

自動運転分野における大型モデルの応用について説明する 10,000 ワードの長い記事

ChatGPT の人気に伴い、大規模モデルがますます注目を集めており、大規模モデルが示す機能は驚くべきものです。
画像生成、推奨システム、機械翻訳などの分野で、大規模なモデルが役割を果たし始めています。簡単に言うと、画像生成 Web サイト Midjourney によって生成されたデザイン画は、多くのプロのデザイナーのレベルをも超えています。
なぜ大型モデルは驚くべき能力を発揮できるのでしょうか?モデルのパラメーターの数と容量が増加すると、モデルのパフォーマンスが向上するのはなぜですか?
AI アルゴリズム会社の専門家は著者にこう言いました: モデルのパラメーター数の増加は、モデルの次元の増加として理解できます。より複雑な方法で現実世界をシミュレートできます。最も単純なシナリオを例として考えます。平面上に散布図を作成します。直線 (1 変数関数) を使用してプロット上の散布点のパターンを記述すると、パラメータが何であっても、常に何らかの点がこの線の外側にあります。二項関数を使用してこれらの点のパターンを表すと、より多くの点がこの関数線上に当てはまります。関数の次元が増加するか、自由度が増加するにつれて、より多くの点がこの線上に収まるようになります。これは、これらの点の法則がより正確に適合することを意味します。
言い換えれば、モデルのパラメーターの数が多いほど、モデルが大規模なデータの法則に適合しやすくなります。
ChatGPT の出現により、人々はモデルのパラメーターが特定のレベルに達すると、その効果が単に「パフォーマンスが向上する」だけでなく、「期待を超えて」良い効果があることを発見しました。 。
NLP (自然言語処理) の分野では、学界や産業界が「新たな能力」の具体的な原理をまだ説明できていないという刺激的な現象が起きています。
「創発」とは何ですか? 「創発」とは、モデルのパラメータの数が一定レベルまで線形に増加すると、モデルの精度が指数関数的に増加することを意味します。
写真を見てみましょう。下の写真の左側はスケーリング則を示しています。これは、2022 年より前に OpenAI 研究者によって発見された現象です。モデル パラメーターのサイズが指数関数的に増加すると、モデルの精度は直線的に増加します。左側の図のモデル パラメーターは指数関数的に増加するのではなく、直線的に増加します。
2022 年 1 月までに、一部の研究者は、モデルのパラメーター スケールが特定のレベルを超えると、モデルの精度が低下することを発見しました。下図の右側に示すように、その度合いは明らかに比例曲線を超えています。
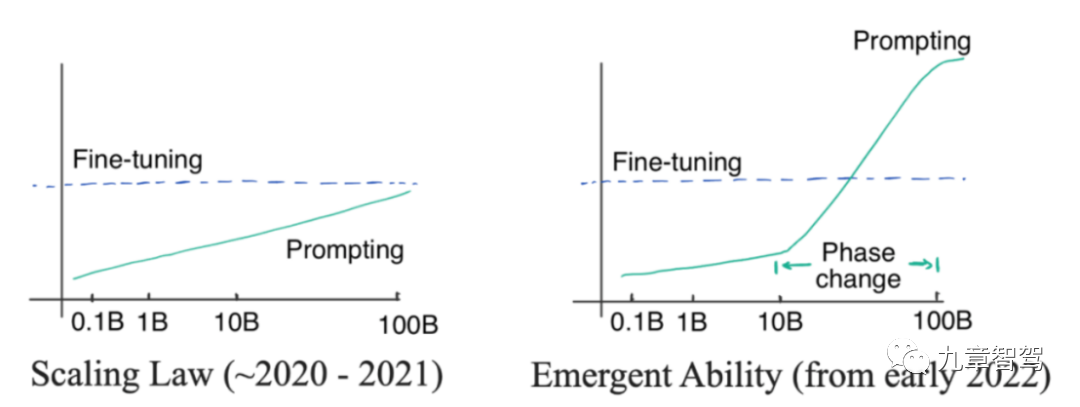
「創発」図
アプリケーション レベルに実装すると、大きなモデルは、小さなモデルでは達成できないいくつかのタスクを実行できることがわかりました。たとえば、大きなモデルでは、加算と減算、単純な推論などが実行できます。
どんなモデルを大型モデルと呼べるでしょうか?
一般的に、1 億を超えるパラメータを持つモデルを「大規模モデル」と呼ぶことができると考えられます。自動運転の分野において、大規模モデルとは主に 2 つの意味を持ち、1 億以上のパラメータを持つモデルと、複数の小さなモデルを重ね合わせて構成されるモデルです。 「大きなモデル」としてモデルとも呼ばれます。
この定義によれば、自動運転の分野では大型モデルが広く使われ始めています。クラウドでは、モデル パラメーターの数の増加によってもたらされる容量の利点を活用し、大規模なモデルを使用してデータ マイニングやデータ アノテーションなどの一部のタスクを完了できます。自動車側では、さまざまなサブタスクを担当する複数の小さなモデルを 1 つの「大きなモデル」にマージできます。これにより、自動車側の計算における推論時間を節約し、安全性を高めることができます。
具体的には、大規模なモデルはどのように活用できるのでしょうか?著者が業界の専門家と伝えた情報によると、業界では現在主に知覚の分野で大規模なモデルが使用されています。次に、大規模なモデルがクラウドと自動車側でそれぞれどのように認識タスクを可能にするかを紹介します。
01
大規模モデルのアプリケーション
1.1 クラウドでの大規模モデルのアプリケーション
1.1.1 自動データ アノテーション
自動アノテーションは、大規模なモデルの事前トレーニングを使用することで実現できます。ビデオ クリップのアノテーションを例にとると、まず大量のラベルなしクリップ データを使用して自己監視を通じて大規模なモデルを事前トレーニングし、次に手動でラベル付けされた少量のクリップ データを使用してモデルを微調整することができます。検出機能: モデルはクリップ データに自動的に注釈を付けることができます。
モデルのラベリング精度が高いほど、人の置き換えの度合いが高くなります。
現在、多くの企業が大型モデルの自動ラベル付けの精度向上を検討しており、精度が基準値に達した後は完全に無人での自動ラベル付けの実現を目指しています。
SenseTime のインテリジェント ドライビング製品担当ディレクターである Leo 氏は、著者に次のように述べています。評価を行った結果、道路上の一般的なターゲットについては、SenseTime の大型モデルの自動ラベル付けの精度が達成できることがわかりました。このようにして、その後の手動レビュー プロセスを非常に効率化できます。
