

ChatGPT については誰もが聞いたことがあるでしょう。テクノロジー業界から注目を集めただけでなく、幅広いメディアでも話題になりました。
ChatGPT は、単純なタスクにおけるパフォーマンスと信頼性についてのいくつかの批判にもかかわらず、他の大規模言語モデル (LLM) と比較してさまざまなタスクで優れたパフォーマンスを発揮し、生産性を高める重要な原動力となっています。
ChatGPT を適用して Pandas データをクリーンアップおよび分析すると、作業効率が大幅に向上します。この記事では、ChatGPT を要求して Pandas タスクを完了する方法を説明する 8 つのプロンプトの例を紹介します。
役割を決定する最初のヒント:
ヒント: あなたは、Pandas ライブラリのチューターの使用方法を私に教えてくれた Python です。 。 Pandas を使用して特定のタスクを実行する方法を説明していただけることを楽しみにしています。また、説明の中でコードを示してください。
質問を始める前に、列名やデータ型を含む DataFrame の構造について説明しました。
ヒント: まず、私が持っている DataFrame について説明します。それでは、質問を始めさせていただきます。以下は、Python 辞書形式で指定された列名とデータ型です。キーは列名を表し、値はデータ型を表します。
{'ストア': dtype('O')、'product_group': dtype('O')、'product_code': dtype('int64')、'stock_qty': dtype(' int64')、'cost': dtype('float64')、'price': dtype('float64')、'last_week_sales': dtype('int64')、'last_month_sales': dtype('int64')}
ここでは、シミュレーション データから作成されたサンプル データ セットが使用されます。データセット リポジトリ リポジトリ (https://github.com/SonerYldrm/datasets) からダウンロードできます。ファイルの名前は sales_data_with_stores.csv です。
以下は参考のために提供されている DataFrame です:
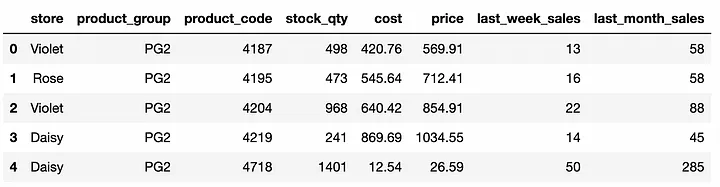
DataFrame の最初の 5 行
これで開始できます。 Pandas に取り組んでいます ミッションは完了しました。
ヒント: 各店舗の先週の売上の平均を計算する方法を教えてください。
これは単純なコード行ですが、Pandas を学び始めたばかりの人にとっては、理解するのに時間がかかるかもしれません。以下は ChatGPT によって与えられる答えです:
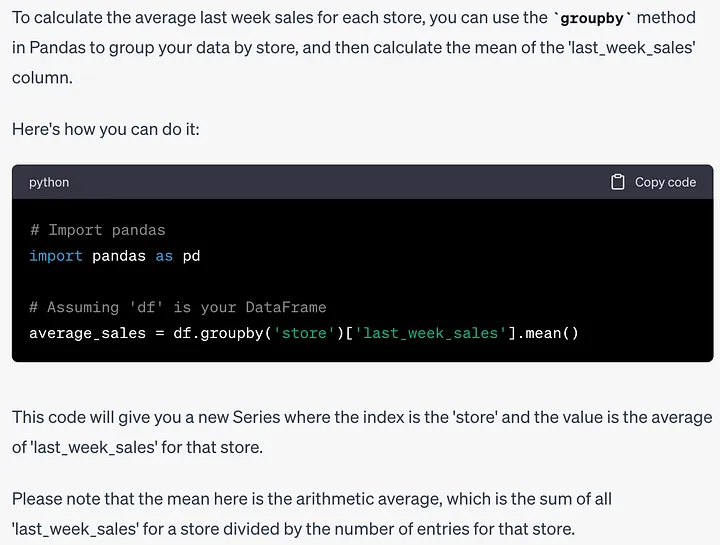
# 导入pandasimport pandas as pd# 假设'df'是你的DataFrameaverage_sales = df.groupby('store')['last_week_sales'].mean()ヒント: 先月の各店舗の利益の合計を確認する方法を教えてください。このタスクでは、ChatGPT はまず利益の計算方法を理解する必要があります。その応答を見てみましょう:
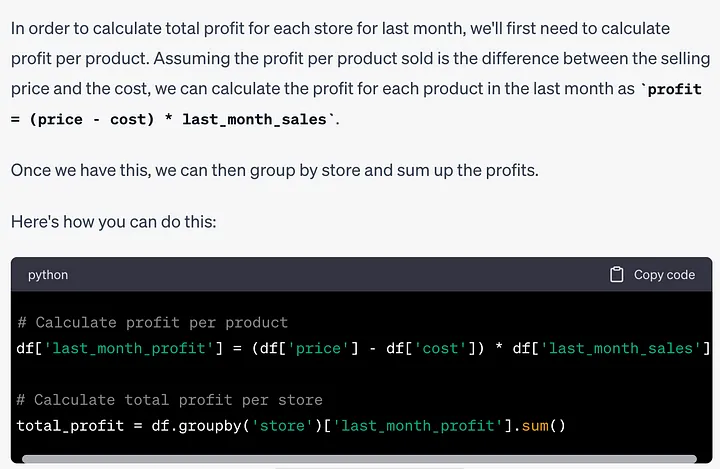
# 计算每个产品的利润df['last_month_profit'] = (df['price'] - df['cost']) * df['last_month_sales']# 计算每个商店的总利润total_profit = df.groupby('store')['last_month_profit'].sum()ヒント: 在庫数量列には欠落している値がいくつかあります。欠損値をその店舗の平均在庫数量に置き換えたいと考えています。このタスクを達成する方法を教えてください。
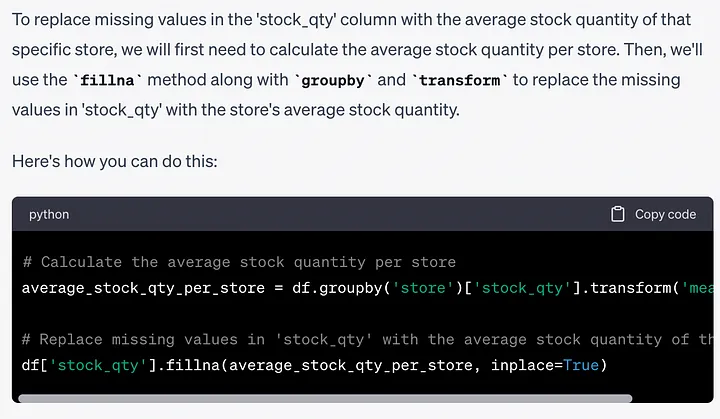
# 计算每个商店的平均库存数量average_stock_qty_per_store = df.groupby('store')['stock_qty'].transform('mean')# 用该商店的平均库存数量替换'stock_qty'中的缺失值df['stock_qty'].fillna(average_stock_qty_per_store, inplace=True)プロンプト: 先月、各店舗で最も販売量が多かった上位 3 つの製品を見つける方法を教えてください。
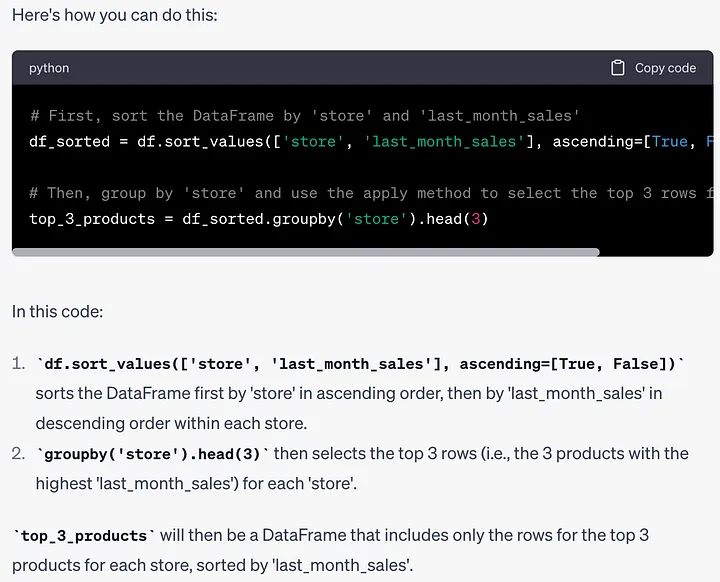
# 首先,按'store'和'last_month_sales'对DataFrame进行排序df_sorted = df.sort_values(['store', 'last_month_sales'], ascending=[True, False])# 然后,按'store'分组,并使用apply方法选择每个组的前3行top_3_products = df_sorted.groupby('store').head(3)它首先对整个DataFrame进行排序。我们也可以在每个组内进行排序。让我们看看ChatGPT是否知道该如何做到这一点。
提示:是否有另一种方法可以在不先对DataFrame进行排序的情况下完成此任务?
