
 テクノロジー周辺機器
AI
OpenAIが上位2位を独占!大規模モデルのコード生成ランキング リストが公開され、70 億 LLaMA がそれを上回り、2 億 5,000 万の Codex に敗れました。
テクノロジー周辺機器
AI
OpenAIが上位2位を独占!大規模モデルのコード生成ランキング リストが公開され、70 億 LLaMA がそれを上回り、2 億 5,000 万の Codex に敗れました。
OpenAIが上位2位を独占!大規模モデルのコード生成ランキング リストが公開され、70 億 LLaMA がそれを上回り、2 億 5,000 万の Codex に敗れました。

最近、Matthias Prappert 氏のツイートが LLM サークル内で広範な議論を引き起こしました。
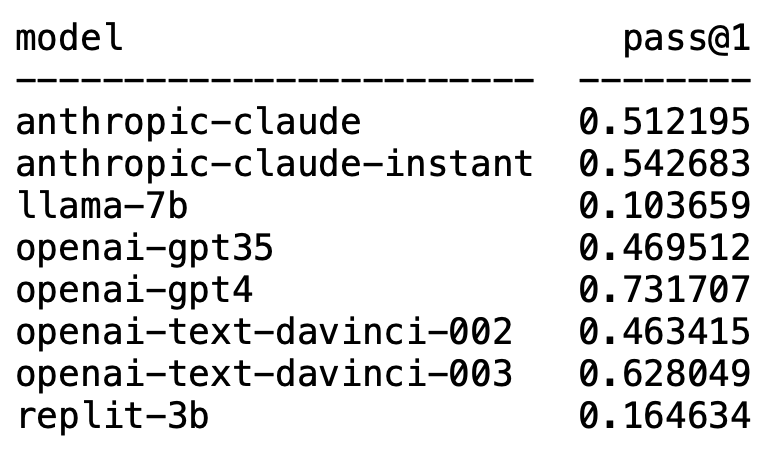
Plappert は著名なコンピューター科学者であり、AI 界隈で主流の LLM に関するベンチマーク テストの結果を HumanEval で公開しました。 。
彼のテストはコード生成に偏っています。
結果は衝撃的で衝撃的でもあります。

予想外なことに、GPT-4 は間違いなくリストを独占し、1 位になりました。
意外なことに、OpenAI の text-davinci-003 が突然浮上し、2 位になりました。
Plappert 氏は、text-davinci-003 は「宝」モデルと呼ぶことができると述べました。
おなじみの LLaMA はコード生成が苦手です。
OpenAI がリストを独占
Plappert 氏は、GPT-4 のパフォーマンスは文献データよりもさらに優れていると述べました。
論文にある GPT-4 ラウンドのテスト データの合格率は 67% ですが、Prappert のテストは 73% に達しました。

