

中国語モデルラッシュテスト:SenseTime、Shanghai AI Labなどが新リリース「Scholar・Puyu」

マシンの心臓部のリリース
ハートオブマシン編集部
今日、毎年恒例の大学入学試験が正式に始まりました。
例年とは異なり、全国の受験者が試験室に殺到したとき、いくつかの大規模な言語モデルもこのコンテストで特別な役割を果たしました。
AI の大型言語モデルが人間に近い知能を実証することが増えているため、言語モデルの知能レベルを評価するために、人間向けに設計された高難度で包括的な試験がますます導入されています。
例えば、GPT-4の技術レポートでは、OpenAIは主にさまざまな分野の試験を通じてモデルの能力をテストしていますが、GPT-4が示す優れた「受験能力」も予想外です。
中国語モデルチャレンジ大学入学試験レポートの結果はどうなりましたか? ChatGPTに追いつくことができるでしょうか? 「候補者」のパフォーマンスを見てみましょう。
包括的な「大きな試験」: 「Scholar・Puyu」の複数の結果が ChatGPT を上回っています
最近、SenseTimeと上海AI研究所は、香港中文大学、復旦大学、上海交通大学と協力して、1000億レベルのパラメータの大規模言語モデル「Scholar Puyu」(InternLM)をリリースした。
「Scholar·Puyu」には 1,040 億のパラメータがあり、1 兆 6,000 億のトークンを含む多言語の高品質データセットでトレーニングされています。 総合的な評価の結果、「学者プユ」は知識習得、読解、数的推論、多言語翻訳などの複数の試験課題で優れた成績を収めただけでなく、総合的な能力も高いことがわかり、非常に成功しました。総合試験で優秀な成績を収めており、中国語大学入学試験の各科目のデータセット(GaoKao)をはじめ、多くの中国語試験で優れた成績を収めており、ChatGPTを超える成績を収めています。
「Scholar・Puyu」合同チームは、世界で最も影響力のある
4 つの包括的な試験評価セット: を含む 20 以上の評価を選択してテストしました。
カリフォルニア大学バークレー校およびその他の大学によって構築されたマルチタスク テスト評価セット MMLU;- AGIEval、Microsoft Research が開始した科目試験評価セット (中国の大学入学試験、司法試験、米国の SAT、LSAT、GRE、GMAT などを含む);
- C-Eval、上海交通大学、清華大学、エディンバラ大学が共同で構築した中国語モデルの包括的な試験評価セット;
- および Gaokao (復旦大学の研究チームが作成した大学入試問題集);
