

RLHF の「RL」は必要ですか?バイナリ クロス エントロピーを使用して LLM を直接微調整する人もいますが、その効果はより優れています。

最近、大規模なデータセットでトレーニングされた教師なし言語モデルが驚くべき機能を達成しました。ただし、これらのモデルは、さまざまな目標、優先順位、スキルセットを持つ人間によって生成されたデータに基づいてトレーニングされており、その一部は必ずしも模倣されることが期待されていません。
安全で高性能、制御可能な AI システムを構築するには、非常に幅広い知識と機能からモデルの望ましい応答と動作を選択することが重要です。既存の手法の多くは、人間が安全で有益であると考える行動のタイプを表す、慎重に精選された人間の嗜好セットを使用することによって、言語モデルに望ましい行動を教え込んでいます。この嗜好学習段階は、大規模なテキスト データ セットに対して行われます。大規模な教師なし事前学習の初期段階の後、 -トレーニング。
最も単純な好みの学習方法は、人間によって実証された高品質な応答の教師あり微調整ですが、最近比較的人気のあるクラスの方法は、人間 (または人工知能) のフィードバックによるものです。強化学習 (RLHF/RLAIF) を実行します。 RLHF メソッドは、報酬モデルを人間の好みのデータセットと照合し、RL を使用して言語モデル ポリシーを最適化し、元のモデルから過度に逸脱することなく高い報酬を割り当てる応答を生成します。
RLHF は優れた会話機能とコーディング機能を備えたモデルを生成しますが、RLHF パイプラインは教師あり学習よりもはるかに複雑で、複数の言語モデルのトレーニングとトレーニングのループが含まれます。言語モデル ポリシーからのサンプリングでは、大きな計算コスト。
そして最近の研究では、既存の手法で使用されている RL ベースの目標は、単純なバイナリ クロスエントロピー目標を使用して正確に最適化できるため、大幅に改善されることが示されています。簡素化されたプリファレンス学習パイプライン。 つまり、明示的な報酬モデルや強化学習を必要とせずに、人間の好みに合わせて言語モデルを直接最適化することは完全に可能です。

#紙のリンク: https://arxiv.org/pdf/2305.18290 .pdf
スタンフォード大学およびその他の機関の研究者は、直接選好最適化 (DPO) を提案しました。このアルゴリズムは、既存の RLHF アルゴリズムを暗黙的に最適化します。同じ目標 (KL による報酬の最大化 - 発散)制約) ですが、実装は簡単で、トレーニングも簡単です。
実験により、DPO は、PPO の RLHF に基づく方法を含む既存の方法と少なくとも同じくらい効果的であることが示されています。
