

大量のデータにラベルを付ける必要がなく、ターゲット検出 OVD の新しいパラダイムはマルチモーダル AGI をさらに一歩進めます

ターゲット検出は、コンピューター ビジョンにおける非常に重要な基本タスクです。一般的な画像分類/認識タスクとは異なり、ターゲット検出では、モデルが指定されたターゲット カテゴリに加えてターゲットの位置と位置をさらに与える必要があります。サイズ情報は、CV の 3 つの主要なタスク (識別、検出、セグメンテーション) において重要な役割を果たします。
現在普及しているマルチモーダル GPT-4 は、視覚的な目標認識能力のみを備えており、より困難な目標検出タスクを完了することはできません。画像やビデオ内のオブジェクトのカテゴリ、位置、サイズ情報を認識することは、自動運転における歩行者や車両の認識、セキュリティ監視アプリケーションにおけるフェイスロック、医療画像分析など、実際の生産における多くの人工知能アプリケーションの鍵となります。 、など。
YOLO シリーズ、R-CNN シリーズ、その他のターゲット検出アルゴリズムなどの既存のターゲット検出手法は、科学研究者の継続的な努力により、高いターゲット検出精度と効率を実現してきました。既存の手法では、モデルのトレーニング前に検出するターゲットのセット (閉セット) を定義する必要があるため、トレーニング セット外のターゲットを検出できません。たとえば、顔を検出するためにトレーニングされたモデルを車両の検出に使用することはできません。既存の手法は手動でラベル付けされたデータに大きく依存しているため、検出対象のカテゴリを追加または変更する必要がある場合、一方ではトレーニング データの再ラベル付けが必要になり、他方ではモデルのラベル付けが必要になります。再トレーニングには時間と労力がかかります。
考えられる解決策は、大量の画像を収集し、Box 情報とセマンティック情報を手動でラベル付けすることですが、これには非常に高額なラベル付けコストが必要となり、モデルのテストには大量のデータが使用されます。データのロングテール分布や手動アノテーションの不安定な品質などの要因は、検出モデルのパフォーマンスに影響を与えます。
CVPR 2021 で公開された記事 OVR-CNN [1] は、新しいターゲット検出パラダイム、つまりオープン語彙検出 (OVD、オープンワールドターゲット検出とも呼ばれる) を提案しています。前述の問題、つまりオープンワールドにおける未知のオブジェクトの検出シナリオです。
OVD は、注釈付きデータの量を手動で増やすことなく、任意の数とカテゴリのターゲットを識別して位置を特定できる機能により、提案されて以来、学界と産業界から継続的に注目を集めてきました。従来の目標検出タスクに新たな活力と新たな課題をもたらし、将来的には目標検出の新たなパラダイムとなることが期待されています。
具体的には、OVD テクノロジーでは、クラスフリー (クラスに依存しない) 領域検出器を変換することで、未知のカテゴリに対する検出モデルの検出能力を強化するために、大量の画像に手動でアノテーションを付ける必要はありません。大量のラベルなしデータでトレーニングされたクロスモーダル モデルと組み合わせて、画像領域の特徴と検出対象の説明テキストをクロスモーダルに配置することで、オープンワールドのターゲットを理解するターゲット検出モデルの能力を拡張します。