- 研究室合同チームが「Scholar Puyu」、GLM-130B、LLaMA-65B、ChatGPT、GPT-4の総合テストを実施し、上記4つの評価セットの結果を以下のように比較しました(100点満点) 。
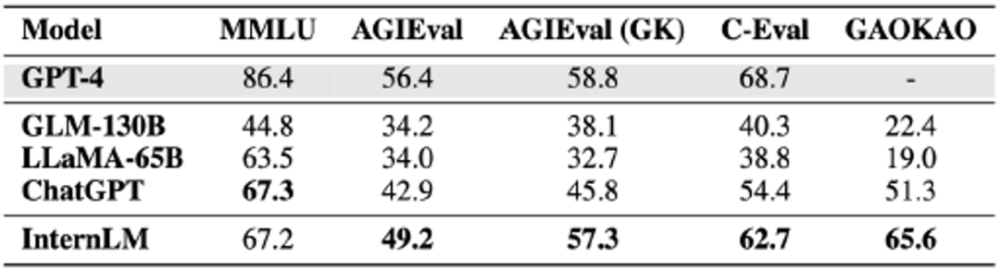 「Scholar Puyu」は、GLM-130B や LLaMA-65B などの学術オープンソース モデルを大幅に上回っているだけでなく、AGIEval、C-Eval、Gaokao などの複数の包括的な試験で ChatGPT をリードしています。 main MMLU は ChatGPT と同じレベルを達成します。これらの総合的な試験の結果は、「Scholar Puyu」の確かな知識と優れた総合力を反映しています。
「Scholar Puyu」は、GLM-130B や LLaMA-65B などの学術オープンソース モデルを大幅に上回っているだけでなく、AGIEval、C-Eval、Gaokao などの複数の包括的な試験で ChatGPT をリードしています。 main MMLU は ChatGPT と同じレベルを達成します。これらの総合的な試験の結果は、「Scholar Puyu」の確かな知識と優れた総合力を反映しています。
「Scholar・Puyu」は試験評価で優れた成績を収めましたが、大規模な言語モデルにはまだ多くの制限があることも評価からわかります。 「Scholar Puyu」はコンテキスト ウィンドウの長さが 2K に制限されており (GPT-4 のコンテキスト ウィンドウの長さは 32K)、長いテキストの理解、複雑な推論、コードの記述、および数理論理学の演繹には明らかな制限があります。さらに、実際の会話では、大規模な言語モデルには依然として錯覚や概念的な混乱などの共通の問題が存在します。これらの制限により、オープン シナリオで大規模な言語モデルを使用するには、まだ長い道のりがあります。
4 つの包括的な試験評価データセットの結果MMLU は、カリフォルニア大学バークレー校 (UC バークレー)、コロンビア大学、シカゴ大学、UIUC が共同で構築したマルチタスクのテスト評価セットで、初等数学、物理学、化学、コンピューター サイエンス、米国史をカバーしています。 、法律、経済、外交、その他多くの分野。 細分化されたアカウントの結果は次の表に示されています。
図の太字は最良の結果を示し、下線は 2 番目の結果を示します
AGIEval は、Microsoft Research が今年提案した新しい科目試験評価セットで、主な目的は、指向性試験を通じて言語モデルの能力を評価し、それによってモデルの知能と人間の知能の比較を実現することです。
