

LLM とデータベースが出会うとき: Alibaba DAMO Academy と HKU が新しい Text-to-SQL ベンチマークを開始

背景
ラージ モデル (LLM) は、汎用人工知能 (AGI) の開発に新しい方向性を提供します。インターネット、書籍、その他のコーパスなどの大量の公開データを使用して、教師付きトレーニングを通じて、強力な言語理解、言語生成、推論などの能力が獲得されています。ただし、大規模なモデルでは、プライベート ドメイン データの活用には依然として課題がいくつかあります。プライベート ドメイン データとは、特定の企業または個人が所有するデータを指し、通常はドメイン固有の知識が含まれています。大規模なモデルとプライベート ドメインの知識を組み合わせることで、大きな価値が提供されます。
プライベート ドメインの知識は、データ形式の観点から非構造化データと構造化データに分類できます。ドキュメントなどの非構造化データは通常、検索を通じて強化され、langchain などのツールを使用して質問と回答のシステムを迅速に実装できます。データベース (DB) などの構造化データには、データベースと対話し、クエリと分析を行って有用な情報を取得するための大規模なモデルが必要です。最近では、LLM を使用したインテリジェントなデータベースの構築、BI 分析の実行、完全な自動テーブル構築など、大規模なモデルやデータベースを中心とした一連の製品やアプリケーションが派生しています。その中でも、自然言語でデータベースと対話する Text-to-SQL テクノロジは、常に非常に期待されている方向です。
学術界では、過去の text-to-SQL ベンチマークは小規模データベースのみに焦点を当てていました。最先端の LLM はすでに 85.3% の実行精度を達成していますが、これは LLM がデータベースへの自然言語インターフェイスとしてすでに利用可能ですか?
新世代のデータセット
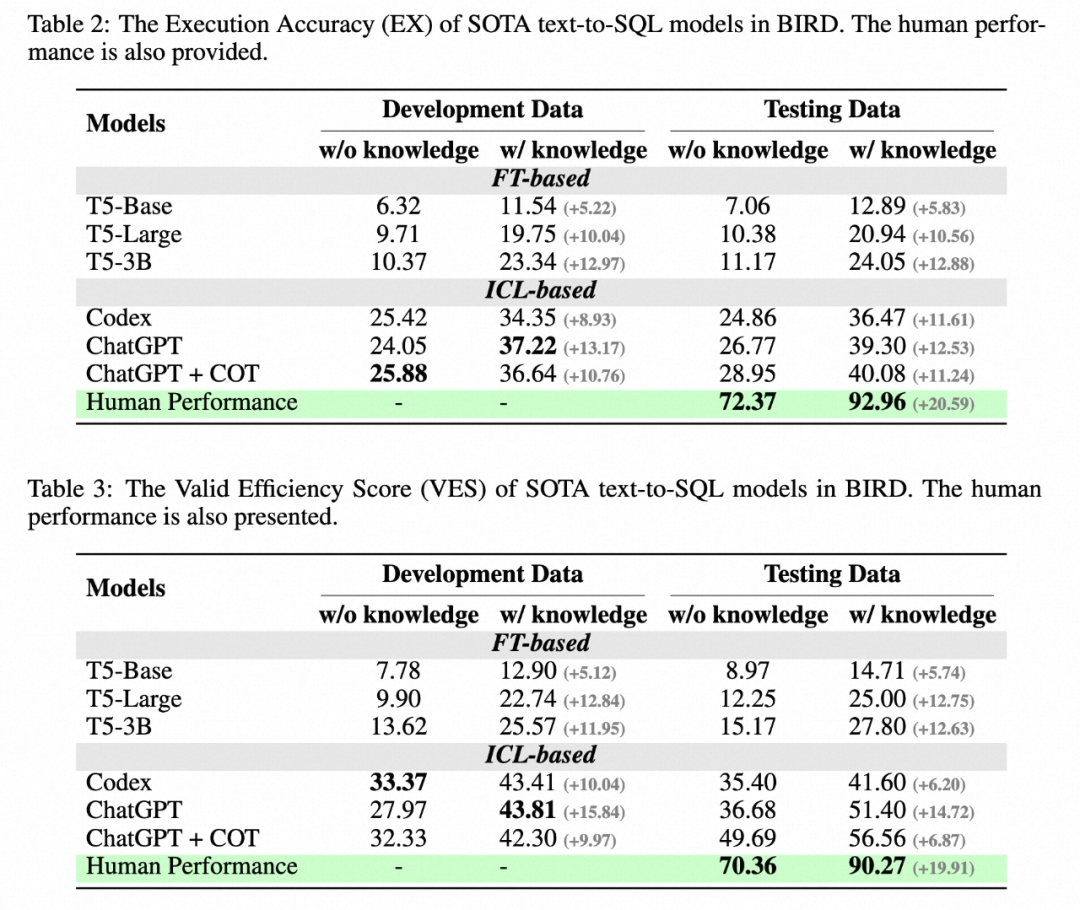