CLIP [2]、ALIGN [3]、R2D2 [4] など、クロスモーダルおよびマルチモーダルの大規模モデル作業の最近の開発は非常に急速です。また、その開発は、OVD の誕生と、OVD 分野における関連研究の急速な反復と進化を促進しました。
OVD テクノロジーには、2 つの重要な問題の解決が含まれます: 1) 領域情報とクロスモーダル大規模モデル間の適応を改善する方法; 2) パンカテゴリー ターゲットを改善する方法 検出器の新しいカテゴリに一般化する能力。これら 2 つの観点から、OVD 分野の関連研究を以下に詳しく紹介します。
#OVD 基本プロセス図[1]
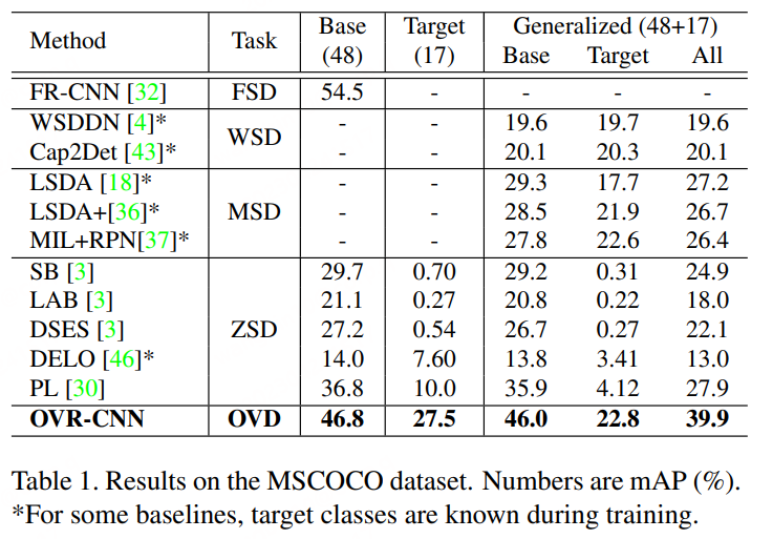
OVD の基本概念: OVD の使用には主に、少数ショットとゼロショットという 2 つのカテゴリのシナリオが含まれます。少数ショットとは、手動でラベル付けされた少数のトレーニング サンプルを含むターゲット カテゴリを指します。およびゼロショット 手動でラベル付けされたトレーニング サンプルが存在しないターゲット カテゴリを指します。一般的に使用される学業評価データセット COCO および LVIS では、データセットは Base クラスと Novel クラスに分割されており、Base クラスは少数ショットのシナリオに対応し、Novel クラスはゼロショットのシナリオに対応します。たとえば、COCO データ セットには 65 のカテゴリが含まれており、一般的な評価設定では、ベース セットには 48 のカテゴリが含まれており、これらの 48 カテゴリのみが少数ショット トレーニングで使用されます。 Novel セットには 17 のカテゴリが含まれており、トレーニング中にはまったく表示されません。テスト指標は主に Novel クラスの AP50 値を参照して比較しています。
論文 1: キャプションを使用したオープン語彙オブジェクトの検出

- ##論文アドレス: https://arxiv.org/pdf/2011.10678.pdf
- コード アドレス: https://github.com/ alirezazareian /ovr-cnn
OVR-CNN は CVPR 2021 の口頭論文であり、OVD 分野の先駆的な研究です。その 2 段階のトレーニング パラダイムは、その後の多くの OVD 作品に影響を与えました。以下の図に示すように、最初のステージでは主に画像とキャプションのペアを使用してビジュアル エンコーダを事前トレーニングします。このステージでは、BERT (固定パラメータ) を使用してワード マスクを生成し、弱教師ありグラウンディング マッチングが ImageNet をロードした ResNet50 で実行されます。著者は、監視が弱いとマッチングが局所最適に陥ると考えているため、堅牢性を高めるために単語マスク予測にマルチモーダル Transformer を追加しています。
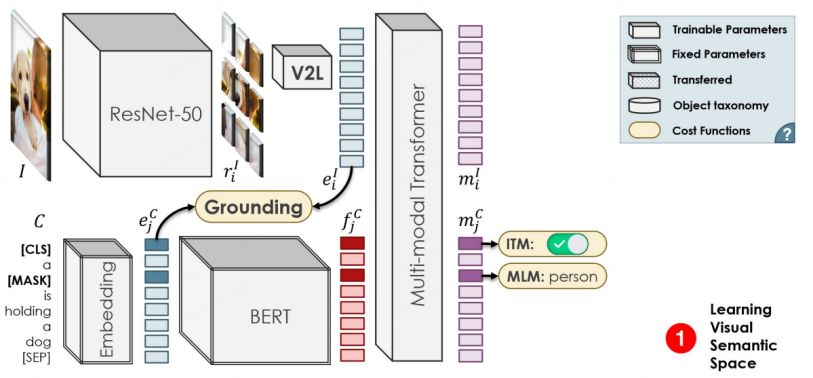
 ##文書アドレス: https://arxiv.org/abs/2112.09106
##文書アドレス: https://arxiv.org/abs/2112.09106