原因を分析すると、データに不一致が生じる可能性が多くあるとのこと。その 1 つは、彼が GPT-4 に与えたプロンプトが、論文の著者が GPT-4 をテストしたときよりもわずかに優れていたことです。
もう 1 つの理由は、論文が GPT-4 をテストしたときにモデルの温度が 0 ではないと推測したことです。
「温度」は、モデルによって生成されるテキストの創造性と多様性を調整するために使用されるパラメーターです。 「温度」は 0 より大きい値で、通常は 0 ~ 1 の間です。モデルがテキストを生成するときに、サンプリングされた予測単語の確率分布に影響します。
モデルの「温度」が高い場合 (0.8、1 以上など)、モデルはより多様で異なる単語から選択する傾向が高くなります。生成されたテキストはリスクが高く、より創造的ですが、より多くのエラーや矛盾が生じる可能性もあります。
「温度」が低い場合 (0.2、0.3 など)、モデルは主に確率の高い単語から選択するため、より滑らかで一貫性のあるテキストが生成されます。
ただし、この時点では、生成されたテキストは保守的で繰り返しが多すぎるように見えるかもしれません。
したがって、実際のアプリケーションでは、特定のニーズに基づいて適切な「温度」値を比較検討して選択する必要があります。
次に、text-davinci-003 についてコメントしたときに、Prappert 氏は、これも OpenAI の下で非常に有能なモデルであると述べました。
GPT-4 ほどではありませんが、1 回のテストで 62% の合格率を達成すれば、それでも確実に 2 位を獲得できます。
Plappert 氏は、text-davinci-003 の最も優れた点は、ユーザーが ChatGPT の API を使用する必要がないことであると強調しました。これは、プロンプトの表示がより簡単になることを意味します。
さらに、プラパート氏は、Anthropic AI のクロードインスタント モデルにも比較的高い評価を与えました。
彼は、このモデルのパフォーマンスは優れており、GPT-3.5 を上回ることができると信じています。 GPT-3.5 の合格率は 46% ですが、claude-instant の合格率は 54% です。
もちろん、Anthropic AI のもう 1 つの LLM、claude は、claude-instant ではプレイできず、合格率はわずか 51% です。
Plappert 氏は、2 つのモデルのテストに使用されたプロンプトは同じであると述べました。
これらのよく知られたモデルに加えて、Prappert は多くのオープンソースの小規模モデルもテストしました。
Plappert 氏は、これらのモデルをローカルで実行できるのは良いことだと言いました。
ただし、規模の点で、これらのモデルは明らかに OpenAI や Anthropic AI ほど大きくないため、比較するのは少々圧倒されます。

LLaMA コード生成?腰を引っ張る
# もちろん、プラパート氏は LLaMA テストの結果に満足していませんでした。
テスト結果から判断すると、LLaMA はコード生成のパフォーマンスが非常に悪かったです。おそらく、GitHub からデータを収集するときにアンダーサンプリングを使用したためです。
Codex 2.5B と比較しても、LLaMA のパフォーマンスは同じではありません。 (合格率 10% 対 22%)

最後に、Replit の 3B サイズ モデルをテストしました。
パフォーマンスは悪くなかったが、Twitter で宣伝されたデータと比較すると (合格率 16% 対 22%)
Plappert 氏は、これはモデルをテストするときに使用した定量化手法によって合格率が数パーセント低下したためではないかと考えています。
レビューの最後で、プラパート氏は非常に興味深い点について言及しました。
あるユーザーが Twitter で、Azure プラットフォームの Completion API (Chat API ではなく) を使用すると GPT-3.5-turbo のパフォーマンスが向上することを発見しました。
Plappert 氏は、Chat API を介してプロンプトを入力するのは非常に複雑な場合があるため、この現象にはある程度の正当性があると考えています。

以上がOpenAIが上位2位を独占!大規模モデルのコード生成ランキング リストが公開され、70 億 LLaMA がそれを上回り、2 億 5,000 万の Codex に敗れました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7651
7651
 15
1392
52
91
11
36
110
15
1392
52
91
11
36
110

