

AI をどこにでも普及させましょう!インテルが新しい VPU を発表: 超高エネルギー効率が GPU を圧倒

AI、人工知能、これは実際にはまったく新しいものではありません。
初期の SF 作品からその後の段階的な実装に至るまで、1997 年にチェスの名手カスパロフを破った IBM スーパーコンピューター「ディープ ブルー」から、2016 年に囲碁チャンピオンのイ・セドルを破った Google AlphaGo に至るまで、AI は常にそこにありました。進歩は常に進化しています。
しかし、コンピューティング能力のアルゴリズム、技術的能力、アプリケーション シナリオなどにさまざまな制限があるため、AI は常に空中の城のように感じられてきました。
ChatGPT が登場するまで、AI が本当に一般の人々の熱意に火をつけるようになり、AI が非常に強力で簡単に利用できるため、多くの個人や企業が AI に興奮し夢中になっていることがわかりました。

ご存知のとおり、効率的で実用的な AI を実現するには、十分に強力で合理的なハードウェアとアルゴリズムが 2 つの基礎となります。この AI ブームにおいて、NVIDIA はハイ パフォーマンス コンピューティングの分野での長年の経験を誇りに思っています。フューチャーレイアウトと深耕は超大規模クラウドAI開発に最適です。
もちろん、AI はクラウド側とデバイス側の実装方法も適用シナリオも多様です。
NVIDIAはクラウド側と生成型AIに注力、インテルはクラウド側生成型と端末側判断型の両方を同時に攻めている 端末側で動作するAIが増えるにつれ、経験によってもたらされる改善はますます明らかになっており、インテルがやるべきことはたくさんあります。
デバイスサイド AI にはいくつかの優れた機能があります:
第一に、ユーザーベースは巨大であり、アプリケーションシナリオはますます広範になっています;
第二に、レイテンシーが非常に低いため、ネットワークに依存して命令とデータを処理のためにクラウドに送信してから返す必要がありません。
3つ目はプライバシーとセキュリティで、アップロード後に個人情報や企業秘密などが漏洩する心配はありません;4つ目はコストが安く、大規模なサーバーや計算が不要で、ローカルの設備のみで完結します。
背景ぼかし、視覚美化、音響美化 (音声ノイズ リダクション)、ビデオ ノイズ リダクション、画像セグメンテーションなど、人々が慣れ親しんでいる機能です。これはエンドサイド AI の典型的な適用シナリオであり、AI は舞台裏で懸命に働いています。
より良い結果を達成するために、これらのアプリケーションはより完全で複雑なネットワーク モデルを必要とし、当然のことながらコンピューティング能力に対する需要は急速に増大しています。たとえば、ノイズ抑制には 2 年前に比べて 50 倍の計算能力が必要となり、背景のセグメンテーションも 10 倍以上増加しています。
言うまでもなく、生成 AI モデルの出現後、コンピューティング能力に対する需要は飛躍的に増加し、直接的には桁違いに増加しています。安定拡散であろうと、言語ベースの GTP であろうと、モデルのパラメーターは非常に重要です。誇張された。
例えば、GPT3 のパラメータ数は GPT2 の約 500 倍となる約 1,750 億個に達し、GPT4 は兆レベルに達すると推定されています。
これらはすべて、ハードウェアとアルゴリズムに対してより厳しい要件を提示しています。