- コード アドレス: https://github.com/microsoft/RegionCLIP
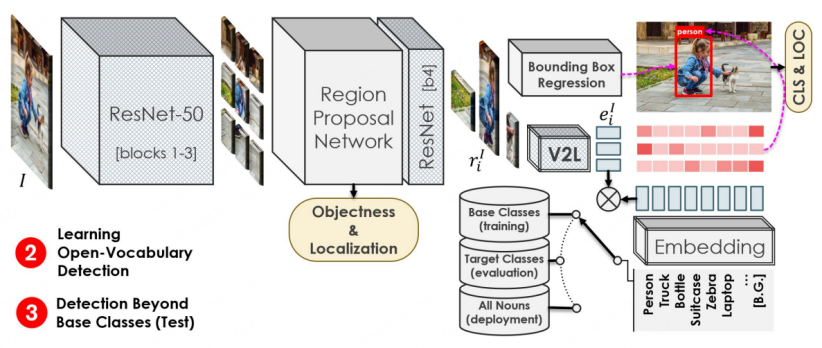
- OVR-CNN での BERT と複数のモデルの使用Modal Transfomer は、画像とテキストのペアの事前トレーニングを実行しますが、クロスモーダル大規模モデル研究の台頭により、科学研究者は、CLIP や ALIGN などのより強力なクロスモーダル大規模モデルを使用して OVD タスクをトレーニングし始めています。検出器モデル自体は主にプロポーザル、つまり地域情報を分類および識別することを目的としていますが、CVPR 2022 で公開された RegionalCLIP [5] では、CLIP などの現在存在する大規模なモデルは、トリミングされたエリアの分類能力が、トリミングされたエリアの分類能力よりもはるかに低いことがわかりました。元の画像自体の機能を改善するために、RegionCLIP は新しい 2 段階の OVD スキームを提案します。
第一段階では、データセットは主に CC3M、COCO キャプション、その他の画像とテキストのマッチング データ セットを使用します。地域レベルの分析のための蒸留事前トレーニング。具体的には:

2. LVIS 事前トレーニングに基づく RPN を使用して提案領域を抽出し、元の CLIP を使用して、抽出されたさまざまな領域を準備された説明と照合および分類し、さらにそれらを偽造セマンティック ラベルに組み立てます。
3. 用意した提案領域と意味ラベルを用いて、新しいCLIPモデルに対して領域とテキストの比較学習を行い、領域情報に特化したCLIPモデルを取得します。
4. 事前トレーニングでは、新しい CLIP モデルは、蒸留戦略を通じて元の CLIP の分類能力も学習し、完全な画像レベルで画像とテキストの比較学習を実行します。 CLIPモデルは完全なイメージを表現する能力を持っています。
第 2 段階では、取得した事前学習モデルを検出モデルに転送して転移学習を行います。
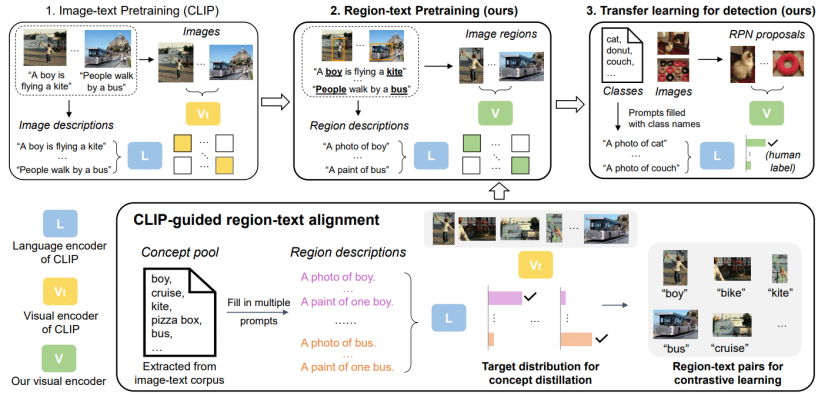
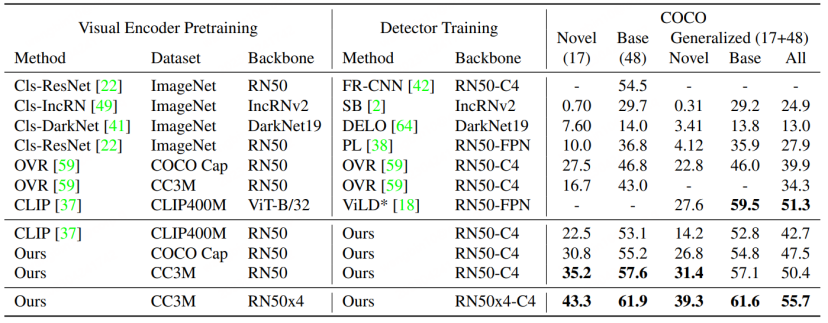
#RegionCLIP は、従来の検出モデル上で既存の大規模クロスモーダル モデルの表現機能をさらに拡張し、より優れたパフォーマンスを実現します。以下の図に示すように、RegionCLIP は OVR-CNN と比較して Novel カテゴリで大きな改善を達成しました。 RegionCLIP は、1 段階の事前トレーニングを通じて、領域情報とマルチモーダル大規模モデルの間の適応性を効果的に向上させますが、CORA は、1 段階のトレーニングに、より大きなパラメータースケールを持つより大きなクロスモーダル大規模モデルを使用すると、トレーニングコストが増加すると考えています。とても高くなります。
論文 3: CORA: 領域プロンプトとアンカーの事前マッチングによる未公開語彙検出のための CLIP の適応

- 論文アドレス: https://arxiv.org/abs/2303.13076
- コードアドレス: https://github.com/tgxs002/CORA