DPO アルゴリズム既存のアルゴリズムと同様、DPO も理論的な選好モデル (ブラッドリー-テリー モデルなど) に依存して、与えられた報酬関数がどの程度適合しているかを測定します。経験的な好みのデータ。ただし、既存の方法では、選好モデルを使用して選好損失を定義し、報酬モデルをトレーニングしてから、学習した報酬モデルを最適化するポリシーをトレーニングしますが、DPO では変数の変更を使用して、選好損失をポリシーの関数として直接定義します。したがって、モデル応答の人間の嗜好データセットを考慮すると、DPO は、トレーニング中にポリシーから報酬関数やサンプルを明示的に学習する必要なく、単純なバイナリ クロスエントロピー目標を使用してポリシーを最適化できます。
DPO 更新により、優先応答と非優先応答の相対対数確率が増加しますが、モデルの劣化を防ぐためにサンプルごとの動的な重要度の重みが含まれています。研究者らは、これが次のことであることを発見しました。単純な確率比ターゲットでは劣化が発生します。
DPO を機構的に理解するには、損失関数  の勾配を分析すると便利です。パラメータ θ に関する勾配は次のように記述できます:
の勾配を分析すると便利です。パラメータ θ に関する勾配は次のように記述できます:
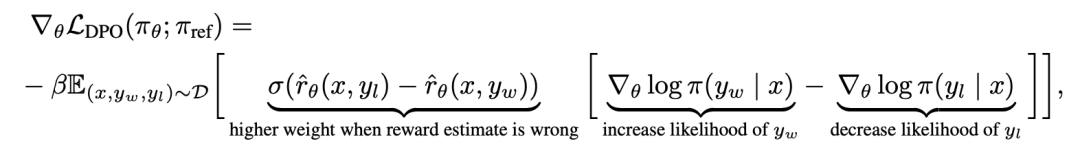
ここで、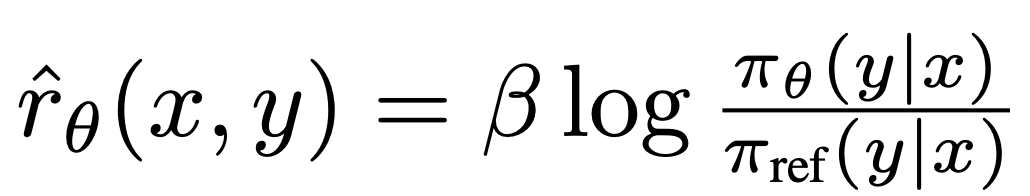 は、言語モデル
は、言語モデル 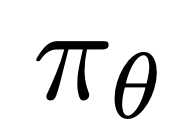 と参照モデル
と参照モデル 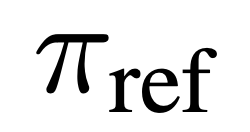 によって暗黙的に定義された報酬です。直感的には、損失関数
によって暗黙的に定義された報酬です。直感的には、損失関数  の勾配は、好ましい完了 y_w の尤度を増加させ、好ましくない完了 y_l の可能性を減少させます。
の勾配は、好ましい完了 y_w の尤度を増加させ、好ましくない完了 y_l の可能性を減少させます。
重要なのは、これらのサンプルの重みは暗黙的報酬モデルによって決定されるということです。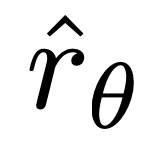 気に入らない完了の評価は、β というスケールによって決定されます。 、暗黙的報酬モデルがランキングの完了においてどの程度不正確であるか、これは KL 制約の強さの反映でもあります。重み付け係数を持たないこの方法の素朴なバージョンは言語モデルの劣化につながるため、実験はこの重み付けの重要性を示しています (付録表 2)。
気に入らない完了の評価は、β というスケールによって決定されます。 、暗黙的報酬モデルがランキングの完了においてどの程度不正確であるか、これは KL 制約の強さの反映でもあります。重み付け係数を持たないこの方法の素朴なバージョンは言語モデルの劣化につながるため、実験はこの重み付けの重要性を示しています (付録表 2)。
論文の第 5 章では、研究者は DPO 手法についてさらに説明し、理論的なサポートを提供し、DPO の利点を RLHF (PPO など) の Actor-Critic アルゴリズムと比較しました。問題。具体的な詳細については、元の論文を参照してください。
実験
実験では、研究者は、設定に基づいてポリシーを直接トレーニングする DPO の能力を評価しました。