これ以前は、インテル AI ソリューションは主に CPU と GPU のアーキテクチャと命令セット レベルで高速化されていました。
たとえば、第 10 世代 Core と第 2 世代から追加された深層学習に基づく DL Boostは、VNNI ベクトル ニューラル ネットワーク命令、BF16/INT8 アクセラレーションなどを含め、強力に拡張可能です。
 たとえば、第 11 世代 Core に追加された
たとえば、第 11 世代 Core に追加された
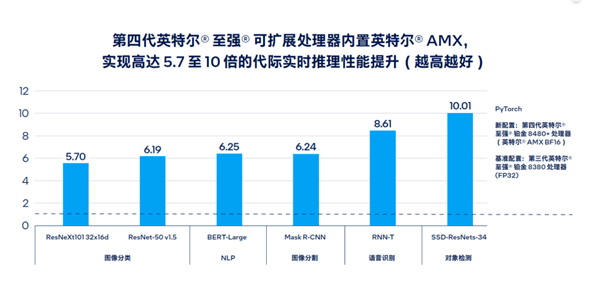
は、NPU の役割に相当し、消費リソースが非常に少なく、効率的にニューラル推論計算を実行できます。 たとえば、Sapphire Rapids というコード名で呼ばれる第 4 世代のスケーラブルな
AMX Advanced Matrix Extensionは、AI のリアルタイム推論とトレーニングのパフォーマンスを最大 10 倍向上させ、大規模な言語モデルの処理速度を向上させました。 20 倍も改善されており、サポートするソフトウェアとツールの開発もより完全で豊富になっています。
 インテルの見解では、
インテルの見解では、
強力なコンピューティング能力を備えたもの、超低レイテンシーを備えたもの、万能なものもあります。スペシャライズを持っている人もいます。
AI には、インフラストラクチャとして、さまざまな負荷と遅延を伴うさまざまなシナリオ アプリケーションと要件があります。たとえば、リアルタイムの音声および画像処理は、それほど多くのコンピューティング能力を必要としませんが、非常に繊細です。遅延に敏感です。 現時点では、Intel の XPU 戦略は、非常に的を絞った特別な利点を持っています。CPU は遅延に敏感な軽量 AI 処理に適しており、GPU は高負荷で並列性の高い AI アプリケーションに適しています。
Intel のもう 1 つの比類のない利点は、その安定した巨大な x86 エコシステムであり、アプリケーションや開発に関係なく幅広い大衆基盤を持っています。
今、Intel は再び VPU を搭載しています。

今年後半にリリースされる Meteor Lake には、初めて独立した VPU ユニットが統合され、特定の AI 操作をより効率的に実行できるように全モデルに標準搭載されます。
Intel VPU ユニットの技術ソースは、2017 年に Intel が買収した AI スタートアップ Movidius から来ており、それによって設計された VPU アーキテクチャは革新的であり、強力なコンピューティング能力を実現するために必要な消費電力はわずか 1.5 W です。 4TOPS. The Energy Efficiency Ratio is Simply Excellent. は、最初はドローンの障害物回避などに使用されていましたが、現在ではプロセッサーに組み込まれ、CPU や GPU と連携して動作します。
VPU は本質的に AI 用に設計された新しいアーキテクチャです。一部の行列演算を効率的に実行でき、特にスパース処理に優れています。その超低消費電力と超高エネルギー効率は、次のような一部のアプリケーションに非常に適しています。ビデオ会議の背景のぼかしや削除、ストリーミング メディアのジェスチャー制御など、開かれて実行される長期的なシナリオが必要です。
Intel がすでに CPU と GPU を備えているのに VPU を構築する必要がある理由は、多くのエンドサイド アプリケーションが現在、バッテリー寿命に非常に敏感なノートブック上で実行されているためです。エネルギー効率の高い VPU が使用されています。モバイルアプリケーションに最適です。
もう一つの要因として、一般的なコンピューティングプラットフォームであるCPUやGPUはそれ自体が重いタスクを抱えており、そこに大量のAI負荷が加わると実行効率が大幅に低下してしまいます。