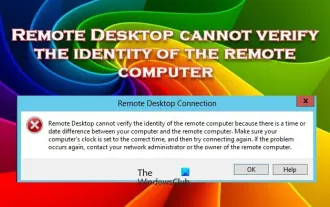 リモート デスクトップがリモート コンピュータの ID を認証できない
Feb 29, 2024 pm 12:30 PM
リモート デスクトップがリモート コンピュータの ID を認証できない
Feb 29, 2024 pm 12:30 PM
Windows リモート デスクトップ サービスを使用すると、ユーザーはコンピュータにリモート アクセスできるため、リモートで作業する必要がある人にとっては非常に便利です。ただし、ユーザーがリモート コンピュータに接続できない場合、またはリモート デスクトップがコンピュータの ID を認証できない場合、問題が発生する可能性があります。これは、ネットワーク接続の問題または証明書の検証の失敗が原因である可能性があります。この場合、ユーザーはネットワーク接続をチェックし、リモート コンピュータがオンラインであることを確認して、再接続を試行する必要がある場合があります。また、リモート コンピュータの認証オプションが正しく構成されていることを確認することが、問題を解決する鍵となります。 Windows リモート デスクトップ サービスに関するこのような問題は、通常、設定を注意深く確認して調整することで解決できます。時間または日付の違いにより、リモート デスクトップはリモート コンピューターの ID を確認できません。計算を確認してください
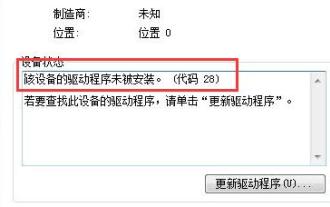 win7ドライバーコード28を解決する方法
Dec 30, 2023 pm 11:55 PM
win7ドライバーコード28を解決する方法
Dec 30, 2023 pm 11:55 PM
一部のユーザーは、デバイスのインストール時にエラー コード 28 を表示するエラーに遭遇しました。実際、これは主にドライバーが原因です。Win7 ドライバー コード 28 の問題を解決するだけで済みます。何をすべきかを見てみましょう。それ。 win7 ドライバー コード 28 で何をするか: まず、画面の左下隅にあるスタート メニューをクリックする必要があります。次に、ポップアップメニューで「コントロールパネル」オプションを見つけてクリックします。このオプションは通常、メニューの下部またはその近くにあります。クリックすると、システムは自動的にコントロール パネル インターフェイスを開きます。コントロールパネルでは、システムの各種設定や管理操作を行うことができます。これはノスタルジックな掃除レベルの最初のステップです。お役に立てば幸いです。次に、続行してシステムに入り、
 2024 CSRankings 全国コンピュータ サイエンス ランキングが発表されました! CMUがリストを独占、MITはトップ5から外れる
Mar 25, 2024 pm 06:01 PM
2024 CSRankings 全国コンピュータ サイエンス ランキングが発表されました! CMUがリストを独占、MITはトップ5から外れる
Mar 25, 2024 pm 06:01 PM
2024CSRankings 全国コンピューターサイエンス専攻ランキングが発表されました。今年、米国の最高のCS大学のランキングで、カーネギーメロン大学(CMU)が国内およびCSの分野で最高の大学の一つにランクされ、イリノイ大学アーバナシャンペーン校(UIUC)は6年連続2位となった。 3位はジョージア工科大学。次いでスタンフォード大学、カリフォルニア大学サンディエゴ校、ミシガン大学、ワシントン大学が世界第4位タイとなった。 MIT のランキングが低下し、トップ 5 から外れたことは注目に値します。 CSRankings は、マサチューセッツ大学アマースト校コンピューター情報科学部のエメリー バーガー教授が始めたコンピューター サイエンス分野の世界的な大学ランキング プロジェクトです。ランキングは客観的なものに基づいています
 ブルースクリーンコード0x0000001が発生した場合の対処方法
Feb 23, 2024 am 08:09 AM
ブルースクリーンコード0x0000001が発生した場合の対処方法
Feb 23, 2024 am 08:09 AM
ブルー スクリーン コード 0x0000001 の対処法。ブルー スクリーン エラーは、コンピューター システムまたはハードウェアに問題がある場合の警告メカニズムです。コード 0x0000001 は、通常、ハードウェアまたはドライバーの障害を示します。ユーザーは、コンピュータの使用中に突然ブルー スクリーン エラーに遭遇すると、パニックになり途方に暮れるかもしれません。幸いなことに、ほとんどのブルー スクリーン エラーは、いくつかの簡単な手順でトラブルシューティングして対処できます。この記事では、ブルー スクリーン エラー コード 0x0000001 を解決するいくつかの方法を読者に紹介します。まず、ブルー スクリーン エラーが発生した場合は、再起動を試みることができます。