まず、よく制御されたテキスト生成環境で、彼らは次の質問を検討しました。PPO などの一般的なプリファレンス学習アルゴリズムと比較して、DPO は参照ポリシーにおける報酬の最大化とトレードオフになります。 KLダイバージェンスの最小化?次に、大規模なモデルと、要約や対話を含むより困難な RLHF タスクに対する DPO のパフォーマンスを評価しました。
最終的に、ほとんどのハイパーパラメータ調整により、DPO は報酬を学習しながら、PPO を使用した RLHF などの強力なベースラインと同等、またはそれ以上のパフォーマンスを発揮することがわかりました。この関数は最高の結果を返します。 N 個のサンプリング軌跡の結果。
タスクに関しては、研究者らは 3 つの異なるオープンエンド型テキスト生成タスクを検討しました。すべての実験で、アルゴリズムは優先データセット 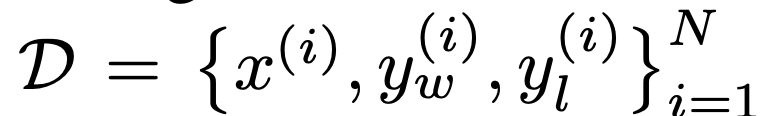 からポリシーを学習します。
からポリシーを学習します。
制御された感情の生成では、x は IMDb データセットからの映画レビューの接頭辞であり、ポリシーは肯定的な感情を含む y を生成する必要があります。比較評価のために、実験では事前にトレーニングされた感情分類子を使用して好みのペアを生成します (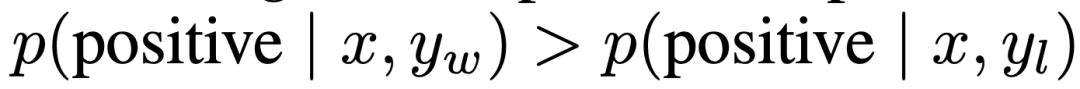 )。
)。
#SFT の場合、研究者は IMDB データセットのトレーニング分割のコメントに収束するまで GPT-2-large を微調整しました。要約すると、x は Reddit からのフォーラム投稿であり、戦略は投稿内の重要なポイントの概要を生成する必要があります。以前の研究に基づいて、実験では Reddit TL;DR 概要データセットと Stiennon らが収集した人間の好みを使用します。この実験では、人が書いたフォーラム記事の要約 2 と RLHF の TRLX フレームワークに基づいて微調整された SFT モデルも使用されました。人間の嗜好データセットは、Stiennon らによって、異なるものの同様にトレーニングされた SFT モデルから収集されたサンプルです。
最後に、1 ターンの会話における x は人間に関する質問であり、天体物理学から人間関係のアドバイスまで何でもあります。ポリシーは、ユーザーのクエリに対して魅力的で役立つ応答を提供する必要があります。ポリシーは、ユーザーのクエリに対して興味深く役立つ応答を提供する必要があります。実験では、人間と自動アシスタントの間の 170,000 の会話が含まれる、人間の有益および無害な会話セットを使用します。各テキストは、大規模な (未知ではあるが) 言語モデルによって生成された 1 対の応答と、人間が好む応答を表す優先ラベルで終わります。この場合、事前トレーニングされた SFT モデルは利用できません。したがって、実験では、SFT モデルを形成するために、推奨される補完のみについて既製の言語モデルを微調整します。
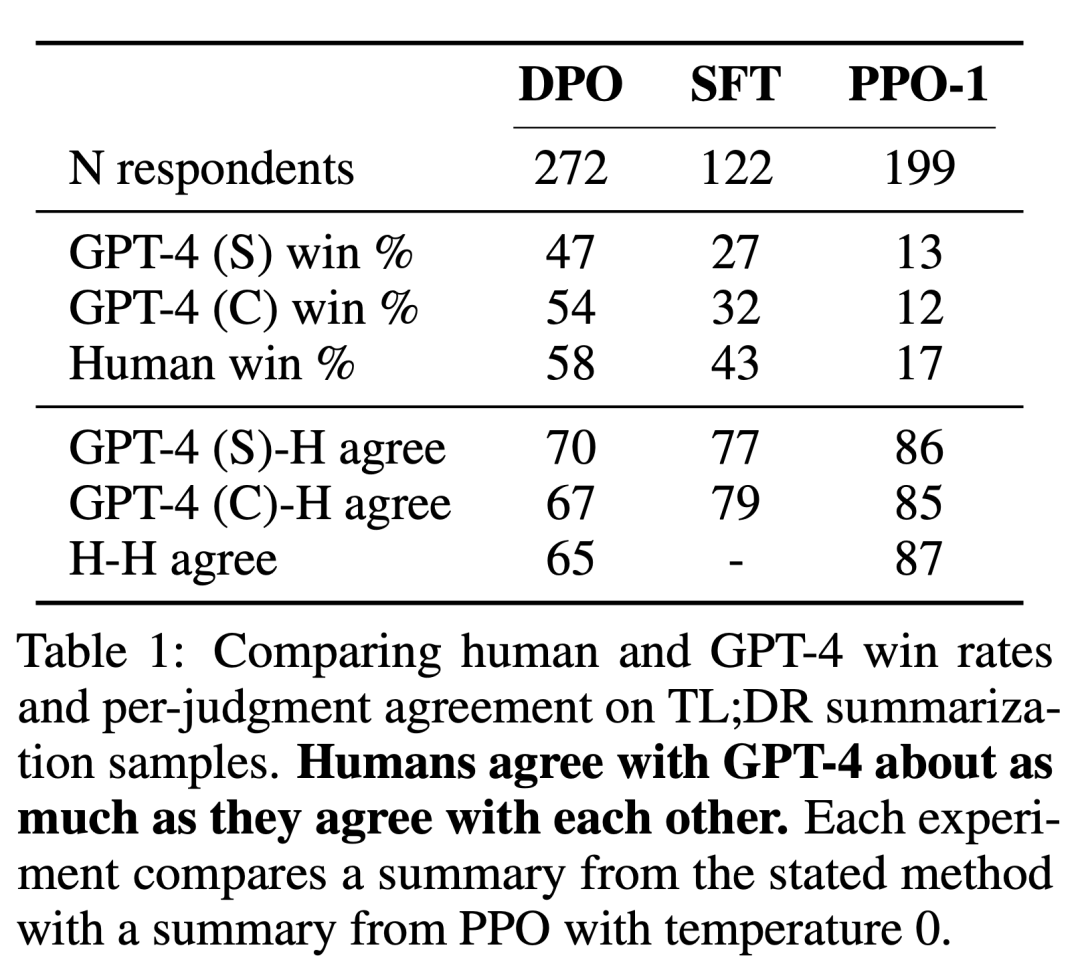