最近、アリババは香港大学およびその他の機関と協力して、新しいベンチマーク BIRD (Can LLM Already Serve as A Database) を立ち上げました。 ) 大規模な実データベース用のインターフェイス? 大規模データベース用の BIg ベンチ (グラウンデッド Text-to-SQL))、95 個の大規模データベースと高品質の Text-SQL ペアが含まれ、最大 33.4 GB のデータ ストレージ容量を備えています。 。以前の最高のモデルは、BIRD での評価が 40.08% にとどまっており、人間の結果である 92.96% にはまだ遠く及ばず、課題がまだ存在することが証明されました。 SQL の正しさの評価に加えて、著者は SQL の実行効率の評価も追加し、このモデルが正しい SQL を書くだけでなく、効率的な SQL を書くことができることを期待しました。

#論文: https://arxiv.org/abs/2305.03111
#ホームページ: https://bird-bench.github.io##コード: https://github.com /AlibabaResearch/DAMO-ConvAI/tree/main/bird
##現在、BIRD のデータとコード、リストはすべてオープンソース化されており、世界中で 10,000 回以上ダウンロードされています。 BIRD は、発売以来、Twitter 上で幅広い注目と議論を引き起こしました。 

# 海外ユーザーからのコメントも非常に刺激的です:

#見逃せない LLM プロジェクト

##非常に役立つチェックポイント、改善の温床

##
AI はあなたを助けますが、あなたの代わりにはなりません

##私の仕事は今のところ安全です...
方法の概要新しい課題
この研究は主に、実際のデータベースの Text-to-SQL 評価、過去に人気のあるテスト ベンチマーク、たとえば、Spider と WikiSQL は、少量のデータベース コンテンツを含むデータベース スキーマのみに焦点を当てているため、学術研究と実際のアプリケーションの間にギャップが生じます。 BIRD は、大規模で実際のデータベース コンテンツ、自然言語の質問とデータベース コンテンツの間の外部知識の推論、大規模なデータベースを処理する際の SQL の効率という 3 つの新しい課題に焦点を当てています。
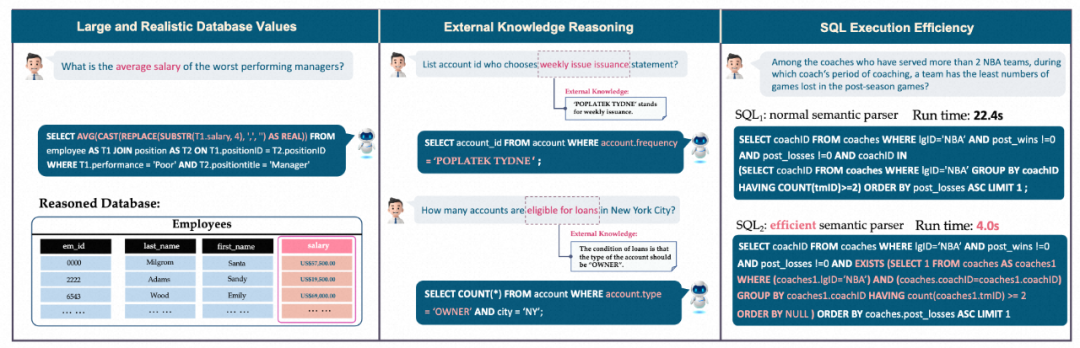