インテリジェント運転製品の開発プロセスにおいて、SenseTime Jueying は、ほとんどの認識タスクに対して大規模モデルの自動事前アノテーションを導入しました。以前と比較して、同じ量のデータで、サンプル数、標識サイクル、標識コストが数十倍以上削減され、開発効率が大幅に向上します。
一般的に、アノテーション タスクに対する誰もが期待するのは、主に、アノテーション プロセスの高効率、アノテーション結果の高精度、高一貫性です。高効率、高精度というとわかりやすいですが、高一貫性とは何でしょうか? 3D 認識用の BEV アルゴリズムでは、エンジニアは LIDAR とビジョンの共同アノテーションを使用し、点群と画像データを共同で処理する必要があります。この種の処理リンクでは、前後のフレームの結果が大きく異なることがないよう、エンジニアがタイミング レベルで何らかの注釈を作成する必要がある場合もあります。
手動アノテーションを使用する場合、アノテーションの効果はアノテーターのアノテーション レベルに依存します。アノテーターのレベルが不均一であると、アノテーション結果に一貫性がなくなる可能性があり、注釈が表示されない可能性があります。 1 つの画像。フレームは大きく、次の画像は小さくなります。一般に、大きなモデルのアノテーション結果はより一貫性があります。
しかし、一部の業界専門家は、特に自動運転企業とアノテーション企業との関係において、大規模モデルを使用した自動アノテーションを実際のアプリケーションに導入するのにはいくつかの困難があると報告しています。自動運転企業はラベリング作業の一部をラベリング会社に委託することになるが、社内にラベリングチームを持たず、すべてのラベリング作業を外部委託する企業もある。
現在、大型モデルの事前アノテーション手法を使用してアノテーションが付けられているターゲットは、主に動的 3D ターゲットです。自動運転会社は、まず大型モデルを使用して、ビデオで推論を行います。アノテーションを付ける必要がある場合は、推論の結果、モデルによって生成された 3D ボックスをアノテーション会社に渡します。最初に大規模なモデルに事前アノテーションを付けてから、事前にアノテーションが付けられた結果をアノテーション会社に渡す場合、2 つの主な問題が関係します。1 つは、一部のアノテーション会社のアノテーション プラットフォームが事前にアノテーションが付けられた結果の読み込みを必ずしもサポートしていない可能性があることです。アノテーション会社は、必ずしも事前にアノテーションを付けた結果を変更することに積極的ではないということです。
アノテーション会社が事前にアノテーションが付けられた結果をロードしたい場合は、大規模なモデルによって生成された 3D フレームのロードをサポートするソフトウェア プラットフォームが必要です。ただし、一部のアノテーション会社は主に手動アノテーションを使用しており、モデルの事前アノテーション結果のロードをサポートするソフトウェア プラットフォームを持っていないため、顧客との接続時に事前アノテーション付きモデルの結果を取得しても、それを受け入れる方法がありません。
さらに、アノテーション会社の観点から見ると、アノテーション前の効果が十分に優れている場合にのみ、真に「労力を節約」できます。そうでない場合は、作業負荷が増加する可能性があります。
ラベル貼り付け前の効果が十分でない場合、ラベル貼り会社は今後も、紛失した箱にラベルを貼り付けたり、間違ってラベルが貼られた箱を削除したりするなど、多くの作業を行う必要があります。ボックスのサイズ調整、均一性などその場合、事前アノテーションを使用しても、実際には作業負荷を軽減できない可能性があります。
したがって、実際のアプリケーションでは、事前アノテーションに大規模なモデルを使用するかどうかは、自動運転会社とアノテーション会社の両方で検討する必要があります。
もちろん、現在の手動アノテーションのコストは比較的高く、アノテーション会社がゼロから始めることを許可した場合、1,000 フレームのビデオ データに対する手動アノテーションのコストは 10,000 元に達する可能性があります。したがって、自動運転企業は依然として、大型モデルの事前ラベル付けの精度を可能な限り向上させ、手動ラベル付けの作業負荷を可能な限り軽減し、それによってラベル付けコストを削減したいと考えています。
1.1.2 データ マイニング
大規模なモデルには強力な一般化があり、マイニングに適していますロングテールデータ。
WeRide の専門家は著者にこう言いました: 従来のタグベースの方法を使用してロングテール シーンをマイニングする場合、モデルは通常、既知の画像カテゴリのみを区別できます。 2021 年に、OpenAI は CLIP モデル (教師なし事前トレーニング後にテキストと画像を対応させることができるテキスト画像マルチモーダル モデル。これにより、画像のラベルだけに依存するのではなく、テキストに基づいて画像を分類できます) をリリースしました。また、このようなテキストと画像のマルチモーダル モデルを採用し、テキストの説明を使用してドライブ ログ内の画像データを取得します。たとえば、「貨物を引きずる建設車両」や「2 つの電球が同時に点灯する信号機」などのロングテール シーンです。
さらに、大規模なモデルでは、データから特徴をより適切に抽出し、類似の特徴を持つターゲットを見つけることができます。
多くの写真から衛生作業員が含まれる写真を見つけたいとします。最初に写真に特にラベルを付ける必要はありません。大量の写真を使用して大規模なモデルを事前トレーニングできます。衛生作業員を含む大規模モデルでは、衛生作業員のいくつかの特徴を抽出できます。次に、衛生作業員の特徴に一致するサンプルを写真から検出し、衛生作業員が含まれるほぼすべての写真をマイニングします。