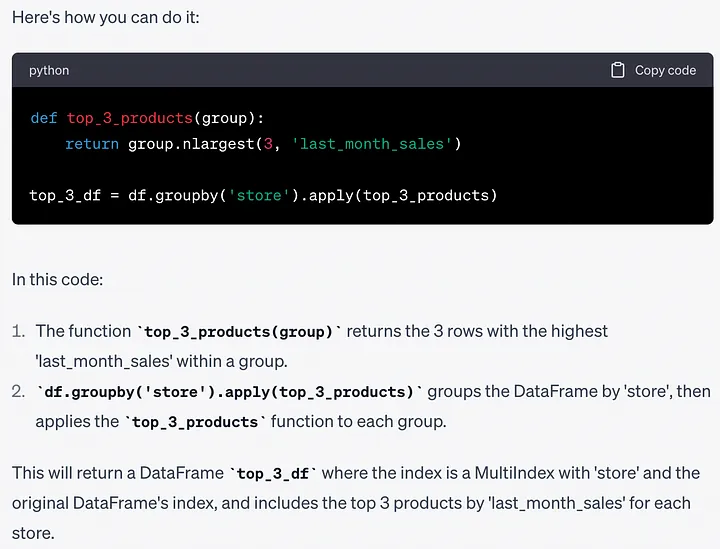
def top_3_products(group):return group.nlargest(3, 'last_month_sales')top_3_df = df.groupby('store').apply(top_3_products)更高效的方法可能是首先对整个DataFrame进行排序。此示例只是想观察ChatGPT是否能提供不同的解决方案。
提示:我想看到每个商店的上周表现与上月表现进行比较。
这是一个简单的任务,但提示并没有直接告诉ChatGPT如何完成。让我们看看它的表现如何。
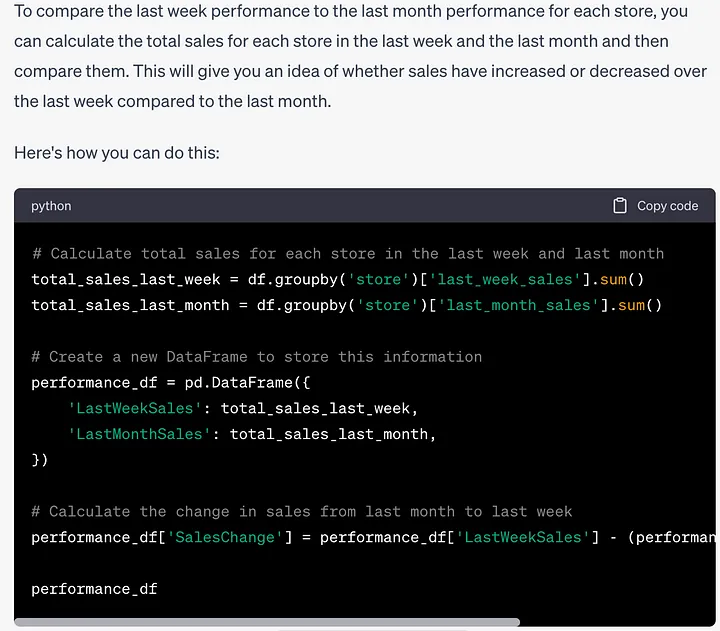
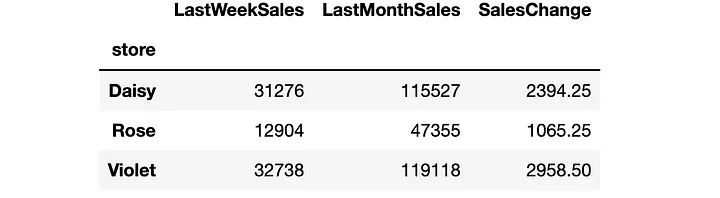
# 计算上周和上个月每个店的总销售额total_sales_last_week = df.groupby('store')['last_week_sales'].sum()total_sales_last_month = df.groupby('store')['last_month_sales'].sum()# 创建一个新的DataFrame来存储这些信息performance_df = pd.DataFrame({'LastWeekSales': total_sales_last_week,'LastMonthSales': total_sales_last_month,})# 计算从上个月到上周销售额的变化performance_df['SalesChange'] = performance_df['LastWeekSales'] - (performance_df['LastMonthSales'] / 4)作为对上周与上月的表现相比较的反应,它找到了上周销售额与上月销售额四分之一之间存在差异,这是非常合理的。
它创建的DataFrame如下所示:
提示:创建一个名为critical_stock的新列,如果stock_qty小于500,则取值为1,否则取值为0。
ChatGPT为这个任务给出了3个选项,以下是我更喜欢的两个:
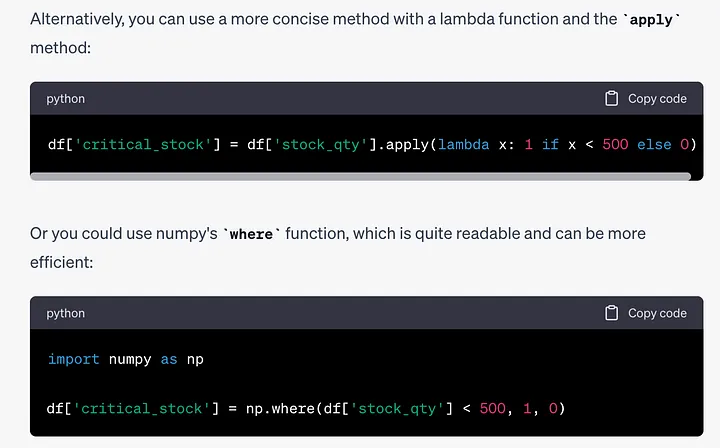
# 第一种选项df['critical_stock'] = df['stock_qty'].apply(lambda x: 1 if x <h2>示例 8</h2><blockquote style="margin-top: 5px; margin-bottom: 5px; padding-left: 1em; margin-left: 0px; border-left: 3px solid rgb(238, 238, 238); opacity: 0.6;"><p>提示:以大小、缺失值、数据类型和列统计信息的形式创建一个DataFrame的摘要。</p></blockquote><p>虽然DataFrame的函数和方法总结起来很简单,但ChatGPT在整理它们时做得非常出色,呈现出整洁清晰的排版。</p><p>如下的是ChatGPT生成的代码:</p><pre class="brush:php;toolbar:false"># 导入必要的库import pandas as pd# DataFrame大小print("DataFrame Size:")print(df.shape)print("\n")# 缺失值print("Missing Values:")print(df.isnull().sum())print("\n")# 数据类型print("Data Types:")print(df.dtypes)print("\n")# 列统计信息print("Column Statistics:")print(df.describe(include='all'))以上示例展示了ChatGPT如何在数据分析中,尤其是在Pandas中,革命性地改变了常见任务的完成方式。我们不仅提高了效率,还对可以在Pandas中完成的复杂操作有了更丰富的理解。
以上がこれら 8 つの ChatGPT 命令を上手に活用して、Pandas タスクを効率的に完了してください。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