まず、データベースには大量のノイズの多いデータ値が含まれています。左側の例では、データベース内の文字列を浮動小数点値 (Float) に変換し、集計計算 (Aggregation) を実行することで平均給与を計算する必要があります。 # 次に、外部知識の推論が必要です。中央の例では、ユーザーに正確に回答を返すために、モデルはまずローンの対象となる口座タイプが「OWNER」である必要があることを認識する必要があります。データベース コンテンツの背後にあるものを明らかにするには、外部の知識と推論が必要になる場合があります。
最後に、クエリの実行効率を考慮する必要があります。右側の例では、より効率的な SQL クエリを使用することで速度が大幅に向上します。ユーザーは正しい SQL を書くことだけでなく、特に大規模なデータベースにおいて効率的な SQL 実行も期待しているため、これは業界にとって大きな価値があります。 ;
データ アノテーション
BIRD は、アノテーション プロセス中に質問の生成と SQL アノテーションを分離します。同時に、問題担当者や SQL 注釈担当者がデータベースをよりよく理解できるように、データベース説明ファイルを作成する専門家が追加されました。
1. データベース コレクション: 著者は、Kaggle や CTU Prague Relational Learning Repository などのオープン ソース データ プラットフォームから 80 のデータベースを収集して処理しました。実際のテーブル データを収集し、ER 図を構築し、現在のデータベースが現在の大規模モデルによって学習されないようにデータベース制約を設定することにより、15 のデータベースがブラック ボックス テストとして手動で作成されました。 BIRDのデータベースには、ブロックチェーン、スポーツ、医療、ゲームなどを網羅する37分野の複数分野のパターンと値が収録されています。
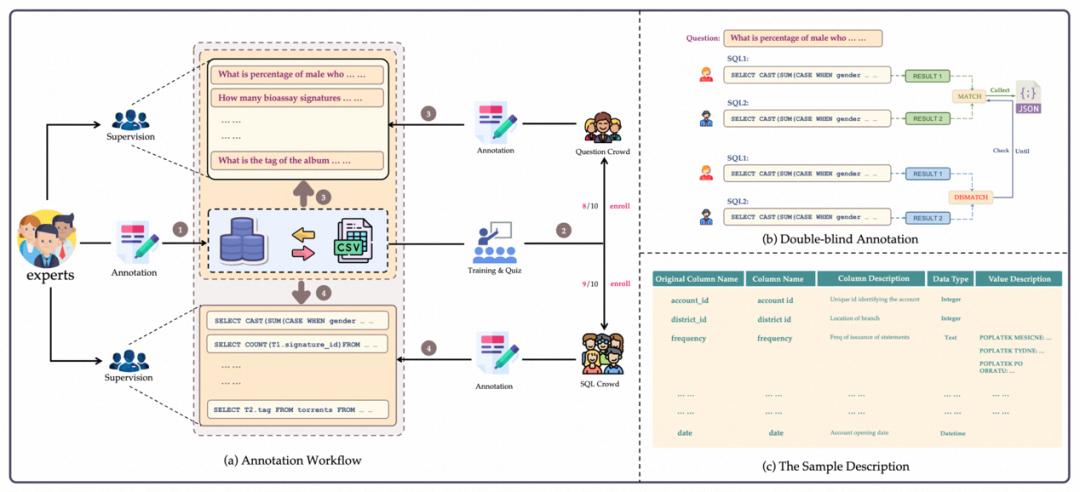
2. 問題集: まず、作成者は専門家を雇って、データベースの説明ファイルを作成します。説明ファイルには、列名、データベース値、および外部パラメーターの完全な説明が含まれます。価値や知識などを理解するために使用されます。次に、BIRD 用の質問を作成するために、米国、英国、カナダ、シンガポール、その他の国から 11 人のネイティブ スピーカーが採用されました。すべての講演者は少なくとも学士以上の学位を持っています。