1.1.3 知識の蒸留を使用して小さなモデルを「教える」
大きなモデル知識の蒸留を使用して小さなモデルを「教える」こともできます。
知識の蒸留とは何ですか?最も一般的な用語で説明すると、大規模モデルはまずデータから何らかの知識を学習するか、情報を抽出し、次に学習した知識を使用して小規模モデルを「教育」します。
実際には、最初に大規模モデルによってラベル付けする必要がある画像を学習し、大規模モデルがこれらの画像にラベルを付けることができます。このようにして、画像にラベルを付けました。 、これらの画像を使用して小さなモデルをトレーニングするのが、知識を蒸留する最も簡単な方法です。
もちろん、最初に大規模なモデルを使用して大規模なデータから特徴を抽出し、抽出されたこれらの特徴を小規模なモデルのトレーニングに使用するなど、より複雑な方法を使用することもできます。つまり、より複雑なモデルを設計し、大規模モデルと小規模モデルの間に中型モデルを追加することもできます。大規模モデルによって抽出された特徴は、まず中型モデルをトレーニングし、次にトレーニング済みの中型モデルを使用して特徴を抽出し、小型モデルに与えて使用します。エンジニアは自分のニーズに応じて設計方法を選択できます。
著者は Xiaoma.ai から、大きなモデルから抽出された特徴の蒸留と微調整に基づいて、歩行者の注意や歩行者の意図認識などの小さなモデルが得られることを学びました。特徴抽出段階へ 大規模なモデルを共有することで計算量を削減できます。
1.1.4 試験車両モデルの性能上限
大型モデルはok 車載モデルの性能上限をテストするために使用されます。一部の企業は、自動車側にどのモデルを導入するかを検討する際、まずクラウドでいくつかの代替モデルをテストし、どのモデルが最も効果があるのか、パラメータの数を増やした後にどの程度最高のパフォーマンスが達成できるのかを確認します。
次に、最もパフォーマンスの高いモデルを基本モデルとして使用し、車両に展開する前に基本モデルを調整して最適化します。
1.1.5 自動運転シナリオの再構築とデータ生成
Haimo Zhixing はこれは 2023 年 1 月の AI DAY で言及されました。「NeRF テクノロジーを使用すると、シーンをニューラル ネットワークに暗黙的に保存し、レンダリングされた画像の教師あり学習を通じてシーンの暗黙的なパラメーターを学習し、運転を自動的に再構築できます。シーン。"###### たとえば、写真、対応するポーズ、色付きのシーンの密な点群をネットワークに入力すると、点グリッド ネットワークに基づいて、色付きの点群がポーズに応じて異なる解像度で表示されます。ラスタライゼーションを実行して複数のスケールでニューラル記述子を生成し、ネットワークを通じて異なるスケールの特徴を融合します。 次に、生成された高密度点群の記述子、位置、対応するカメラ パラメーター、画像露出パラメーターが後続のネットワークに入力され、トーン マッピングが微調整され、合成が可能になります。一貫した色と露出で写真を生成します。 #このようにして、シーンを再構成できます。そして、視点の変更、照明の変更、テクスチャ素材の変更などにより、車線変更、迂回、Uターンなどの主要な車両のさまざまな挙動を視点変更によりシミュレーションすることで、さまざまな高リアリティなデータを生成することができます。など、差し迫った衝突をシミュレートすることもできる、高リスクのシナリオ データです。 1.2.1 さまざまなタスクの検出に使用される小さなモデルを結合する 自動車側で大きなモデルを使用する主な形式は、異なるサブタスクを処理する小さなモデルをマージして「大きなモデル」を形成し、その後ジョイントを実行することです。推論。ここでの「大規模モデル」は、従来の意味での多数のパラメータを意味するものではありません (たとえば、1 億を超えるパラメータを持つ大規模モデルなど)。もちろん、結合されたモデルは、さまざまなサブタスクを処理する小規模モデルよりもはるかに大きくなります。 従来の自動車側認識モデルでは、さまざまなサブタスクを処理するモデルが独立して推論を実行します。たとえば、あるモデルは車線境界線検出タスクを担当し、別のモデルは信号機検出タスクを担当します。認識タスクが増加するにつれて、エンジニアはそれに対応してシステム内の特定のターゲットを認識するためのモデルを追加します。 従来の自動運転システムは機能が少なく、認識作業も比較的簡単でしたが、自動運転システムの機能向上に伴い、認識作業が増えています。異なるタスクが引き続き個別に使用される場合、対応するタスクを担当する小規模なモデルが独立した推論に使用される場合、システムの遅延が大きくなりすぎ、セキュリティ上のリスクが発生します。 Juefei Technology の BEV マルチタスク認識フレームワークは、さまざまなターゲットの小さなシングルタスク認識モデルを組み合わせて、車線、地面の矢印などの静的情報を同時に出力できるシステムを形成します。 、交差点の横断歩道、停止線などのほか、交通参加者の位置、サイズ、向きなどの動的な情報も含まれます。 Juefei Technology の BEV マルチタスク認識アルゴリズム フレームワークを以下の図に示します。 1.2 車両側での大きなモデルの適用
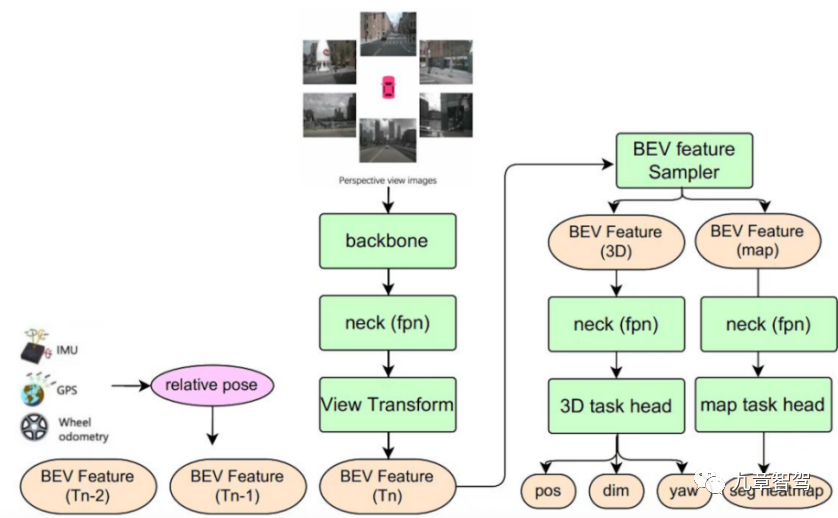