研究者らは 2 つの評価方法を使用しました。制約付き報酬最大化目標の最適化における各アルゴリズムの効率を分析するために、制御された感情生成環境における報酬達成の限界と基準戦略からの KL 乖離によって各アルゴリズムを実験で評価します。実験ではグラウンドトゥルースの報酬関数 (感情分類器) を使用できるため、この限界を計算できます。しかし実際には、グラウンドトゥルースの報酬関数は不明です。したがって、ベースライン戦略の勝率によってアルゴリズムの勝率を評価し、要約およびシングルラウンド対話設定における要約の品質と応答の有用性の人による評価の代理として GPT-4 を使用します。要約の場合、実験ではテスト マシン内の参照要約が制限として使用され、対話の場合、テスト データ セット内の優先応答がベースラインとして選択されます。既存の研究では、言語モデルが既存の指標よりも優れた自動評価器である可能性があることが示唆されていますが、研究者らは人を対象とした研究を実施し、評価に GPT-4 を使用する実現可能性を実証しました。GPT-4 は人間の場合に強く判断されました。人間と GPT-4 の相関関係一般に、ヒューマン・アノテーター間の合意と同等かそれ以上です。
DPO に加えて、研究者らは人間の好みとの一貫性を維持するために、いくつかの既存のトレーニング言語モデルも評価しました。最も単純な実験では、概要タスクに関する GPT-J のゼロショット プロンプトと、対話タスクに関する Pythia-2.8B の 2 ショット プロンプトを調査します。さらに、実験では SFT モデルと Preferred-FT を評価します。 Preferred-FT は、SFT モデル (感情制御と要約) または一般言語モデル (シングルターン対話) から選択された完了 y_w に関する教師あり学習によって微調整されたモデルです。もう 1 つの擬似教師ありアプローチは尤度法です。これは、y_w に割り当てられる確率を最大化し、y_l に割り当てられる確率を最小化するようにポリシーを最適化するだけです。実験では、「Unlikehood」に対してオプションの係数 α∈[0,1] を使用します。彼らはまた、嗜好データから学習した報酬関数を使用した PPO と PPO-GT も検討しました。 PPO-GT は、制御された感情設定で利用可能なグラウンド トゥルース報酬関数から学習されたオラクルです。感情実験では、チームは PPO-GT の 2 つの実装 (既製バージョンと修正バージョン) を使用しました。後者では、報酬を正規化し、ハイパーパラメーターをさらに調整してパフォーマンスを向上させます (実験では、報酬を学習して「通常の」PPO を実行する場合にもこれらの変更を使用しました)。最後に、N 個のベースラインのうち最良のものを検討し、SFT モデル (会話用語では Preferred-FT) から N 個の応答をサンプリングし、嗜好データセットから学習した報酬関数に基づいて最高スコアの応答を返します。この高性能アプローチは報酬モデルの品質を PPO の最適化から切り離しますが、テスト時にクエリごとに N 個のサンプル完了が必要となるため、中程度の N であっても計算的には非現実的です。