3. SQL 生成: BIRD 用の SQL を生成するために、データ エンジニアとデータベース コースの学生で構成されるグローバル アノテーション チームが採用されました。データベースと参照データベース記述ファイルが与えられた場合、アノテーターは質問に正しく答えるために SQL を生成する必要があります。二重盲検アノテーション方法が採用されており、2 人のアノテーターが同じ質問にアノテーションを付ける必要があります。二重盲検アノテーションを使用すると、1 人のアノテーターによって引き起こされるエラーを最小限に抑えることができます。
4. 品質検査: 品質検査は、有効性と結果実行の一貫性の 2 つの部分に分かれています。有効性には、実行の正しさだけでなく、実行結果が null (NULL) にならないことも必要です。専門家は、SQL の実行結果が有効になるまで、問題の状況を徐々に修正します。
5. 難易度の分割: text-to-SQL の難易度の指標は、研究者にアルゴリズムを最適化するための参考情報を提供します。 Text-to-SQL の難易度は、SQL の複雑さだけでなく、質問の難しさ、追加の知識による理解の容易さ、データベースの複雑さなどの要因にも依存します。そこで著者は、SQL アノテーターにアノテーション プロセス中の難易度を評価するよう依頼し、その難易度を 3 つのカテゴリ (簡単、中程度、難しい) に分類しました。
データ統計
1. 質問タイプの統計: 質問は、基本的な質問タイプ (基礎的な質問タイプ) の 2 つのカテゴリに分類されます。タイプ)と推論タイプ。基本的な質問タイプには、従来の Text-to-SQL データセットでカバーされている質問が含まれますが、推論質問タイプには、値を理解するために外部の知識が必要な質問が含まれます。
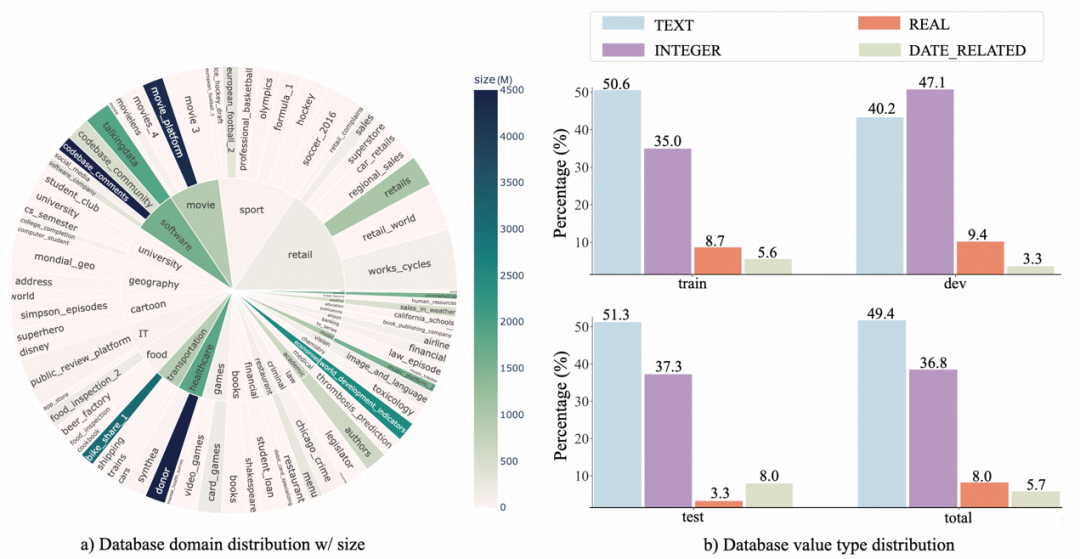