CORA [6] は CVPR 2023 に含まれています。CORA [6] が提案する現在の OVD タスクが直面する 2 つの障害を克服するために、DETR のような OVD モデルが設計されています。記事のタイトルに示されているように、モデルには主に領域プロンプティングとアンカー プレマッチングという 2 つの戦略が含まれています。前者は、Prompt 技術を使用して、CLIP ベースの地域分類器によって抽出された地域特徴を最適化し、全体と領域の間の分布ギャップを軽減します。後者は、DETR 検出手法のアンカー ポイント事前マッチング戦略を使用して OVD を改善します。新しいタイプのオブジェクトを配置するモデルの能力。
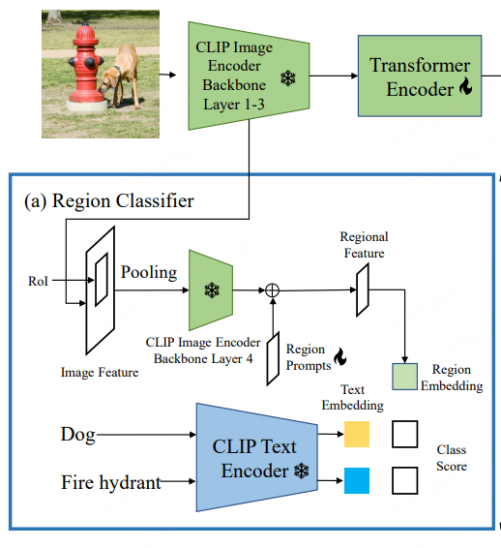
CLIP 画像全体の特徴と元のビジュアル エンコーダーの局所的特徴の間には分布ギャップがあり、その結果、分類精度が低くなります (これは、RegionCLIP の開始点と同様です)。したがって、CORA は、CLIP 画像エンコーダに適応し、地域情報の分類パフォーマンスを向上させるために、Region Prompting を提案します。具体的には、最初に画像全体が CLIP エンコーダの最初の 3 層を通じて特徴マップにエンコードされ、次に RoI Align によってアンカー ボックスまたは予測ボックスが生成され、領域特徴にマージされます。これは、CLIP 画像エンコーダの 4 番目の層によってエンコードされます。フル画像特徴マップと CLIP 画像エンコーダの地域特徴の間の分布ギャップを軽減するために、学習可能な地域プロンプトが設定され、第 4 層によって出力される特徴と結合されて、テキスト特徴で使用する最終的な地域特徴が生成されます。マッチングの場合、マッチング損失は単純なクロスエントロピー損失を使用し、CLIP に関連するパラメーター モデルはトレーニング プロセス中にすべてフリーズされます。
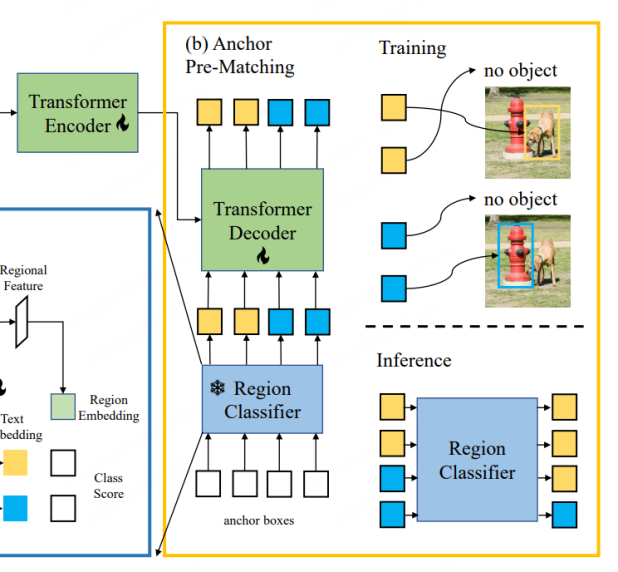
CORA は、DETR に似た DETR のような検出器モデルであり、アンカー事前マッチング戦略を使用して、フレーム回帰トレーニング用に事前に候補フレームを生成します。具体的には、アンカー プリマッチングでは、各ラベル ボックスを最も近いアンカー ボックスのセットと照合して、どのアンカー ボックスをポジティブ サンプルとみなすべきか、どのアンカー ボックスをネガティブ サンプルとみなすべきかを決定します。通常、このマッチング プロセスは IoU (交差対和集合比) に基づいており、アンカー ボックスとラベル ボックス間の IoU が事前に定義されたしきい値を超えている場合はポジティブ サンプルとみなされ、それ以外の場合はネガティブ サンプルとみなされます。 CORA は、この戦略が新しいカテゴリへのローカリゼーション能力の一般化を効果的に改善できることを示しています。