## Juefei Technology BEVタスク認識アルゴリズム フレームワークのマルチ概略図
このマルチタスク認識モデルは、機能の時間的融合を実現します。つまり、過去の時点での BEV 機能を機能キューに保存し、現在に基づく推論フェーズ 当時の自車座標系がベンチマークとして使用され、過去の時点での BEV 特徴が自車の動きに従って時空間的に位置合わせされます (特徴の回転と平行移動を含む)。状態に戻ると、履歴時点で位置合わせされた BEV フィーチャが現在の時点の BEV フィーチャと結合されます。自動運転シナリオでは、タイミング フュージョンにより認識アルゴリズムの精度が向上し、単一フレーム認識の制限をある程度補うことができます。図に示す 3D ターゲット検出サブタスクを例にとると、時間融合を使用すると、知覚モデルは、単一フレームの知覚モデルでは検出できないいくつかのターゲット (現時点で遮蔽されているターゲットなど) を検出できます。また、ターゲットの移動速度をより正確に判断し、下流のタスクによるターゲットの軌道予測を支援します。
Juefei Technology の BEV センシング技術責任者である Qi Yuhan 博士は、著者に次のように述べています。このようなモデル アーキテクチャを使用すると、センシング タスクがますます複雑になると、マルチタスク ジョイントが必要になります。センシング フレームワークは、リアルタイムの認識を保証し、自動運転システムの下流で使用するために、より正確な認識結果を出力することもできます。
ただし、マルチタスクの小規模モデルを結合すると、いくつかの問題も発生します。アルゴリズム レベルから見ると、異なるサブタスクにおけるマージされたモデルのパフォーマンスが「ロールバック」される可能性があります。つまり、モデル検出のパフォーマンスは、独立した単一タスク モデルのパフォーマンスよりも低くなります。さまざまな小さなモデルを結合して形成された大規模モデルのネットワーク構造は依然として非常に洗練されていますが、結合されたモデルはマルチタスクの共同トレーニングの問題を解決する必要があります。 マルチタスクの共同トレーニングでは、各サブタスクは同時かつ同期の収束を達成できない可能性があり、各タスクは「負の転送」と結合モデルの影響を受けます。特定のタスクでは精度の「ロールバック」が発生します。アルゴリズム チームは、マージされたモデル構造を可能な限り最適化し、共同トレーニング戦略を調整し、「負の転送」現象の影響を軽減する必要があります。 1.2.2 物体検出 業界の専門家は著者にこう言いました。比較的固定値を持つオブジェクトは、大規模なモデルでの検出に適しています。 それでは、真理値が比較的固定されているオブジェクトとは何でしょうか? いわゆる真理値が固定されたオブジェクトとは、車線の境界線、柱、街灯など、真の値が天候や時間などの要因に影響されないオブジェクトです。信号機、横断歩道、地下室 駐車ライン、駐車スペースなど これらの物体の存在や位置は固定されており、雨や暗闇などの要因によって変化することはなく、車両が当該エリアを通過する限り、彼らの位置は固定されています。このようなオブジェクトは、大規模なモデルでの検出に適しています。 1.2.3 車線トポロジー予測 自動運転会社の社内 AI DAY 氏は、「BEV 特徴マップに基づいて、標準マップをガイダンス情報として使用し、自己回帰エンコードおよびデコード ネットワークを使用して BEV 特徴を構造化されたトポロジ点シーケンスにデコードして、車線トポロジ予測を実現します。」 業界におけるオープンソースの傾向に伴い、基本的なモデル フレームワークは次のとおりです。もはや秘密ではありません。多くの場合、企業が良い製品を作れるかどうかを決めるのはエンジニアリング能力です。 エンジニアリング能力は、システムの機能を向上させるのに効果的と考えられる方法を考えるときに、アイデアの実現可能性をすぐに検証できるかどうかを決定します。 Tesla と Open AI の大きな共通点は、両社が強力なエンジニアリング能力を備えていることです。アイデアの信頼性をできるだけ早くテストし、選択したモデルに大規模なデータを適用できます。 大型モデルの能力を実際に最大限に活用するには、企業のエンジニアリング能力が非常に重要です。次に、大型モデルを使いこなすためにはどのようなエンジニアリング能力が必要なのかをモデル開発のプロセスに応じて説明します。 大規模なモデルには多数のパラメーターがあり、それに応じてトレーニングに使用されるデータも大型モデル 部分も大きいです。たとえば、テスラのアルゴリズム チームは、昨年の AI Day でチームが話していた 3D 占有ネットワークをトレーニングするために約 14 億枚の画像を使用しました。 実際、画像数の初期値は、おそらく実際に使用される数の数十倍または数百倍になります。これは、最初にモデルのトレーニングに役立つ画像をフィルタリングして除外する必要があるためです。したがって、モデルのトレーニングに使用される画像は 14 億枚であるため、元の画像の数は 14 億枚よりもはるかに多くなる必要があります。 では、数百億、さらには数千億の画像データを保存するにはどうすればよいでしょうか?これは、ファイル読み取りシステムとデータ ストレージ システムの両方にとって大きな課題です。特に、現在の自動運転データはクリップ形式でファイル数が多いため、小さなファイルを即時に保存する効率が求められます。 このような課題に対処するために、業界の一部の企業はデータのスライス ストレージ方式を使用し、分散アーキテクチャを使用してマルチユーザーおよびマルチ同時アクセスをサポートしています。スループット帯域幅は 100G/s に達し、I/O 遅延はわずか 2 ミリ秒に抑えられます。