2. データベースの分布: 著者はサンバースト図を使用して、データベース ドメインとそのデータ サイズの関係を示します。半径が大きいほど、より多くのテキスト SQL がそのデータベースに基づいていることを意味し、その逆も同様です。色が濃いほどデータベース サイズが大きくなります。たとえば、ドナーはベンチマーク内で最大のデータベースであり、4.5 GB のスペースを占有します。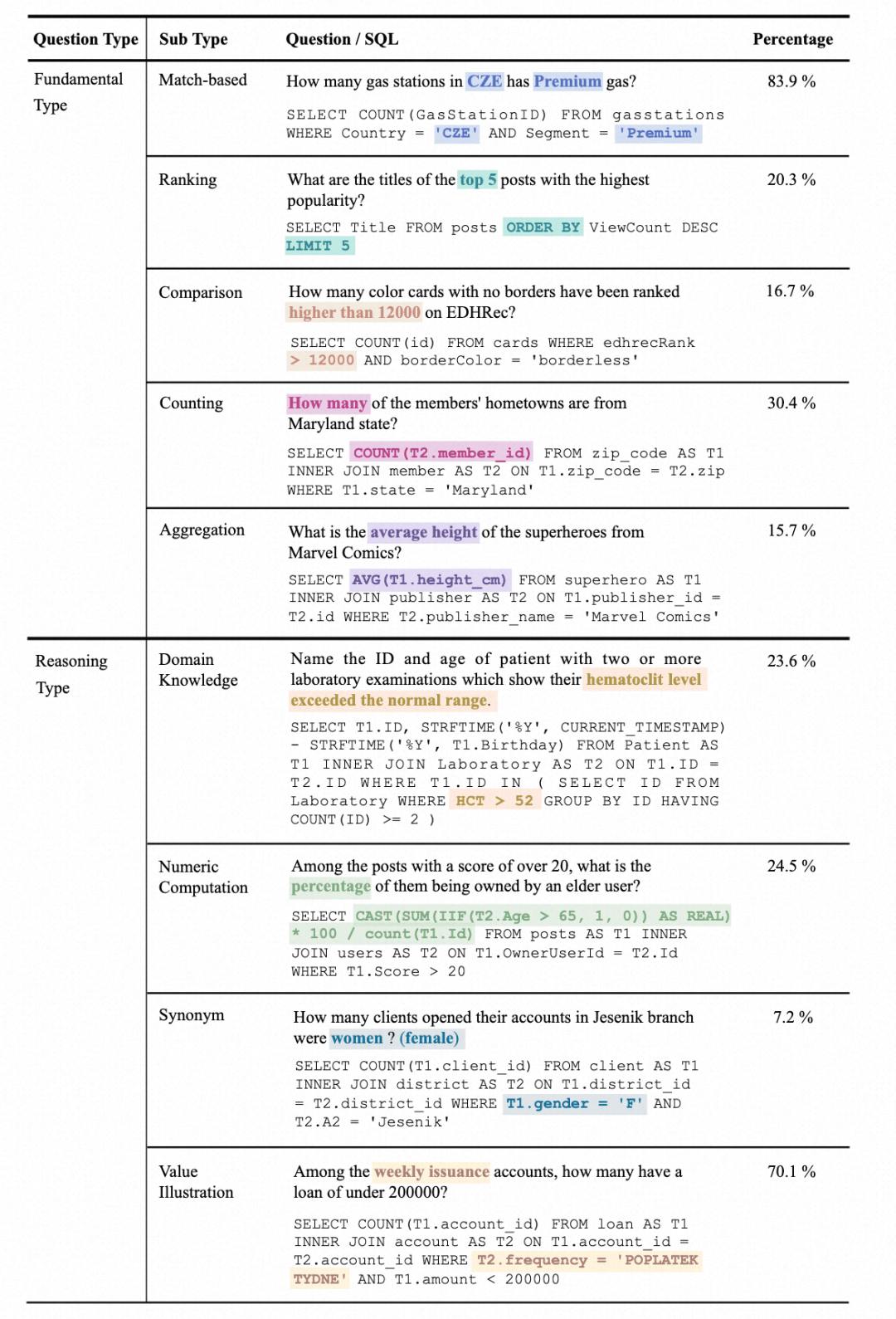
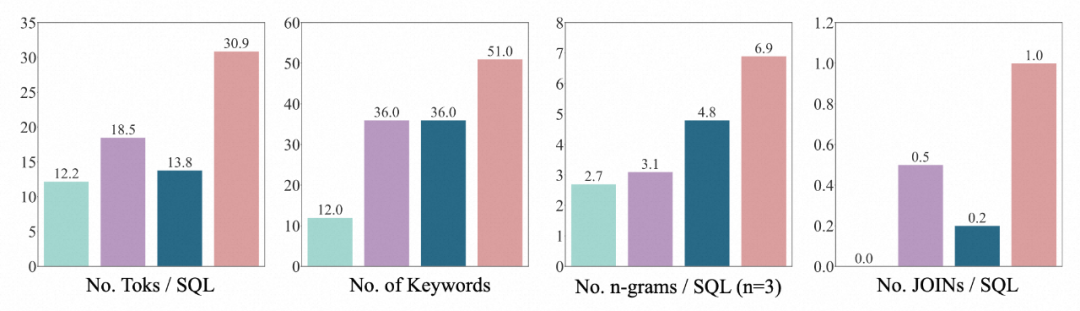
3.SQL 分布: SQL を通じて作成者によって渡されたトークンの数、キーワードの数、 n-gram 型、JOIN の数値とその他の 4 つの次元は、BIRD の SQL が最も多様で複雑であることを証明しています。
#評価指標
2. 有効効率スコア: SQL の精度と効率の両方を考慮します。 、モデルの予測を比較します。 SQL 実行速度と実際の注釈付き SQL 実行速度との相対的な差は、実行時間を効率の主な指標とします。
実験分析
著者は、学習型の T5 モデルと、パフォーマンスが良好な大規模モデルを選択しました以前のベンチマーク テストでは、ベースライン モデルとして言語モデル (LLM) を使用しました: Codex (code-davinci-002) および ChatGPT (gpt-3.5-turbo)。複数ステップの推論が実際のデータベース環境における大規模な言語モデルの推論機能を刺激できるかどうかをよりよく理解するために、その思考連鎖バージョンも提供されています。そして、ベースライン モデルを 2 つの設定でテストします。1 つは完全なスキーマ情報の入力で、もう 1 つは問題に関係するデータベース値を人間が理解し、モデルがデータベースを理解するのに役立つ自然言語記述 (知識証拠) に要約されます。 。
著者はいくつかの結論を述べています:
 1. 追加の知識の獲得: データベース値の理解に関する知識証拠 (知識証拠) を増やすことで、大幅な改善が見られます。これは、実際のデータベース シナリオでは、セマンティック解析機能だけに依存するだけでは十分ではないことを証明しています。データベース値を理解することで、ユーザーはより多くの情報を見つけることができます。正確に答えてください。