この評価セットは、中国の大学入学試験、司法試験、米国のSAT、LSAT、GRE、GMATなどの重要な試験を含む、中国と米国のさまざまな試験に基づいた19の評価項目で構成されています。これら 19 専攻のうち 9 専攻は中国の大学入学試験からのものであり、通常、重要な評価サブセット AGIEval (GK) としてリストされていることに言及する価値があります。
次の表でGKの付いた科目は中国語の大学入試科目です。
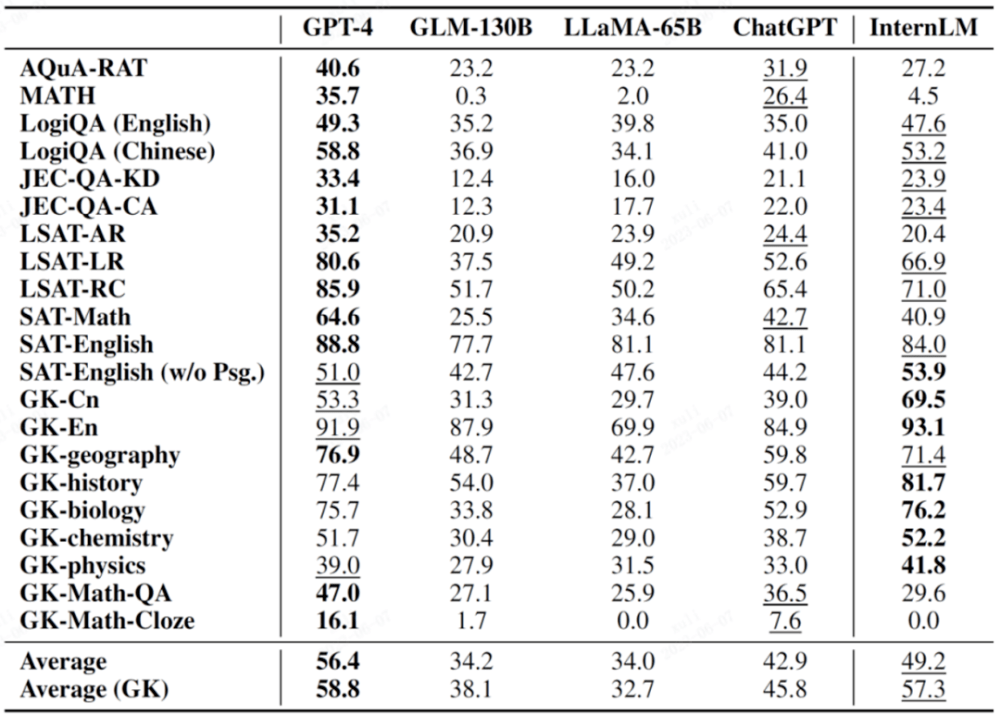
図の太字は最良の結果を示し、下線は 2 番目の結果を示します
C-Eval は、上海交通大学、清華大学、エディンバラ大学が共同で構築した中国語モデルの包括的な試験評価セットです。
数学、物理、化学、生物学、歴史、政治、コンピュータなどの科目試験から、公務員、公認会計士、弁護士、医師などの専門試験まで、52科目約14,000問の試験問題を収録しています。
テスト結果はリーダーボードから取得できます。
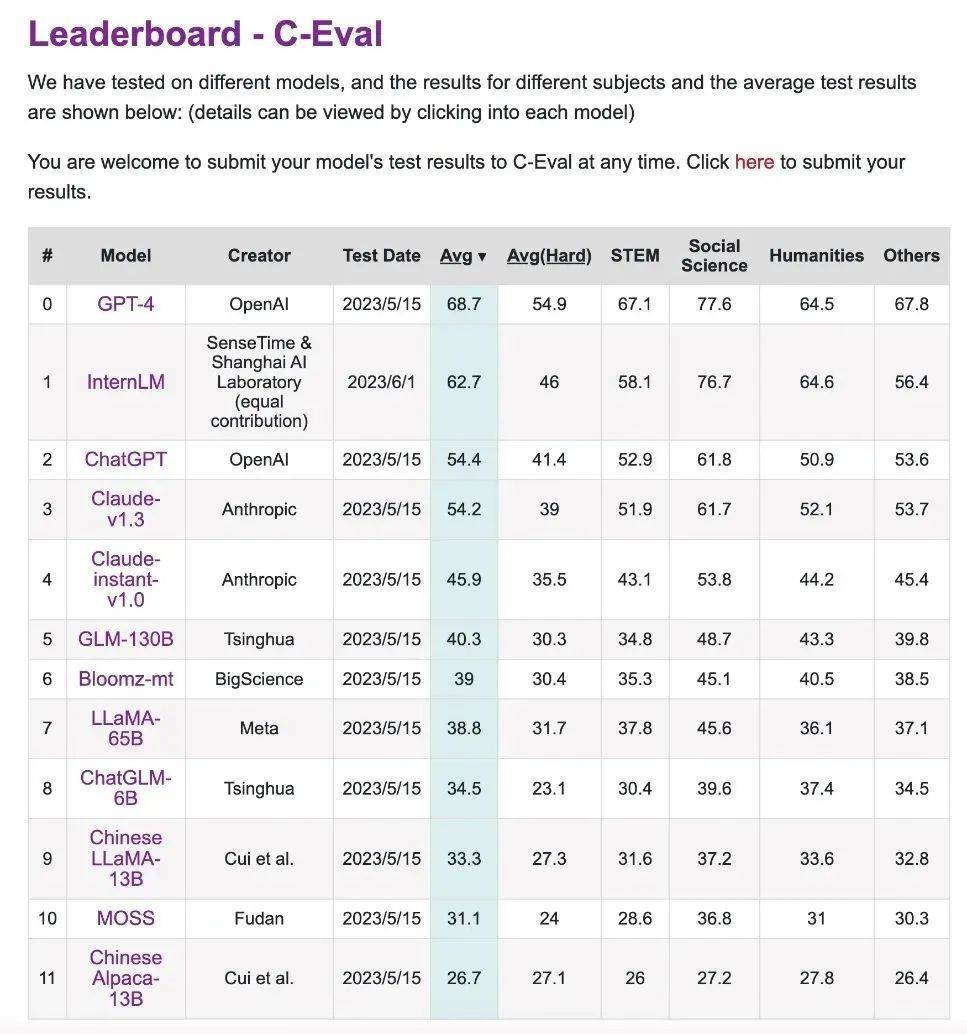
こちらのリンクはCEVA評価コンテストのランキング一覧です
Gaokao は、復旦大学の研究チームが作成した中国大学入学試験問題に基づいた包括的な試験評価セットで、中国大学入学試験のさまざまな科目と、次のような複数の問題タイプが含まれています。多肢選択問題、穴埋め問題、一問一答形式の質問です。
GaoKao の評価では、プロジェクトの 75% 以上で「Scholar・Puyu」が ChatGPT をリードしています。
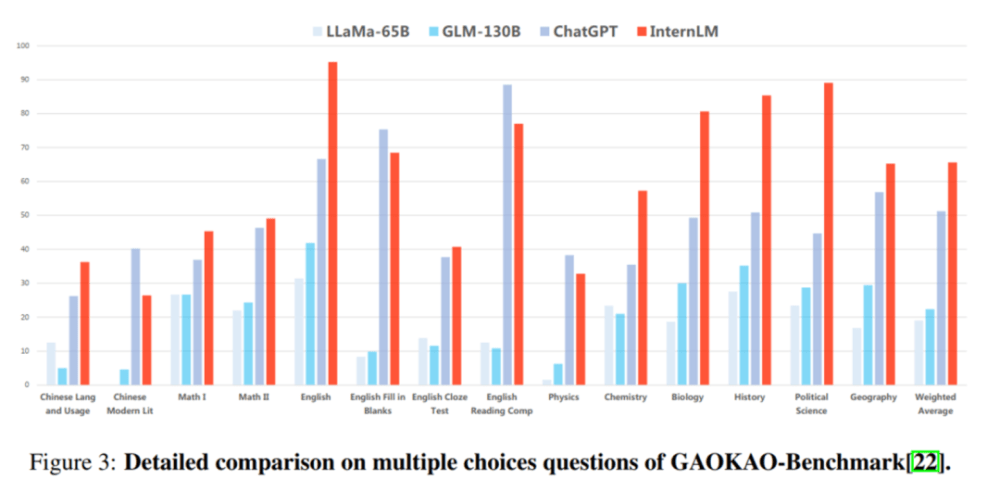
副評価:読解力・推論能力に優れる
「偏り」を避けるために、研究者らはまた、「Scholar Puyu」などの言語モデルの下位項目の能力を、複数の学術評価セットを通じて評価および比較しました。
その結果、「Scholar Puyu」は中国語と英語の読解力に優れているだけでなく、数的推理、プログラミング能力などの評価でも良好な成績を収めていることがわかりました。
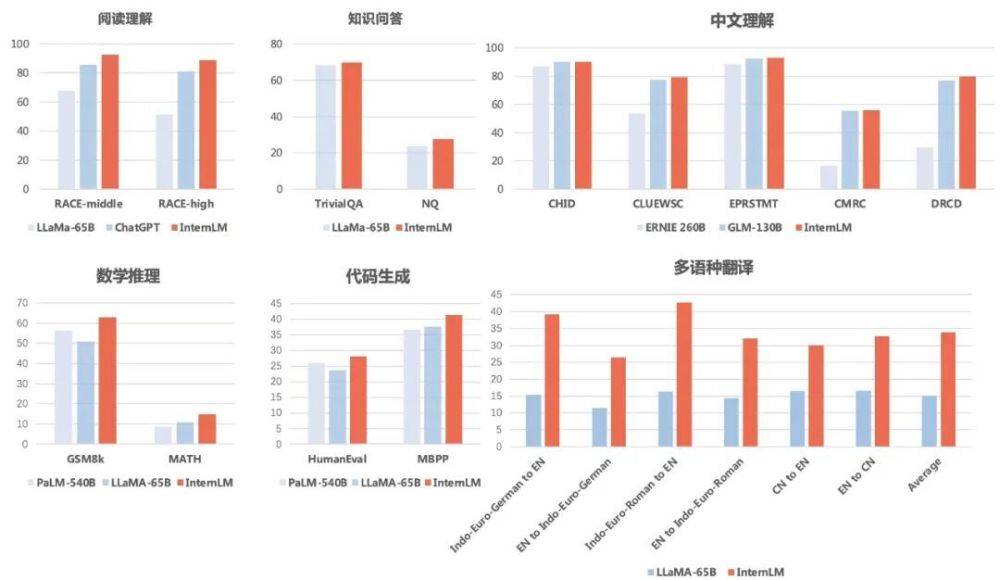
知識の質問と回答の点では、「Scholar Puyu」は TriviaQA と NaturalQuestions で 69.8 点と 27.6 点を獲得し、どちらも LLaMA-65B (68.2 点と 23.8 点) を上回りました。
読解力(英語)という点では、「Scholar・Puyu」はLLaMA-65BやChatGPTよりも明らかに優れています。 Puyu の中学と高校の英語読解では 92.7 点と 88.9 点、ChatGPT では 85.6 点と 81.2 点、LLaMA-65B ではさらに低かった。
中国語理解の点で「Scholar Puyu」の結果は、中国語主要2モデルERNIE-260BとGLM-130Bを総合的に上回りました。