いわゆるマルチユーザーとは、特定のデータ ファイルに同時にアクセスする多くのユーザーを指します。マルチ同時実行性は、複数のスレッドで特定のデータ ファイルにアクセスする必要性を指します。たとえば、エンジニアがモデルをトレーニングするとき、彼らはマルチを使用します。 -threading. 各スレッドはすべて、特定のデータ ファイルの使用を必要とします。 ビッグ データの場合、モデルがデータ情報をより適切に抽象化できるようにするにはどうすればよいでしょうか。これには、モデルのパラメータ数の多さの利点を最大限に活用できるように、モデルが対応するタスクに適したネットワーク アーキテクチャを備え、モデルが強力な情報抽出能力を備えている必要があります。 SenseTime の大型モデル R&D のシニア マネージャーである Lucas 氏は、著者にこう語った: 「当社には、標準化された工業グレードの半自動超大型モデル設計システムがあります。私たちはこのシステムを利用して、非常に大規模なモデルのネットワーク アーキテクチャを設計するとき、ニューラル ネットワーク検索システムをベースとして使用して、大規模データの学習に最適なネットワーク アーキテクチャを見つけることができます。 小規模なモデルを設計する場合、最終的に満足のいく結果が得られるモデルを得るには、主に手動の設計、チューニング、反復に依存します。このモデルは必ずしも最適であるとは限りませんが、反復後は、基本的には要件を満たすことができます。 大規模なモデルに直面した場合、大規模なモデルのネットワーク構造は非常に複雑であるため、手動での設計、調整、反復を使用すると、大量の計算能力を消費することになります。土地代も高いし。したがって、限られたリソースでトレーニングに十分なネットワーク アーキテクチャを迅速かつ効率的に設計する方法は、解決する必要がある問題です。 Lucas 氏は、一連の演算子ライブラリがあり、モデルのネットワーク構造はこの一連の演算子の順列と組み合わせとして見ることができると説明しました。この産業グレードの検索システムは、ネットワークの層数やパラメータの大きさなどの基本的なパラメータを設定することで、より良いモデル効果を実現するために演算子をどのように配置および組み合わせるかを計算できます。 モデルのパフォーマンスは、特定のデータセットの予測精度、モデルの実行時に使用されるメモリ、モデルの実行に必要な時間など、いくつかの基準に基づいて評価できます。 。これらのメトリクスに適切な重みを与えることで、満足のいくモデルが見つかるまで反復を続けることができます。もちろん、検索段階では、最初にいくつかの小さなシーンを使用してモデルの効果を最初に評価しようとします。 モデルの効果を評価する際、より代表的なシーンをどのように選択すればよいでしょうか? 一般的に、いくつかの一般的なシナリオを選択できます。ネットワーク アーキテクチャは、モデルが特定のシナリオの特性を学習できることを期待するのではなく、モデルが大量のデータから重要な情報を抽出できるようにすることを主な目的として設計されています。モデルはロングテール シナリオのマイニングのいくつかのタスクを完了するために使用されますが、モデル アーキテクチャを選択する際には、モデルの機能を評価するために一般的なシナリオが使用されます。 高効率かつ高精度のニューラル ネットワーク検索システムを使用すると、計算効率と計算精度が十分に高いため、モデル効果が迅速に収束し、迅速に見つけることができます。巨大な空間でもうまく機能するネットワークアーキテクチャ。 前の基本的な作業が完了したら、トレーニング リンクに進みます。トレーニングリンクの最適化場所。 #2.3.1 最適化演算子 ニューラル ネットワークは、多くの要素から構成されると理解できます。 Basic 演算子の順列と組み合わせから導き出されますが、演算子の計算には計算能力リソースが消費される一方で、メモリも消費されます。オペレーターの計算効率を向上させるためにオペレーターを最適化できれば、トレーニング効率も向上します。 PyTorch、TensorFlow など、すでにいくつかの AI トレーニング フレームワークが市場に出回っています。これらのトレーニング フレームワークは、機械学習エンジニアが独自のモデルを構築するために呼び出す基本的なオペレーターを提供できます。 。一部の企業は、トレーニングの効率を向上させるために、独自のトレーニング フレームワークを構築し、基盤となるオペレーターを最適化します。 PyTorch と TensorFlow は可能な限り汎用性を確保する必要があるため、PyTorch と TensorFlow が提供する演算子は一般に非常に基本的なものです。企業は自社のニーズに応じて基本的な演算子を統合できるため、中間結果を保存する必要がなくなり、メモリ使用量が節約され、パフォーマンスの損失が回避されます。 さらに、一部の特定の演算子が計算中の中間結果への依存度が高いため、GPU の並列性を十分に活用できないという問題を解決するために、一部の企業では、業界は独自のアクセラレーション ライブラリを構築し、これらの演算子の中間結果への依存を減らし、計算プロセスで GPU の並列コンピューティングの利点を最大限に活用し、トレーニング速度を向上させることができます。 たとえば、4 つの主流の Transformer モデルでは、ByteDance の LightSeq は PyTorch に基づいて最大 8 倍の高速化を達成しました。 #2.3.2 並列戦略を上手に活用する 並列コンピューティングは「 「スペース・フォー・タイム」方式とは、計算依存関係をできる限りなくしてデータを並列化し、大きなバッチを小さなバッチに分割し、各計算ステップでの GPU アイドル待ち時間を削減し、計算のスループットを向上させることです。 