しかし、アンカー事前マッチング機構を使用すると、少なくとも 1 つのアンカー ボックスがラベル ボックスに一致する場合にのみトレーニングを正常に実行できるなど、いくつかの問題も発生します。それ以外の場合、ラベル ボックスは無視され、モデルの収束が妨げられます。さらに、ラベル ボックスがより正確なアンカー ポイント ボックスを取得したとしても、領域分類器の認識精度が限られているため、ラベル ボックスは依然として無視される可能性があります。つまり、ラベル ボックスに対応するカテゴリ情報は、ラベル ボックスに対応するカテゴリ情報と一致していません。 CLIP トレーニングに基づく領域分類子。したがって、CORA は CLIP-Aligned テクノロジーを使用して、CLIP の意味認識機能と事前トレーニングされた ROI の位置決め機能を利用して、少ない労力でトレーニング データ セット内の画像のラベルを再設定します。トレーニング より多くのタグ ボックスに一致します。
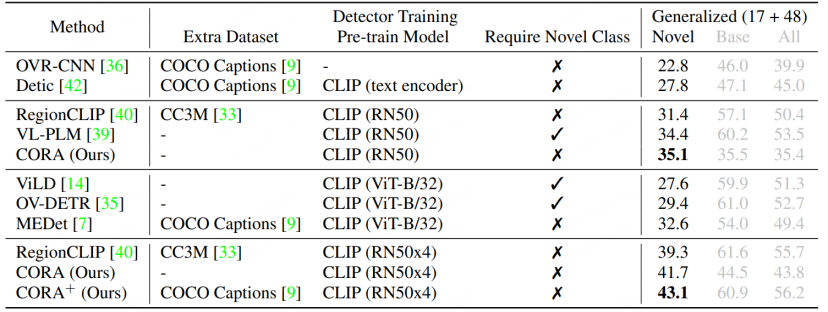
RegionCLIP と比較すると、CORA は COCO データ セットの AP50 値を 2.4 もさらに向上させます。
概要と展望
OVD テクノロジーは、現在人気のあるクロス/マルチモーダル大規模モデルの開発と密接に関連しているだけでなく、過去の科学研究者の目標も継承しています。検出分野における技術の蓄積は、従来の AI 技術と一般的な AI 機能の研究をうまく結び付けるものです。 OVDは、未来に向けた新たな目標検出技術であり、あらゆる目標を検出・位置特定できるOVDの能力は、マルチモーダル大型モデルのさらなる開発を促進し、マルチモーダルAGIの重要な基盤となることが期待されています。開発中。現在、マルチモーダル大規模モデルの学習データ ソースは、インターネット上の多数の大まかな情報ペア、つまりテキストと画像のペア、またはテキストと音声のペアです。 OVD テクノロジーを使用して、元の大まかな画像情報を正確に特定し、コーパスをフィルタリングするための画像の意味情報の予測を支援する場合、大規模モデルの事前トレーニング データの品質がさらに向上し、表現能力と理解能力が最適化されます。大型モデルの。
良い例は SAM (Segment Anything)[7] です。SAM を使用すると、科学研究者は一般的な視覚的な大規模モデルの将来の方向性を確認できるだけでなく、多くの思考のきっかけにもなります。 OVD テクノロジーを SAM とうまく連携させることで、SAM の意味理解能力を強化し、SAM に必要なボックス情報を自動的に生成することで、人的資源をさらに解放できることは注目に値します。 AIGC (人工知能生成コンテンツ) の場合と同様に、OVD テクノロジーはユーザーと対話する機能も強化できます。たとえば、ユーザーが写真内の特定のターゲットを指定して変更したり、ターゲットの説明を生成したりする必要がある場合、 OVD の言語理解機能と未知のターゲットを検出する OVD 機能を利用して、ユーザーが説明したオブジェクトを正確に特定し、より高品質のコンテンツ生成を実現します。 OVD 分野の関連研究は現在活況を呈しており、OVD 技術が将来の汎用 AI 大型モデルにもたらす可能性のある変化には期待に値します。
以上が大量のデータにラベルを付ける必要がなく、ターゲット検出 OVD の新しいパラダイムはマルチモーダル AGI をさらに一歩進めますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7733
7733
 15
1643
14
1397
52
1290
25
1233
29
15
1643
14
1397
52
1290
25