図 2 は、感情設定におけるさまざまなアルゴリズムの報酬 KL 限界を示しています。
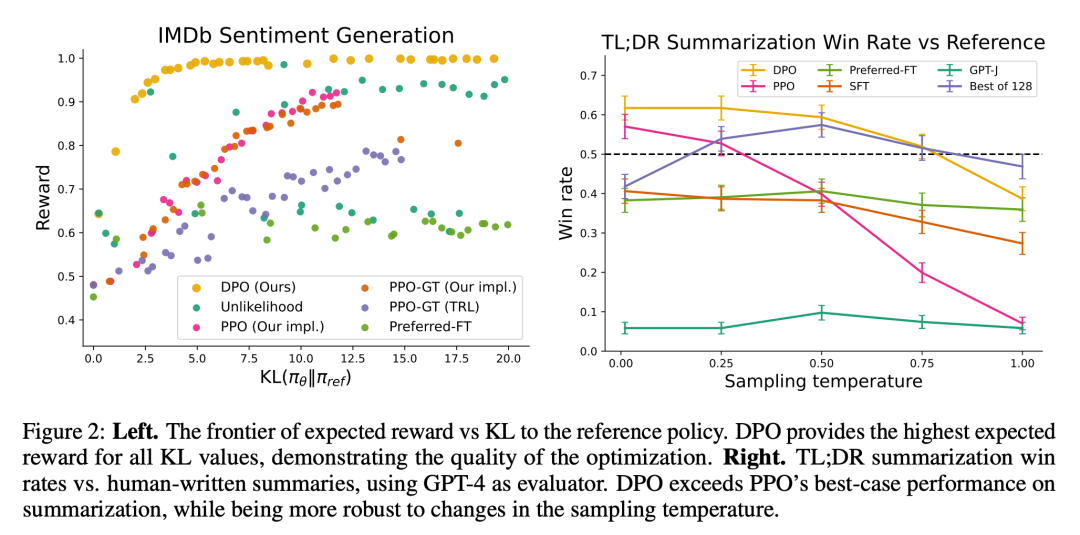
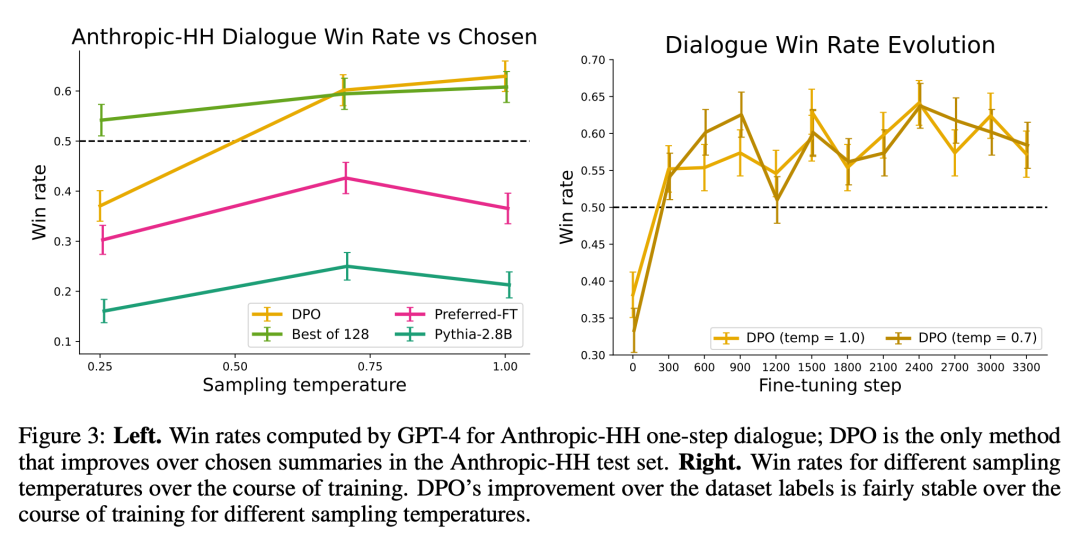
図 3 は、DPO が比較的早く最適なパフォーマンスに収束することを示しています。
研究の詳細については、元の論文を参照してください。
以上がRLHF の「RL」は必要ですか?バイナリ クロス エントロピーを使用して LLM を直接微調整する人もいますが、その効果はより優れています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7504
7504
 15
1378
52
78
11
19
54
15
1378
52
78
11
19
54

 Debian Apacheログ形式の構成方法
Apr 12, 2025 pm 11:30 PM
Debian Apacheログ形式の構成方法
Apr 12, 2025 pm 11:30 PM
この記事では、Debian SystemsでApacheのログ形式をカスタマイズする方法について説明します。次の手順では、構成プロセスをガイドします。ステップ1:Apache構成ファイルにアクセスするDebianシステムのメインApache構成ファイルは、/etc/apache2/apache2.confまたは/etc/apache2/httpd.confにあります。次のコマンドを使用してルートアクセス許可を使用して構成ファイルを開きます。sudonano/etc/apache2/apache2.confまたはsudonano/etc/apache2/httpd.confステップ2:検索または検索または
 Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Systemsでは、Readdir関数はディレクトリコンテンツを読み取るために使用されますが、それが戻る順序は事前に定義されていません。ディレクトリ内のファイルを並べ替えるには、最初にすべてのファイルを読み取り、QSORT関数を使用してソートする必要があります。次のコードは、debianシステムにreaddirとqsortを使用してディレクトリファイルを並べ替える方法を示しています。
 Tomcatログがメモリの漏れのトラブルシューティングに役立つ方法
Apr 12, 2025 pm 11:42 PM
Tomcatログがメモリの漏れのトラブルシューティングに役立つ方法
Apr 12, 2025 pm 11:42 PM
Tomcatログは、メモリリークの問題を診断するための鍵です。 Tomcatログを分析することにより、メモリの使用状況とガベージコレクション(GC)の動作に関する洞察を得ることができ、メモリリークを効果的に見つけて解決できます。 Tomcatログを使用してメモリリークをトラブルシューティングする方法は次のとおりです。1。GCログ分析最初に、詳細なGCロギングを有効にします。 Tomcatの起動パラメーターに次のJVMオプションを追加します:-xx:printgcdetails-xx:printgcdateStamps-xloggc:gc.logこれらのパラメーターは、GCタイプ、リサイクルオブジェクトサイズ、時間などの情報を含む詳細なGCログ(GC.log)を生成します。分析GC.LOG