現在、多くの企業が PyTorch トレーニング フレームワークを採用しています。このトレーニング フレームワークには、分散データ並列トレーニング モードとして DDP モードが含まれており、DDP モードはデータ分散を設計します。マシンとマルチカード トレーニング たとえば、会社に 8 台のサーバーがあり、各サーバーに 8 枚のカードがある場合、同時に 64 枚のカードをトレーニングに使用できます。 このモードを使用しない場合、エンジニアは複数のカードを備えた 1 台のマシンを使用してモデルをトレーニングすることしかできません。 100,000 枚の画像データを使用してモデルをトレーニングするとします。単一マシンのマルチカード モードでは、トレーニングに 1 週間以上かかります。トレーニング結果を使用して特定の推測を評価したい場合、またはいくつかの代替モデルから最適なモデルを選択したい場合、そのようなトレーニング時間により、推測を迅速に検証し、モデルの効果を迅速にテストするために必要な待ち時間が非常に長くなります。そうなると研究開発効率は非常に低くなってしまいます。 マルチマシンとマルチカードの並列トレーニングでは、ほとんどの実験結果は 2 ~ 3 日で確認できます。このように、モデルの効果を検証するプロセスは非常に手間がかかります。もっと早く。 具体的な並列化手法としては、主にモデル並列化とシーケンス並列化が考えられます。 モデルの並列処理は、次の図に示すように、パイプラインの並列処理とテンソルの並列処理に分類できます。 02
大規模モデルを上手に活用する方法
2.1 データ ストレージとファイル転送システムのアップグレード
2.2 適切なネットワーク アーキテクチャを効率的に見つける
2.3 モデルのトレーニング効率の向上
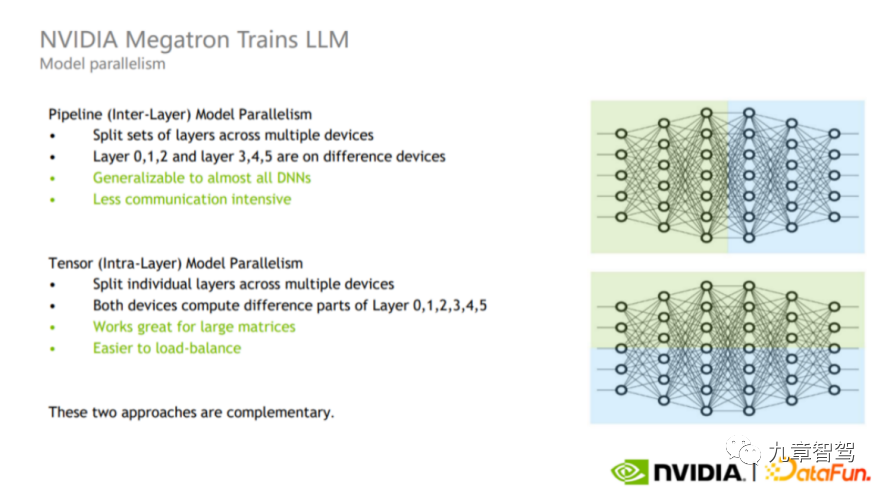
パイプライン並列処理とテンソル並列処理の概略図、写真は NVIDIA から引用
パイプラインの並列処理は層間並列処理です (図の上部)。エンジニアはトレーニング プロセス中に、計算のためにモデルの異なる層を異なる GPU に分割することを覚えておくことができます。たとえば、図の上半分に示すように、レイヤーの緑色の部分と青色の部分を異なる GPU で計算できます。
Tensor 並列処理は層内並列処理 (図の下の部分) であり、エンジニアは層の計算を異なる GPU に分割できます。このモードはGPU間の負荷分散が可能なため、大きな行列の計算に適していますが、通信回数やデータ量が比較的多くなります。
モデル並列処理に加えて、シーケンス並列処理もあります。Tensor 並列処理では Layer-norm と Dropout が分割されないため、これら 2 つの演算子が各 GPU 間で繰り返されます。計算量は多くありませんが、アクティブなビデオ メモリを多く消費します。
この問題を解決するために、実際のプロセスでは、Layer-norm と Dropout がシーケンスの次元に沿って互いに独立しているという事実を利用できます (つまり、異なるレイヤー間の Layer_norm と Dropout は互いに影響しません)、下の図に示すように Layer-norm と Dropout を分割します。この分割の利点は、通信量を増やさず、メモリ使用量を大幅に削減できることです。
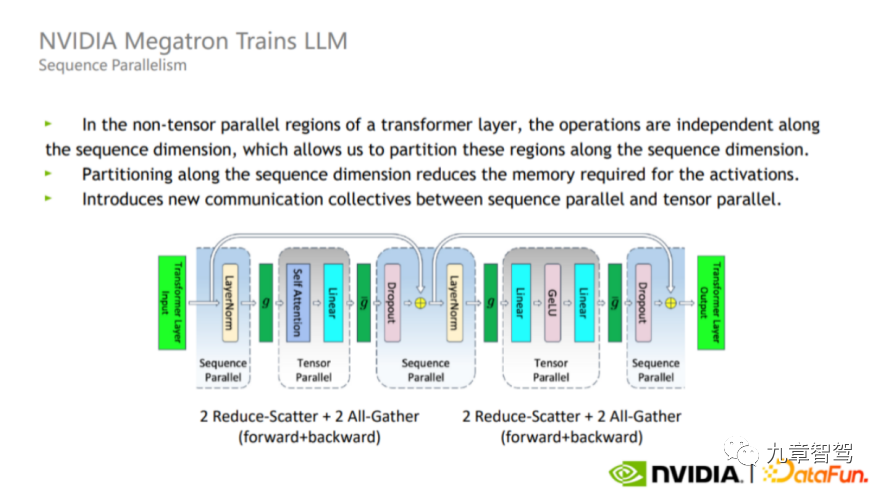
シーケンス並列図、NVIDIA からの画像 #実際には、モデルごとに適切な並列戦略が異なるため、エンジニアはモデルの特性、使用するハードウェアの特性、中間計算プロセスに基づいて継続的なデバッグを行った後、適切な並列戦略を見つける必要があります。
2.3.3 「スパース」を上手に活用する モデルをトレーニングするときは、スパース性をうまく利用する必要があります。つまり、すべてのニューロンが「アクティブ化」される必要はありません。つまり、トレーニング データを追加するときに、すべてのモデル パラメーターが新しく追加されたものに基づく必要はありません。データは更新されますが、一部のモデル パラメーターは変更されず、一部のモデル パラメーターは新しく追加されたデータで更新されます。 優れたスパース処理により、モデルのトレーニング効率を向上させながら精度を確保できます。 たとえば、認識タスクでは、新しい画像が渡されると、これらの画像に基づいて更新する必要があるパラメーターを選択して、ターゲットを絞った特徴抽出を実行できます。 2.3.4 基本情報の統合処理 一般的には、さらに多くの情報があります。モデルが使用され、これらのモデルは同じデータを使用する可能性があります (たとえば、ほとんどのモデルはビデオ データを使用します)。各モデルがビデオ データをロードして処理すると、多くの繰り返し計算が発生します。ほとんどのモデルが使用する必要があるビデオ、点群、地図、CAN 信号などのさまざまなモーダル情報を均一に処理できるため、異なるモデルで処理結果を再利用できます。 #2.3.5 ハードウェア構成の最適化 実際に分散トレーニングを使用する場合、1,000 台のマシントレーニング プロセス中に、データを保存するさまざまなサーバーから勾配などの中間結果を取得し、非常に大規模な分散トレーニングを実行する方法は大きな課題です。 この課題に対処するには、まず、CPU、GPU などの構成方法、ネットワーク カードの選択方法、およびネットワーク カードの速度を考慮する必要があります。