1. 追加の知識の獲得: データベース値の理解に関する知識証拠 (知識証拠) を増やすことで、大幅な改善が見られます。これは、実際のデータベース シナリオでは、セマンティック解析機能だけに依存するだけでは十分ではないことを証明しています。データベース値を理解することで、ユーザーはより多くの情報を見つけることができます。正確に答えてください。
2. 思考の連鎖は必ずしも完全に有益であるとは限りません: モデルに特定のデータベース値の記述とゼロショットがない場合、モデル自身の COT 推論をより正確に生成できます。 。しかし、追加の知識 (知識証拠) が与えられた場合、LLM は COT を実行するように依頼され、その効果は有意ではないか、さらには低下していることがわかりました。したがって、このシナリオでは、LLM によって知識の競合が発生する可能性があります。この矛盾をどのように解決して、モデルが外部の知識を受け入れ、モデル自身の強力な多段階推論の恩恵を受けることができるようにするかが、将来の重要な研究の方向性となるでしょう。
3. 人間とのギャップ: BIRD は人間による指標も提供します。著者は、初めてテスト セットに直面したときにアノテーターのパフォーマンスをテストするために試験を使用し、それを人間による指標の基礎として使用します。 。実験の結果、現在最高の LLM は依然として人間に遠く及ばないことが判明し、課題がまだ存在することが証明されました。著者らは詳細なエラー分析を実行し、将来の研究に向けた潜在的な方向性をいくつか提供しました。

LLM をデータベース分野に適用すると、ユーザーはよりスマートで便利なサービスを提供できるようになります。データベースのインタラクティブなエクスペリエンス。 BIRD の出現は、自然言語と実際のデータベース間のインタラクションのインテリジェントな開発を促進し、実際のデータベース シナリオ向けの text-to-SQL テクノロジーに進歩の余地を与え、研究者がより高度で実用的なデータベース アプリケーションを開発するのに役立ちます。
以上がLLM とデータベースが出会うとき: Alibaba DAMO Academy と HKU が新しい Text-to-SQL ベンチマークを開始の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 CでChronoライブラリを使用する方法は?