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Debian Syslogのファイアウォールルールを構成する方法
Apr 13, 2025 am 06:51 AM
Debian Syslogのファイアウォールルールを構成する方法
Apr 13, 2025 am 06:51 AM
この記事では、Debian SystemsでiPtablesまたはUFWを使用してファイアウォールルールを構成し、Syslogを使用してファイアウォールアクティビティを記録する方法について説明します。方法1:Iptablesiptablesの使用は、Debian Systemの強力なコマンドラインファイアウォールツールです。既存のルールを表示する:次のコマンドを使用して現在のiPtablesルールを表示します。Sudoiptables-L-N-vでは特定のIPアクセスを許可します。たとえば、IPアドレス192.168.1.100がポート80にアクセスできるようにします:sudoiptables-input-ptcp - dport80-s192.166
 Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
このガイドでは、Debian SystemsでSyslogの使用方法を学ぶように導きます。 Syslogは、ロギングシステムとアプリケーションログメッセージのLinuxシステムの重要なサービスです。管理者がシステムアクティビティを監視および分析して、問題を迅速に特定および解決するのに役立ちます。 1. syslogの基本的な知識Syslogのコア関数には以下が含まれます。複数のログ出力形式とターゲットの場所(ファイルやネットワークなど)をサポートします。リアルタイムのログ表示およびフィルタリング機能を提供します。 2。syslog(rsyslogを使用)をインストールして構成するDebianシステムは、デフォルトでrsyslogを使用します。次のコマンドでインストールできます:sudoaptupdatesud
 Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverのファイアウォールの構成は、サーバーのセキュリティを確保するための重要なステップです。以下は、iPtablesやFirewalldの使用を含む、一般的に使用されるファイアウォール構成方法です。 iPtablesを使用してファイアウォールを構成してIPTablesをインストールします(まだインストールされていない場合):sudoapt-getupdatesudoapt-getinstalliptablesview現在のiptablesルール:sudoiptables-l configuration