マシン間の送信は高速になります。 次に、パラメータを同期して中間結果を保存する必要がありますが、規模が大きい場合、これは非常に困難になり、ネットワーク通信の作業が発生します。 さらに、トレーニング プロセス全体には長い時間がかかるため、クラスターの安定性が非常に高い必要があります。 大規模なモデルではすでに一部を再生できるようになりました。自動運転の分野での役割、モデルパラメータを増加し続けた場合、大型モデルが驚くべき効果を示すことが期待できますか? 著者が自動運転分野のアルゴリズム専門家とやりとりしたところによると、現時点での答えはおそらく「ノー」です。なぜなら、上記の「創発」現象がまだ CV に適用されていないからです (コンピュータ ビジョン) フィールドが表示されます。現在、自動運転分野で使用されるモデルパラメータの数はChatGPTに比べてはるかに少ないです。 「創発」効果がない場合、モデルのパフォーマンスの向上とパラメータ数の増加の間にはほぼ線形の関係があるため、コストの制約を考慮すると、企業はまだモデル内のパラメータ数を最大化できていません。 なぜコンピュータビジョンの分野ではまだ「創発」という現象が起きていないのでしょうか?専門家の説明は次のとおりです: まず、世の中にはテキスト データよりもはるかに多くの視覚データが存在しますが、画像データはまばらであり、ほとんどの写真には含まれていない可能性があります。有効な情報がどれだけあるか、各画像内のピクセルのほとんどは有効な情報を提供しません。セルフィーを撮る場合、中央の顔を除いて、背景領域には有効な情報がありません。 第 2 に、画像データには大幅なスケール変更があり、完全に構造化されていません。スケールの変更は、同じセマンティクスを含むオブジェクトが、対応するピクチャ内で大きくなったり小さくなったりする可能性があることを意味します。たとえば、最初に自撮りをして、遠くにいる友人にもう一枚撮ってもらうと、2枚の写真では顔の割合が大きく異なります。非構造化とは、各ピクセル間の関係が不確実であることを意味します。 しかし、自然言語処理の分野では、言語は人と人とのコミュニケーションのツールであるため、通常は文脈が関連しており、各文の情報密度が一般的に高くなります。たとえば、どの言語でも、「リンゴ」という単語は通常、長すぎません。 したがって、視覚データそのものを理解することは、自然言語よりも困難になります。 業界の専門家は著者にこう言いました: パラメーターの数が増えるとモデルのパフォーマンスが向上することが期待できますが、パラメーターの数を増やし続けることの現在の費用対効果は低いです。 たとえば、モデルの容量を既存の 10 倍に拡張すると、相対エラー率は 90% 削減できます。現時点では、モデルは顔認識などのいくつかのコンピューター ビジョン タスクをすでに完了できています。この時点でモデルの容量を 10 倍に拡張し続け、相対エラー率が 90% 減少し続けても、達成できる値が 10 倍に増加しない場合は、拡張を続ける必要はありません。モデルの容量。 モデルが大きくなると、より多くのトレーニング データとより多くの計算能力が必要になるため、モデルの容量を拡張するとコストが増加します。モデルの精度が許容範囲に達したら、コストの上昇と精度の向上の間でトレードオフを行い、実際のニーズに応じて許容できる精度で可能な限りコストを削減する必要があります。 精度を向上させるために必要なタスクがまだいくつかありますが、大規模なモデルは主に、自動アノテーションやデータ マイニングなど、クラウドでの一部の手動作業を置き換えます。人間によって行われた。コストが高すぎる場合、経済勘定は計算されません。 しかし、一部の業界専門家は著者にこう言いました。「まだ質的変化点には達していないが、モデルのパラメータが増加し、データ量が増加するにつれて、確かに次のことが観察できます。」モデルの精度が向上しました。ラベル付けタスクに使用されるモデルの精度が十分に高ければ、自動ラベル付けのレベルが向上し、大幅な人件費が削減されます。現時点では、モデルのサイズが大きくなるにつれてトレーニング コストは増加しますが、コストはモデル パラメーターの数にほぼ線形に関係しています。学習コストは増加しますが、人員の削減で相殺できるため、パラメータの数を増やすことには依然としてメリットがあります。 さらに、トレーニング効率を向上させてトレーニング コストを最小限に抑えながら、モデル パラメーターの数を増やすいくつかのテクニックも使用します。既存のモデル スケール内でコストを一定に保ちながら、モデルのパラメーターの数を増やし、モデルの精度を向上させることができます。これは、モデルパラメータの増加に対してモデルのコストが直線的に増加するのを防ぐことに相当し、コストの増加をほとんどゼロ、またはわずかな増加に抑えることができます。 上記のアプリケーションに加えて、他にどのようなことができるでしょうか。大規模モデルの価値を発見することについて? CMU 研究科学者の Max 氏は著者にこう言いました: 知覚タスクを達成するために大規模なモデルを使用することの核心は、パラメータを積み重ねますが、「内部循環」できるフレームワークを作成します。モデル全体で内部ループを実現できない場合、または継続的なオンライン トレーニングを実現できない場合、良好な結果を達成することは困難になります。 では、モデルの「内部ループ」を実装するにはどうすればよいでしょうか?以下の図に示すように、ChatGPT のトレーニング フレームワークを参照できます。 モデル パラメーターを増やし続けることに意味はありますか?