Apr 28, 2025 pm 10:18 PM
CでChronoライブラリを使用する方法は?
Apr 28, 2025 pm 10:18 PM
CでChronoライブラリを使用すると、時間と時間の間隔をより正確に制御できます。このライブラリの魅力を探りましょう。 CのChronoライブラリは、時間と時間の間隔に対処するための最新の方法を提供する標準ライブラリの一部です。 Time.HとCtimeに苦しんでいるプログラマーにとって、Chronoは間違いなく恩恵です。コードの読みやすさと保守性を向上させるだけでなく、より高い精度と柔軟性も提供します。基本から始めましょう。 Chronoライブラリには、主に次の重要なコンポーネントが含まれています。STD:: Chrono :: System_Clock:現在の時間を取得するために使用されるシステムクロックを表します。 STD :: Chron
 CでハイDPIディスプレイを処理する方法は?
Apr 28, 2025 pm 09:57 PM
CでハイDPIディスプレイを処理する方法は?
Apr 28, 2025 pm 09:57 PM
CでのハイDPIディスプレイの取り扱いは、次の手順で達成できます。1)DPIを理解してスケーリングし、オペレーティングシステムAPIを使用してDPI情報を取得し、グラフィックスの出力を調整します。 2)クロスプラットフォームの互換性を処理し、SDLやQTなどのクロスプラットフォームグラフィックライブラリを使用します。 3)パフォーマンスの最適化を実行し、キャッシュ、ハードウェアアクセラレーション、および詳細レベルの動的調整によりパフォーマンスを改善します。 4)ぼやけたテキストやインターフェイス要素などの一般的な問題を解決し、DPIスケーリングを正しく適用することで解決します。
 CでDMA操作を理解する方法は?
Apr 28, 2025 pm 10:09 PM
CでDMA操作を理解する方法は?
Apr 28, 2025 pm 10:09 PM
CのDMAとは、直接メモリアクセステクノロジーであるDirectMemoryAccessを指し、ハードウェアデバイスがCPU介入なしでメモリに直接データを送信できるようにします。 1)DMA操作は、ハードウェアデバイスとドライバーに大きく依存しており、実装方法はシステムごとに異なります。 2)メモリへの直接アクセスは、セキュリティリスクをもたらす可能性があり、コードの正確性とセキュリティを確保する必要があります。 3)DMAはパフォーマンスを改善できますが、不適切な使用はシステムのパフォーマンスの低下につながる可能性があります。実践と学習を通じて、DMAを使用するスキルを習得し、高速データ送信やリアルタイム信号処理などのシナリオでその効果を最大化できます。
 Cのリアルタイムオペレーティングシステムプログラミングとは何ですか?
Apr 28, 2025 pm 10:15 PM
Cのリアルタイムオペレーティングシステムプログラミングとは何ですか?