多言語翻訳に関しては、「Scholar・Puyu」の多言語翻訳の平均スコアは33.9で、LLaMA(平均スコア15.1)を大きく上回りました。
数学的推論の点では、「Scholar Puyu」は、評価に広く使用されている 2 つの数学テストである GSM8K と MATH でそれぞれ 62.9 点と 14.9 点を獲得し、Google の PaLM を大幅に上回りました。 -540B (スコア 56.5 と 8.8) )およびLLaMA-65B(スコア50.9および10.9)。
プログラミング能力の観点から見て、「Scholar Puyu」は、HumanEval と MBPP という 2 つの最も代表的な評価で、それぞれ 28.1 と 41.4 のスコアを獲得しました (コーディング分野で微調整した後、HumanEval のスコアは45.7に改善)、PaLM-540B(スコア26.2および36.8)およびLLaMA-65B(スコア23.7および37.7)を大幅に上回りました。 さらに、研究者らは「Scholar Puyu」の安全性についても評価しました。TruthfulQA (主に回答の事実の正確性を評価) と CrowS-Pairs (主に回答にバイアスが含まれているかどうかを評価) について、「Scholar Puyu」の言語一流のレベルに達しました。
以上が中国語モデルラッシュテスト:SenseTime、Shanghai AI Labなどが新リリース「Scholar・Puyu」の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1657
1657
 14
1415
52
1309
25
1257
29
1230
24
14
1415
52
1309
25
1257
29
1230
24

 Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
メタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 10生成AIコーディング拡張機能とコードのコードを探る必要があります
Apr 13, 2025 am 01:14 AM
10生成AIコーディング拡張機能とコードのコードを探る必要があります
Apr 13, 2025 am 01:14 AM
ねえ、忍者をコーディング!その日はどのようなコーディング関連のタスクを計画していますか?このブログにさらに飛び込む前に、コーディング関連のすべての問題について考えてほしいです。 終わり? - &#8217を見てみましょう
 AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