1233
29

 ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
DDREASE は、ハード ドライブ、SSD、RAM ディスク、CD、DVD、USB ストレージ デバイスなどのファイル デバイスまたはブロック デバイスからデータを回復するためのツールです。あるブロック デバイスから別のブロック デバイスにデータをコピーし、破損したデータ ブロックを残して正常なデータ ブロックのみを移動します。 ddreasue は、回復操作中に干渉を必要としないため、完全に自動化された強力な回復ツールです。さらに、ddasue マップ ファイルのおかげでいつでも停止および再開できます。 DDREASE のその他の主要な機能は次のとおりです。 リカバリされたデータは上書きされませんが、反復リカバリの場合にギャップが埋められます。ただし、ツールに明示的に指示されている場合は切り詰めることができます。複数のファイルまたはブロックから単一のファイルにデータを復元します
 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
マルチモーダル文書理解機能のための新しい SOTA!アリババの mPLUG チームは、最新のオープンソース作品 mPLUG-DocOwl1.5 をリリースしました。これは、高解像度の画像テキスト認識、一般的な文書構造の理解、指示の遵守、外部知識の導入という 4 つの主要な課題に対処するための一連のソリューションを提案しています。さっそく、その効果を見てみましょう。複雑な構造のグラフをワンクリックで認識しMarkdown形式に変換:さまざまなスタイルのグラフが利用可能:より詳細な文字認識や位置決めも簡単に対応:文書理解の詳しい説明も可能:ご存知「文書理解」 「」は現在、大規模な言語モデルの実装にとって重要なシナリオです。市場には文書の読み取りを支援する多くの製品が存在します。その中には、主にテキスト認識に OCR システムを使用し、テキスト処理に LLM と連携する製品もあります。
 柔軟かつ高速な 5 本の指を備え、人間のタスクを自律的に完了する初のロボットが登場、大型モデルが仮想空間トレーニングをサポート
Mar 11, 2024 pm 12:10 PM
柔軟かつ高速な 5 本の指を備え、人間のタスクを自律的に完了する初のロボットが登場、大型モデルが仮想空間トレーニングをサポート
Mar 11, 2024 pm 12:10 PM
今週、OpenAI、Microsoft、Bezos、Nvidiaが投資するロボット企業FigureAIは、7億ドル近くの資金調達を受け、来年中に自立歩行できる人型ロボットを開発する計画であると発表した。そしてテスラのオプティマスプライムには繰り返し良い知らせが届いている。今年が人型ロボットが爆発的に普及する年になることを疑う人はいないだろう。カナダに拠点を置くロボット企業 SanctuaryAI は、最近新しい人型ロボット Phoenix をリリースしました。当局者らは、多くのタスクを人間と同じ速度で自律的に完了できると主張している。人間のスピードでタスクを自律的に完了できる世界初のロボットである Pheonix は、各オブジェクトを優しくつかみ、動かし、左右にエレガントに配置することができます。自律的に物体を識別できる