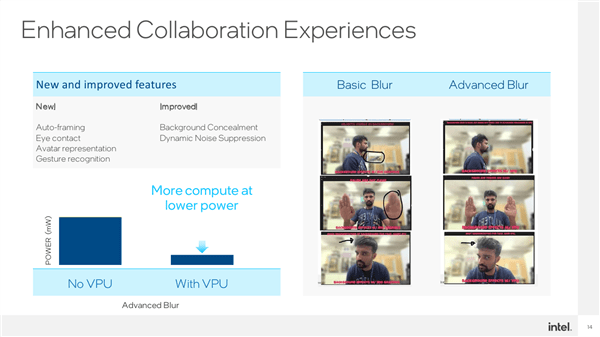
アプリケーション シナリオに特化した VPU は、ビデオ会議など、非常に広範囲にわたります。現在の CPU AI は、自動フレーミング (Auto-Framing)、視線追跡、仮想アバター/ポートレート、ジェスチャ認識などをすでに実装できます。
低消費電力で高い計算能力を備えた VPU を追加すると、背景のぼかし、動的ノイズ リダクション、その他の処理を強化して効果をより正確にすることもできます。たとえば、背景のオブジェクトは次のような場合にぼやけます。ぼやけてはいけないものがぼやけなくなるまで待ちます。
効率的なハードウェアと適切なシナリオでは、その強みを最大限に発揮して最高の結果を達成するには、同様に効率的なソフトウェアが必要です。これは、何万人ものソフトウェア開発者を抱えるインテルにとってはまったく問題ではありません。
Meteor Lake はまだ正式にリリースされていません。インテルは VPU の適応に関して多くのエコロジカル パートナーと協力しており、独立したソフトウェア開発者も非常に活発です。
たとえば、Adobe、多くのフィルター、自動処理、インテリジェントなカットアウトなどを VPU 上で実行できます。
たとえば、仮想アンカーなどの Unreal Engine のデジタル担当者や VPU は、リアルタイムで非常にうまくキャプチャしてレンダリングできます。
Blender、Audacity、OBS、GIMP...リストは長く作成できますが、そのリストはまだ増え続けています。

さらに重要なのは、CPU、GPU、VPU はそれぞれ単独で機能するのではなく、組み合わせてそれぞれの利点を最大限に発揮し、最高の AI エクスペリエンスを実現できることです。
例えば、GIMP には Stable Diffusion をベースとしたプラグインがあり、一般ユーザーが生成 AI を使用する敷居を大幅に下げることができ、CPU、GPU、VPU の高速化機能をフルに活用し、分散することができます。モデル全体を異なる IP 上で相互に連携させて、最高のパフォーマンスを実現します。
このうち、VPU は VNET モジュールをホストして実行し、GPU はエンコーダ モジュールを実行することで、複雑な画像を生成するのにわずか 20 秒程度しかかかりません。
このうち、VPU の消費電力が最も低く、次に CPU、GPU が最も高くなります。

インテルは、PC エクスペリエンスを向上させるための AI の重要性を十分に認識しており、この課題に対処するために、ハードウェア レベルとソフトウェア レベルの両方で AI の開発と普及を促進し、AI の強固な基盤を築くためにあらゆる努力を払っています。デバイス側のAIの開発と普及。
ハードウェア レベルでは、CPU、GPU、および VPU がユビキタスな基盤プラットフォームを形成し、ソフトウェア レベルでは、OpenVINO などのさまざまな標準化された開発ソフトウェアがアプリケーション シナリオの探索を大幅に促進します。
将来的には、Meteor Lake プラットフォームを搭載した薄型軽量ノートブックで、安定拡散などの大規模モデルを簡単に実行してヴィンセントグラフを実現できるようになり、AI の適用閾値が大幅に下がります。最終的にどこでも真の AI を実現します。

以上がAI をどこにでも普及させましょう!インテルが新しい VPU を発表: 超高エネルギー効率が GPU を圧倒の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7456
7456
 15
1376
52
77
11
14
10
15
1376
52
77
11
14
10

 vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのオブジェクトに文字列を変換する場合、標準のjson文字列にはjson.parse()が推奨されます。非標準のJSON文字列の場合、文字列は正規表現を使用して処理し、フォーマットまたはデコードされたURLエンコードに従ってメソッドを削減できます。文字列形式に従って適切な方法を選択し、バグを避けるためにセキュリティとエンコードの問題に注意してください。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue axiosのタイムアウトを設定するために、Axiosインスタンスを作成してタイムアウトオプションを指定できます。グローバル設定:Vue.Prototype。$ axios = axios.create({Timeout:5000});単一のリクエストで:this。$ axios.get( '/api/users'、{timeout:10000})。
 vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
概要:Vue.js文字列配列をオブジェクト配列に変換するための次の方法があります。基本方法:定期的なフォーマットデータに合わせてマップ関数を使用します。高度なゲームプレイ:正規表現を使用すると、複雑な形式を処理できますが、慎重に記述して考慮する必要があります。パフォーマンスの最適化:大量のデータを考慮すると、非同期操作または効率的なデータ処理ライブラリを使用できます。ベストプラクティス:コードスタイルをクリアし、意味のある変数名とコメントを使用して、コードを簡潔に保ちます。
 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
