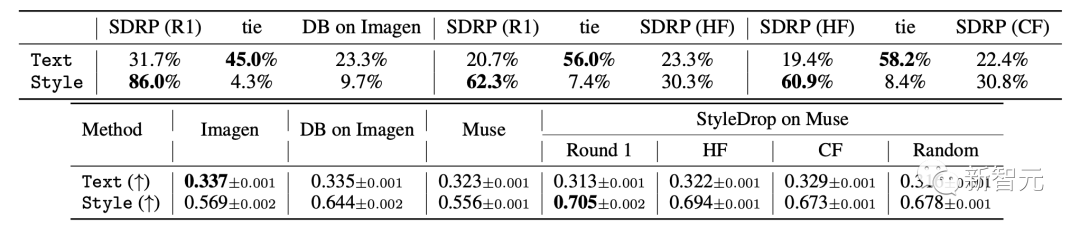
テキスト スコアの場合、研究者は画像とテキストの埋め込み間のコサイン類似性を測定します。スタイルスコアについては、研究者らはスタイル参照と合成画像埋め込みの間のコサイン類似度を測定します。
研究者らは、190 個のテキスト プロンプトに対して合計 1520 個の画像を生成しました。研究者らは最終スコアがもっと高くなるだろうと期待していましたが、測定基準は完璧ではありません。 そして、反復トレーニング (IT) によりテキスト スコアが向上し、研究者の目標と一致しました。 ただし、トレードオフとして、合成画像でトレーニングされ、スタイルが選択バイアスによって偏っている可能性があるため、第 1 ラウンドのモデルのスタイル スコアは低下します。 Imagen の DreamBooth は、スタイル スコアにおいて StyleDrop ほど良くありません (HF の 0.644 対 0.694)。 研究者らは、Imagen 上の DreamBooth のスタイル スコアの増加は明らかではない (0.569 → 0.644) のに対し、Muse 上の StyleDrop の増加はより明らかである (0.556 → 0.694) ことに気づきました。 研究者らは、Muse でのスタイルの微調整が Imagen でのスタイル微調整よりも効果的であると分析しました。 さらに、StyleDrop は、きめ細かい制御のために、カラー オフセット、グラデーション、鋭角の制御などの微妙なスタイルの違いをキャプチャします。 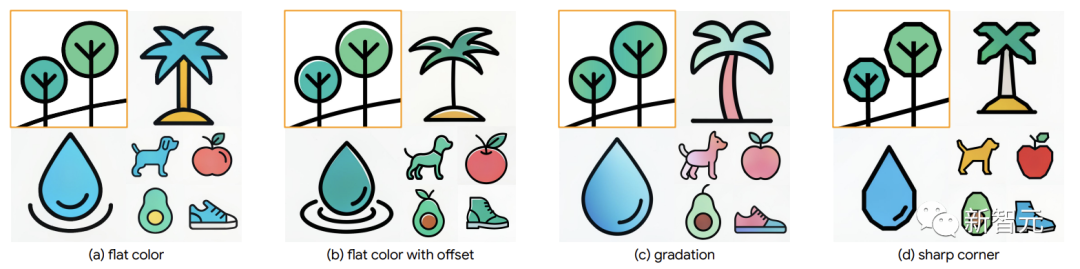
デザイナーが StyleDrop を導入すれば、作業効率は 10 倍速くなるそしてそれはすでに出発しています。
AI の 1 日は人間の生活の 10 年に相当し、AIGC は光の速さで発展しています。人の目を眩ませる光の速さ!
以上がミッドジャーニーのライバル登場! GoogleのStyleDropエース「カスタマイズマスター」がAIアート界に爆発をもたらすの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7566
7566
 15
1386
52
87
11
28
105
15
1386
52
87
11
28
105


 DeepSeekを検索する方法
Feb 19, 2025 pm 05:39 PM
DeepSeekを検索する方法
Feb 19, 2025 pm 05:39 PM
DeepSeekは、特定のデータベースまたはシステムでのみ検索する独自の検索エンジンであり、より速く、より正確です。それを使用する場合、ユーザーはドキュメントを読み、さまざまな検索戦略を試し、ユーザーエクスペリエンスに関するヘルプを求めてフィードバックを求めて、利点を最大限に活用することをお勧めします。
 セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
この記事では、SESAME Open Exchange(gate.io)Webバージョンの登録プロセスとGate Tradingアプリを詳細に紹介します。 Web登録であろうとアプリの登録であろうと、公式Webサイトまたはアプリストアにアクセスして、本物のアプリをダウンロードし、ユーザー名、パスワード、電子メール、携帯電話番号、その他の情報を入力し、電子メールまたは携帯電話の確認を完了する必要があります。
 Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか? BYBITは、ユーザーにトレーディングサービスを提供する暗号通貨交換です。 Exchangeのモバイルアプリは、次の理由でAppStoreまたはGooglePlayを介して直接ダウンロードすることはできません。1。AppStoreポリシーは、AppleとGoogleがApp Storeで許可されているアプリケーションの種類について厳しい要件を持つことを制限しています。暗号通貨交換アプリケーションは、金融サービスを含み、特定の規制とセキュリティ基準を必要とするため、これらの要件を満たしていないことがよくあります。 2。法律と規制のコンプライアンス多くの国では、暗号通貨取引に関連する活動が規制または制限されています。これらの規制を遵守するために、BYBITアプリケーションは公式Webサイトまたはその他の認定チャネルを通じてのみ使用できます
 セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
アプリをダウンロードしてアカウントの安全を確保するために、正式なチャネルを選択することが重要です。
 Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
この記事では、Binance、Okx、Gate.io、Bitflyer、Kucoin、Bybit、Coinbase Pro、Kraken、Bydfi、Xbit分散化された交換など、注意を払う価値のある上位10の暗号通貨取引プラットフォームを推奨しています。これらのプラットフォームには、トランザクションの数量、トランザクションの種類、セキュリティ、コンプライアンス、特別な機能の点で独自の利点があります。適切なプラットフォームを選択するには、あなた自身の取引体験、リスク許容度、投資の好みに基づいて包括的な検討が必要です。 この記事があなたがあなた自身に最適なスーツを見つけるのに役立つことを願っています
 セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
ログインステップやパスワード回復プロセスなど、セサミオープンエクスチェンジWebバージョンのログイン操作の詳細な紹介も、ログイン障害、ページを開くことができず、プラットフォームにスムーズにログインするのに役立つ検証コードを受信できません。
 Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Webサイトログインポータルの最新バージョンにアクセスするには、これらの簡単な手順に従ってください。公式ウェブサイトに移動し、右上隅の[ログイン]ボタンをクリックします。既存のログインメソッドを選択してください。「登録」してください。登録済みの携帯電話番号または電子メールとパスワードを入力し、認証を完了します(モバイル検証コードやGoogle Authenticatorなど)。検証が成功した後、Binance公式WebサイトLogin Portalの最新バージョンにアクセスできます。