今週のAIの風景:進歩、倫理的考慮、規制の議論の旋風。 Openai、Google、Meta、Microsoftのような主要なプレーヤーは、画期的な新しいモデルからLEの重要な変化まで、アップデートの急流を解き放ちました
 従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
Shopify CEOのTobiLütkeの最近のメモは、AIの能力がすべての従業員にとって基本的な期待であると大胆に宣言し、会社内の重大な文化的変化を示しています。 これはつかの間の傾向ではありません。これは、pに統合された新しい運用パラダイムです
 ビジョン言語モデル(VLM)の包括的なガイド
Apr 12, 2025 am 11:58 AM
ビジョン言語モデル(VLM)の包括的なガイド
Apr 12, 2025 am 11:58 AM
導入 鮮やかな絵画や彫刻に囲まれたアートギャラリーを歩くことを想像してください。さて、各ピースに質問をして意味のある答えを得ることができたらどうでしょうか?あなたは尋ねるかもしれません、「あなたはどんな話を言っていますか?
 GPT-4o vs Openai O1:新しいOpenaiモデルは誇大広告に値しますか?
Apr 13, 2025 am 10:18 AM
GPT-4o vs Openai O1:新しいOpenaiモデルは誇大広告に値しますか?
Apr 13, 2025 am 10:18 AM
導入 Openaiは、待望の「Strawberry」アーキテクチャに基づいて新しいモデルをリリースしました。 O1として知られるこの革新的なモデルは、推論能力を強化し、問題を通じて考えられるようになりました
 SQLに列を追加する方法は? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQLに列を追加する方法は? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQLの変更テーブルステートメント:データベースに列を動的に追加する データ管理では、SQLの適応性が重要です。 その場でデータベース構造を調整する必要がありますか? Alter Tableステートメントはあなたの解決策です。このガイドの詳細は、コルを追加します
 最高の迅速なエンジニアリング技術の最新の年次編集
Apr 10, 2025 am 11:22 AM
最高の迅速なエンジニアリング技術の最新の年次編集
Apr 10, 2025 am 11:22 AM
私のコラムに新しいかもしれない人のために、具体化されたAI、AI推論、AIのハイテクブレークスルー、AIの迅速なエンジニアリング、AIのトレーニング、AIのフィールディングなどのトピックなど、全面的なAIの最新の進歩を広く探求します。