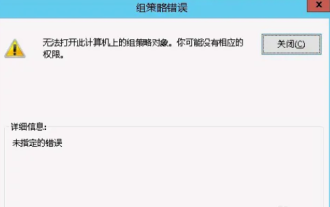 このコンピュータではグループ ポリシー オブジェクトを開けません
Feb 07, 2024 pm 02:00 PM
このコンピュータではグループ ポリシー オブジェクトを開けません
Feb 07, 2024 pm 02:00 PM
コンピュータを使用しているときに、オペレーティング システムが誤動作することがあります。今日私が遭遇した問題は、gpedit.msc にアクセスすると、正しいアクセス許可がない可能性があるためグループ ポリシー オブジェクトを開けないというメッセージがシステムから表示されることでした。このコンピュータ上のグループ ポリシー オブジェクトを開けませんでした。解決策: 1. gpedit.msc にアクセスすると、アクセス許可がないため、このコンピュータ上のグループ ポリシー オブジェクトを開けないというメッセージが表示されます。詳細: システムは指定されたパスを見つけることができません。 2. ユーザーが閉じるボタンをクリックすると、次のエラー ウィンドウがポップアップ表示されます。 3. ログ レコードをすぐに確認し、記録された情報を組み合わせて、問題が C:\Windows\System32\GroupPolicy\Machine\registry.pol ファイルにあることを確認します。
 コンピューターが頻繁にブルー スクリーンになり、コードが毎回異なります
Jan 06, 2024 pm 10:53 PM
コンピューターが頻繁にブルー スクリーンになり、コードが毎回異なります
Jan 06, 2024 pm 10:53 PM
win10 システムは非常に優れた高インテリジェンス システムであり、その強力なインテリジェンスはユーザーに最高のユーザー エクスペリエンスをもたらすことができ、通常の状況では、ユーザーの win10 システム コンピューターに問題はありません。しかし、優れたコンピューターにはさまざまな障害が発生するのは避けられず、最近、友人が win10 システムで頻繁にブルー スクリーンが発生したと報告しています。今日、エディターは、Windows 10 コンピューターで頻繁にブルー スクリーンを引き起こすさまざまなコードに対する解決策を提供します。毎回異なるコードが表示される頻繁なコンピューターのブルー スクリーンの解決策: さまざまな障害コードの原因と解決策の提案 1. 0×000000116 障害の原因: グラフィック カード ドライバーに互換性がないことが考えられます。解決策: 元の製造元のドライバーを置き換えることをお勧めします。 2、
 コード0xc000007bエラーを解決する
Feb 18, 2024 pm 07:34 PM
コード0xc000007bエラーを解決する
Feb 18, 2024 pm 07:34 PM
終了コード 0xc000007b コンピューターを使用しているときに、さまざまな問題やエラー コードが発生することがあります。その中でも最も厄介なのが終了コード、特に終了コード0xc000007bです。このコードは、アプリケーションが正常に起動できず、ユーザーに迷惑がかかっていることを示しています。まずは終了コード0xc000007bの意味を理解しましょう。このコードは、32 ビット アプリケーションを 64 ビット オペレーティング システムで実行しようとしたときに通常発生する Windows オペレーティング システムのエラー コードです。それはそうすべきだという意味です
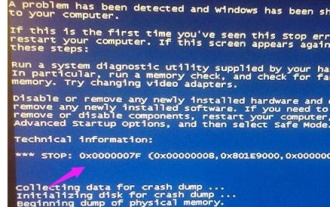 0x0000007fブルースクリーンコードの原因と解決策を詳しく解説
Dec 25, 2023 pm 02:19 PM
0x0000007fブルースクリーンコードの原因と解決策を詳しく解説
Dec 25, 2023 pm 02:19 PM
システムを使用しているときによく遭遇するブルースクリーンの問題ですが、エラーコードに応じて、さまざまな原因と解決策が異なります。たとえば、stop: 0x0000007f の問題が発生した場合、ハードウェアまたはソフトウェアのエラーである可能性があるため、エディタに従って解決策を見つけてみましょう。 0x000000c5 ブルー スクリーン コードの理由: 回答: メモリ、CPU、グラフィック カードが突然オーバークロックされているか、ソフトウェアが正しく実行されていません。解決策 1: 1. 起動時に F8 キーを押し続け、セーフ モードを選択し、Enter キーを押してに入ります。 2. セーフ モードに入ったら、win+r を押して実行ウィンドウを開き、「cmd」と入力して Enter を押します。 3. コマンド プロンプト ウィンドウで「chkdsk /f /r」と入力し、Enter キーを押して、y キーを押します。 4.