04
大規模モデルのその他の可能なアプリケーション
4.1 知覚の分野で
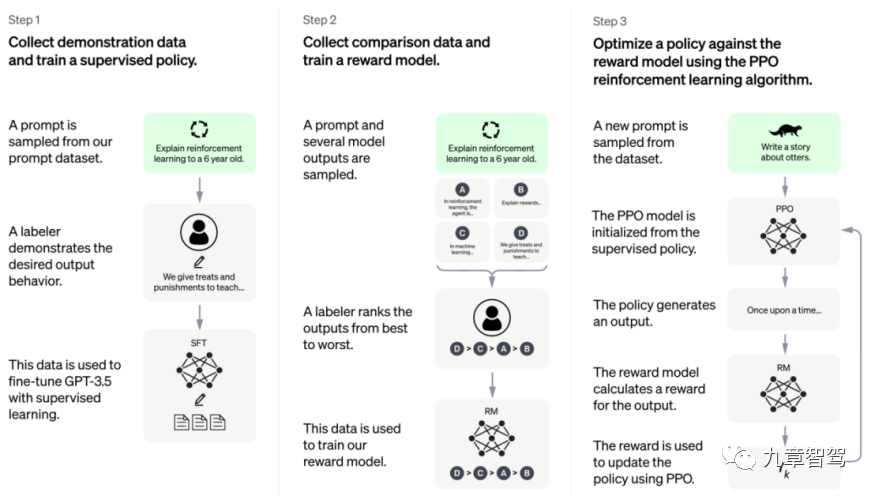
ChatGPT トレーニング フレームワーク、写真は Open AI 公式 Web サイトから引用 ##ChatGPT のモデル フレームワークは 3 つのステップに分けることができます: 最初のステップは教師あり学習です。エンジニアはまずデータの一部を収集してラベルを付け、次にデータのこの部分を使用してモデルをトレーニングします。 2 番目のステップでは、報酬モデル (報酬モデル) を設計します。このモデルは、いくつかのラベル付け結果をそれ自体で出力できます。3 番目のステップでは、強化学習に似たパスを通じて自己教師あり学習を実装できます。強化学習は、より一般的な言語で呼ばれます。 「自分自身で遊ぶ」、または「インナーループ」と言います。
3 番目のステップに到達すると、モデルはエンジニアがラベル付きデータを追加する必要がなくなり、ラベルなしデータを取得した後に損失を自分で計算し、更新できるようになります。パラメータなどを繰り返して、最終的にトレーニングが完了します。
「モデルのトレーニングが注釈付きデータに依存しなくなるように、認識タスクを実行するときに適切な報酬ポリシーを設計できれば、モデルは「内部ループ」を達成したと言えます。パラメータは、ラベルのないデータに基づいて継続的に更新できます。」
4.2 計画の分野での
囲碁などの分野では、一般にゲームに勝つことだけが目標となるため、各ステップの質を判断するのが簡単です。最後に。
しかしながら、自動運転計画の分野においては、自動運転システムが示す挙動の評価体系は明確ではありません。安全の確保だけでなく、快適さについての感覚も人それぞれですし、できるだけ早く目的地に着きたいという思いもあるでしょう。
チャットシーンに移りますが、ロボットが毎回与えるフィードバックが「良い」か「悪い」かは、実はGoのような明確な評価システムではありません。自動運転も同様で、人によって「良い」「悪い」の基準が異なり、明確に表現するのが難しいニーズがあるかもしれません。
ChatGPT トレーニング フレームワークの 2 番目のステップでは、アノテーターはモデルによって出力された結果を並べ替え、この並べ替えられた結果を使用して報酬モデルをトレーニングします。最初は、この報酬モデルは完璧ではありませんが、継続的なトレーニングを通じて、この報酬モデルを継続的に望ましい効果に近づけることができます。
人工知能企業の専門家は著者にこう語った: 自動運転計画の分野では、車の運転に関するデータを継続的に収集し、人間がどのような状況下で運転するかをモデルに伝えることができます。どのような状況で正常に走行できるのか(言い換えれば、人が危険を感じるのか)、データ量が増えるにつれて報酬モデルはどんどん完成度に近づいていきます。
言い換えれば、完璧な報酬モデルを明示的に書くことを諦め、代わりにモデルにフィードバックを与え続けることで常に完璧に近づくソリューションを取得することを検討できます。
計画の分野における現在の一般的な慣行と比較すると、まず初期の報酬モデルを使用し、次に手動の記述ルールに依存して最適なソリューションを明示的に見つけようとします。データに基づいて継続的に最適化することは、パラダイム シフトです。
この方法を採用すると、最適化計画モジュールは比較的標準的なプロセスを採用できるようになります。必要なのは継続的にデータを収集し、報酬モデルをトレーニングすることだけです。それは、計画モジュール全体に対するエンジニアの理解の深さに依存します。
さらに、すべての履歴データをトレーニングに使用できます。現在の問題の一部は解決されていますが、特定のルール変更後はそのことを心配する必要はありません。従来の方法を採用していたら、解決できたであろう問題が再び発生します。
以上が自動運転分野における大型モデルの応用について説明する 10,000 ワードの長い記事の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7461
7461
 15
1376
52
77
11
17
17
15
1376
52
77
11
17
17

 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
先頭と開始点に書かれている エンドツーエンドのパラダイムでは、統一されたフレームワークを使用して自動運転システムのマルチタスクを実現します。このパラダイムの単純さと明確さにも関わらず、サブタスクにおけるエンドツーエンドの自動運転手法のパフォーマンスは、依然としてシングルタスク手法に比べてはるかに遅れています。同時に、以前のエンドツーエンド手法で広く使用されていた高密度鳥瞰図 (BEV) 機能により、より多くのモダリティやタスクに拡張することが困難になります。ここでは、スパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) が提案されています。このパラダイムでは、スパース検索は、高密度の BEV 表現を使用せずに、空間、時間、タスクを含む運転シナリオ全体を完全に表します。具体的には、統合されたスパース アーキテクチャが、検出、追跡、オンライン マッピングなどのタスク認識のために設計されています。さらに、重い
 エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
この 1 か月間、いくつかのよく知られた理由により、私は業界のさまざまな教師やクラスメートと非常に集中的な交流をしてきました。この交換で避けられない話題は当然、エンドツーエンドと人気の Tesla FSDV12 です。この機会に、現時点での私の考えや意見を整理し、皆様のご参考とご議論に役立てたいと思います。エンドツーエンドの自動運転システムをどのように定義するか、またエンドツーエンドで解決することが期待される問題は何でしょうか?最も伝統的な定義によれば、エンドツーエンド システムとは、センサーから生の情報を入力し、関心のある変数をタスクに直接出力するシステムを指します。たとえば、画像認識では、従来の特徴抽出 + 分類子方式と比較して、CNN はエンドツーエンドと言えます。自動運転タスクでは、各種センサー(カメラ/LiDAR)からのデータを入力