Apr 28, 2025 pm 10:15 PM
Cは、リアルタイムオペレーティングシステム(RTOS)プログラミングでうまく機能し、効率的な実行効率と正確な時間管理を提供します。 1)Cハードウェアリソースの直接的な動作と効率的なメモリ管理を通じて、RTOのニーズを満たします。 2)オブジェクト指向の機能を使用して、Cは柔軟なタスクスケジューリングシステムを設計できます。 3)Cは効率的な割り込み処理をサポートしますが、リアルタイムを確保するには、動的メモリの割り当てと例外処理を避ける必要があります。 4)テンプレートプログラミングとインライン関数は、パフォーマンスの最適化に役立ちます。 5)実際のアプリケーションでは、Cを使用して効率的なロギングシステムを実装できます。
 フィールドをMySQLテーブルに追加および削除する手順
Apr 29, 2025 pm 04:15 PM
フィールドをMySQLテーブルに追加および削除する手順
Apr 29, 2025 pm 04:15 PM
MySQLでは、AlterTabletable_nameaddcolumnnew_columnvarchar(255)afterexisting_columnを使用してフィールドを追加し、andtabletable_namedopcolumncolumn_to_dropを使用してフィールドを削除します。フィールドを追加するときは、クエリのパフォーマンスとデータ構造を最適化する場所を指定する必要があります。フィールドを削除する前に、操作が不可逆的であることを確認する必要があります。オンラインDDL、バックアップデータ、テスト環境、および低負荷期間を使用したテーブル構造の変更は、パフォーマンスの最適化とベストプラクティスです。
 Cのスレッドパフォーマンスを測定する方法は?
Apr 28, 2025 pm 10:21 PM
Cのスレッドパフォーマンスを測定する方法は?
Apr 28, 2025 pm 10:21 PM
Cのスレッドパフォーマンスの測定は、標準ライブラリのタイミングツール、パフォーマンス分析ツール、およびカスタムタイマーを使用できます。 1.ライブラリを使用して、実行時間を測定します。 2。パフォーマンス分析にはGPROFを使用します。手順には、コンピレーション中に-pgオプションを追加し、プログラムを実行してGmon.outファイルを生成し、パフォーマンスレポートの生成が含まれます。 3. ValgrindのCallGrindモジュールを使用して、より詳細な分析を実行します。手順には、プログラムを実行してCallGrind.outファイルを生成し、Kcachegrindを使用して結果を表示することが含まれます。 4.カスタムタイマーは、特定のコードセグメントの実行時間を柔軟に測定できます。これらの方法は、スレッドのパフォーマンスを完全に理解し、コードを最適化するのに役立ちます。
 定量的交換ランキング2025デジタル通貨のトップ10の推奨事項定量取引アプリ
Apr 30, 2025 pm 07:24 PM
定量的交換ランキング2025デジタル通貨のトップ10の推奨事項定量取引アプリ
Apr 30, 2025 pm 07:24 PM
交換に組み込まれた量子化ツールには、1。Binance:Binance先物の定量的モジュール、低い取り扱い手数料を提供し、AIアシストトランザクションをサポートします。 2。OKX(OUYI):マルチアカウント管理とインテリジェントな注文ルーティングをサポートし、制度レベルのリスク制御を提供します。独立した定量的戦略プラットフォームには、3。3Commas:ドラッグアンドドロップ戦略ジェネレーター、マルチプラットフォームヘッジアービトラージに適しています。 4。Quadency:カスタマイズされたリスクしきい値をサポートするプロフェッショナルレベルのアルゴリズム戦略ライブラリ。 5。Pionex:組み込み16のプリセット戦略、低い取引手数料。垂直ドメインツールには、6。cryptohopper:クラウドベースの定量的プラットフォーム、150の技術指標をサポートします。 7。BITSGAP:
 DeepSeekの公式Webサイトは、マウススクロールイベントの浸透の影響をどのように達成していますか?
Apr 30, 2025 pm 03:21 PM
DeepSeekの公式Webサイトは、マウススクロールイベントの浸透の影響をどのように達成していますか?
Apr 30, 2025 pm 03:21 PM
マウススクロールイベントの浸透の効果を実現する方法は? Webを閲覧すると、いくつかの特別なインタラクションデザインに遭遇することがよくあります。たとえば、DeepSeekの公式ウェブサイトでは、...
